




 本文详细介绍了对抗生成网络(GAN)的基本概念,包括生成器与鉴别器的运作机制,以及GAN在动画人脸生成、序列生成等方面的应用。文章还探讨了GAN的训练目标、Wasserstein距离、模型评估指标Inception Score和FID,以及训练过程中可能遇到的挑战,如模式塌缩和多样性问题。
本文详细介绍了对抗生成网络(GAN)的基本概念,包括生成器与鉴别器的运作机制,以及GAN在动画人脸生成、序列生成等方面的应用。文章还探讨了GAN的训练目标、Wasserstein距离、模型评估指标Inception Score和FID,以及训练过程中可能遇到的挑战,如模式塌缩和多样性问题。
代码部分参考:李宏毅机器学习作业6-使用GAN生成动漫人物脸_iwill323的博客-CSDN博客
目录
Generative Adversarial Network (GAN)
借助Discriminator 的力量计算 Divergence
从Objective Function到JS divergence
Wasserstein distance概念:另一种计算divergence的方法
Mode Collapse与Mode Dropping的区别
Frechet Inception Distance (FID)
基本概念介绍
生成器(generator)
区别于给定x输出y的神经网络,现在给神经网络的输入添加一个从简单分布(Simple Distribution)中随机采样的变量,生成一个复杂的满足特定分布规律的输出(Complex Distribution)
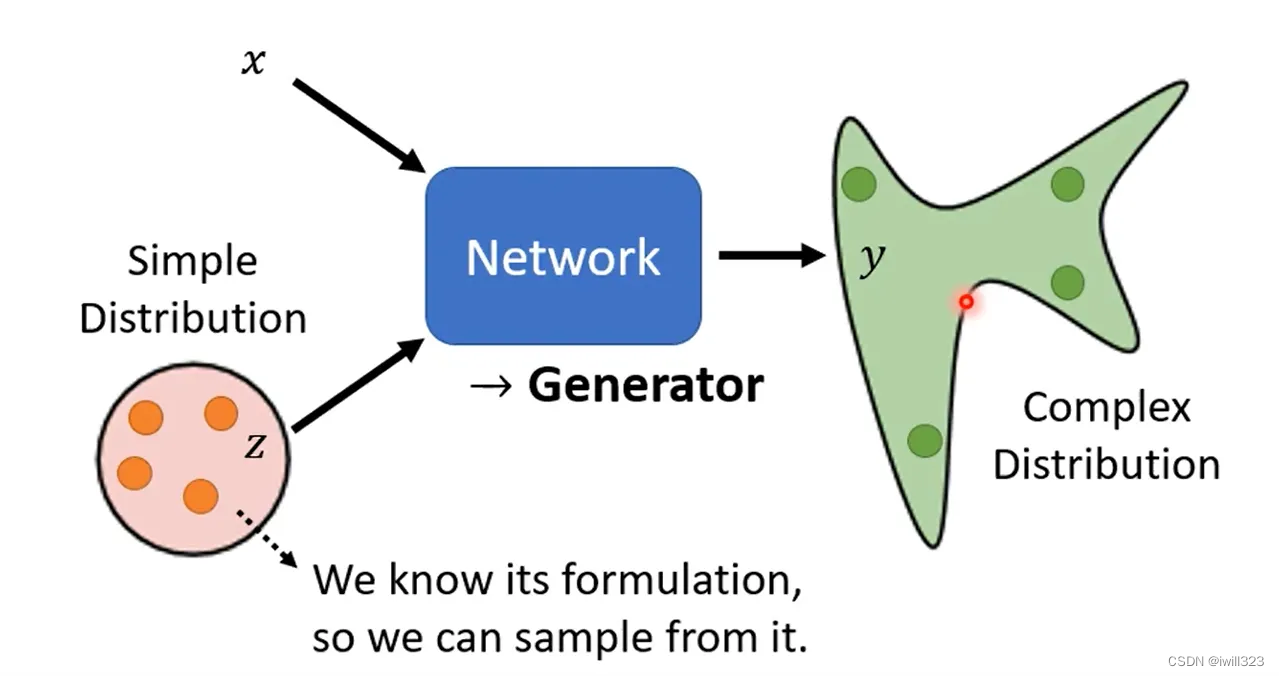
分布:高斯分布、均一分布
z所选择的不同的distribution之间的差异并没有真的非常大,generator会想办法把这个简单的distribution对应到一个复杂的distribution。所以可以简单地选择“正态分布”
