







概念
LRU (Least Recently Used-最近最少使用) 是一种常见的缓存淘汰算法,其核心思想是:当缓存空间不足时,优先淘汰最久未被使用的数据。它基于"局部性原理"——最近被访问的数据未来更可能被再次访问。
核心特点
- 有序性:维护数据项的访问顺序
- 快速访问:需要快速查找、插入和删除
- 淘汰机制:缓存满时删除最久未使用的数据
时间复杂度要求
- 查找操作:O(1)
- 插入操作:O(1)
- 删除操作:O(1)
实现方案
使用 双向链表 + 哈希表 的组合:
- 双向链表:维护访问顺序(头节点存放最近访问,尾节点存放最久未访问)
- 哈希表:提供O(1)的键值查找能力
Java代码实现示例
import java.util.HashMap;
import java.util.Map;
public class LRUCache<K, V> {
// 双向链表节点
class Node {
K key;
V value;
Node prev;
Node next;
Node() {}
Node(K key, V value) {
this.key = key;
this.value = value;
}
}
// 缓存容量
private final int capacity;
// 哈希表用于快速查找
private final Map<K, Node> cache;
// 链表头尾指针
private final Node head, tail;
// 当前缓存大小
private int size;
public LRUCache(int capacity) {
this.capacity = capacity;
this.size = 0;
cache = new HashMap<>();
// 创建虚拟头尾节点(哨兵节点)
head = new Node();
tail = new Node();
head.next = tail;
tail.prev = head;
}
// 获取数据
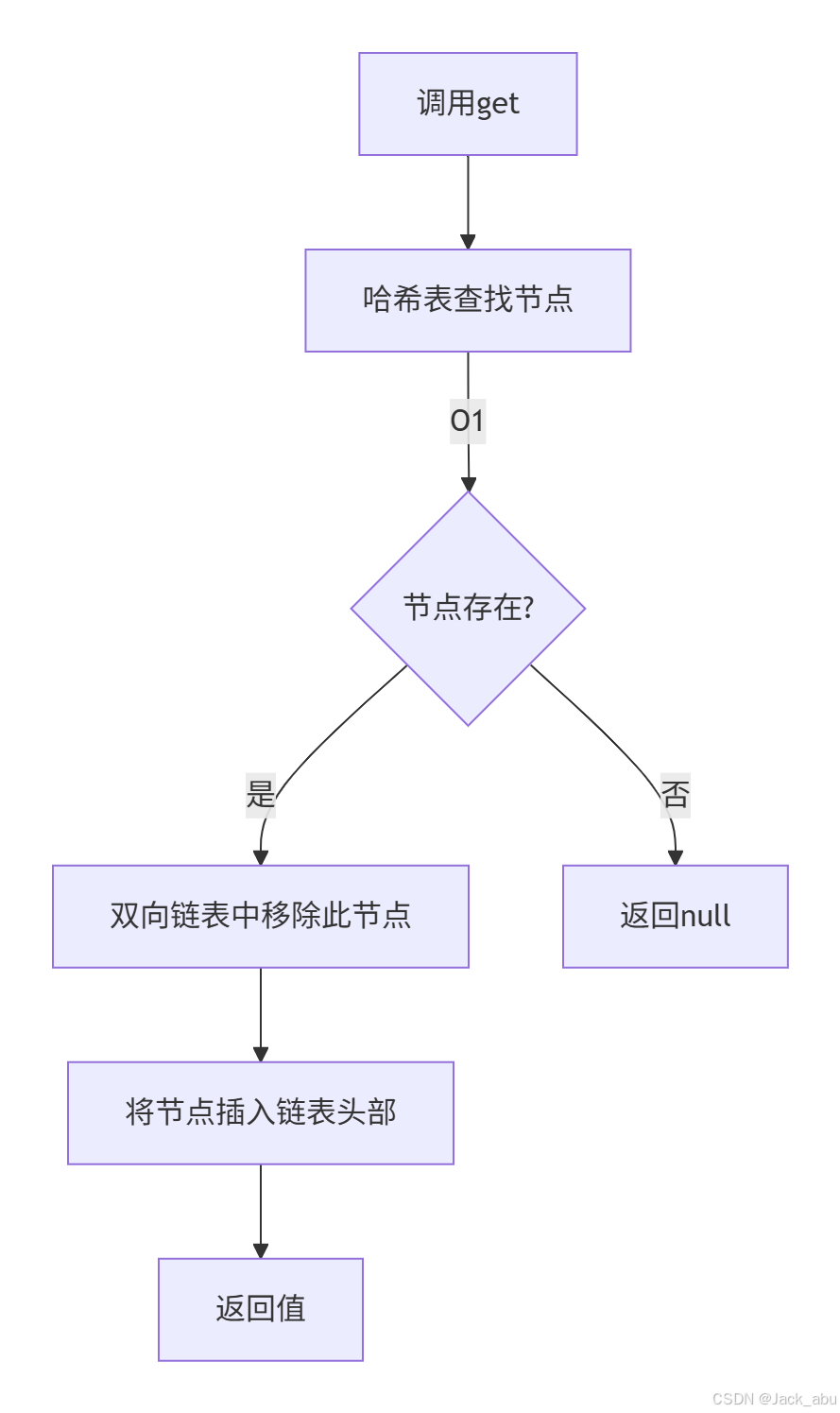
public V get(K key) {
Node node = cache.get(key);
if (node == null) return null;
// 移动到链表头部(表示最近使用)
moveToHead(node);
return node.value;
}
// 添加数据
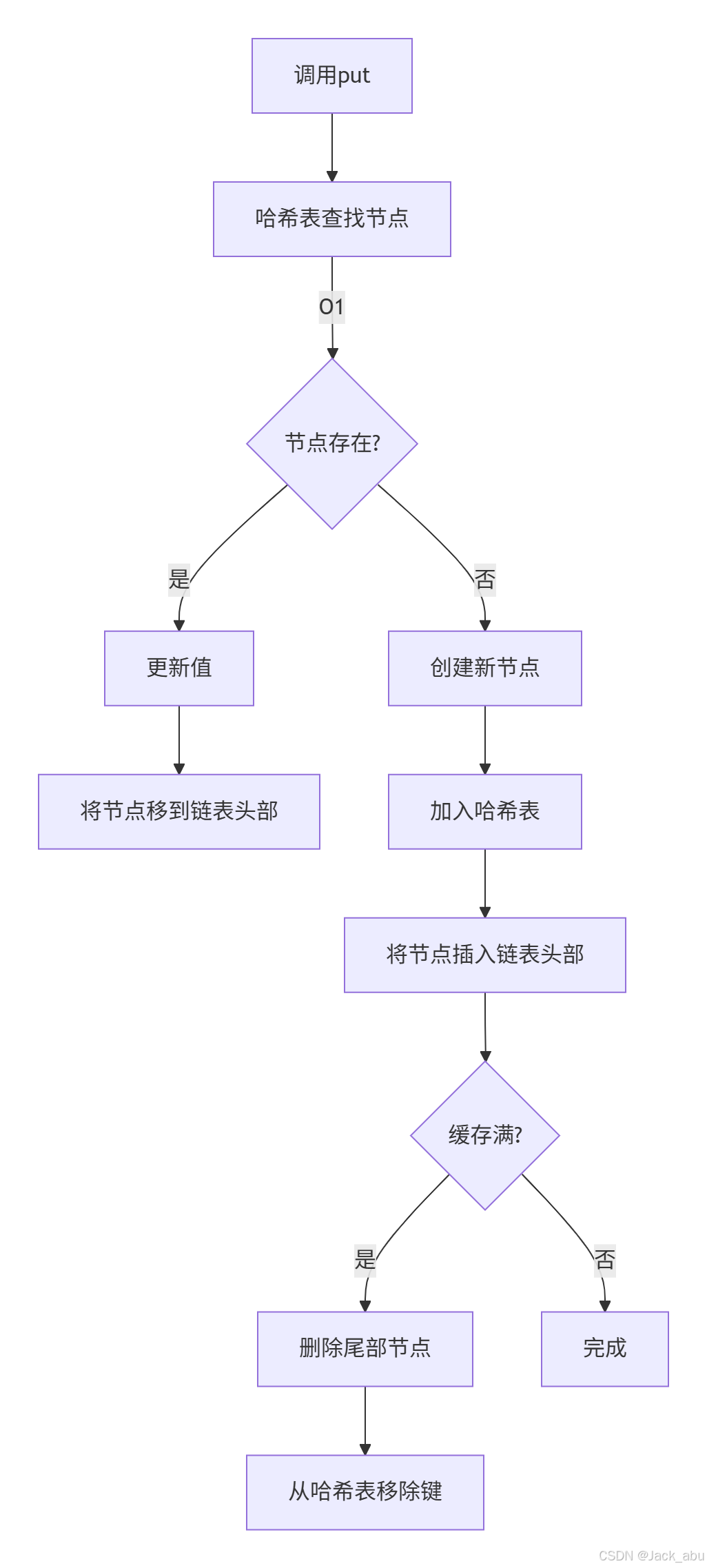
public void put(K key, V value) {
Node node = cache.get(key);
if (node != null) {
// 键已存在:更新值并移到头部
node.value = value;
moveToHead(node);
} else {
// 键不存在:创建新节点
Node newNode = new Node(key, value);
cache.put(key, newNode);
addToHead(newNode);
size++;
// 超出容量时删除尾部节点
