



一文讲完NPU计算与调度机制
NPU架构
NPU架构组成
- NPU网络推理的执行分为几个层级:
- 应用层:编译器可以将多个神经网络模型分布单个或者多个stream
- 中间层:调度负责将具体的任务负载从各个stream中提取出来放到调度队列
- 底层:底层驱动和运行时调度器将任务分配到NPU硬件中进行执行。
- NPU硬件架构:单个计算核心、多个簇(Cluster)以及异构架构等。
- 计算核心是由调度器以及处理单元(Processing Element,PE)阵列组成
- cluster则有多个计算核心组成
- 异构架构中除了有PE阵列单元负责卷积以及矩阵操作之外,还有支持向量运算的向量计算单元等
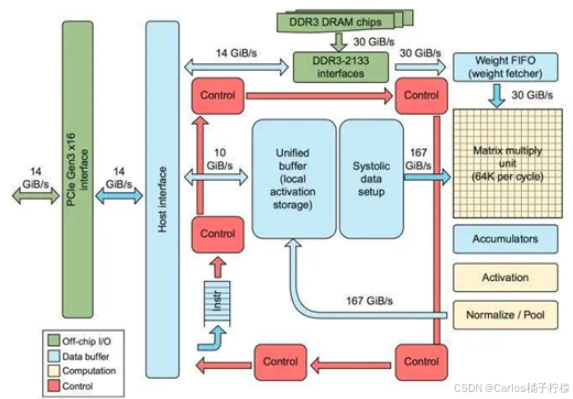
- 以TPU为例,其主要计算资源为:
- Matrix Multiply Unit:矩阵乘单元
- Accumulators:存储矩阵乘加输出的中间结果
- Activation:激活单元(处理CNN中的激活函数,引入非线性特征,选择重要特征,抑制次要特征,防止梯度消失)
- Unified Buffer:统一缓存
- 当前市场上主流AI芯片,常用的架构有以下几种形态:
-
- GEMM加速架构(TensorCore from Nvidia, Matrix Core from AMD);
-
- CGRA (初创公司);
-
- Systolic Array (Google TPU);
-
- Dataflow (Wave, Graphcore,初创公司);
-
- Spatial Dataflow (Samba Nova, Groq);
-
- Sparse架构 (Inferentia)
-
NPU并行计算架构
- 异步指令流:
- Scalar 计算单元读取指令序列,并把向量计算、矩阵计算、数据搬运指令发送给对应的指令队列,Vector 计算单元、Cube 计算单元、DMA 搬运单元异步地并行执行接收到的指令(“异步并行”:将串行的指令流分解);
- 同步信号流:
- 指令间可能会存在依赖关系,为了保证不同指令队列间的指令按照正确的逻辑关系执行,Scalar 计算单元也会给对应单元下发同步指令;
- 计算数据流:
- DMA 搬入单元把数据搬运到 Local Memory,Vector/Cube 计算单元完成数据计算,并把计算结果回写到 Local Memory,DMA 搬出单元把处理好的数据搬运回 Global Memory。
NPU模型的计算过程
从内存角度看NPU计算
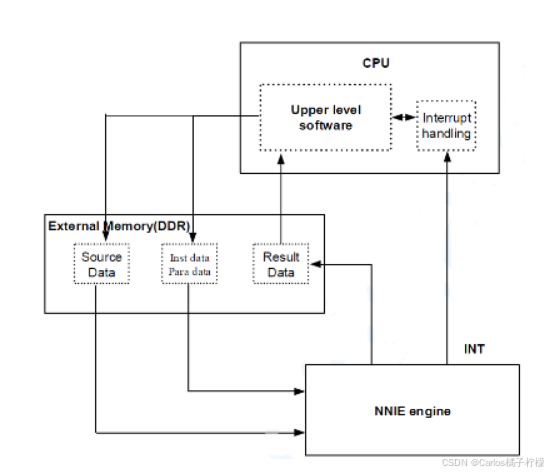
- 与NPU模块交互的单元主要有两部分,DDR内存和CPU处理器。
- NPU 硬件只能从 DDR 中获取数据,使用的DDR也可以是专用的内存。
- 调用 NPU 任务时,访问空间可cache 而且 CPU 可能会进行访问,为了保证 NPU 输入输出数据不被 CPU cache 干扰,需要刷cache将数据从cache刷到DDR,NPU 单元使用DDR中数据作为输入
- 数据收集存储在文件系统 -> 数据预处理缩放裁切归一化 -> 模型转换到NPU支持的格式 -> 模型加载 -> 配置NPU构建引擎 -> 分配内存 -> 创建上下文 -> 执行推理 -> 数据后处理
以Atlas平台NPU计算为例,AI Core内部的异步并行计算过程:
- Scalar计算单元读取指令序列,并把向量计算、矩阵计算、数据搬运指令发射给对应单元的指令队列,向量计算单元、矩阵计算单元、数据搬运单元异步的并行执行接收到的指令。
