



大家好,我是 Ai 学习的老章
我是 vLLM 的粉丝,更新过 N 多相关文章,内网部署大模型全都是使用 vLLM
大模型本地部署,vLLM 睡眠模式来了
vLLM v0.13.0 来了,对 DeepSeek 深度优化
vLLM-Omni 帮助文档翻译,模型相关
vLLM 最新版来了,Docker Model Runner 集成 vLLM
DeepSeek-OCR 本地部署(上):CUDA 升级 12.9,vLLM 升级至最新稳定版
前文之后 vLLM 重要更新
继续介绍 vLLM 的最新的几个动态
🎉1、vLLM 官网上线(正式)
官网地址:https://vllm.ai/
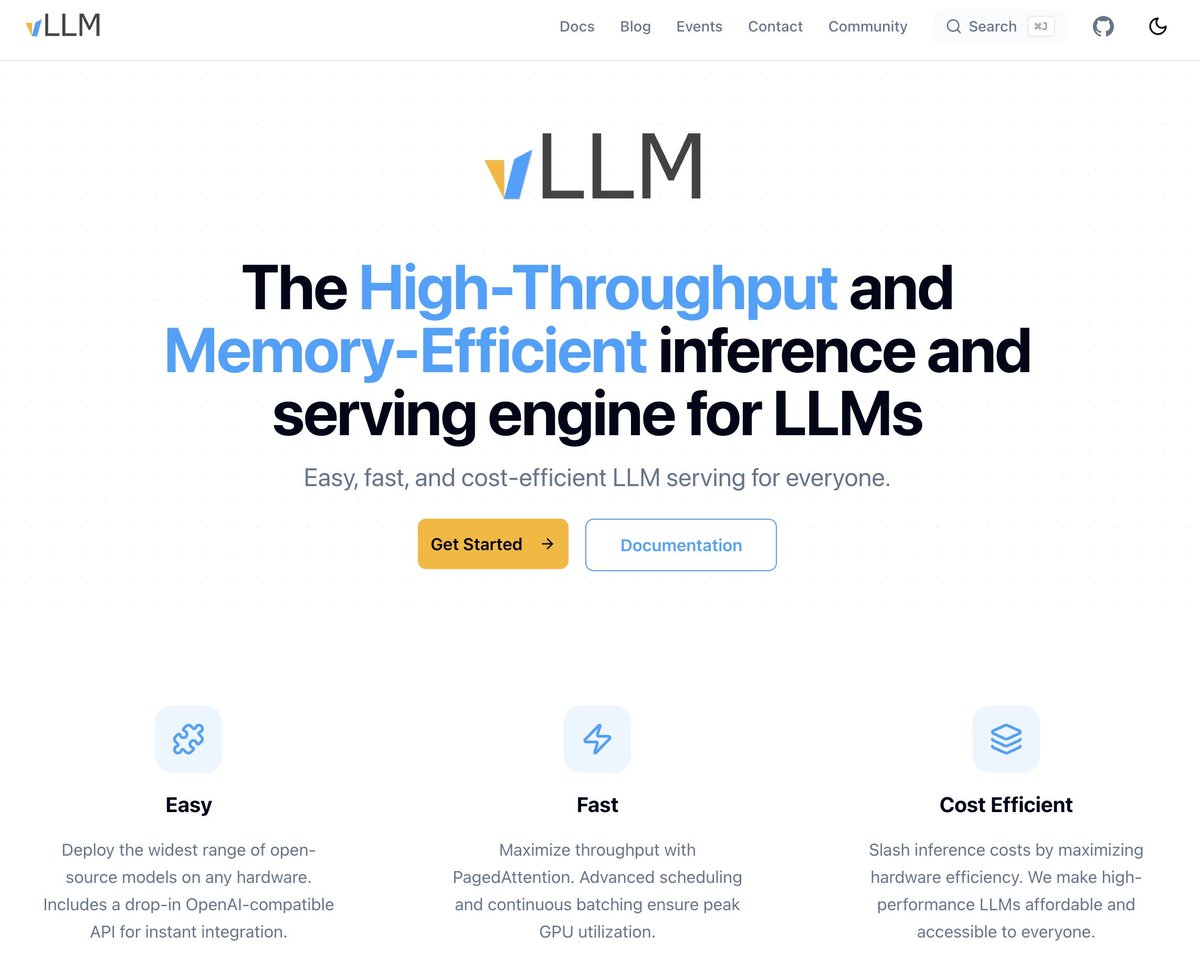
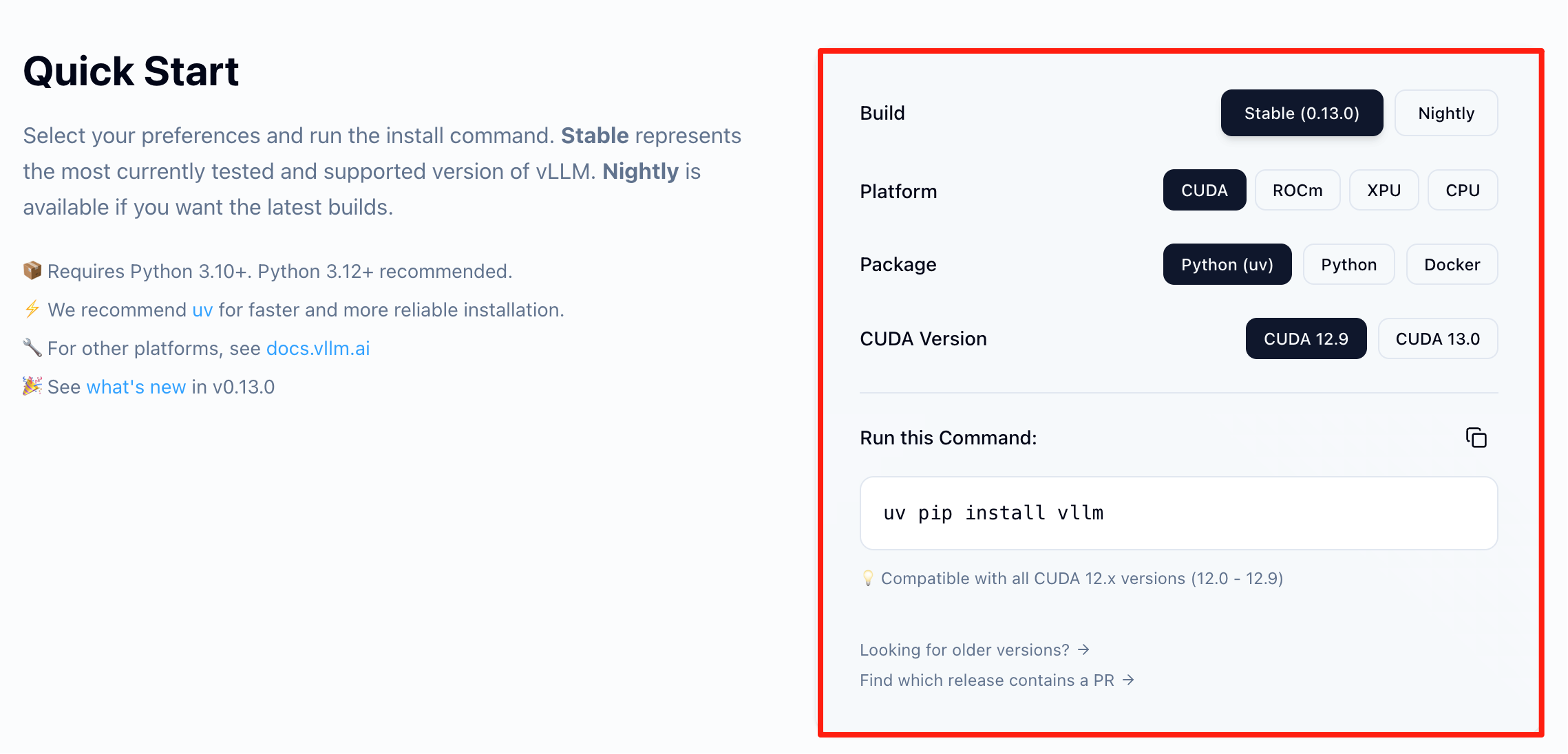
这里面有个极友好的交互式 vLLM 安装选择器(GPU、CPU 等)
✨ 2、巨大里程碑——vLLM 语义路由 v0.1
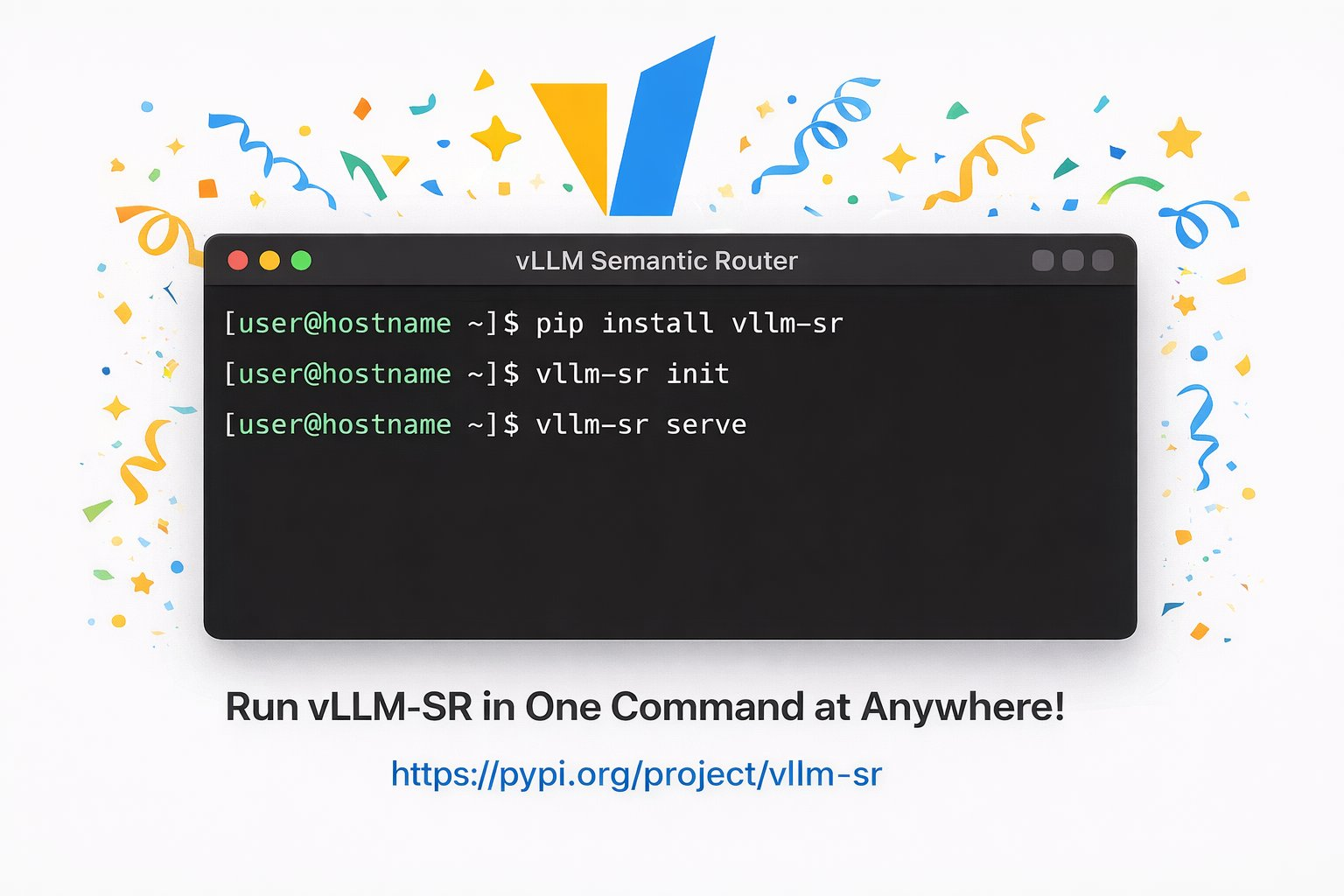
实现的功能:
用户与多种 AI 模型之间的桥梁 ,通过捕捉请求上下文信号,智能地将请求路由到不同的 LLM 提供商和架构中。除模型选择外,也可以在安全过滤(脱狱/PII)、语义缓存和幻觉检测方面做出智能决策。
