



当我用30分钟跑通第一个AI客服应用实例时,我心里想的是:“就这?知识库不过如此。”但当我把这套系统真正往“能用”的方向推进时,才发现——跑通一个Demo和落地一个系统之间,隔着一整个太平洋。
本文是我从“会调接口”到“理解知识库工程”的完整复盘。不讲空洞的理论,只讲踩过的坑、流过的汗、以及最终想明白的那些事。
作者:Javy21(javy21@csdn)
专栏:《老攻城狮的AI编程实践之路》
一、从“So Easy”到“我太浅薄了”
橘子洲头AI客服跑通后那天,我坐在电脑前发了好一会儿呆。
30条问答对,一个Flask服务,一个Ollama模型——就这么简单的东西,居然真的能回答游客的问题。我甚至有点膨胀:“知识库?不就是把问答对存起来,查到了就回复,查不到就扔给大模型嘛。”
这种膨胀持续了大约48小时。然后我开始认真思考一个问题:如果把这个Demo放大100倍——1000份文档、10万个用户、每天几万次查询——这套方案还能撑得住吗?
答案很明显:撑不住。
于是我老老实实回过头来,重新审视“知识库”这三个字到底意味着什么。以下是我从“会调接口”到“理解知识库工程”的完整思考过程。
二、知识库的本质:不是“存”,而是“找”
2.1 我最初的理解(错得离谱)
用户提问 → 查问答对 → 有就回复 → 没有就扔给大模型
这叫什么知识库?这叫带缓存的聊天机器人。它根本没有“理解”知识,只是在“匹配”知识。
2.2 真正的知识库在做什么
真正的知识库系统,做的是三件事:
| 环节 | 做什么 | 我的Demo做了什么 |
|---|---|---|
| 知识表示 | 把非结构化的文档变成可计算的结构 | ❌ 手动整理问答对(人工结构化) |
| 知识检索 | 从海量知识中快速找到相关的内容 | ❌ 关键词匹配(30条数据不需要检索) |
| 知识生成 | 基于检索结果生成准确回答 | ✅ 调用了大模型 |
我的Demo只做了第三件事,前两件事基本没做。 这就是为什么它“So Easy”——因为我绕过了知识库最核心、最困难的部分。
2.3 一个更诚实的对比
| 维度 | 我的Demo(30条问答对) | 真正的知识库系统(1000+文档) |
|---|---|---|
| 数据量 | 30条 | 10万+片段 |
| 检索方式 | 关键词匹配 | 向量检索 + 关键词检索(混合检索) |
| 检索精度 | 100%(因为数据太少) | 70-90%(需要持续优化) |
| 知识更新 | 手动改JSON | 自动化索引流水线 |
| 回答质量 | 依赖人工整理的质量 | 依赖检索质量 + 模型推理质量 |
| 可维护性 | 一个人搞定 | 需要团队协作 |
跑通Demo只需要1天,落地一个真正的知识库系统,可能需要3-6个月。
三、知识库的四个核心环节(每一环都是坑)
3.1 环节一:知识表示——让机器“看懂”文档
核心问题:PDF、Word、Excel、网页……这些格式机器看不懂。得把它们变成机器能处理的东西。
我的做法(太天真) :手动整理30条问答对,存成JSON。
真实做法:
原始文档(PDF/Word/HTML)
↓ 文档解析(提取纯文本)
↓ 文本清洗(去噪、规范化)
↓ 语义切分(按段落/章节/语义边界)