方法:
- X,Z两个向量直接接起来,变成一个比较长的向量,作为network的input
- X跟Z正好长度一样,相加以后当做network的input
什么时候需要输出一个分布
当我们的任务需要一点创造力的时候,一个输入有多种可能的输出,这些不同的输出都是对的,但又只需要输出一个对象,这时就需要使用generator,在网络中加入随机输入,让网络在复杂分布中随机选择一个对象输出(输出有几率的分布)。
Generative Adversarial Network (GAN)
GAN是众多generator中比较有代表性的一个,而GAN的种类也非常多,常常会出现重名的GAN和奇奇怪怪的GAN名字。
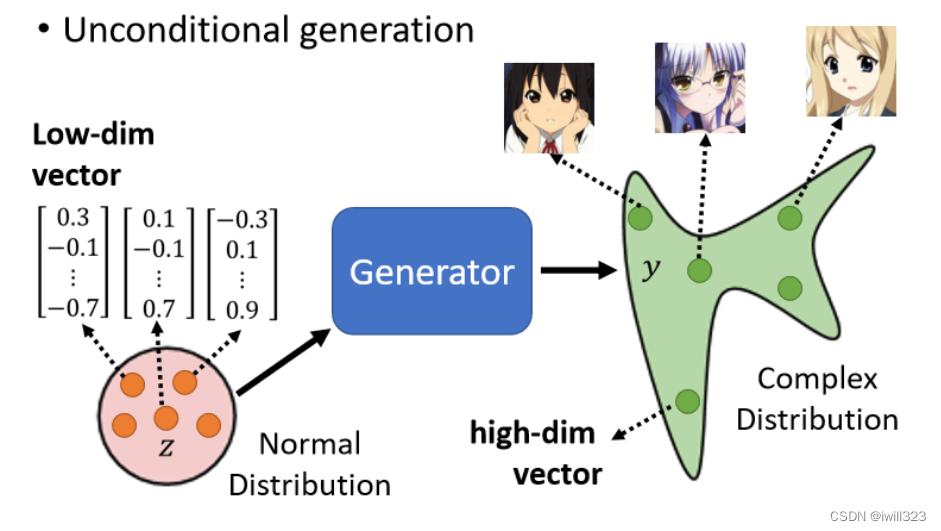
以unconditional generation(不考虑x,只考虑z)为例,假设Z是从一个normal distribution里采样出来的向量,通常会是一个low dimensional的向量,维度是你自己决定的,丢到generator裡面,输出一个非常高维的向量,希望是一个二次元人物的脸
 discriminator(鉴别器)
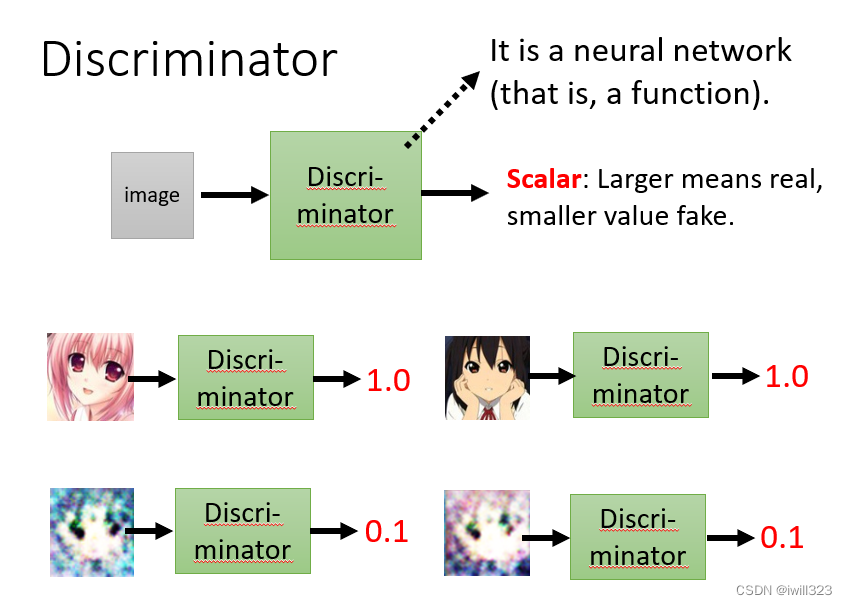
discriminator(鉴别器)
Discriminator也是一个神经网络(可以考虑使用CNN、transformer等),可以将generator输出的图像转换成数字,越接近于1,说明图像越真实,品质越高。
GAN的基本思想和算法
generator和discriminator是对抗关系,discriminator通过真实的图像来监督generator的图形生成,两者不断相互进化。
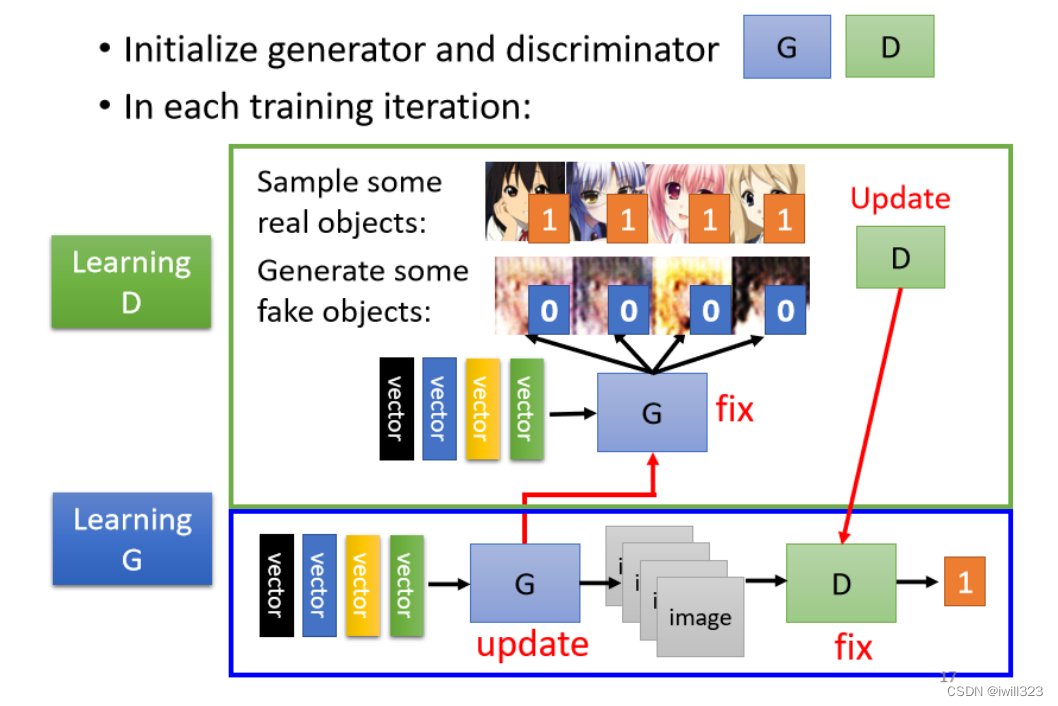
