




什么是向量数据库?
向量数据库(Vector Database),也叫矢量数据库,主要用来存储和处理向量数据。
在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方向,线段的长度表示向量的大小。
图像、文本和音视频这种非结构化数据都可以通过某种变换或者嵌入学习转化为向量数据存储到向量数据库中,从而实现对图像、文本和音视频的相似性搜索和检索。这意味着您可以使用向量数据库根据语义或上下文含义查找最相似或相关的数据,而不是使用基于精确匹配或预定义标准查询数据库的传统方法。从技术上来讲,要实现对非结构化数据的精确匹配是很困难的,因为数据没有结构,就不存在类似关系型数据库中的表定义,无法通过某个字段(属性)来查询。
可以将向量理解为原始非结构化数据的一个标识(似hash但非hash,可以类比),任何一个非结构化数据经过某种embedding算法后,都能转换成一个向量(向量维数一般很高,成千上万)。在存储时会将向量和对应的原始非结构化数据关联起来,找到向量就能找到对应的原始数据。在查询时,首先将待查询的条件进行embedding,查询条件就转换成了一个向量。然后比较条件向量和数据库中存在的原始数据向量,返回最相似的N个原始数据向量,进而得到N个原始数据的查询结果。
这里有三个关键点:
1. 不同的结构化数据的embedding的算法都有哪些?
2. 怎样才能在大量的原始非结构化数据向量中找到与查询向量最相似的N个向量?一个一个去暴检查,还是有索引相关的技术(类似MySQL中的B+ Tree)?
3. 怎么判断两个向量最相似?
不同的结构化数据的embedding的算法都有哪些?
Embedding又叫嵌入,用于将复杂的非结构化数据表示为结构化的向量格式,以便在向量数据库中存储以及实现对非结构化数据的相似性判断。一旦数据被嵌入为向量,向量数据库可以执行相似性搜索,以找到在向量空间中彼此接近的数据点,这对于推荐、聚类和分类非常有用。
文本嵌入
Word2Vec:根据语料库中的上下文将单词转换为向量。
GloVe(全局向量表示):使用词共现统计生成嵌入。
FastText:通过考虑子词信息扩展Word2Vec。
BERT(双向编码器表示):为句子和单词生成上下文感知的嵌入。
GPT(生成预训练变换器):提供嵌入作为其语言建模能力的一部分。
Sentence Transformers:专为句子级别嵌入设计。
图像嵌入
卷积神经网络(CNNs):从图像中提取特征,用于分类和识别任务。
ResNet、VGG、Inception:用于生成图像嵌入的预训练CNN模型。
视觉变换器(ViT):将变换器架构应用于图像数据。
视频嵌入
3D卷积网络:通过考虑时间信息扩展CNN以处理视频数据。
循环神经网络(RNNs)/ LSTMs:处理视频帧序列。
I3D(膨胀3D卷积网络):用于视频动作识别。
音频嵌入
MFCC(梅尔频率倒谱系数):传统的音频特征提取方法。
基于频谱图的CNNs:使用频谱图作为输入的CNN模型。
WaveNet:用于生成音频嵌入的深度神经网络架构。
OpenAI的Whisper:用于语音识别和嵌入的模型。
这些算法和模型根据应用的具体需求选择,例如数据类型、所需的准确性水平和计算资源。嵌入使得在向量数据库中对大规模非结构化数据进行高效处理和分析成为可能。
怎样才能在大量的原始非结构化数据向量中找到与查询向量最相似的N个向量?
组织和索引嵌入后的向量是向量数据库和相似性搜索系统的核心任务,类似MySQL中的B+ tree,是向量数据库最核心的地方。为了高效地存储和检索这些向量,通常会使用专门的算法和数据结构。以下是一些常见的组织和索引嵌入向量的算法和方法:
基于树的算法
KD-Tree: 用于低维空间的最近邻搜索。通过递归地将空间划分为超矩形来组织数据。在高维空间中性能下降。
Ball Tree: 适用于高维空间。使用球体而不是矩形来划分空间。在某些情况下比 KD-Tree 更有效。
VP-Tree (Vantage Point Tree): 适合度量空间的最近邻搜索。通过选择一个“视点”并根据距离划分空间。
Annoy (Approximate Nearest Neighbors Oh Yeah): 用于大规模数据集的近似最近邻搜索。构建多个树并在查询时搜索这些树。适合内存受限的环境。
基于图的算法
HNSW (Hierarchical Navigable Small World): 基于图的近似最近邻搜索算法。构建一个小世界网络以实现快速搜索。在许多实际应用中表现出色。
基于Hash的算法
LSH (Locality-Sensitive Hashing): 用于近似最近邻搜索。通过哈希函数将相似的项映射到相同的桶中。适合处理大规模数据集。
基于倒排索引的算法
主要用于文档的搜索,倒排索引首先提取关键词,然后将所有与此关键字相关的文档都关联到这个关键字,这样查询到这个关键字以后就能快速找到对应的文档。
怎么判断两个向量最相似?
向量的距离可以用来衡量两个向量的相似度,常见的有余弦距离,欧式距离和向量内积几种方式。
余弦距离
通过计算两个向量的夹角余弦值来计算相似性。夹角为0时相似度为1,夹角90度时,相似度为0,夹角180时相似度为-1,因此余弦相似度的取值范围为[-1,1]。
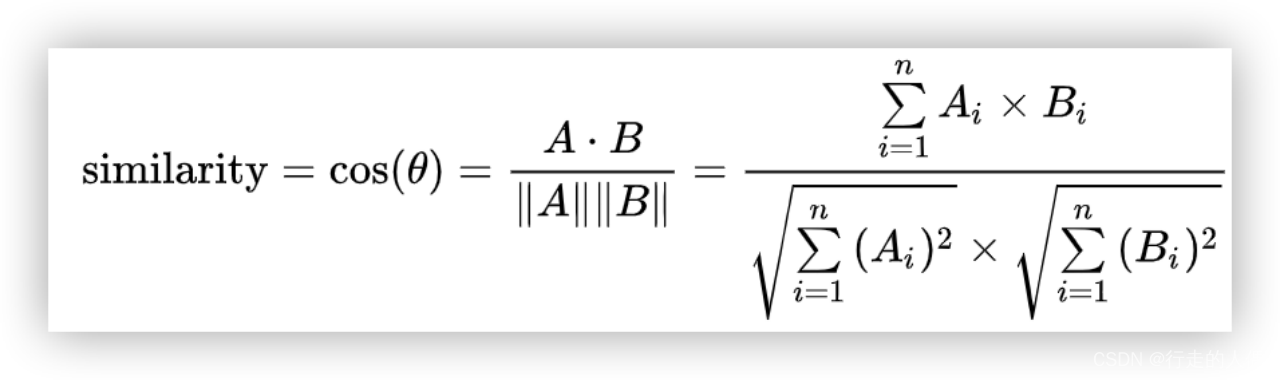
欧式距离
欧式距离全称是欧几里得距离,度量的是空间上两个点之间的连线距离,空间上的点都可以看着是从原点出发的向量。

