




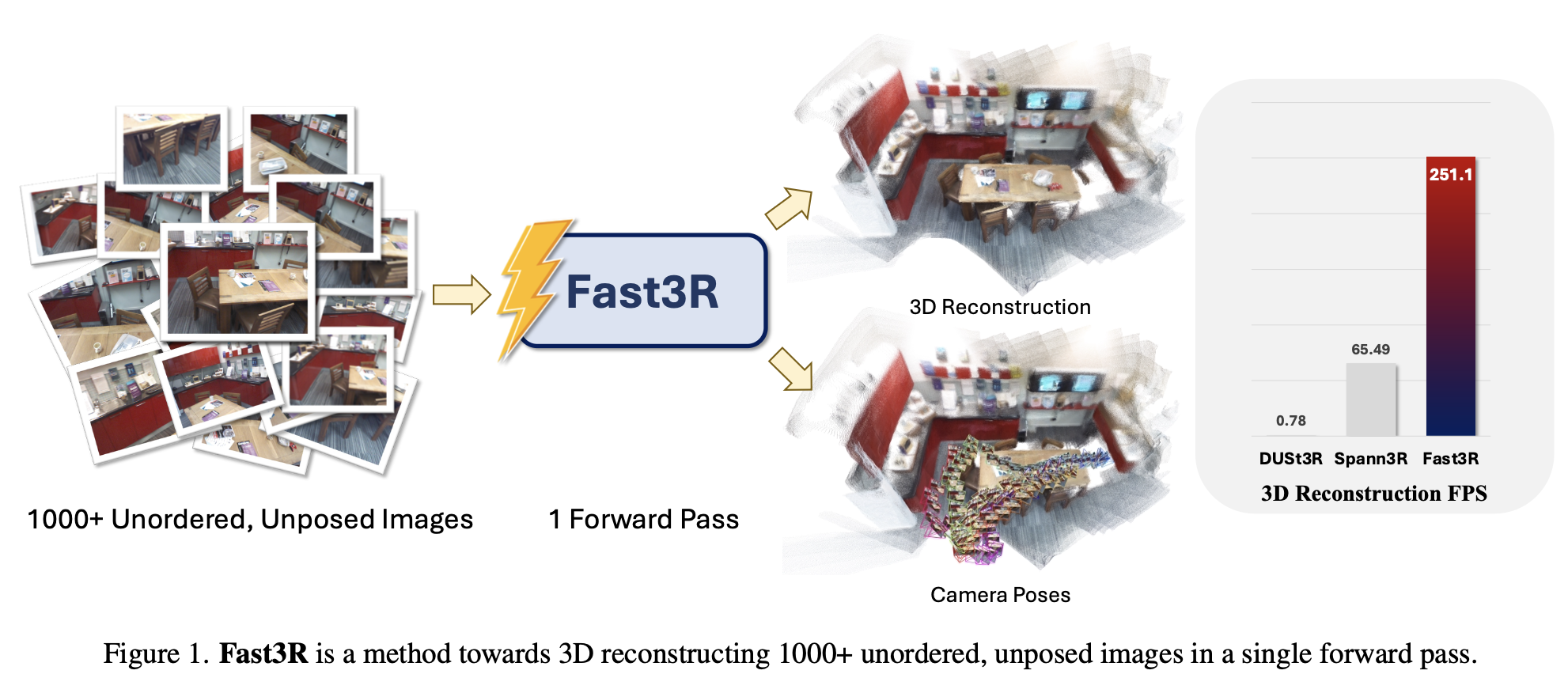
论文介绍:Fast3R,多视图 3D 重建的新范式
在计算机视觉领域,多视图 3D 重建(Multi-view 3D Reconstruction)长期以来都是一个核心挑战。它旨在从一系列不同视角的二维图像中,重建出精确的三维几何结构和相机姿态。传统方法,如基于运动结构法(SfM)和多视图立体视觉(MVS)的流水线,通常需要复杂的预处理和迭代对齐步骤,尤其是在处理大规模、非结构化的图像集时,其效率和可扩展性会受到严重限制。
正是在这样的背景下,Fast3R(Fast 3D Reconstruction) 应运而生。它提出了一种革命性的方法,通过引入基于 Transformer 的架构,从根本上改变了 3D 重建的范式,实现了在单次前向传播中处理上千张图像的壮举,为大规模 3D 重建开启了全新的可能性。
核心原理与架构
Fast3R 的成功并非偶然,其背后是精心设计的模型架构和训练策略。它的核心思想是:与其将多视图 3D 重建任务拆解为无数个耗时且冗余的“成对”处理和对齐步骤,不如从一开始就将其作为一个整体来解决。正如 Fast3R 论文摘要中所述,该方法是一个“对 DUSt3R 的一种新颖的多视图泛化,通过并行处理许多视图来实现高效且可扩展的 3D 重建”[^1]。
1. 基于 Transformer 的多视图处理
Fast3R 的模型架构借鉴了在大型语言模型中取得巨大成功的 Transformer 结构。它将输入的 N 张图像作为一个整体序列来处理,而非像 DUSt3R 那样两两配对。根据论文描述,“Fast3R 的 Transformer-based 架构在单次前向传播中处理 N 张图像,绕过了迭代对齐的需求”[^1]。这种处理方式使得模型能够:
- 并行处理: 所有图像在一次前向传播中被同时处理,极大地提高了推理速度。
- 捕获全局上下文: Transformer 的自注意力机制(self-attention)允许模型直接学习图像序列中的长程依赖关系。这意味着每一张图像不仅能从自身中学习信息,还能直接利用序列中所有其他图像提供的上下文信息,从而更精确地推断出 3D 结构。
2. 模型输出:从全局到局部
Fast3R 模型最直接、最基础的输出是两种类型的点云,它们共同构成了重建的核心:
- 全局点云 (X_GX\_{G}X_G):这是模型最关键的输出。它直接在统一的全局坐标系中(通常是第一张图片的坐标系)预测出整个场景的 3D 点云。这一步骤就直接完成了全局对齐,彻底绕过了 DUSt3R 中最复杂、最耗时的拼接过程。
- 局部点云 (X_LX\_{L}X_L):同时,模型也预测出每一张图片在自身局部坐标系中的点云。这些局部点云可以被视为全局点云的补充,正如论文图 14 所解释的,“全局点图为点的提供了很好的锚点,而局部点图则利用这些锚点(通过将它们与全局点图对齐)来提供更精确的点位置”[^1]。
可以把 全局点云 理解为一个建筑的整体蓝图,它提供了所有结构的主体框架和位置信息;而 局部点云 则是对每一块区域的详细测量,用来填充和校正蓝图中的细节,确保最终重建的精准度。
训练策略:位置插值与泛化能力
一个引人深思的问题是,如果模型在训练时只使用少量图片(例如 20 张),它如何在推理时处理多达上千张的图片,并保证效果?Fast3R 论文给出的答案是 “位置插值”(Position Interpolation) 这一巧妙的训练策略。
1. 训练数据与任务
Fast3R 的训练数据并非专门构建的 1000 张图片样本,而是使用了现有的、包含真实 3D 扫描数据的高质量数据集,如 CO3D、ScanNet++、ARKitScenes 等。这些数据集提供了图像、相机参数以及对应的 3D 真实点云。在训练时,模型被设定为从一个包含 1000 个可能图像索引的大型索引池中,随机采样 20 个索引。
模型的训练任务是:
- 点云回归: 学习预测出与这些图片对应的全局点云和局部点云。
- 损失函数: 通过计算预测的点云与数据集中提供的真实点云之间的距离来优化模型。论文中用到的 损失函数 如下:
L=∑i=1NLglobal(XGi,XG,gti)+λ∑i=1NLlocal(XLi,XL,gti)\mathcal{L} = \sum_{i=1}^N \mathcal{L}_{\text{global}}(X_G^i, X_{G, \text{gt}}^i) + \lambda \sum_{i=1}^N \mathcal{L}_{\text{local}}(X_L^i, X_{L, \text{gt}}^i)L=




















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










