




 本文介绍了如何利用SwiftUI结合MachineLearning实现声音识别功能,特别是判断音频中的声音是男性还是女性。通过苹果的CreateML工具进行训练,收集音频数据并分类,最终将训练好的模型集成到SwiftUI应用中进行声音分析。尽管CreateML适用于初学者,但深入到机器学习时,可能需要借助Python等更强大的工具。
本文介绍了如何利用SwiftUI结合MachineLearning实现声音识别功能,特别是判断音频中的声音是男性还是女性。通过苹果的CreateML工具进行训练,收集音频数据并分类,最终将训练好的模型集成到SwiftUI应用中进行声音分析。尽管CreateML适用于初学者,但深入到机器学习时,可能需要借助Python等更强大的工具。
SwiftUI之声音识别
配合MachineLearning功能,判断说话的人是男性还是女性。需要实现这个功能,首先需要有MachineLearning模块,即已经训练过的数据。
苹果自带了CreateML工具,可以自己训练图片,文字,声音,甚至图表,关键在于收集格式合适以及数量可观的数据。
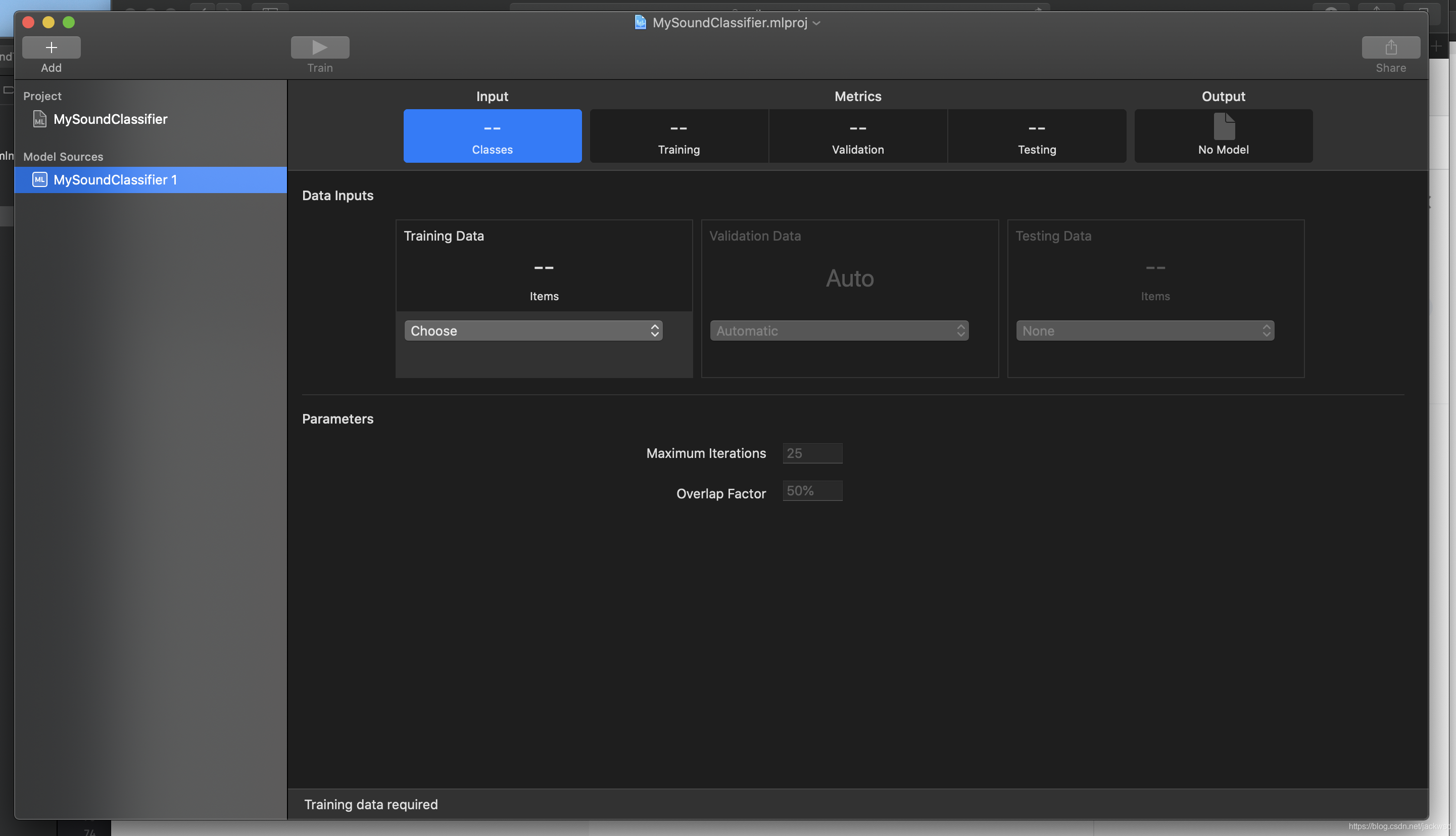
上图是训练音频的软件,使用方法很简单,类似于文本训练,通过文件夹区分男女声,然后在文件夹下放置搜集的男女声音频文件,为了准确性,可以将文件分类为训练用,校验用,以及测试用。即分成各种文件夹,而音频文件越多越好。
