






【更新记录】
- 2022年3月25日 更新原始内容
本文目录结构
Unity 是最受欢迎的游戏引擎之一,不仅用于视频游戏开发,还被电影和汽车等行业采用。 Unity 提供工具来创建具有可定制物理、风景和角色的虚拟模拟环境。 Unity 机器学习代理工具包 (ML-Agents) 是一个开源项目,使开发人员能够针对在 Unity 上创建的环境训练强化学习 (RL) 智能体。
强化学习是机器学习 (ML) 的一个领域,它教导软件代理如何在环境中采取行动,以最大限度地实现长期目标。有关更多信息,请参阅 Amazon SageMaker RL – 使用 Amazon SageMaker 进行托管强化学习。 ML-Agents 正在成为许多游戏公司中越来越流行的工具,用于游戏关卡难度设计、错误修复和作弊检测等用例。目前,ML-Agents 用于在本地训练代理,无法扩展以有效使用更多计算资源。在获得经过训练的模型之前,您必须在本地 Unity 引擎上训练 RL 代理很长时间。该过程耗时且不可扩展以处理大量数据。
在这篇博文中,我们通过将 ML-Agents Unity 接口与 Amazon SageMaker RL 集成来演示解决方案,使您能够以完全托管和可扩展的方式在 Amazon SageMaker 上训练 RL 代理。
1. Overview of solution
SageMaker 是一项完全托管的服务,可实现快速模型开发。 它提供了许多内置功能来帮助您进行训练、调优、调试和模型部署。 SageMaker RL 构建在 SageMaker 之上,添加了预构建的 RL 库并使其易于与不同的仿真环境集成。 您可以使用 TensorFlow 和 PyTorch 等内置深度学习框架和 RLlib 库中的各种内置 RL 算法来训练 RL 策略。 训练和推理的基础设施完全由 SageMaker 管理,因此您可以专注于 RL 制定。 SageMaker RL 还提供了一组 Jupyter 笔记本,展示了机器人、运筹学、金融等领域的各种领域 RL 应用。
下图说明了我们的解决方案架构。

在这篇文章中,我们通过与示例 Unity 环境进行交互,详细介绍了在 SageMaker 上训练 RL 代理的细节。 要访问本文的完整笔记本,请参阅 GitHub 上的 SageMaker 笔记本示例。
设置环境
首先,我们导入所需的 Python 库并为权限和配置设置环境。 以下代码包含设置 Amazon Simple Storage Service (Amazon S3) 存储桶、定义训练作业前缀、指定训练作业位置以及创建 AWS Identity and Access Management (IAM) 角色的步骤:
import sagemaker
import boto3
# set up the linkage and authentication to the S3 bucket
sage_session = sagemaker.session.Session()
s3_bucket = sage_session.default_bucket()
s3_output_path = 's3://{}/'.format(s3_bucket)
print("S3 bucket path: {}".format(s3_output_path))
# create a descriptive job name
job_name_prefix = 'rl-unity-ray'
# configure where training happens – local or SageMaker instance
local_mode = False
if local_mode:
instance_type = 'local'
else:
# If on SageMaker, pick the instance type
instance_type = "ml.c5.2xlarge"
# create an IAM role
try:
role = sagemaker.get_execution_role()
except:
role = get_execution_role()
print("Using IAM role arn: {}".format(role))
2. Building a Docker container
SageMaker 使用 Docker 容器来运行脚本、训练算法和部署模型。 Docker 容器是一个独立的软件包,用于管理所有代码和依赖项,它包含运行应用程序所需的一切。 我们首先在包含 Ray 依赖项的预构建 SageMaker Docker 映像之上构建,然后安装所需的核心包:
- gym-unity – Unity 提供了一个包装器,将 Unity 环境包装到一个健身房界面中,这是一个开源库,可让您访问一组经典的 RL 环境
- mlagents-envs – 提供 Python API 以允许与 Unity 游戏引擎直接交互的包
根据机器的状态,Docker 构建过程可能需要长达 10 分钟。 有关所有预构建的 SageMaker RL Docker 映像,请参阅 GitHub 存储库。
3. Unity environment example
在这篇文章中,我们使用了一个名为 Basic 的简单示例 Unity 环境。 在下面的可视化中,我们控制的代理是向左或向右移动的蓝色框。 对于它采取的每一步,它都会花费代理一些能量,从而产生小的负奖励(-0.01)。 绿球是具有固定位置的目标。 智能体在绿球之间随机初始化,并在与绿球碰撞时收集奖励。 大绿球提供+1的奖励,小绿球提供+0.1的奖励。 该任务的目标是训练智能体朝着提供最多累积奖励的球移动。

4. Model training, evaluation, and deployment
在本节中,我们将引导您完成训练、评估和部署模型的步骤。
编写训练脚本
在启动 SageMaker RL 训练作业之前,我们需要指定训练过程的配置。 它通常在笔记本之外的单个脚本中实现。 训练脚本定义了 RL 训练的输入(Unity 环境)和算法。 以下代码显示了脚本的外观:
import json
import os
import gym
import ray
from ray.tune import run_experiments
from ray.tune.registry import register_env
from sagemaker_rl.ray_launcher import SageMakerRayLauncher
from mlagents_envs.environment import UnityEnvironment
from mlagents_envs.exception import UnityWorkerInUseException
from mlagents_envs.registry import default_registry
from gym_unity.envs import UnityToGymWrapper
class UnityEnvWrapper(gym.Env):
def __init__(self, env_config):
self.worker_index = env_config.worker_index
if 'SM_CHANNEL_TRAIN' in os.environ:
env_name = os.environ['SM_CHANNEL_TRAIN'] +'/'+ env_config['env_name']
os.chmod(env_name, 0o755)
print("Changed environment binary into executable mode.")