- 不同的指令间有可能存在依赖关系,为了保证不同指令队列间的指令按照正确的逻辑关系执行,Scalar计算单元也会给对应单元下发同步指令。
- AI Core内部数据处理的基本过程:DMA搬入单元把数据搬运到Local Memory,Vector/Cube计算单元完成数据计算,并把计算结果写回Local
Memory,DMA搬出单元把处理好的数据搬运回Global Memory。
从编程角度看NPU计算
- SPMD(Single-Program Multiple-Data)并行计算
- SPMD模式下,系统会启动一组进程,并行处理待处理的数据:
- 数据分片
- 被分发给不同进程处理
- 每个进程接独立地对这些分片进行并行计算(多个计算核心上运行)
- 多个AI Core共享相同的指令代码,每个核上的运行实例唯一的区别是block_idx不同
- 算子被调用时,所有的计算核心都执行相同的实现代码,入口函数的入参也是相同的。每个核上处理的数据地址需要在起始地址上增加GetBlockIdx()*BLOCK_LENGTH(每个block处理的数据长度)的偏移来获取。这样也就实现了多核并行计算的数据切分。
- SPMD模式下,系统会启动一组进程,并行处理待处理的数据:
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// get start index for current core, core parallel
xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
// pipe alloc memory to queue, the unit is Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}
...
}
// 实现核函数
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 初始化算子类,算子类提供算子初始化和核心处理等方法
KernelAdd op;
// 初始化函数,获取该核函数需要处理的输入输出地址,同时完成必要的内存初始化工作
op.Init(x, y, z);
// 核心处理函数,完成算子的数据搬运与计算等核心逻辑
op.Process();
}
NPU利用率
为什么NPU利用率会低?
- NPU低效率计算问题,从微架构设计领域,可以涉及到:
- 稀疏数据(稀疏DNN网络,或者稀疏输入输出数据)导致PE对大量零值数据的无效计算问题;
- PE之间由于软件硬件调度算法的效率低,PE之间互相依赖导致的延迟问题;
- 带宽与计算峰值能力不匹配导致的数据等待问题。
- NPU利用率的差异其实是内存墙和功耗墙的问题。
- 内存墙:当MAC计算单元愈来愈高,数据带宽的限制会导致数据传输速度不足,导致计算单元等待数据
- 功耗墙:MAC单元和DDR。堆MAC单元可以拉高算力,单MAC单元耗电量会提升,同时还需要高带宽的支撑,如果使用HBM(高带宽内存,DRAM垂直堆叠技术)会提高DDR的功耗
- 为了解决内存墙和功耗墙问题,业界常用的方法有两种:
- 存算一体,但会受到工艺节点瓶颈的限制;
- 减少数据搬运。
- NPU需要尽可能将算子数据将存放在local memory中,从而减少DRAM的访问次数。
- 英伟达和谷歌使用静态weight,其数据流的设计是通过在PE的RF(Register File)中存取weight,来减少读取weight产生的功耗。