详细介绍:https://blog.vllm.ai/2026/01/05/vllm-sr-iris.html
🤝3、感谢一系列小号 vLLM
https://github.com/skyzh/tiny-llm
https://github.com/Wenyueh/MinivLLM
https://github.com/GeeeekExplorer/nano-vllm
其中 nano-vLLM 我之前介绍过:大模型本地部署,小号的 vLLM 来了
而 MinivLLM 那个项目更离谱,它建立在 nano-vLLM 之上更加迷你
4、🚀Day-0 支持一系列大模型
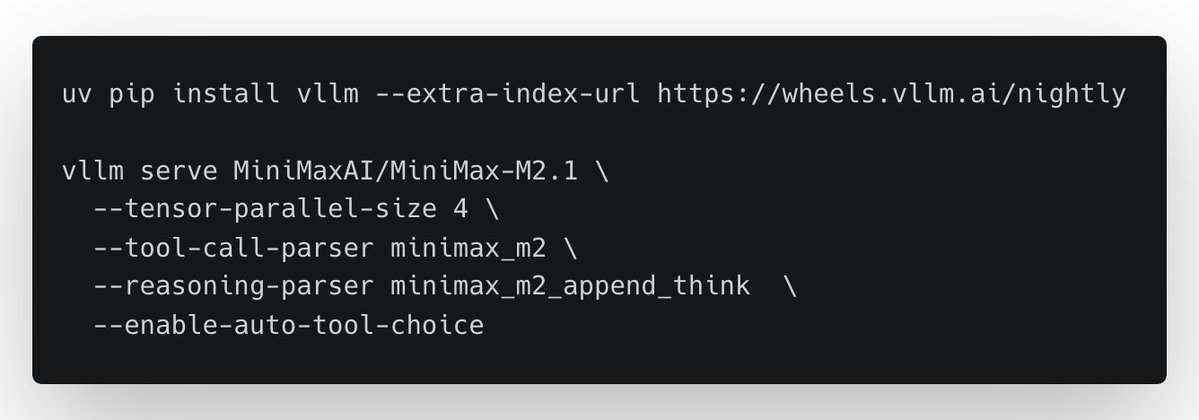
MiniMax-M2.1
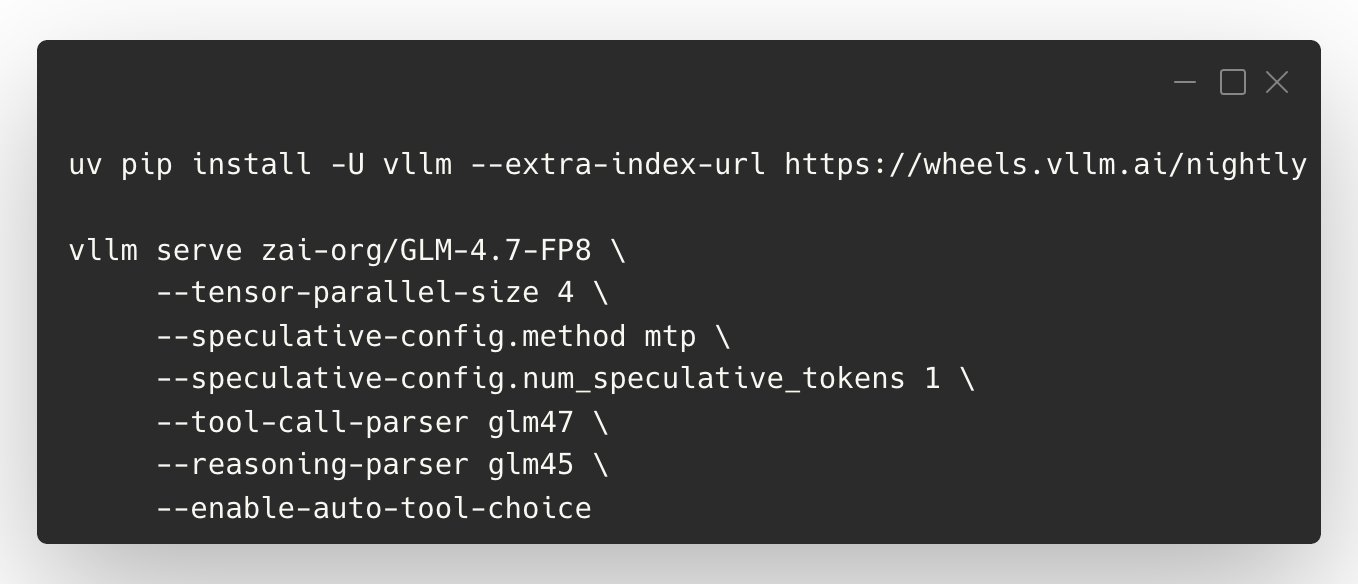
GLM-4.7
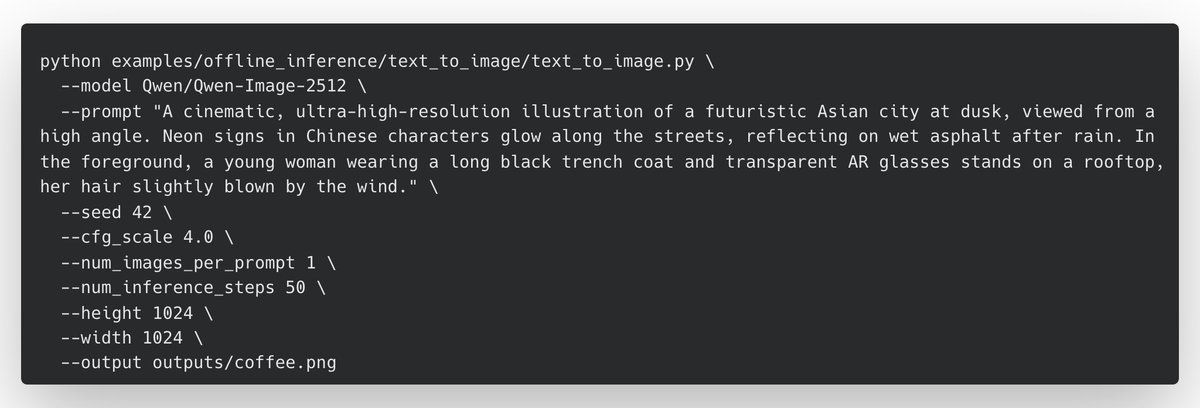
Qwen-Image-2512
关于 vLLM-Omini,我也详细写过


















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










