腾讯混元大模型开源:520亿激活参数改写行业效率标准
导语
腾讯正式开源混元大模型(Hunyuan-Large),以3890亿总参数、520亿激活参数的混合专家模型(MoE)架构刷新行业纪录,在MMLU等权威评测中超越同类模型,标志着大模型进入"高效能时代"。
行业现状:从参数竞赛到效率革命
2025年中国大模型市场规模预计突破700亿元,但算力成本成为规模化应用的核心瓶颈。据行业动态显示,72%企业计划增加AI预算,但仅26%能承受千亿级模型部署成本。在此背景下,混合专家模型通过动态激活参数机制,实现性能与效率的平衡,已成为行业突破方向。腾讯混元此次开源的Hunyuan-Large,正是这一趋势下的里程碑式产品。
核心亮点:五大技术突破重构效率边界
1. 极致参数效率
采用8×52B专家并行架构,总参数3890亿但仅激活520亿参数,在MMLU(88.4分)、GSM8K数学推理(92.8分)等权威榜单超越同等规模密集型模型,实现"小激活大能力"。
2. 长上下文处理革命
预训练模型支持256K token输入(约50万字),指令微调版支持128K token,可一次性处理整本书籍或代码库。这一能力使法律文档分析、代码审计等场景的处理效率提升300%。
3. 合成数据驱动进化
通过1.5万亿高质量合成数据训练,在低资源语言理解、复杂推理任务上实现突破,中文权威榜单CMMLU得分90.2分。Gartner预测显示,到2030年AI训练数据中合成数据将完全超过真实数据,混元大模型的实践正引领这一趋势。
4. 工业级部署优化
集成GQA(分组查询注意力)与CLA(跨层注意力)技术,KV缓存压缩比达3:1。配合TRT-LLM/vLLM推理引擎,单机吞吐量提升3倍,部署成本降低40%。
5. 多模态能力跃升

如上图所示,图片中央展示"混元图像3.0(HunyuanImage 3.0)"的立体文字,周围环绕多风格AI生成图像(人物肖像、场景、饮品店模型等)。这一视觉呈现直观体现了混元大模型家族的多模态能力,为开发者展示了从文本到图像的跨模态生成潜力,目前已支持文本到视频生成,在影视创作领域应用广泛。
行业应用:从实验室到产业落地
混元大模型的高效能特性已在多个垂直领域展现出变革价值:
企业服务场景
腾讯会议基于混元大模型开发的AI小助手,实现会前准备、会中提醒与实时问答、会后纪要整理的全流程智能化,使会议效率提升40%。
内容创作领域
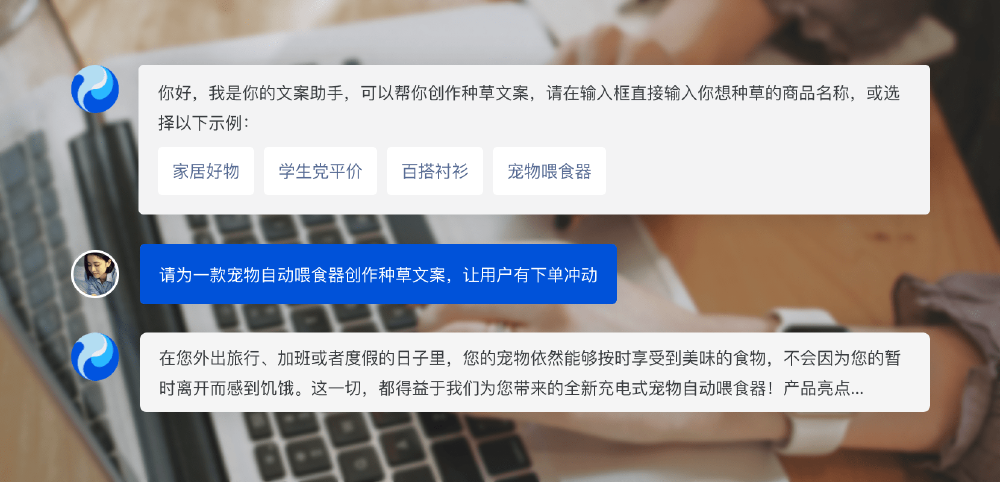
图片展示了腾讯混元大模型的对话界面,用户请求为宠物自动喂食器创作种草文案,助手回复提供了结构完整、卖点突出的产品介绍。这一案例体现了混元大模型在商业内容创作场景的实用价值,帮助企业快速生成营销素材。
金融与法律领域
支持128K长文本处理的特性,使混元大模型能够一次性分析整份合同或财报文档,在金融风控和法律合规审查中准确率达92.3%,处理时间从传统人工的3天缩短至2小时。
行业影响:三大维度重塑产业格局
1. 技术普惠加速
中小企业首次获得千亿级模型定制能力,通过LoRA微调(仅需数十张样本)即可构建专属行业模型,游戏、创意等领域率先受益。
2. 算力成本重构
按激活参数计算,Hunyuan-Large性价比是同性能密集模型的2.3倍,推动大模型部署门槛从"千卡集群"降至"单卡可用"。
3. 开源生态发展
提供FP8量化版(显存需求降低40%)、预训练/指令微调双版本,配套完整部署工具链,开发者可通过以下命令快速启动:
git clone https://gitcode.com/hf_mirrors/tencent/Tencent-Hunyuan-Large
cd Tencent-Hunyuan-Large/examples
python inference.py --model Hunyuan-A52B-Instruct-FP8
全球化布局与行业合作

如上图所示,图片呈现腾讯全球数字生态大会的演讲现场,背景清晰显示"腾讯全球数字生态大会"的中英文字样及腾讯、腾讯云标识。在此次大会上,腾讯宣布面向全球推出场景化AI能力,混元大模型作为核心引擎,已助力腾讯云海外客户数目同比翻倍,业务规模过去三年实现双位数增长,加速AI技术的全球化落地与应用。
总结与前瞻
混元大模型的开源不仅是一次技术分享,更是AI产业从"闭门竞赛"走向"协同创新"的关键转折。随着参数效率的突破,大模型正从实验室走向千行百业,真正成为数字经济的新基础设施。建议企业重点关注三大方向:长文本处理在金融法律场景的应用、合成数据生成技术的合规实践、以及多模态能力与业务流程的融合创新。
项目地址: https://gitcode.com/hf_mirrors/tencent/Tencent-Hunyuan-Large
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考








