



 文章详细描述了PRIVANALYZER和PRIVGUARD在实际数据分析中的性能评估,包括使用Kaggle竞赛程序的测试,以及在AMDSEV支持下的隐私保护。结果显示PRIVGUARD在合理性能开销下有效执行隐私策略,同时探讨了系统的限制和未来改进方向。
文章详细描述了PRIVANALYZER和PRIVGUARD在实际数据分析中的性能评估,包括使用Kaggle竞赛程序的测试,以及在AMDSEV支持下的隐私保护。结果显示PRIVGUARD在合理性能开销下有效执行隐私策略,同时探讨了系统的限制和未来改进方向。
4 评估
本次评估旨在证明:(1)PRIVANALYZER支持用于数据分析的常用库,并能分析现实世界中的程序;(2)PRIVGUARD轻量级且可扩展。为此,我们(1)使用来自Kaggle竞赛平台的23个真实世界分析程序测试PRIVANALYZER,并(2)使用这些程序的一个子集测量PRIVGUARD的开销。结果显示,PRIVGUARD能够在合理的性能开销下正确执行PRIVPOLICY策略。
4.1 实验设置
我们用大约1400行Python代码实现了PRIVANALYZER,并将其集成到工业级数据治理平台Parcel中,以原型化PRIVGUARD。我们的实现采用了Inter Planetary File System (IPFS)作为存储层,AES-256-GCM作为加密算法,以及AMD SEV作为可信执行环境(TEE)。
Inter Planetary File System (IPFS):
Inter Planetary File System (IPFS) 是一种分布式文件系统,旨在连接所有计算设备的文件系统。IPFS 使用内容寻址来唯一标识文件,而不是通过物理地址定位。这意着每个文件和所有的块都有一个独一无二的哈希值,确保文件的内容能够被验证和取回,而不依赖于原始的位置或服务器。
IPFS 的设计目标是提高网络的效率、减少重复的数据、提高网页加载速度,并使网络对地理和政治限制更加鲁棒。它也支持离线浏览,即使原始网站不再可用,只要有人在某处保存了其内容的副本。IPFS 通过创建一个更持久的、更开放的互联网来促进去中心化,这对于数据的保存和访问是一次重大的变革。
AMD SEV (Secure Encrypted Virtualization):
AMD SEV (Secure Encrypted Virtualization) 是由 AMD 提供的一项安全技术,设计用于保护虚拟机(VM)的隐私和完整性。SEV 通过对虚拟机的内存进行加密来实现这一点。每个虚拟机都可以被分配一个唯一的加密密钥,由专门的硬件安全处理器管理,因此即使是物理机的管理员也无法访问加密的虚拟机内存。