1、随机初始化generator和discriminator。
2、固定generator不变,更新discriminator。
将generator产生的图像和数据库样本比较,让discriminator分辨二者之间的差异,从而把二者区分开。具体地说,就是 real ones 经 0过 D,输出值大(接近 1),generator 产生的数据 (generated ones) 经过 D,输出值小(接近 0)。
该训练可以当作分类的问题来做(把样本当作类别1,Generator產生的图片当作类别2),然后训练一个classifier;也可以当作regression的问题来做(样本对应输出1,generator產生的图形对应输出0)

3、固定discriminator不变,更新generator。
从gaussian distribution采样作為generator输入,產生一个图片,把这个图片丢到Discriminator裡面,Discriminator会给这个图片一个分数,Generator训练的目标是要Discriminator的输出值越大越好,说明它产生的数据可以以假乱真
4、不断循环上述过程,直至产生很好的图像
实际中可以把 generator 和 discriminator 组成一个大的网络结构,如下图所示,前几层为 generator,后几层为 discriminator,中间 hidden Layer 的输出就是 generator 的输出,更新generator的时候就只更改前面几层,而更新discriminator的时候就只更改后面几层。
理解:
Generator 或 Discriminator每次只有一个在训练。训练时,所掌握的是对方上一轮训练的信息。其实这就像是双方每一次交手后,知道对方最新的技术水平,然后回去提升自己。精妙,但是对训练过程提出了更高要求:如果其中一个训练过程中某几步loss上升,就会对另一个的训练会产生负面影响,后者又可能会对前者产生负面影响,恶性循环,导致训练“坏掉”。