- 权重从DRAM读取到寄存器,NPU在计算时尽可能利用寄存器中的权重,通常的实现是将ifmap输入特征图广播给所有的PE计算核心,部分和(Psum)将穿过所有的PE完成累加
NPU提升利用率的模型调优案例
- 案例1:NPU亲和优化器替换
- 在PyTorch混合精度模式下,每次迭代执行一次参数更新时(梯度更新),在Loss乘/除以缩放系数的过程中都会包含连续多个小算子(如add、mul、sqrt等)下发,由于小算子在NPU上计算快,导致算子在CPU上的下发成为性能的主要瓶颈。
- 频繁的算子调用、数据传输次数的增加
- 优化核心思想是将多个小算子融合为一个大算子
- 减少调度开销、减少内存访问、减少通信开销
- 在PyTorch混合精度模式下,每次迭代执行一次参数更新时(梯度更新),在Loss乘/除以缩放系数的过程中都会包含连续多个小算子(如add、mul、sqrt等)下发,由于小算子在NPU上计算快,导致算子在CPU上的下发成为性能的主要瓶颈。
optimizer = torch_npu.optim.NpuFusedSGD(
model.parameters(),
args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
- 案例2:集成模型
- 将多个模型进行合并,当多个模型的输入是一致的,可以将多个模型的backbone进行合并,或者在浅层的特征层进行合并
- 减少调度开销、减少内存访问、减少通信开销
- 案例3:避免使用硬件不友好算子
- 减少空洞卷积:在YOLO模型中,backbone和neck存在多个空洞卷积算子,空洞卷积算子是纸面计算量低,但是如果没有特定的执行硬件优化,其计算效率是很低的,所以在模型设计中需要考虑减少硬件不友好算子的使用。
- 分组卷积不分发:对于分组卷积不进行多核NPU分发计算,减少shuffle时多个NPU之间的内存数据访问。
- 小算子合并:计算较快、层间相邻的算子,可以选择在一个NPU完成,不再进行多核之间的分发计算,以减少通信和调度开销。
负载和设计多样性
计算受限算子\带宽受限算子
- 神经网络有多个计算强度各不相同的算子操作
- 计算强度是由
计算量 / 访存量就可以得到的,它表示此模型在计算过程中,每个字节内存交换到底用于进行多少次浮点运算,其单位是字节每秒浮点运算次数(FPLOPs)/字节(Byte) - 算子的计算强度越大,其内存使用效率越高。
- 计算强度是由
- 根据计算强度我们可以把不同的算子其分为计算受限(computing-bound)以及存储受限(memory-bound)两种类型。
- 计算受限的算子,通常对相同的数据执行多个操作,因此可以充分利用加速器中的处理元素。但是,它们不需要经常从内存中获取数据,而不需要充分利用内存缓冲区和带宽。
- 如矩阵计算、卷积算子、FFT快速傅里叶变换等。
- 存储受限的算子,数据可重用性很低,需要非常频繁地获取数据,计算资源没有得到充分利用,在等待数据。
- 如排序、矩阵转置、池化(Pooling)、全连接层(full connection)、激活函数(activation function)等算子以及自注意力(self-attention)等算子都是受内存限制类型的。
- 计算受限的算子,通常对相同的数据执行多个操作,因此可以充分利用加速器中的处理元素。但是,它们不需要经常从内存中获取数据,而不需要充分利用内存缓冲区和带宽。
NPU硬件的灵活设计
- NPU支持的调度灵活性通常可以分为四个维度:
- T 即数据切块大小(Tile sizes):
- 改变张量数据结构在多层次结构的缓冲区的每个级别中的数据切块的边界和宽高比。