↓ 向量化(生成384/768维向量)
↓ 存入向量数据库(Chroma/Milvus/Qdrant)关键教训:文档解析比想象中难得多。PDF里的表格、图片、页眉页脚、多栏排版——每一个都是坑。某企业5000+份文档散落在Confluence、Wiki、PDF手册中,新员工平均40分钟才能找到答案——问题不在于“没有知识”,而在于“知识无法被有效检索”。
工程化要点:
| 文档类型 | 解析难点 | 建议工具 |
|---|---|---|
| 表格、图片、多栏、扫描件 | PyPDF2 + PDFPlumber + OCR | |
| Word | 样式、嵌入对象、修订痕迹 | python-docx |
| HTML | 标签冗余、动态内容 | BeautifulSoup |
| Excel | 多Sheet、公式、合并单元格 | pandas + openpyxl |
3.2 环节二:文本切分——切得好不好,决定了检索的上限
核心问题:一篇文档几十页,不能整篇喂给模型(上下文窗口有限)。但切得太碎,语义就断了。
我的做法:没有做切分(30条问答对不需要)。
真实做法:
# 好的切分策略
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # 每个片段的大小
chunk_overlap=64, # 重叠部分(保持上下文连贯)
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""]
)关键教训:切分粒度直接影响检索质量。把“知识点讲解-例题解析-课后练习”整段拆分,用户问“例题解析”时却要加载整段内容;把一句完整的“定理描述”拆成两段,检索到的片段就缺失了关键逻辑。
工程化要点:
| 文档类型 | 推荐chunk_size | 推荐overlap | 理由 |
|---|---|---|---|
| 技术文档/API说明 | 384-512 | 10-15% | 代码片段需保持完整 |
| 长篇PDF/政策文件 | 768-1024 | 64-150 | 保持段落语义连贯 |
| FAQ/问答对 | 256-384 | 32-64 | 问答通常较短 |
| 会议纪要/制度 | 512 | 64 | 一句话差异可能改变含义 |
一个重要的坑:切分不是“切完就完了”。切分后的每个片段需要保留元数据(来源文档、页码、章节等),否则检索到了也无法溯源-。
3.3 环节三:向量检索——找得快,更要找得准
核心问题:从10万个片段中找到最相关的3-5个,既要快(毫秒级),又要准(不遗漏、不跑偏)。
我的做法:没有做向量检索(30条数据直接关键词匹配就够了)。
真实做法:
真正的知识库系统,不会只用一种检索方式。纯向量检索只懂“语义”,不懂“字词”——用户搜“ModelArts”时,它可能返回一堆语义相关但根本不包含这个词的文档。
混合检索(Hybrid Search)是目前的主流方案-:
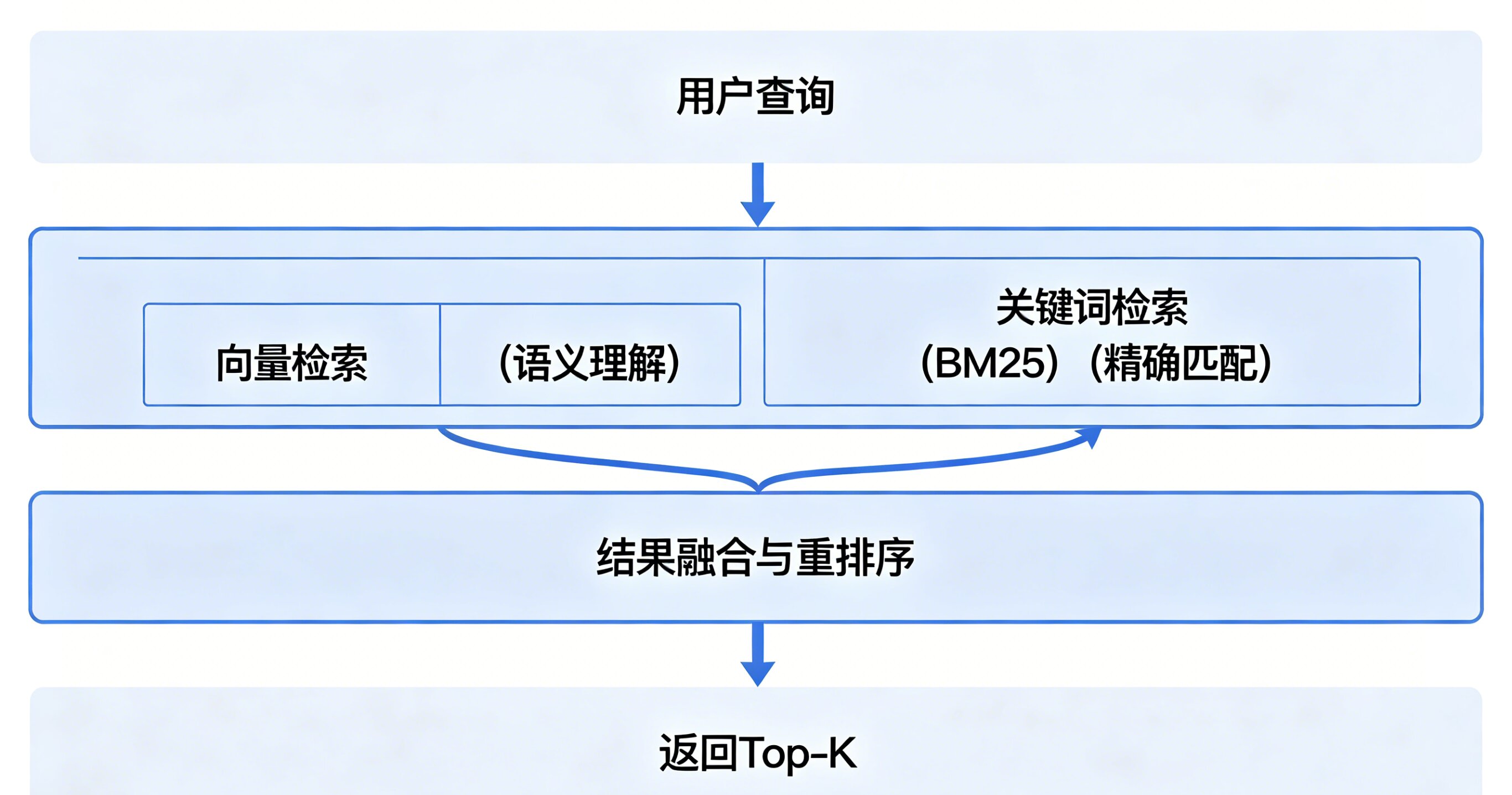
关键教训:向量检索不是万能的。当文档数量从30条暴涨到10万条时,纯向量检索的精度会断崖式下跌。必须配合关键词检索和重排序-。
工程化要点:
| 优化手段 | 解决的问题 | 效果 |
|---|---|---|
| 混合检索 | 专有名词/代码/型号无法被语义检索命中 | 召回率提升10-18% |
| 重排序(Rerank) | 向量粗排不够精确 | Top-1准确率显著提升 |
| 查询改写 | 多轮对话中的指代消解 | 检索命中率提升 |
| HyDE | 用户查询过短/模糊 | 生成假设性文档辅助检索 |
3.4 环节四:知识生成——让模型“照着说”,而不是“随便说”
核心问题:检索到了相关片段,怎么让模型基于这些片段生成准确的回答,而不是“发挥想象力”?
我的做法:
prompt = f"""参考以下内容回答问题:
{context}
问题:{question}
"""真实做法:
真正生产环境的Prompt,远比这个复杂:
prompt = f"""你是一位专业助手,请基于以下参考文档回答问题。
【核心规则】
1. 如果参考文档中有直接答案,请准确引用并标注出处
2. 如果参考文档中没有答案,请明确告知用户“未找到相关信息”
3. 如果参考文档中有部分相关信息,请综合推断并说明依据
4. 不要编造参考文档中没有的内容
5. 回答要简洁、准确、有条理
【参考文档】
{context}
【用户问题】
{question}
【回答】"""关键教训:Prompt是控制模型行为的“最后一道防线”。好的Prompt能让模型“知之为知之,不知为不知”。
工程化要点:
| 优化方向 | 做法 | 效果 |
|---|---|---|
| 引用溯源 | 每个回答带来源文档+页码 | 增强可信度,便于人工复核-2 |
| 拒绝回答 | 知识库无相关信息时明确告知 | 避免幻觉,保护品牌信誉-2 |
| 答案精简 | 控制生成长度,避免冗余 | 提升用户体验,降低成本 |
四、我踩过的坑(以及我是怎么爬出来的)
坑1:“总纲淹没细则”
现象:三个文件(总纲140页、细则50页、指导意见20页),任何问题都只返回总纲的内容。
根因:总纲篇幅大、片段多,向量检索按相似度排序时,总纲的片段占据了Top-K的全部位置。
解决方案:强制跨文件均衡采样——每个文件独立检索,各取N个片段。
教训:向量检索不是“公平”的。篇幅大的文档天然占据优势,必须从业务层面干预。
坑2:补采片段“丢了”
现象:日志显示补采到了3个片段,但最终返回时不见了。
根因:分组-取片段的逻辑有缺陷,补采的片段没有被正确合并到最终结果中。
解决方案:重构检索逻辑,改为“每个文件独立检索 → 各自取Top-K → 合并”。
教训:工程化的核心是“确定性”。每一步都要有明确的输入输出,不能依赖隐式的假设。
坑3:内存占用爆炸
现象:Windows任务管理器显示内存占用超过20GB。
根因:Qwen2.5:7B模型加载(~8-12GB)+ Chroma向量库(~2-4GB)+ Python进程(~1-2GB)+ WSL2开销(~2-3GB)。
解决方案:
-
.wslconfig限制WSL2内存上限为16GB -
num_predict=1024限制生成长度 -
debug=False关闭调试模式
教训:32GB内存是“黄金分水岭”,但不加节制地使用,照样会爆。必须主动管理每一MB内存。
五、从Demo到生产:还差什么?