# Try connecting to the Unity3D game instance.
while True:
try:
unity_env = UnityEnvironment(
env_name,
no_graphics=True,
worker_id=self.worker_index,
additional_args=['-logFile', 'unity.log'])
except UnityWorkerInUseException:
self.worker_index += 1
else:
break
else:
env_name = env_config['env_name']
while True:
try:
unity_env = default_registry[env_name].make(
no_graphics=True,
worker_id=self.worker_index,
additional_args=['-logFile', 'unity.log'])
except UnityWorkerInUseException:
self.worker_index += 1
else:
break
self.env = UnityToGymWrapper(unity_env)
self.action_space = self.env.action_space
self.observation_space = self.env.observation_space
def reset(self):
return self.env.reset()
def step(self, action):
return self.env.step(action)
class MyLauncher(SageMakerRayLauncher):
def register_env_creator(self):
register_env("unity_env", lambda config: UnityEnvWrapper(config))
def get_experiment_config(self):
return {
"training": {
"run": "PPO",
"stop": {
"timesteps_total": 10000,
},
"config": {
"env": "unity_env",
"gamma": 0.995,
"kl_coeff": 1.0,
"num_sgd_iter": 20,
"lr": 0.0001,
"sgd_minibatch_size": 100,
"train_batch_size": 500,
"monitor": True, # Record videos.
"model": {
"free_log_std": True
},
"env_config":{
"env_name": "Basic"
},
"num_workers": (self.num_cpus-1),
"ignore_worker_failures": True,
}
}
}
if __name__ == "__main__":
MyLauncher().train_main()
训练脚本有两个组成部分:
- UnityEnvWrapper – Unity 环境存储为二进制文件。 要加载环境,我们需要使用 Unity ML-Agents Python API。 UnityEnvironment 采用环境的名称并返回一个交互式环境对象。 然后,我们使用 UnityToGymWrapper 包装对象,并返回一个可使用 Ray-RLLib 和 SageMaker RL 训练的对象。
- MyLauncher – 此类继承 SageMakerRayLauncher 基类,以便 SageMaker RL 应用程序使用 Ray-RLLib。 在类中,我们注册了 Ray 可以识别的环境,并在训练期间指定了我们想要的配置。 示例超参数包括环境名称、累积奖励中的折扣因子、模型的学习率以及运行模型的迭代次数。 有关常用超参数的完整列表,请参阅常用参数。
训练模型
设置配置和模型自定义后,我们就可以开始 SageMaker RL 训练作业了。 请参阅以下代码:
metric_definitions = RLEstimator.default_metric_definitions(RLToolkit.RAY)
estimator = RLEstimator(entry_point="train-unity.py",
source_dir='src',
dependencies=["common/sagemaker_rl"],
image_name=custom_image_name,
role=role,
train_instance_type=instance_type,
train_instance_count=1,
output_path=s3_output_path,
base_job_name=job_name_prefix,
metric_definitions=metric_definitions,
hyperparameters={
# customize Ray parameters here
}
)
estimator.fit(wait=local_mode)
job_name = estimator.latest_training_job.job_name