向量内积
又称数量积,点积,得到的是一个数字。两个向量a = [a1, a2,…, an]和b = [b1, b2,…, bn]的点积定义为:a·b=a1b1+a2b2+……+anbn。
通过三角形余弦定理可推导出,
a1b1+a2b2+……+anbn = |a||b|cos(θ),等号的左边部分刚好就是向量的内积。所以就有了上面余弦距离中求cos(θ)的公式了。
向量的内积在几何上表示为其中一个向量(a)的距离(|a|)与另一个向量(b)在此向量(a)上的投影(|b|cos(θ))的距离的乘积,即:|a||b|cos(θ)。
向量数据库在LLM中的作用
在大规模语言模型(LLM)中,向量数据库扮演着重要角色,主要用于高效存储和检索嵌入向量。由于我们的文档等非结构化数据可能非常的多,也可能在不停的增加和变化,且这些文档可能是内部非公开的。这些因素就决定了不可能实时训练基于这些非公开数据的大模型,训练的成本和代价太高了。向量数据库在一定程度上可以解决此问题,其主要作用是可以实时存储这些大量的非结构化数据,通过查询条件从向量数据库中查询到最合适(最相关,最相似,最相近,etc.)的提示词(Prompt),再将这些提示词送入到LLM模型中进行推理。如果没有向量数据库,我们人为很难从大量的非




















 3419
3419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