- O 即循环顺序(Loop order):
- 改变每个数据切块的循环计算结构中循环执行顺序。
- P 即循环并行化(Loop parallelization):
- 改变每个数据切块的计算中从哪个张量维度(长、宽或者通道)进行并行化调度,这实际代表着数据的空间划分(例如跨多个PE划分)。
- S 即数组形状(Array shape):
- 改变加速器硬件资源即PE阵列的逻辑形状和集群方式。这决定了数据切块的数量和在PE阵列上映射的张量维度的最大切块尺寸。
- T 即数据切块大小(Tile sizes):
- 每一种灵活性都会带来多余的硬件面积,因此绝大多数NPU硬件架构只能支持以上几个维度当中的一个或几个
- 但是也会形成一个巨大的硬件映射空间,而针对于一个特定任务负载的每一个调度的决策在这个映射空间都是一个点,其结果都会得到不同的延时以及硬件利用率等性能。这些因素都给调度器和编译器带来了相当的复杂度。
- 以昇腾AI Core为例:
- AI Core 计算模式 Cube 单元能够高效地执行 MAC(矩阵乘加)操作,目前支持的矩阵大小为 161616。
- 注意:通常矩阵乘中两矩阵很大,因此数据是分块(Tiling)后送入 Cube 单元的,每送完一块,结果存放到累加器,最后得到结果。
- 在 CPU 的计算过程中,矩阵 A 按行扫描,矩阵 B 按列扫描。典型的存储方式是 A 和 B 都 按行方式(Row-Major)进行存储,而内存读取按行读更方便,因此对 A 矩阵高效,对 B 矩阵低效。
- 为了提高内存读取的效率,NPU 将矩阵 B 的存储方式转成按列存储(Column-Major),通过改变矩阵存储的方式来提升矩阵计算的效率。
- Cube Core 一条指令完成两个 16*16 矩阵的 MAC,相当于一个时钟周期进行 163 = 4096 个 MAC 运算。执行前将 A 按行、将 B 按列存放在 Input Buffer,并通过 Cube Core 计算得到 C,按行存放在 Output Buffer。
矩阵的预处理:
- 分块(Tiling):因为片上缓存容量有限,因此将整个矩阵 B 划分为多个子矩阵,并依次搬运到缓存中,最后得到结果矩阵 C;
- 填充(Padding):A 和 B 都等分成同样大小的块(16*16),排不满的地方可以通过补 0 实现。
NPU调度
NPU模型调用过程
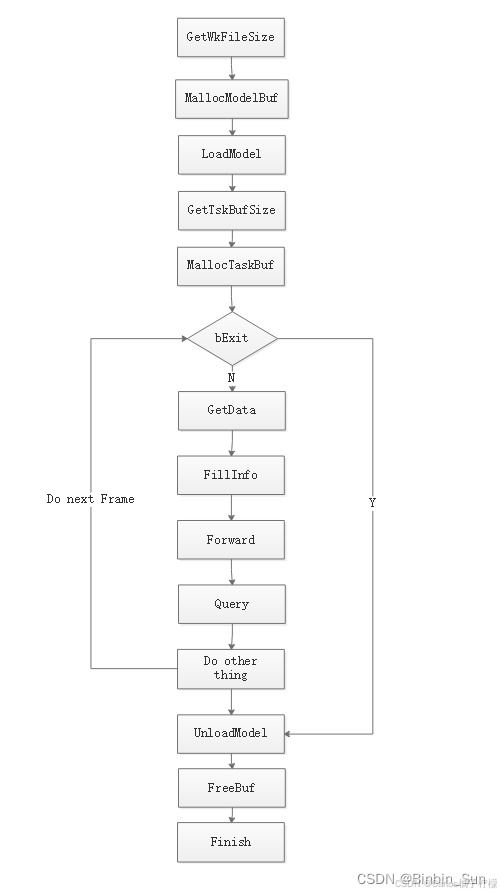
- CNN模型的完整调用流程:
- 模型的加载,数据的填充,算法的推理,后处理,模型卸载部分。
- 实际上针对单核和双核在策略和调度上一致的,算法模型的推理可以同时跑在两个核上。在实际运行中,和 NPU 相关的只有Forward模块,此处用到了 NPU的计算资源。在进行推理时,可通过参数可选择推理计划使用的核。推理进行时,两个核中所进行的计算可以并行进行,并不会相互影响。需要注意的是,针对单核,只能串行执行。
单个神经网络调度优化
- 单网络调度目标:单个NPU或GPU核心中调度单个模型到达最低时延和最高硬件利用率。
- 在CNN的运行分层从上到下使用了几种优化技术:
- 服务层级编排:云服务接收数百万DNN任务并将其分发到多个服务器。
- 图级并行化:将网络视为向无环图(Directed Acyclic Graph, DAG)的计算图,其中节点表示CNN中的算子,边表示张量。目标是充分实现计算图并行性,通常是AI编译器的工作。
- 运行时级调度:负载平衡和并发方式 优化算子之间的并行性。在单CNN模型推理中仅限于模型内的并行性, 而在多CNN模型推理中,则可以是跨模型的并发。