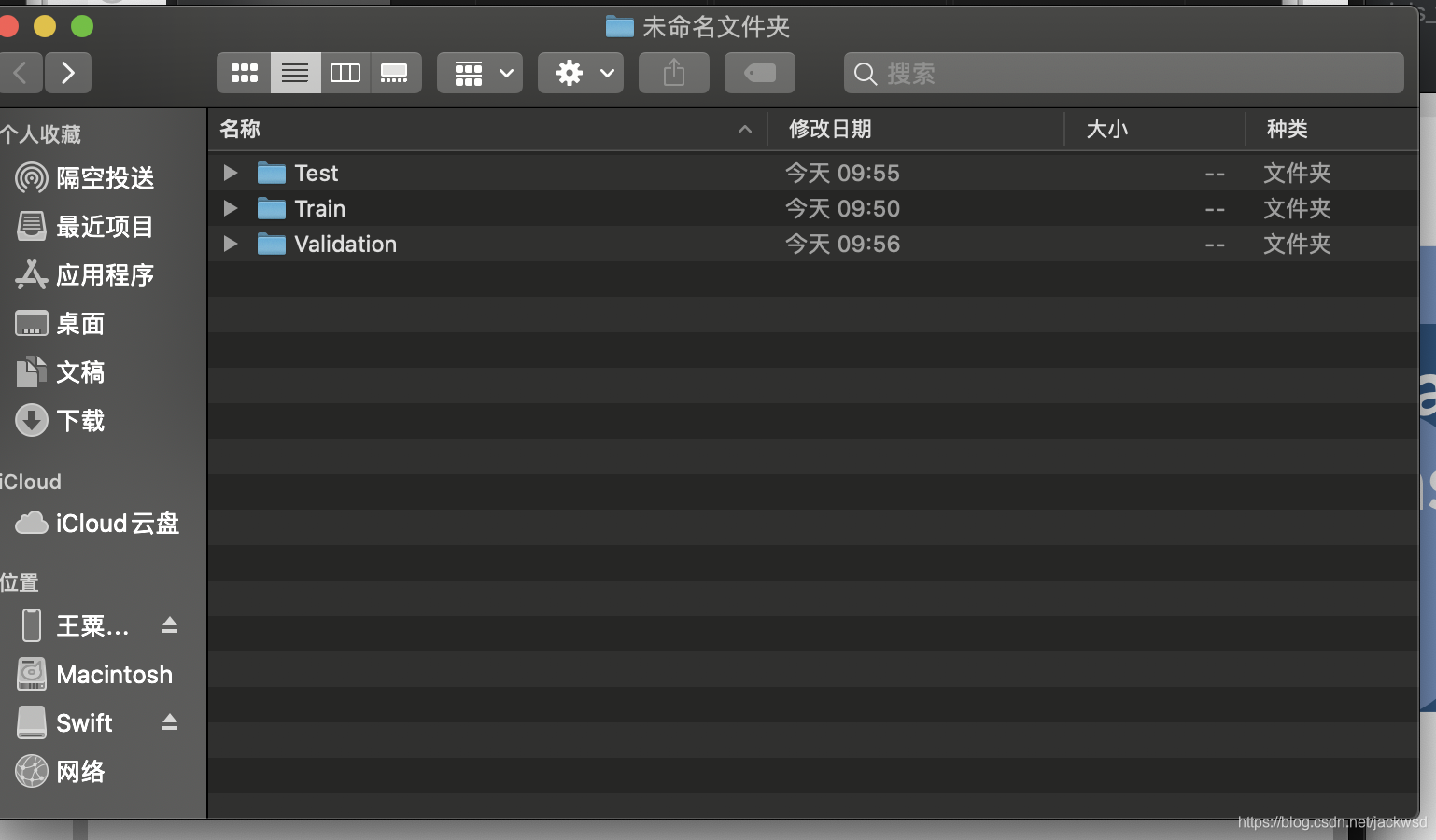
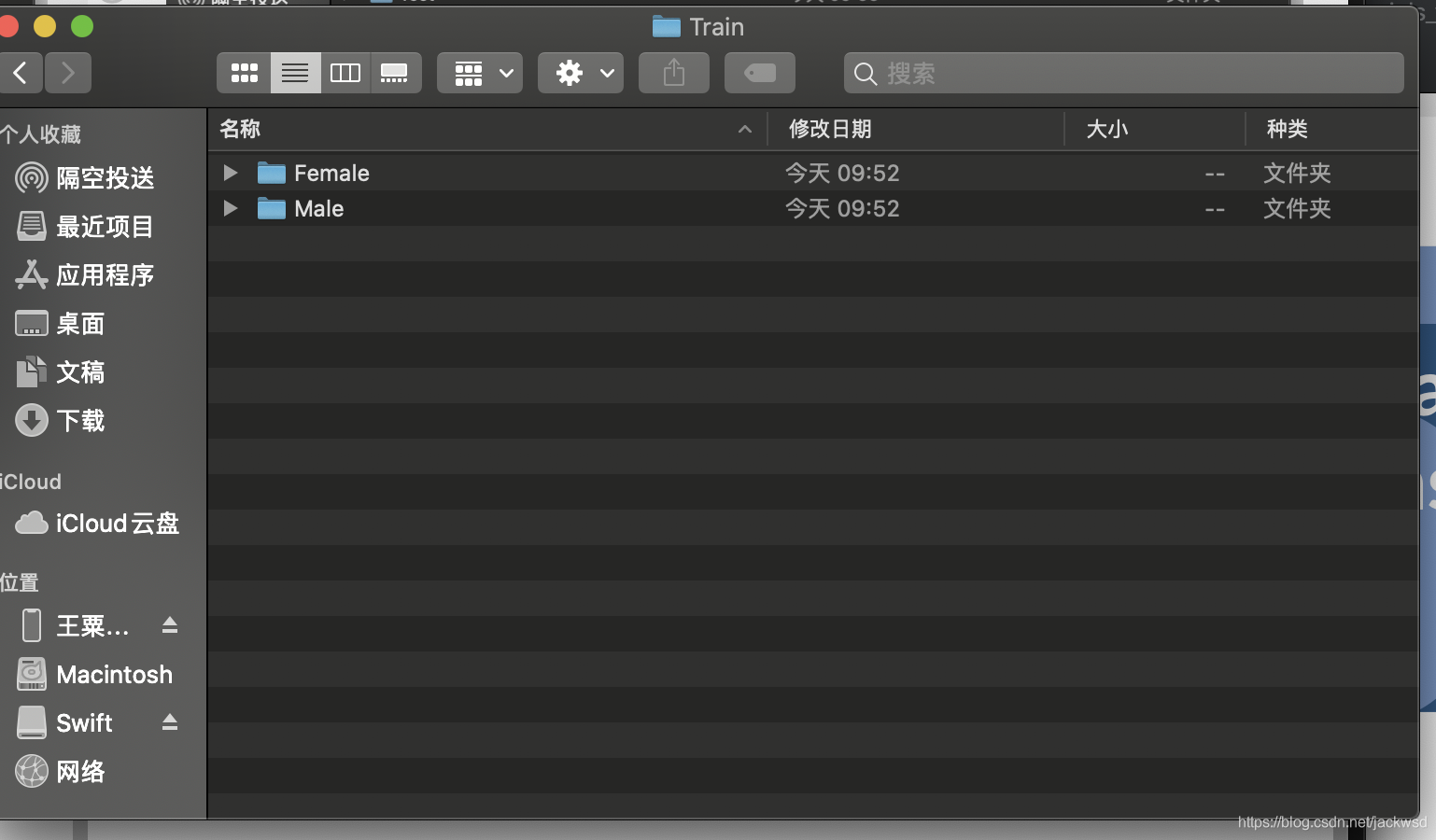
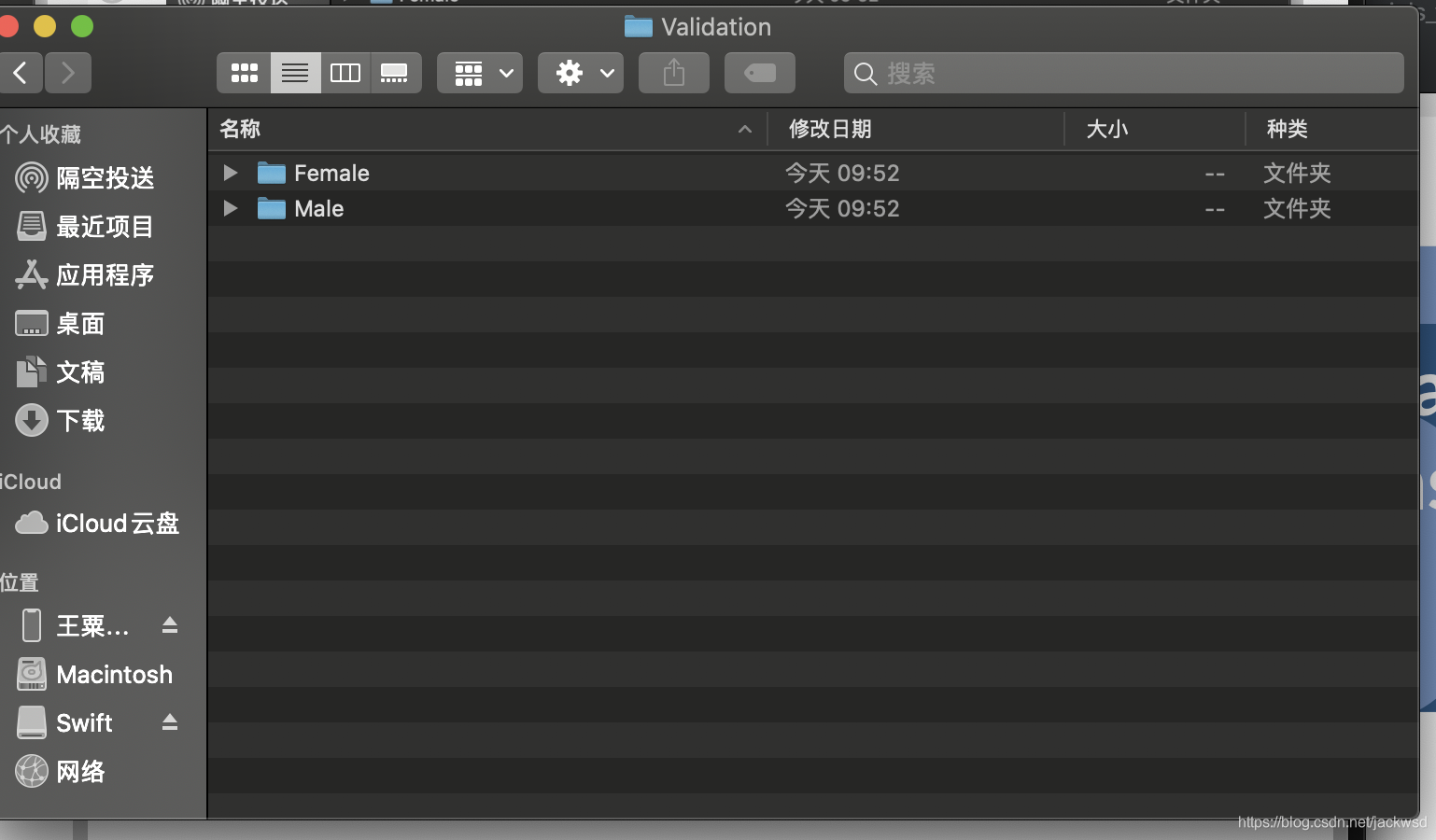
然后将文件路径放到训练工具CreateML中
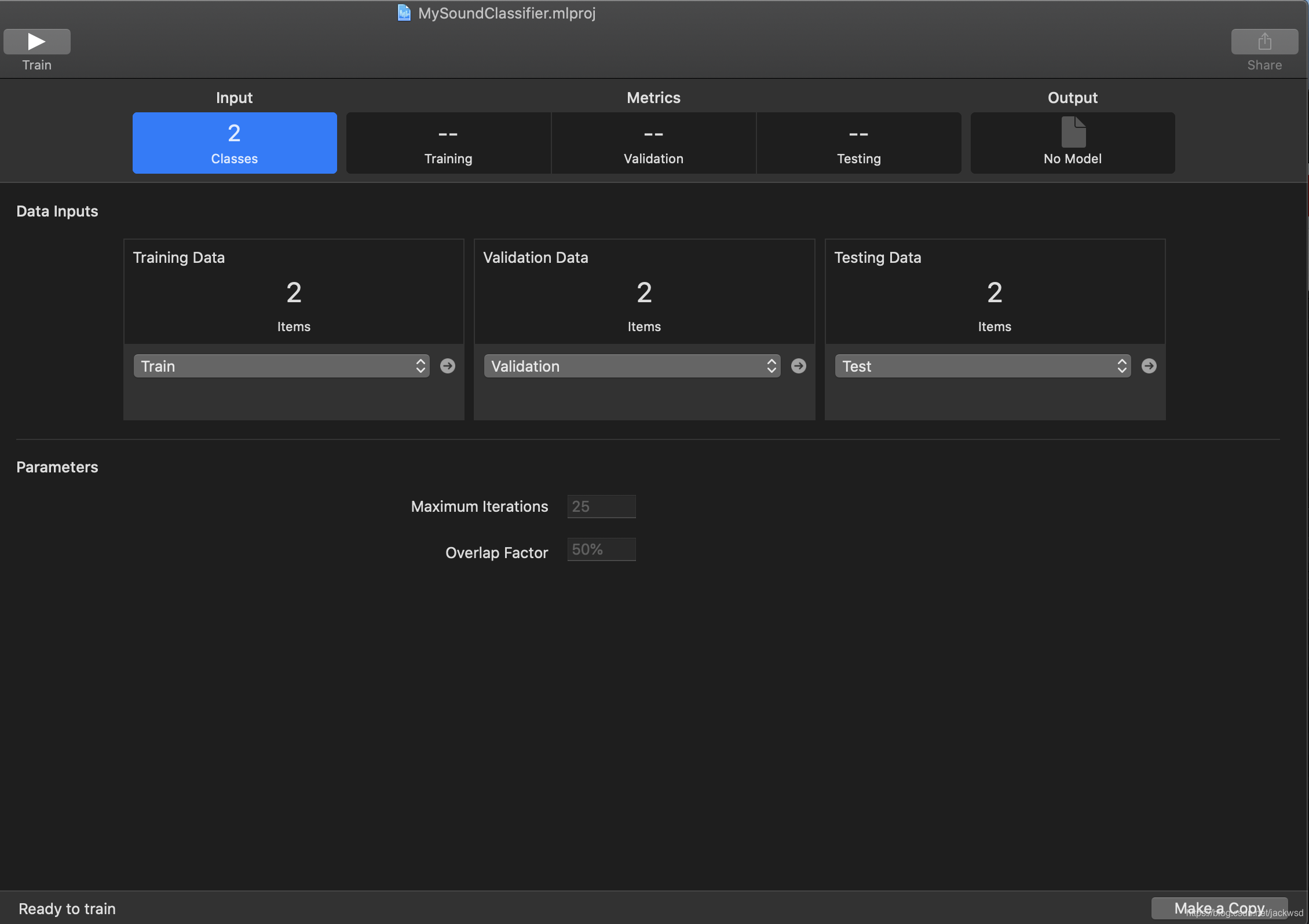
点击▶️,训练即可。训练后的模块准确性跟很多东西有关,用于训练的文件越多自然越好。

从Output中直接拖出训练好的模块,即可放入工程中。
以上只是简单介绍制作方法。
当模块拖到工程后,如图