为了评估PRIVGUARD对现实世界程序的静态分析能力,我们从Kaggle收集了23个不同任务的分析程序,Kaggle是最著名的数据分析竞赛平台之一。这些程序分析敏感数据,如欺诈检测和交易预测。我们选择这些程序作为案例研究,以展示PRIVGUARD分析现实世界分析程序和支持常用库的能力。这些案例研究旨在代表数据科学家在许多不同类型的组织中日常操作期间编写的程序。我们随机调查了100个Kaggle程序,发现约85%的程序代码行数(移除空行后)少于300行。相应地,我们的案例研究程序代码行数介于50到276行之间,总计1600行代码,并且包括从Kaggle笔记本随机挑选的程序和竞赛排行榜上的顶尖程序。如表1所示,这些程序使用了多种外部库,包括广泛使用的库,如pandas、PySpark、Tensorflow、PyTorch、scikit-learn和XGBoost。
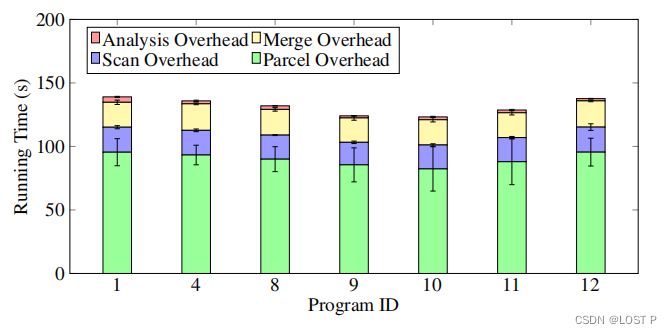
评估的第一步,我们使用PRIVANALYZER分析表1中列出的收集程序。在实验中,我们为每个程序手动设计了一个合适的LEGALEASE策略,并将其附加到每个数据集上。对于每个程序,我们记录了在数据集上运行的时间以及PRIVANALYZER分析程序所需的时间。我们还手动检查了PRIVANALYZER输出的分析结果是否正确。所有实验均在一台安装了Ubuntu 18.04 LTS的服务器上运行,该服务器配备了32个AMD Opteron™ Processor 6212和512GB RAM。结果见表2。评估的第二步,我们选取了7个带有开源数据集的案例研究,在PRIVGUARD原型上运行它们,并测量了相关性能。
4.2 结果
支持现实世界程序。我们的实验展示了PRIVGUARD分析组织中常见的数据处理分析程序的能力。表2中的结果显示,大多数程序的静态分析仅需一两秒钟,有三个例外分别需要3.32秒、4.78秒和6.84秒。下一段将解释这些异常值的原因。与其他抽象解释和符号执行框架一样,我们预计条件语句、循环以及其他控制流构造将对分析时间产生比程序长度更大的影响。幸运的是,数据分析和机器学习的程序倾向于不广泛使用这些构造,尤其是与传统程序相比。相反,它们倾向于使用库提供的构造,如pandas定义的查询特性或scikit-learn提供的模型构建类。上文提到的异常值(案例研究2、13和14)包含了相对较多的条件使用,因此,它们的分析时间略长于其他程序。这些结果表明,PRIVGUARD将能够扩展到更长的数据分析和机器学习程序,尤其是如果这些程序遵循相同的模式,偏好使用库而不是传统的控制流构造。
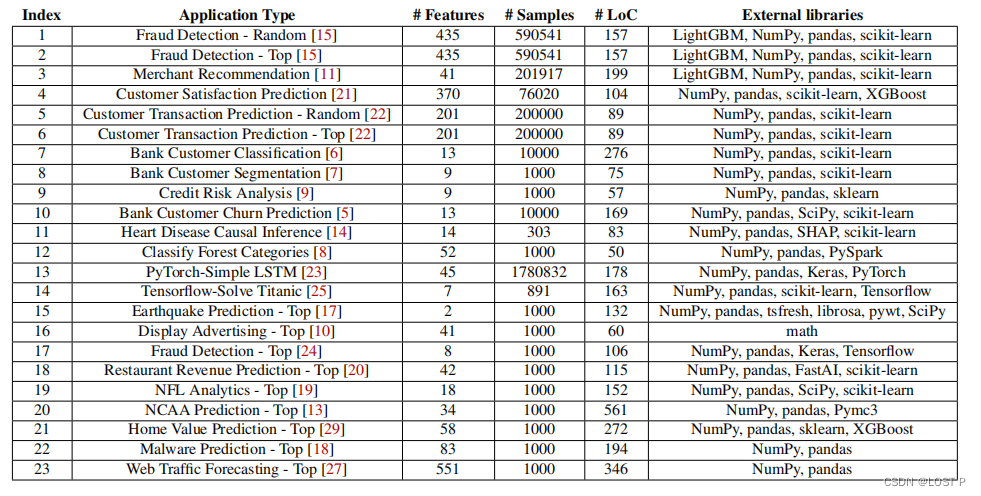