应用实例
Anime Face Generation(动画人脸生成)

Progressive GAN——真实人脸生成
生成“没有看过的\连续变化的”人脸。generator输入一个向量 输出一张图片。把输入的向量,做内插interpolation,看到两张图片之间连续的变化。

The first GAN
BigGAN
设定目标与训练
GAN 的训练目标:让生成器产生的与真实数据之间的分布接近
从给定简单的 Normal Distribution 采样数据,经过 Generator,得到的输出分布PG,使其接近目标分布Pdata。于是要计算PG与Pdata这两个分布之间的距离,用Divergence表征,找一个genenrator尽量使Divergence小。
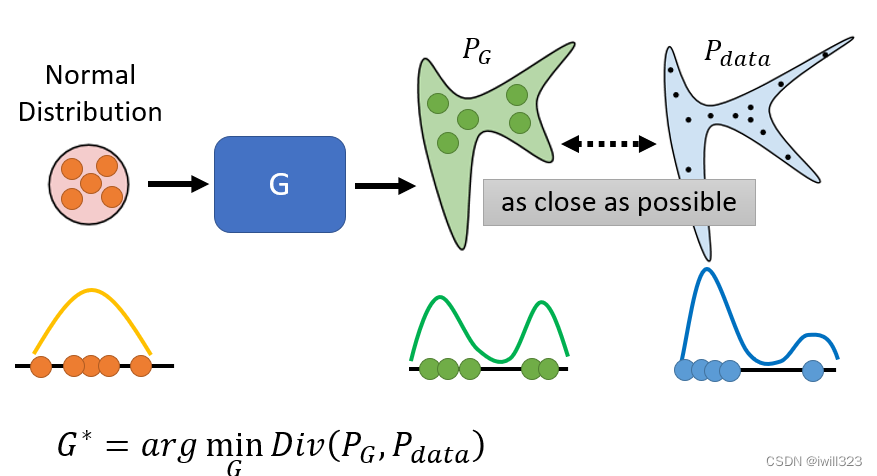
问题在于我们无法知道PG和Pdata的分布。GAN 告诉我们,不需要知道 PG 跟Pdata的分布具体长什麼样子,只要能从 PG 和 Pdata这两个分布中采样,就有办法算 Divergence。
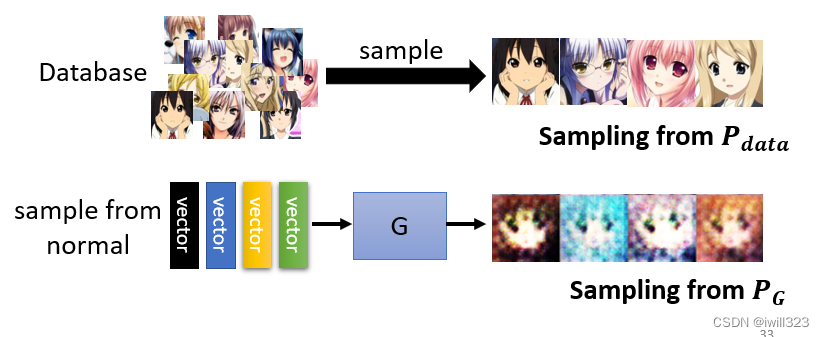
关于采样:从数据库裡面随机采样一些图片出来,就得到 Pdata;从 Normal Distribution 裡面采样向量丢给 Generator,让 Generator 產生一堆图片出来,那这些图片就是从 PG采样出来的结果
借助Discriminator 的力量计算 Divergence
Discriminator训练目标是看到Pdata给一个较高的分数,看到PG给一个比较低的分数。这个 Optimization 的问题如下(要Maximize 的东西叫 Objective Function,如果 Minimize 就叫它 Loss Function):