print("Training job: %s" % job_name)
在代码中指定了一些参数:
- entry_point – 我们编写的训练脚本的路径,用于指定训练过程
- source_dir – 除了入口点文件之外,具有其他训练源代码依赖项的目录的路径
- dependencies - 目录的路径列表,其中包含要导出到容器的附加库
此外,我们还说明了容器镜像名称、训练实例信息、输出路径和选择的指标。我们还可以使用 hyperparameters 参数自定义任何与 Ray 相关的参数。我们通过调用 estimator.fit 启动 SageMaker RL 训练作业,并根据训练脚本中的规范启动模型训练过程。
在较高的层次上,训练作业会启动一个神经网络,并朝着智能体获得更高奖励的方向逐渐更新网络。通过多次试验,代理最终学会了如何有效地导航到高回报的位置。 SageMaker RL 处理整个过程,并允许您在 SageMaker 控制台的训练作业页面中查看训练作业状态。
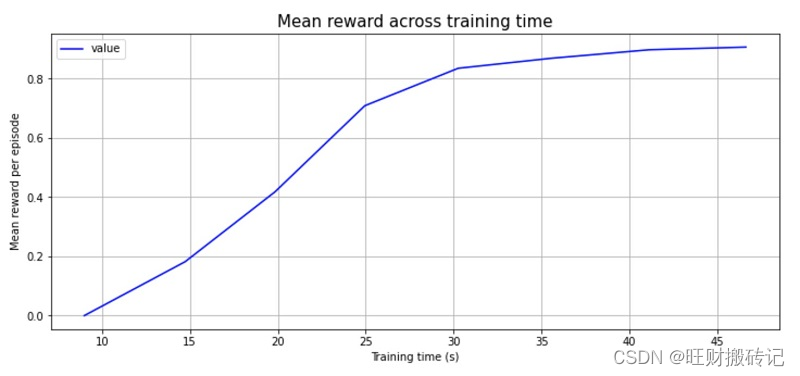
还可以通过检查 Amazon CloudWatch 中记录的训练日志来监控模型性能。由于任务的简单性,该模型在不到 1 分钟的时间内完成了大约 800 集(代理到达目标球的次数)的训练(10,000 次代理移动)。下图显示收集到的平均奖励收敛于 0.9 左右。代理可以从这个环境中获得的最大奖励是 1,每一步花费 0.01,因此平均奖励在 0.9 左右似乎是最优策略的结果,表明我们的训练过程是成功的!
5. Evaluating the model
当模型训练完成后,我们可以加载训练好的模型来评估它的性能。 与训练脚本中的设置类似,我们使用健身房包装器包装 Unity 环境。 然后我们通过加载训练好的模型来创建一个代理。
为了评估模型,我们使用固定的代理和目标初始化针对环境多次运行经过训练的代理,并将代理在每集的每一步收集的累积奖励相加。
在五个情节中,平均情节奖励为 0.92,最大奖励为 0.93,最小奖励为 0.89,这表明经过训练的模型确实表现良好。
部署模型
我们可以使用 SageMaker 模型部署 API 只需几行代码即可部署经过训练的 RL 策略。 您可以传递输入并根据策略得出最佳操作。 输入形状需要与来自环境的观察输入形状相匹配。
对于 Basic 环境,我们部署模型并将输入传递给预测器:
from sagemaker.tensorflow.model import TensorFlowModel
model = TensorFlowModel(model_data=estimator.model_data,
framework_version='2.1.0',
role=role)
predictor = model.deploy(initial_instance_count=1,
instance_type=instance_type)
input = {"inputs": {'observations': np.ones(shape=(1, 20)).tolist(),
'prev_action': [0, 0],
'is_training': False,
'prev_reward': -1,
'seq_lens': -1
}
}
result = predictor.predict(input)
print(result['outputs']['actions'])
该模型预测对应于左移或右移的指标。 蓝盒代理的推荐移动方向始终指向较大的绿球。
6. Cleaning up
完成模型运行后,调用 predictor.delete_endpoint() 删除模型部署端点以避免产生未来费用。
7. Customizing training algorithms, models, and environments
除了上述用例之外,我们鼓励您探索此解决方案支持的自定义功能。
在前面的代码示例中,我们将近端策略优化 (PPO) 指定为训练算法。 PPO 是一种流行的 RL 算法,其性能与最先进的方法相当,但实现和调整要简单得多。根据您的用例,您可以通过从已在 RLLib 中实现的综合算法列表中选择或从头构建自定义算法来选择最适合的算法进行训练。
默认情况下,RLLib 应用预定义的卷积神经网络或全连接神经网络。但是,您可以为训练和测试创建自定义模型。按照 RLLib 中的示例,您可以通过调用 ModelCatalog.register_custom_model 注册自定义模型,然后使用 custom_model 参数引用新注册的模型。
在我们的代码示例中,我们调用了一个名为 Basic 的预定义 Unity 环境,但您可以尝试使用其他预构建的 Unity 环境。但是,在撰写本文时,我们的解决方案仅支持单代理环境。构建新环境时,通过调用 register_env 进行注册,并使用 env 参数引用环境。
本文翻译自: https://aws.amazon.com/cn/blogs/machine-learning/training-a-reinforcement-learning-agent-with-unity-and-amazon-sagemaker-rl/



















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












