




 本文介绍了深度学习中的线性回归,包括一维线性回归的原理和Pytorch实现,以及如何通过线性回归进行多项式回归以提高拟合精度。通过实例展示了数据准备、模型创建、训练过程以及最终的预测效果。
本文介绍了深度学习中的线性回归,包括一维线性回归的原理和Pytorch实现,以及如何通过线性回归进行多项式回归以提高拟合精度。通过实例展示了数据准备、模型创建、训练过程以及最终的预测效果。
随着人工智能的发展,深度学习变得越来越炙手可热,所以博主也来凑一下热闹,抽空开始进行深度学习,下面是我自己 的一些学习经验分享,如果有错,请各位看官勿喷,帮忙指出一下,不胜感激。
现在最热的深度学习框架为
T
e
n
s
o
r
F
l
o
w
TensorFlow
TensorFlow、
P
y
t
o
r
c
h
Pytorch
Pytorch 等等,下面我主要写的对象就为
P
y
t
o
r
c
h
Pytorch
Pytorch,内容参考的是廖星宇老师的《深度学习之pytorch》,我觉得这本书内容很基础,也很详细,非常适合初学者入门。
P
y
t
o
r
c
h
Pytorch
Pytorch 基础部分网上有很多教程,我这里就不板门弄斧,后面我会再补上,这里就开始我们这章的主题:线性回归。
一维线性回归
1)原理
线性回归大家应该都不陌生,简单说,就是给定一个数据集
D
=
{
(
x
i
,
y
i
)
}
D=\{(x_i,y_i)\}
D={(xi,yi)},线性回归希望可以找到一个最好的函数
f
(
x
)
f(x)
f(x),使得
f
(
x
)
=
w
x
+
b
f(x)=wx+b
f(x)=wx+b 能尽量多的拟合这些数据点。
我们一般使用向量的形式来表示函数
f
(
x
)
f(x)
f(x):
f
(
x
)
=
w
T
x
+
b
{\text{f}}(x) = {w^T}x + b
f(x)=wTx+b
我们只需要通过不断的调整
w
w
w,
b
b
b,就可以找到最符合条件的点。怎么学习这两个参数呢,其实只需要衡量
f
(
x
i
)
f(x_i)
f(xi),
y
i
y_i
yi 之间的差别, 可以使用均方误差
L
o
s
s
=
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
Loss = \sum\nolimits_{i = 1}^m {{{(f({x_i}) - {y_i})}^2}}
Loss=∑i=1m(f(xi)−yi)2 来衡量,要做的事情就是希望能够找到
w
w
w 和
b
b
b,使得:
(
w
,
b
)
=
arg
min
w
,
b
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
=
arg
min
w
,
b
∑
i
=
1
m
(
y
i
−
w
x
i
−
b
)
2
(w,b) = \mathop {\arg \min }\limits_{w,b} \sum\nolimits_{i = 1}^m {{{(f({x_i}) - {y_i})}^2}} = \mathop {\arg \min }\limits_{w,b} \sum\nolimits_{i = 1}^m {{{({y_i} - w{x_i} - b)}^2}}
(w,b)=w,bargmin∑i=1m(f(xi)−yi)2=w,bargmin∑i=1m(yi−wxi−b)2
现在要求解这个连续函数的最小值,那么只需要求它的偏导数,让它的偏导数等于0来估计它的参数,即:
∂
L
o
s
s
(
w
,
b
)
∂
w
=
2
(
w
∑
i
=
1
m
x
i
2
−
∑
i
=
1
m
(
y
i
−
b
)
x
i
)
=
0
\frac{{\partial Loss(w,b)}}{{\partial w}} = 2(w\sum\limits_{i = 1}^m {x_i^2 - } \sum\limits_{i = 1}^m {({y_i} - b){x_i}} ) = 0
∂w∂Loss(w,b)=2(wi=1∑mxi2−i=1∑m(yi−b)xi)=0
∂
L
o
s
s
(
w
,
b
)
∂
b
=
2
(
m
b
−
∑
i
=
1
m
(
y
i
−
w
x
i
)
)