if (size > capacity) {
Node removed = removeTail();
cache.remove(removed.key);
size--;
}
}
}
// === 辅助方法 ===
// 添加节点到头部
private void addToHead(Node node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// 从链表中移除节点
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
// 移动节点到头部
private void moveToHead(Node node) {
removeNode(node);
addToHead(node);
}
// 移除尾部节点(最久未使用)
private Node removeTail() {
Node node = tail.prev;
removeNode(node);
return node;
}
}
实现说明
-
数据结构选择
- 双向链表:维护访问顺序
- 哈希表:提供O(1)的键查找
-
哨兵节点
- 虚拟头节点(head)和尾节点(tail)简化边界操作
- 避免空指针检查和特殊处理
-
关键操作
-
// 插入新节点 head → newNode → nextNode ↑ ↑ head nextNode // 移动节点到头部 prevNode → node → nextNode → head → node → nextNode // 删除尾部节点 tail.prev → tail → 删除tail.prev -
时间复杂度
get(): O(1) (哈希查找 + 链表操作)put(): O(1) (哈希操作 + 链表操作)
使用示例
public class Main {
public static void main(String[] args) {
LRUCache<Integer, String> cache = new LRUCache<>(2);
cache.put(1, "Apple");
cache.put(2, "Banana");
System.out.println(cache.get(1)); // 返回 "Apple"
cache.put(3, "Cherry"); // 淘汰 key=2
System.out.println(cache.get(2)); // 返回 null
cache.put(4, "Durian"); // 淘汰 key=1
System.out.println(cache.get(1)); // 返回 null
System.out.println(cache.get(3)); // 返回 "Cherry"
System.out.println(cache.get(4)); // 返回 "Durian"
}
}
处理流程示意图
初始状态:
head ↔ tail
插入A:
head → A ↔ tail
插入B:
head → B ↔ A ↔ tail
访问A:
head → A ↔ B ↔ tail
插入C (容量满时):
1. 移除尾部B