5.1 我目前做到的程度
| 能力 | 状态 |
|---|---|
| 单文档问答 | ✅ 已实现 |
| 多文档检索 | ✅ 已实现(跨文件均衡采样) |
| 引用溯源 | ✅ 已实现(文件名+页码) |
| 本地部署 | ✅ 已实现 |
5.2 距离“生产可用”还差什么
| 能力 | 当前状态 | 差距说明 |
|---|---|---|
| 文档自动解析 | ❌ 手动整理问答对 | 生产环境需要自动解析PDF/Word/Excel |
| 增量更新 | ❌ 全量重建索引 | 文档更新后需增量索引,不能每次都重建 |
| 高并发支持 | ❌ 单线程Flask | 生产环境需要多线程/异步/负载均衡 |
| 权限管理 | ❌ 无 | 不同用户只能访问授权文档-2 |
| 审计日志 | ❌ 无 | 谁问了什么、系统回了什么,需要可追溯-2 |
| 效果评估 | ❌ 人工判断 | 需要Precision@k、Recall@k、忠实度等量化指标-24 |
| 监控告警 | ❌ 无 | 系统异常、检索质量下降需要主动告警 |
5.3 生产环境的7个关键指标
根据生产实践,一个合格的RAG系统需要关注以下指标:
| 指标 | 含义 | 我的系统状态 |
|---|---|---|
| Precision@k | 返回的结果中有多少是相关的 | ❌ 未测量 |
| Recall@k | 相关的结果中有多少被返回了 | ❌ 未测量 |
| 忠实度 | 回答是否基于检索到的文档 | ⚠️ 目测还行 |
| 答案相关性 | 回答是否解决了用户问题 | ⚠️ 目测还行 |
| 幻觉检测 | 是否编造了不存在的事实 | ⚠️ 目测较少 |
| 延迟 | 响应时间是否可接受 | ✅ 5-10秒 |
| Token消耗 | 成本是否可控 | ✅ 本地部署,成本为0 |
一个残酷的事实:没有量化指标,就没办法系统性地优化系统。靠“感觉”判断效果,在30条数据时还行,在10万条数据时就是灾难。
六、给同路人的建议
6.1 如果你刚开始
-
先跑通Demo:用我的方法,30条问答对 + Flask + Ollama,1天跑通
-
再理解原理:向量是什么、检索是什么、RAG是什么
-
然后扩大规模:从30条到300条,从手动整理到自动解析
-
最后工程化:混合检索、重排序、增量更新、监控评估
6.2 关于“炫技”和“务实”的思考
网上有很多关于RAG的“高级技巧”——HyDE、Query Rewriting、Self-RAG、多Agent协作……看起来很厉害,但我要说一句可能不太中听的话:
对于90%的企业知识库场景,把基础做到位,比堆砌高级技巧更重要。
什么是“基础到位”?
-
文档解析准确(不乱码、不漏内容)
-
切分策略合理(语义完整、不过度碎片化)
-
检索策略得当(该用向量用向量,该用关键词用关键词)
-
Prompt设计扎实(让模型“知之为知之,不知为不知”)
-
评估体系完善(能量化的都量化)
这些做到位了,系统效果不会差。这些没做到位,堆再多高级技巧也是空中楼阁。
6.3 关于“学习路径”的思考
回顾我从“跑通Demo”到“理解知识库”的整个过程,最关键的转折点不是学会了某个新技术,而是想明白了“知识库到底在解决什么问题” 。
知识库不是在解决“怎么调用大模型”的问题——那太简单了。知识库在解决的是:
-
怎么从10万份文档中,在1秒内找到最相关的3个片段?
-
怎么保证找到的片段确实是相关的,而不是“看起来相关”?
-
怎么让模型的回答有据可查,而不是凭空捏造?
-
怎么在文档更新后,系统能自动同步,而不需要人工重建?
-
怎么衡量系统今天比昨天更好?
这些问题,每一个都比“调用API”难10倍。但正是这些问题,区分了一个“会调接口的开发者”和一个“能落地系统的工程师”。
七、写在最后
回到开头的问题:知识库到底难不难?
答案是:说难也难,说不难也不难。
不难,是因为技术栈已经非常成熟——向量数据库、LangChain、Ollama,都是开箱即用的工具。跟着教程走,1天就能跑通Demo。
难,是因为从Demo到生产,中间有太多工程化的问题需要解决——文档解析、切分策略、检索优化、效果评估、增量更新、权限管理、监控告警……每一个都是实实在在的工程挑战。
跑通Demo考验的是学习能力,落地系统考验的是工程能力。
而我,作为一个写了20年代码的老IT,更愿意把时间花在后者上。
如果你也在从Demo走向生产的路上,欢迎在评论区分享你的经验和困惑。我们一起把这条路走通。
作者:Javy21(javy21@csdn)
博客主页:https://blog.csdn.net/javy21
首发日期:2026年7月本文是《老攻城狮的AI编程实践之路》专栏的第3篇深度思考,希望能够带给读者一些启发,从跑通Demo到理解工程,从“So Easy”到“我太浅薄了”——这就是我的AI知识库学习之路。
本文采用 CC BY-NC 4.0 许可协议。欢迎转载,请注明出处。🙌


















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