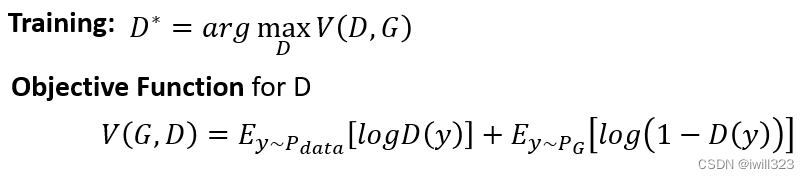
之所以写成这个样子,是因为在最开始设计时,希望在训练Discriminator时能够按照分类问题的方式考虑,事实上这个 Objective Function 就是 Cross Entropy 乘一个负号。Discriminator可以当做是一个分类器,它做的事情就是把从 Pdata 采样出来的真实 Image当作 Class 1,把从 PG 采样出来的假 Image当作 Class 2,训练过程等价于训练一个二元分类器。
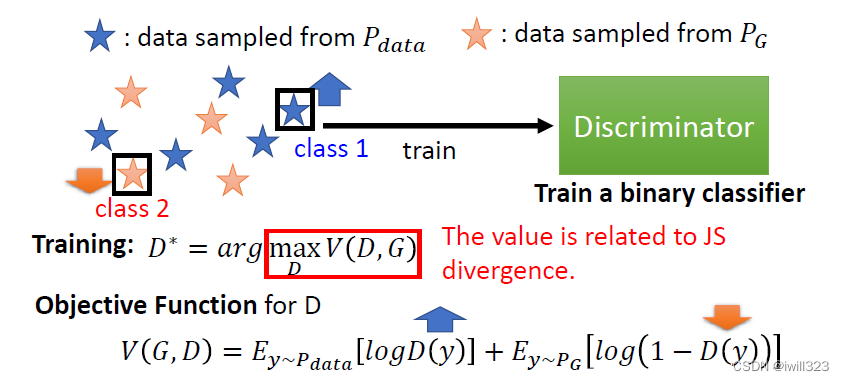
从Objective Function到JS divergence
经过推导可以发现,𝑉(𝐷,𝐺)的最大值和JS divergence相关,详细的证明请参见 GAN 原始的 Paper。直观上也可以理解:如果Discriminator 很难分辨 PG 和 Pdata,没办法准确打分,那么Objective Function的最大值就比较小,所以小的 Divergence对应小的Max 𝑉(𝐷,𝐺),反之假如PG 和 Pdata 很不像,divergence大,Discriminator 很容易就把两者分开了,得到的Max 𝑉(𝐷,<



















&spm=1001.2101.3001.5002&articleId=127487363&d=1&t=3&u=2519bdb4cfb44443af70f9222a1bbd91)
 1246
1246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