- 算子级别:通过循环平铺和缓冲区管理等机制来加速算子执行,以达到充分利用NPU计算和内存资源。
- 在NPU编译器层面,主要进行以下操作:
- 算子识别与优化:主要是算子融合,将多个连续的算子融合成一个复合算子,减少中间数据的传输和存储开销。例如,将卷积和ReLU激活函数融合成一个复合算子。
- 数据布局优化:根据NPU的硬件特性,选择合适的数据格式(如NHWC或NCHW)进行存储和计算;内存对齐,确保数据在内存中的对齐,以提高访存效率。
- 并行化优化:包括数据并行和计算并行,将计算任务划分为多个子任务,分配给不同的NPU核心并行执行;将输入数据和权重数据划分为多个部分,每个部分由不同的NPU核心处理。
- 通信与同步优化:优化NPU核心之间的数据传输,减少通信开销。同步机制:确保各个核心之间的计算结果能够正确地聚合和传递,避免数据竞争和死锁。
- 负载均衡:动态调度:根据每个核心的当前负载情况,动态调整任务分配,确保各个核心的负载均衡。任务优先级:根据任务的优先级和依赖关系,合理安排任务的执行顺序。
- 缓存优化:数据预取:通过预测机制提前加载数据到高速缓存中,减少数据访问的延迟。缓存管理:优化缓存策略,减少缓存未命中率,提高数据访问效率。
- 硬件特性利用:专用硬件单元:利用NPU中的专用硬件单元(如卷积加速器、矩阵乘法器等)进行高效计算。流水线技术:通过流水线技术,将计算任务分解为多个阶段,每个阶段由不同的硬件单元处理,提高整体计算效率。
- 低精度计算:将浮点数转换为低精度的定点数(如INT8),减少计算和存储开销,提高计算效率。
- 编译优化技术:指令级并行:通过指令重排和并行执行,提高指令执行效率。循环展开:通过循环展开减少循环控制开销,提高计算效率。
- 性能分析与调优:使用性能分析工具对生成的代码进行分析,识别性能瓶颈,根据性能分析结果,对代码进行进一步的优化。

多个神经网络调度优化
- 时分复用(time multiplex)
- 时分复用是一种常用的多神经网路调度的策略是时分多路复用。
- 在这种策略中,单个DNN模型使用整个加速器,然后转换到另一个DNN网络模型。这通常是通过每个DNN在不同的stream中来进行管理的。
- 时分多路复用调度策略也可以采用多种多样的形式,例如可以是基于FIFO的、固定时间的、贪婪的或计算-存储平衡的等等策略。
- 其中计算-内存平衡调度器的目标是提高硬件利用率并降低总体延迟,当内存资源被完全占用时,它们会调度计算受限(computing-bounding)的算子到硬件中执行,而当计算能力被充分利用时,则调度内存受限(memory-bounding)的算子到硬件资源中执行。
- 共部(co-location)
- 在多个同一类的网络模型共享使用同一个硬件资源的方式叫做共部(Co-location),这可以通过在硬件架构中使用不同处理器模块专用于多个同一类的网络模型来实现。
- 例如在FPGA模型开发研究中,通常每个网络或每种网络类型都有一个专门的处理器模块。但是共部(Co-location)不仅局限于FPGA上的专用处理器模块,在具有多核的NPU硬件架构中,也可以将每个核都分配一个网络模型。
- 在多个同一类的网络模型共享使用同一个硬件资源的方式叫做共部(Co-location),这可以通过在硬件架构中使用不同处理器模块专用于多个同一类的网络模型来实现。
- 混合调度
- 共地址的调度方式也可以与时分多路复用方法相结合。如在NPU架构中有4个计算核心,其中左边三个核心支持分时复用的调度策略,而最右侧的核心则实现了共部调度策略;在这种情况下,调度可以获得一些模型的时间复用优势,同时保持一个模型的专用核心。