=
0
\frac{{\partial Loss(w,b)}}{{\partial b}} = 2(mb - \sum\limits_{i = 1}^m {({y_i} - w{x_i}} )) = 0
∂b∂Loss(w,b)=2(mb−i=1∑m(yi−wxi))=0
2)实现
首先创建一些数据点:
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042 ],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827], [3.465],
[1.65], [2.904], [1.3]], dtype=np.float32)我们可以看看产生的这些离散的数据点:
plt.scatter(x_train, y_train, color="r")
plt.xlabel("X")
plt.ylabel("Y")
plt.show()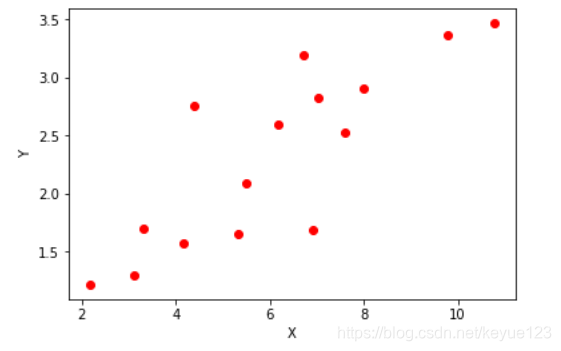
有了数据,我们就可以开始创建模型:
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # 输入和输出的维度都是1
def forward(self, x):
out = self.linear(x)
return out上面我们定义了一个简单的模型 y = w x + b y=wx+b y=wx+b , 输入输出参数都是一维,当然这里可以根据我们想要的输入输出维度进行更改。同时可以根据电脑有没有英伟达的 G P U GPU GPU,来决定使用 C P U CPU CPU 还是 G P U GPU GPU 训练:
if torch.cuda.is_available():
model = LinearRegression().cuda()
else:
model = LinearRegression()模型创建好之后,我们需要定义优化函数和损失函数,在 p y t o r c h pytorch pytorch 中提供了 t o r c h . o p t i m torch.optim torch.optim 方法优化我们的神经网络,我们可以直接使用,感兴趣的可以看看深度学习——优化器算法Optimizer详解:
criterion = nn.MSELoss() # 损失函数
optimizer = torch.optim.SGD(model.parameters(), 1e-3) # 优化函数接下来我们就可以开始训练模型了,前面生成的数据为 numpy,需要将其转化为深度学习支持的 tensor:
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)模型训练,我们这里定义训练6000次:
num_epochs = 6000
for epoch in range(num_epochs):
x_train = Variable(x_train) # 将数据变为 Variable
y_train = Variable(y_train)
output = model(x_train) # 训练模型
loss = criterion(output, y_train) # 计算损失
optimizer.zero_grad() # 梯度归零,不然梯度会累加,造成无法收敛
loss.backward() # 进行反向传播,计算损失函数对于网络参数的梯度值
optimizer.step() # 更新参数值
if(epoch + 1) % 200 == 0:
print("loss: ", loss.data)每次训练后的损失如下:
loss: tensor(0.1865)
loss: tensor(0.1848)
loss: tensor(0.1833)
loss: tensor(0.1819)
loss: tensor(0.1806)
loss: tensor(0.1795)
loss: tensor(0.1784)
loss: tensor(0.1775)
loss: tensor(0.1767)
loss: tensor(0.1759)
loss: tensor(0.1752)
loss: tensor(0.1746)