表2报告了所有23个案例研究的性能开销。结果报告了分析性能开销——静态分析所需时间与原始程序本地执行时间的比率。结果显示,这种开销可以忽略不计。对于运行时间较长的案例研究程序,部署PRIVGUARD的性能开销通常小于1%。对于运行更快的程序,绝对开销类似——通常只需一两秒钟——但当程序执行时间很短时,这代表了较大的相对变化。我们实验中的最大相对性能开销约为35%,对于一个仅需13.33秒的程序而言。整体性能开销和可扩展性。我们还在原型实现上评估了7个案例研究,并测量了PRIVGUARD系统的总体开销。结果显示在图7和图8中。对于每个案例研究,我们通过组合可能的属性并更改属性中的参数来合成一百万个随机策略,以模拟一百万个数据主体的隐私偏好。结果显示,摄取一百万策略的性能开销在150秒以下。具体来说,超过一半的开销用于Parcel的系统开销,如数据上传、数据存储、数据加密等。数据摄取大约占开销的三分之一,静态分析仅需不到10秒。
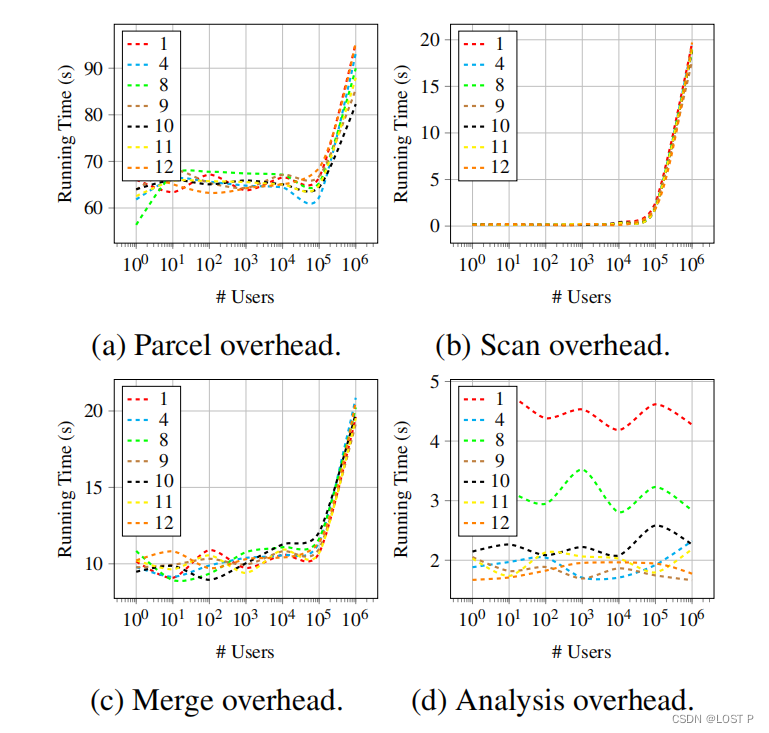
我们还基于不同用户数量的开销进行了基准测试,如图8所示。Parcel开销指的是Parcel平台诸如数据加载或传输等引起的开销。扫描开销指的是寻找不比守护策略更严格的策略所花费的时间。合并开销指的是在TEE内合并数据集所用的时间。分析开销指的是运行PRIVANALYZER的开销。如图8所示,当用户数量较小时,Parcel开销、扫描开销和合并开销相对稳定,然后随用户数量线性增长。请注意,我们使用log10刻度来表示x轴。曲线是指数的,但增长率是线性的。除了静态分析之外的所有实验:开销 = O(#用户)+ O(1)。不出所料,对于固定程序,分析开销几乎是恒定的。结果显示,PRIVGUARD能够扩展到大量用户和数据集。
5 相关工作
相关工作分为两大类:(1)隐私政策的形式化;(2)隐私政策的执行。
隐私政策形式化。Tschantz等人使用修改后的马尔可夫决策过程来形式化隐私政策中的目的限制。Chowdhury等人]提出了一种基于FOTL子集的政策语言,捕获HIPAA的要求。Lam等人证明,对于任何符合HIPAA中明显模式的隐私政策,都存在一个有限的代表性医院数据库,该数据库展示了法律在所有可能的医院中的应用方式。Gerl等人引入LPL,一个可扩展的分层隐私语言,允许表达和执行新的隐私属性,如用户同意。Trabelsi等人基于XACML提出PPL粘性政策,用于表达和处理Web 2.0中的隐私政策。Azraoui等人专注于隐私政策的问责性方面,并将PPL扩展到A-PPL。
隐私政策合规性执行。超越隐私规定的形式化,近期研究还探索了执行形式化隐私政策的技术。Chowdhury等人提议使用时序模型检查来实时监控隐私政策。Sen等人引入GROK,一个为类似Map-Reduce的大数据系统设计的数据清单。PODS/SOLID]专注于将数据控制权还给数据所有者。在PPL政策引擎中,政策决策点(PDP)匹配数据管理员的隐私政策和数据主体的隐私偏好来决定合规性。隐私政策通过政策执行点执行。与我们的工作相比,PPL政策引擎在复杂数据分析任务中提供了有限的细粒度隐私合规支持,因为其执行引擎依赖于直接的触发器到行动的翻译。此外,PPL没有提供严格的正确性证明。在其扩展A-PPL和SPECIAL项目中也存在类似差异。我们的工作提供了解决这些问题所必需的执行机制,并可以视为迈向Maniatis等人提出的宏大挑战的第一步。