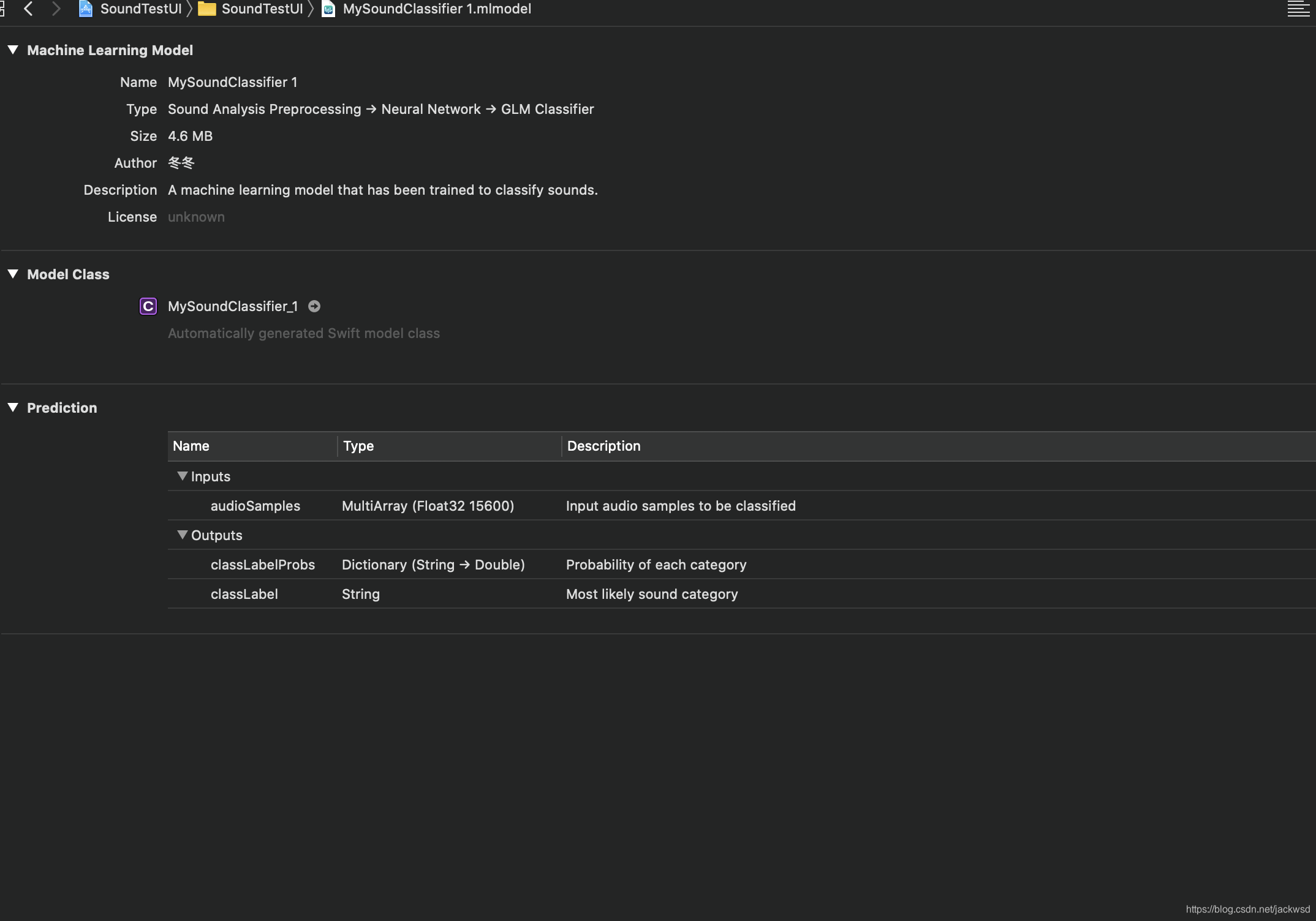
Inputs为我们需要输入模块的内容,即音频样本(audioSamples),而模块会输出该样本最可能的分类及可能性比例。
因为需要用到音频获取以及声音分析,所以首先
定义一个ObservableObject类型变量
class testMessage: ObservableObject{
@Published var message = "Nothing"
}
因为需要在不同的视图内传递数据,使用了protocol以及notification两种方式传递数据
在contentView中添加以下变量
//另一种数据传递方式测试用
@State var message = "Nothing"
@ObservedObject var myMessage = testMessage()
//AVEngine
private let audioEngine = AVAudioEngine()
//声音识别模块
private var soundClassifier = MySoundClassifier 1()
var inputFormat: AVAudioFormat!
var analyzer: SNAudioStreamAnalyzer!
var resultsObserver = ResultsObserver()
let analysisQueue = DispatchQueue(label: "dongdong")
初始化函数
init(){
resultsObserver.delegate = self
inputFormat = audioEngine.inputNode.inputFormat(forBus: 0


















&spm=1001.2101.3001.5002&articleId=108049468&d=1&t=3&u=d1bbc941caa74941be0e63ac754574a3)
 2313
2313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