- 不同的方法需要不同的硬件和软件来支持它们,这取决于不同的场景的需求,在设计中考虑运行时哪项指标是最重要的:吞吐量、延迟、公平性或确定性。
多个神经网络调度的目标和指标
- 在多个DNN工作负载运行时,对于调度机制来说有多个而不是单一的优化目标,包括满足不同CNN网络的实时性要求,高效的硬件映射、调度的开销/收益的平衡等。
- 帧的划分:
- 同一个深度神经网络DNN模型推理时,可以并行处理多帧数据的推理,而不同帧则由不同的计算核心同时处理,模型参数可以在核心之间共享。
- 任务划分:包括层划分(layer partition)、特征图划分、通道划分等
- 层间并行:将CNN的不同层分配给不同的NPU核心,每个核心负责处理一层或多层的计算。
- 但是需要一个很好的平衡策略使整个网络模型能够恰好地分割到所有核心,否则会出现部分计算核心处于空闲状态,从而降低了硬件领用率和推理时延。
- 例如一个网络模型,在双核间进行调度,但是其分层切分并没有做好,这会导致双核NPU利用率降低,
- 层内并行:在单个层内部,可以进一步将计算任务划分为多个子任务,这些子任务可以并行执行。例如,卷积层的多个卷积核可以分配给不同的NPU核心。
- 由于每次只在每个核上处理输入特征的一部分,因此在最后要做一些后处理来考虑边缘对齐。
- 层间并行:将CNN的不同层分配给不同的NPU核心,每个核心负责处理一层或多层的计算。
- 数据划分:
- 输入数据划分:将输入特征图划分为多个子区域,每个子区域由不同的NPU核心处理。
- 权重数据划分:将卷积核权重划分为多个部分,每个部分由不同的NPU核心处理。
- 此外,还有负载均衡、优化计算、硬件加速等方法。
- 优化是有代价的,目前看起来最有前景的调度策略都需要硬件支持,如抢占表、权重的内存直接访问(Direct Memory Access,DMA)、输入特征的DMA或硬件运行时调度模块。
谷歌TPU芯片
- 在 TPU 中有一个关键组件叫做 MXU(Matrix Multiply Unit,矩阵乘法单元),为了处理大规模的 Int8 矩阵加乘法运算而设计了独特的脉动阵列(Systolic Array)架构,(为什么叫脉动阵列,Systolic 一词专指“心脏收缩的”,表示数据有节奏的持续计算)。 在CPU 中程序逻辑,数据在经过 ALU 计算前后都会经由寄存器处理;而 TPU 内部数据在 ALU 之间更快地流动且复用,寄存器->ALU->ALU->ALU->ALU。
- TPU 上的控制逻辑(control logic)只占了芯片的 2%(远低于 CPU 和 GPU),累加器 Accumulators是一个能够存储 4MiB 的 32-bit 数据的累加单元,用来存储 MXU 计算后的结果。 TPU 属于一个专用的电路,里面最大的两个就是 Local Unified BUffeer 和 MXU
TPU架构的演进
- 在 TPU v1 中,它有两个存储区域:Accumulator 负责储存矩阵乘积结果;Activation Storage 负责储存激活函数输出。TPU v2 交换了 Accumulators 和 Activation Pipeline 这两个独立缓冲区的位置,并将它们合并为 Vector Memory,变得更像传统架构中的 L1 Cache。
- 在 TPU v1 中,Activation Pipeline 是专门针对激活函数场景特殊处理的,即卷积之后有一个 Batch Normalization 再接一个特殊的激活函数的 ALU 计算。然而,这种特殊的 ALU 计算无法满足训练场景的需求。因此,曾经的 Activation Pipeline 在 TPU v2 中变成了一个 Vector Unit,用于专门处理一系列的向量激活函数。
