




一、测试背景
1.1 目的
Postgresql(Oracle兼容)与 Oracle 数据库在处理字符类型字段(VARCHAR / VARCHAR2)时,长度语义(字符 vs 字节) 的差异,以及客户端字符集环境(NLS_LANG)对 Oracle 插入操作的影响。
1.2 测试环境
|
项目 |
源端(postgresql) |
目标端(Oracle) |
|
数据库版本 | Postgresql(Oracle兼容) |
Oracle 19c Standard Edition 2 (19.9.0.0.0) |
|
字符集 |
UTF-8 |
AL32UTF8 |
|
默认长度语义 |
nls_length_semantics = char (按字符) |
nls_length_semantics = byte (按字节,默认) |
|
测试客户端 |
psql |
SQL*Plus / DBeaver |
1.3 测试数据
-
中文字符串:
'中华人民共和国'(共 7 个字符) -
UTF-8 编码字节数:21 字节(每个汉字 3 字节)
二、测试步骤与原始现象
2.1 Postgresql(源端)测试
sql
-- 建表(不显式指定单位,依赖默认语义)CREATE TABLE test_highgo_utf8 (a VARCHAR(10));
-- 插入数据INSERT INTO test_highgo_utf8 (a) VALUES ('中华人民共和国');
-- 查询存储结果SELECT a, LENGTHB(a) AS bytes_length, LENGTH(a) AS char_length FROM test_highgo_utf8;
结果:

结论:postgresql默认 VARCHAR(10) 存储 10 个字符(而非 10 字节),因此 7 个汉字可正常存储。
2.2 Oracle 数据库(目标端)测试
场景 A:通过 SQL*Plus 插入(未设置 NLS_LANG)
sql
-- 建表(显式指定 CHAR 语义)CREATE TABLE test_oracle_utf8 (a VARCHAR2(10 CHAR));
-- 插入相同数据INSERT INTO test_oracle_utf8 (a) VALUES ('中华人民共和国');
结果: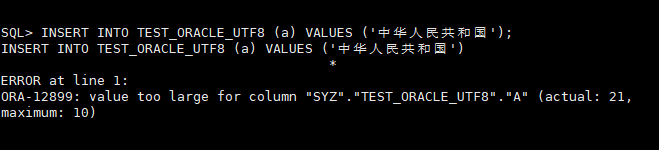
查询表定义:
SELECT column_name, char_used, char_length, data_lengthFROM user_tab_columns WHERE table_name = 'TEST_ORACLE_UTF8';
Plain Text
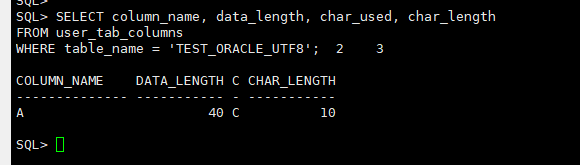
输出:CHAR_USED = 'C', CHAR_LENGTH = 10, DATA_LENGTH = 40 —— 表明列定义正确为字符语义。初步困惑:为什么显式 CHAR 语义仍报字节超限?
场景 B:通过 DBeaver(JDBC 驱动)插入
同样使用 VARCHAR2(10 CHAR) 表,通过 DBeaver 执行:
sql
INSERT INTO test_oracle_utf8 (a) VALUES ('中华人民共和国');
Plain Text
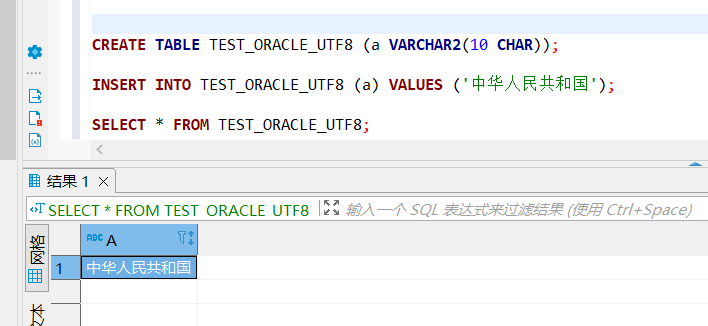
关键发现:相同的表、相同的 SQL,在不同客户端下结果不同 → 问题不在数据库,而在客户端环境。
三、根本原因分析
3.1 Oracle 字符集转换机制
Oracle 的 NLS_LANG 环境变量决定了客户端(SQL*Plus)如何将输入字符转换为数据库字符集。其格式为:
当客户端输入字符串时:
-
SQL*Plus 认为输入字符的编码为
NLS_LANG中指定的字符集。 -
SQL*Plus 将输入字符串从该字符集转换为数据库字符集(
NLS_CHARACTERSET)。 -
数据库按转换后的字节序列存储。
3.2 本次错误的详细拆解
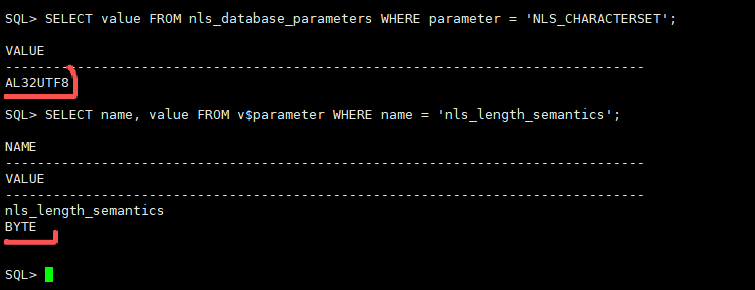
环境状态
数据库字符集:AL32UTF8(汉字 → 3 字节)
错误过程
-
用户在 SQL*Plus 中输入
'中华人民共和国'(终端通常为 UTF-8 编码,每个汉字 3 字节,共 21 字节)。 -
数据库最终收到的数据字节数大于 21 字节(本例中报错
actual:21恰好是原始 UTF-8 长度,说明转换后字节数未变但语义错误;某些情况下字节数会更大)。
结论
问题不是 Oracle 的 CHAR 语义失效,而是客户端 NLS_LANG 配置错误,导致 SQL*Plus 在字符集转换过程中产生异常,最终使数据库认为数据长度超限。
3.3 DBeaver 为何成功?
DBeaver 使用 JDBC 驱动(oracle.jdbc.OracleDriver),驱动内部会正确处理字符集转换,无需依赖 NLS_LANG 环境变量。它通过 JDBC URL 参数(如 useUnicode=true&characterEncoding=UTF-8)或自动检测数据库字符集来完成转换,因此不受此问题影响。
四、测试结论
-
Oracle 19c 中
VARCHAR2(10 CHAR)语义完全正常在正确的客户端字符集配置下,可以成功存储 7 个汉字(21 字节),因为CHAR语义限制的是字符个数,而非字节数。 -
postgresql数据库默认按字符存储,与 Oracle 显式
CHAR语义行为一致测试中postgresqlVARCHAR(10)同样成功存储 7 个汉字,两者在正确配置下可兼容。 -
ORA-12899错误的直接原因是客户端NLS_LANG未正确设置SQL*Plus 依赖此变量进行字符集转换,错误配置会导致传输字节数异常,触发长度超限。 -
图形化工具(DBeaver、Navicat 等)及 JDBC 驱动不受此问题影响它们内置字符集处理逻辑,无需手工配置
NLS_LANG。
补充(Xshell终端编码 → CentOS系统locale → Oracle NLS_LANG → 数据库字符集)
五、数据同步建议(针对异构同步)
在将数据从postgresql同步到 Oracle 时,为避免字符长度相关错误,请遵循以下清单:
|
检查项 |
操作 |
|
源端字段分析 |
计算源端字段的实际最大字节数:
|
|
目标端字段设计 |
使用 |
|
同步工具环境 |
如果同步任务通过 SQL*Plus 执行, 必须正确设置 |

















 到Oracle19.9字符语义&spm=1001.2101.3001.5002&articleId=161799306&d=1&t=3&u=5938fc93540f433a8db365b9fba64c9c)

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