6 限制
我们希望指出PRIVGUARD的几个限制,并认为缓解这些限制是重要的未来方向。
首先,PRIVGUARD容易受到内部攻击。在我们的威胁模型中,我们假设数据分析师是诚实但鲁莽的,可能无意中违反隐私法规。这样的威胁模型应该足以捕获大多数现实世界的用例。然而,防御恶意分析师要困难得多。由于PRIVANALYZER是作为一个Python库实现的,因此有可能编写恶意程序来规避其分析。例如,一个恶意程序可能动态地重新定义PRIVANALYZER的runFilter函数(在我们之前的示例中使用)以总是报告策略已经得到满足。在程序加载之前,通过语法分析检测动态语言特性的使用可以解决这个问题。然而,由于Python中动态特性众多,检测所有这类攻击非常具有挑战性。
其次,许多PURPOSE属性不能被PRIVGUARD自动执行,因为它们与程序属性无关。例如,一个程序是否代表“合法利益”只能由人类判断,因此任何完全自动化的系统都无法在没有人工描述的情况下做出决定。为了应对这个挑战,我们选择记录这些属性,并使日志可供人工审计。我们强调的是,我们的目标是最小化而不是消除合规过程中的人力努力。
第三,PRIVGUARD依赖于TEE,如AMD SEV,来防御不受信任的第三方。然而,最近的研究发现主流TEE中存在几个漏洞,这削弱了它们对恶意第三方的保护。尽管超出了讨论范围,我们还是想向潜在用户提及这些可能的漏洞。
7 结论与未来工作
在本文中,我们提出了PRIVGUARD,一个旨在促进隐私法规合规性的框架。核心组件是PRIVANALYZER,一个支持程序与政策之间合规性验证的静态分析器。我们在Parcel上原型化了PRIVGUARD,Parcel是一个工业级数据治理平台。我们相信PRIVGUARD有潜力大幅降低隐私法规合规性的成本。
我们还想追求PRIVGUARD未来版本的几个方向。首先,我们希望进一步改进PRIVGUARD API的可用性,考虑到人机交互(HCI)要求,以便非专家也能轻松指定他们自己的隐私偏好。其次,PRIVGUARD目前采用一次性同意策略,这覆盖了大多数当前的应用场景,但正如中指出的,这种策略有几个缺陷。这个限制可以通过允许数据管理员在数据收集后向数据主体请求动态同意来解决,如中所描述。


















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