2. head → C ↔ A ↔ tail
实际应用场景
- 数据库查询缓存
- 页面置换算法
- Redis内存管理
- 浏览器缓存管理
- CPU缓存系统
附:为什么要用双向列表+哈希表组合
LRU算法需要同时满足两个关键需求:
- 快速查找(O(1)时间复杂度)
- 快速维护访问顺序(O(1)移动/删除)
单数据结构无法同时满足:
| 数据结构 | 查找效率 | 维护顺序效率 | 问题 |
|---|---|---|---|
| 数组 | O(1)随机访问 | O(n)移动元素 | 移动元素成本高 |
| 单向链表 | O(n)查找 | O(1)移动节点 | 查找效率低下 |
| 哈希表 | O(1)查找 | 无法维护顺序 | 无序存储 |
| 双向链表 | O(n)查找 | O(1)移动/删除 | 查找效率低下 |
组合方案的优势:
- 哈希表:提供O(1)的键值查找能力
- 双向链表:提供O(1)的节点操作能力
- 快速移动节点到头部(最近使用)
- 快速删除尾部节点(淘汰最久未使用)
关键操作分析(O(1)时间复杂度):
1. 访问元素(get)
2. 插入元素(put)
为什么必须用双向链表?(单向链表的问题)
假设使用单向链表:
-
删除节点需要O(n)时间:
- 需要遍历找到前驱节点才能删除
- 伪代码:
// 删除node需要的前驱节点 Node prev = head; while(prev.next != node) { prev = prev.next; // O(n)遍历 } prev.next = node.next;
-
无法直接操作尾部节点:
- 删除LRU项时,无法快速访问前驱节点
关键实现细节解析
1. 节点删除(双向链表O(1))
private void removeNode(Node node) {
node.prev.next = node.next; // 前驱指向后继
node.next.prev = node.prev; // 后继指向前驱
}
2. 节点插入头部(双向链表O(1))
private void addToHead(Node node) {
// 新节点连接原首节点
node.next = head.next;
node.prev = head;
// 原首节点连接新节点
head.next.prev = node;
head.next = node;
}
设计决策总结
| 需求 | 解决方案 |
|---|---|
| O(1)查找 | 哈希表存储键到节点的映射 |
| O(1)插入新元素 | 哈希表插入 + 链表头部插入 |
| O(1)移动元素到前端 | 双向链表节点删除/插入 |
| O(1)删除最久未使用 | 双向链表尾部指针 + 哈希表同步删除 |
| 避免边界条件 | 虚拟头/尾节点(哨兵节点) |
这种经典的组合实现了时间复杂度与空间效率的最佳平衡(O(1)操作 + O(n)空间),是现代系统中实现LRU缓存的黄金标准。Java的LinkedHashMap也是基于相同的原理实现的。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