- 在 TPU v1 中,MXU 是和 Vector Memory 相连接的,而在 TPU v2 中,谷歌将 MXU 和 Vector Unit 进行了连接,所有的数据出口和计算都由 Vector Unit 进行分发。
- 在 TPU v1 中使用 DDR3 内存是为了将推理权重直接加载进来用于计算。然而在训练过程中会产生许多中间层的变量和权重,这时 DDR3 的回写速度无法满足需求。因此,在 TPU v2 中将 DDR3 与 Vector Memory 放在一起,并将 DDR3 的位置换成 HBM。
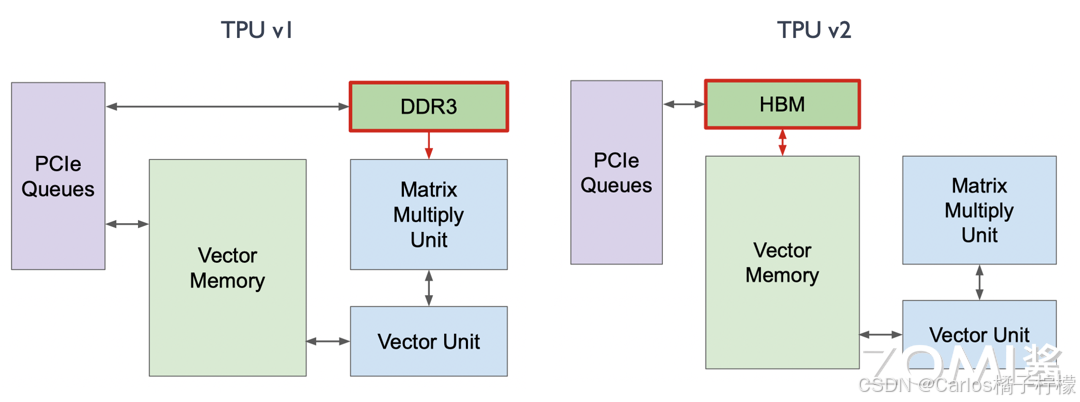
- 在TPU v2架构中,TPU core包含矩阵乘法单元(MXU)、转置/规约/置换核心(TRP Unit)、矢量单元(Vector Unit)、标量单元(Scalar Unit)
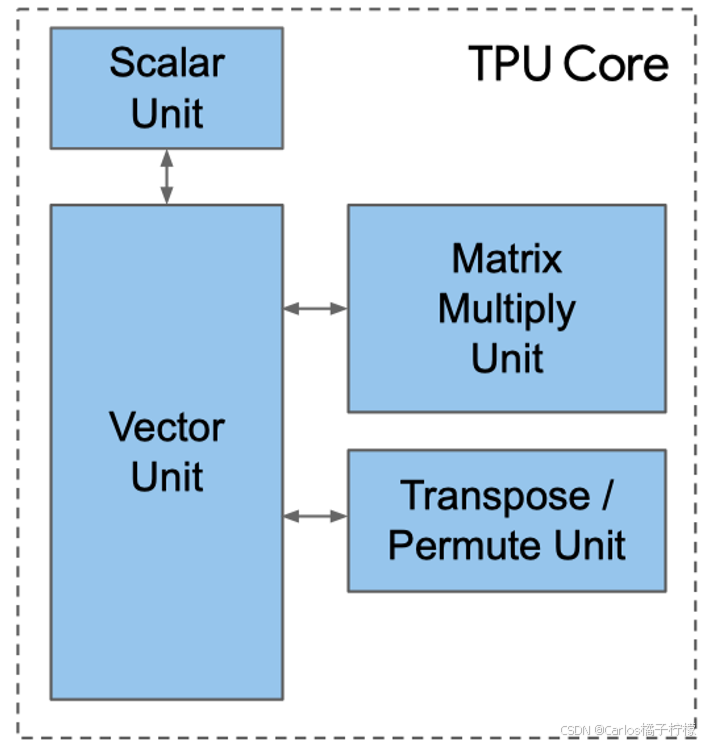
- TPU v3 实际上就是 TPU v2 的增强版。TPU v3 相比 TPU v2 有约 1.35 倍的时钟频率、ICI 贷款和内存带宽,两杯 MXU 数量,峰值性能提高 2.7 倍。
- TPU v4 的硬件增加了 Sparse Core 的支持用于利好稀疏计算,以及集群计算的良好支持等。
昇腾 AI 芯片
昇腾 AI 芯片有什么不同
- 昇腾 AI 处理器是华为基于达芬奇架构专为AI计算加速而设计的处理器,3D Cube 矩阵计算单元,支持多种计算模式和混合精度计算。
- 昇腾 AI 架构包括了芯片系统控制 CPU(Control CPU),AI 计算引擎(包括 AI Core 和 AI CPU),多层级的片上系统缓存(Cache)或缓冲区(Buffer),数字视觉预处理模块(Digital Vision Pre-Processing,DVPP)等,采用 LPDDR4 高速主存控制器接口;
- 达芬奇架构指令集采用了 CISC 指令,高效的运算密集型 CISC 指令含有特殊专用指令;
昇腾架构
- AI Core:
- 计算核心,负责执行矩阵、向量、标量计算密集的算子任务,采用达芬奇架构;
- 包括三种基础计算单元:Cube(矩阵)计算单元、Vector(向量)计算单元和Scalar(标量)计算单元
- AI CPU:
- 承担非矩阵类复杂计算,即负责执行不适合跑在 AI Core 上的算子;
- TS Core:
- 作为任务调度器(Task Scheduler,TS),以实现计算任务在 AI Core 上的高效分配和调度(专门服务于 AI Core 和 AI CPU,不承担任何其它的工作);
- ARM CPU:
- 控制芯片整体运行;
- DVPP:
- 数字视觉预处理子系统,完成图像视频编解码;
- Cache & Buffer:
- 多层级片上缓存/缓冲区
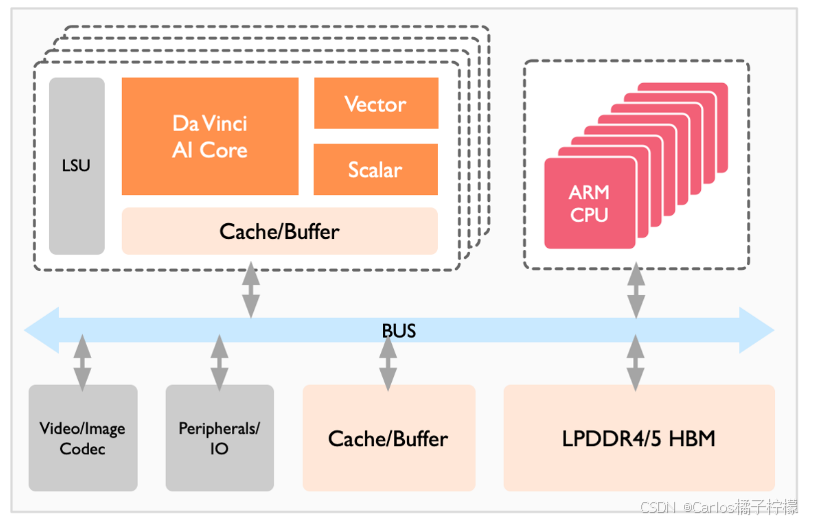
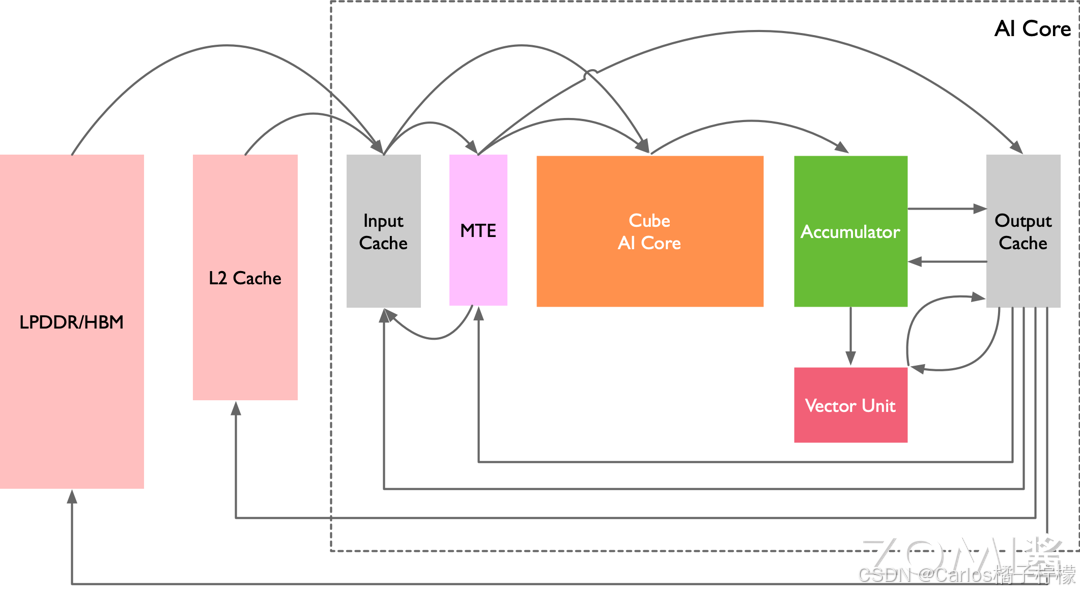
- 多层级片上缓存/缓冲区
昇腾计算单元
- AI Core(Cube Core):
- 每次执行可以完成 fp16 的矩阵乘,如 C = A(1616) * B(1616),更大的矩阵运算需要先对矩阵进行分块(在 L1 Buffer 中进行缓存);
- Vector Unit:
- 向量计算单元执行向量指令,类似于传统的单指令多数据(SIMD)指令,每个向量指令可以完成多个操作数的同一类型运算。
- 算力低于 Cube,灵活度高(如数学中的求倒数、平方根等),Vector 所有计算的源数据和目标数据都会存储在 Unified Buffer 中(Unified Buffer 再与 L1 Buffer 进行交互),并按 32 Byte 对齐;
- Scalar Unit:
- 负责各类型标量数据运算和程序流程控制,算力最低,功能上类比小核 CPU,完成整个程序循环控制、分支判断、Cube/Vector 等指令地址和参数计算以及基本算术运算等;
- 相对于Host CPU,Scalar的计算能力较弱,重点用于发射指令,性能调优时尽量减少if/else及变量运算。
- Accumulator(累加器):
- 把当前矩阵乘的结果与上一次计算的结果相加,可以用于完成卷积中增加 bias 等操作。
昇腾计算单元的电路实现是怎么样的?
- 对于运算 C = A(1616) * B(1616),矩阵 C 中的每一个元素都需要进行 16次乘法与 15 次加法计算得到(一个矩阵计算子电路)。
- 在 AI Core 中,共有 256 个矩阵计算子电路,每一条指令都可以并行完成 256 个矩阵 C 中的元素的计算。
double buffer
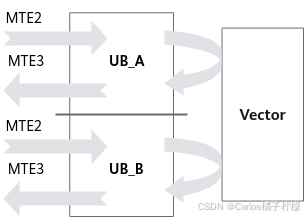
- 一个完整的数据搬运和计算过程,MTE2将数据从Global Memory搬运到Unified Buffer,Vector完成计算后将结果写回Unified Buffer,最后由MTE3将计算结果搬回Global Memory。
- 数据搬运与Vector计算串行执行,Vector计算单元无可避免存在资源闲置问题。
- 为减少Vector等待时间,double buffer机制将Unified Buffer一分为二,即UB_A、UB_B。实现数据的进出搬运和Vector计算实现并行执行,Vector闲置问题得以有效缓解。
昇腾存储单元
- 存储控制单元(MTE):
- MTE (Memory Transfer Engine,存储转换引擎)在搬运过程中可执行随路数据格式/类型转换;
- 作为 AI Core 内部数据通路传输控制器,负责 AI Core 内部数据在不同缓冲区间的读写管理,以及完成一系列的格式转换操作;
- 缓冲区:
- 输入缓冲区(L1 Buffer):AI Core 采用了大容量片上缓冲区设计,通过增大片上缓存的数据量来减少数据从片外搬运到 AI Core 中的频次,从而降低数据搬运过程中所产生的功耗和时延,有效控制整体计算耗能和提升性能; L0 Buffer Cube指令的输入和输出;
- 输出缓冲区(Unified Buffer):用来存放神经网络中每层计算的中间结果,从而在进入下一层时方便获取数据。
- 寄存器(SPR/GPR):
- 寄存器资源主要是标量计算单元在使用。
值得注意的是,昇腾存储单元采用了数据通路技术:
- 数据通路是数据在 AI Core 中的流通路径,它有以下特点:
1、多进单出,可通过并行输入来提高数据流入的效率;
2、将多种输入数据处理完成后只生成输出特征矩阵,数据种类相对单一,单输出数据通路,可以节约芯片硬件资源。
参考资料
- https://chenzomi12.github.io/02Hardware05Abroad/06TPU2.html



















 29
29

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