loss: tensor(0.1741)
loss: tensor(0.1735)
loss: tensor(0.1731)
loss: tensor(0.1727)
loss: tensor(0.1723)
loss: tensor(0.1720)
loss: tensor(0.1717)
loss: tensor(0.1714)
loss: tensor(0.1712)
loss: tensor(0.1710)
loss: tensor(0.1708)
loss: tensor(0.1706)
loss: tensor(0.1704)
loss: tensor(0.1703)
loss: tensor(0.1701)
loss: tensor(0.1700)
loss: tensor(0.1699)
loss: tensor(0.1698)训练完成后,我们就得到了一条直线尽可能的靠近这些离散的点,下面可以看看预测的效果:
plt.scatter(x_train.numpy(), y_train.numpy(), color="r", label="origin data")
plt.plot(x_train.numpy(), output.data.numpy(), "b", label="predict data")
plt.show()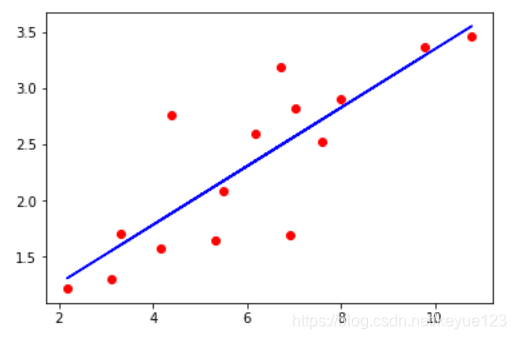
多项式回归
对于一般的线性回归,由于该函数拟合出来的是一条直线,所以精度欠佳,我们可以考虑多项式回归,也就是提高每个属性的次数,原理和上面的线性回归是一样的,只不过这里用的是高次多项式而不是简单的一次线性多项式 。
首先给出我们想要拟合的方程:
y
=
1
+
2
x
+
3
x
2
+
4
x
3
y = 1 + 2x + 3{x^2} + 4{x^3}
y=1+2x+3x2+4x3
然后可以设置参数方程:
y
=
b
+
w
1
x
+
w
2
x
2
+
w
3
x
3
y = b + w_1x + w_2{x^2} + w_3{x^3}
y=b+w1x+w2x2+w3x3
可以看到,上述方程与线性回归方程并没有本质区别。所以我们可以采用线性回归的方式来进行多项式的拟合,下面的代码实现,我就不一一细讲了。
w_target = np.array([2, 3, 4]) # 定义参数
b_target = np.array([1]) # 定义参数
f_y = 'y = {:.2f} + {:.2f} * x + {:.2f} * x^2 + {:.2f} * x^3'.format(
b_target[0], w_target[0], w_target[1], w_target[2]) # 打印出函数的式子
print(f_y) 获得实际函数的方程式:
y
=
1.00
+
2.00
∗
x
+
3.00
∗
x
2
+
4.00
∗
x
3
y = 1.00 + 2.00 * x + 3.00 * x^2 + 4.00 * x^3
y=1.00+2.00∗x+3.00∗x2+4.00∗x3
x_sample = np.arange(-1, 1.1, 0.1)
y_sample = b_target[0] + w_target[0] * x_sample + w_target[1] * x_sample ** 2 + w_target[2] * x_sample ** 3
plt.plot(x_sample, y_sample, label='real curve')
plt.show() # 实际图形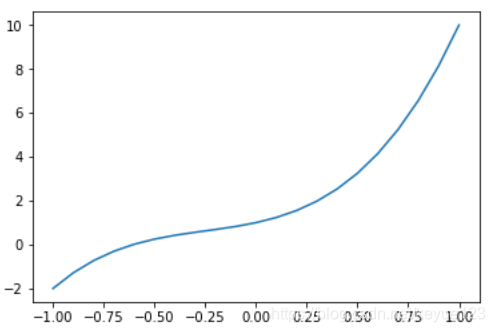
数据准备,我们需要将数据处理成矩阵的方式:
x_train = np.stack([x_sample ** i for i in range(1, 4)], axis=1)
x_train = torch.from_numpy(x_train).float() # 转换成 float tensor
y_train = torch.from_numpy(y_sample).float().unsqueeze(1) # 转化成 float tensor定义参数和模型,在这里模型也可以使用上面一维线性回归的模型创建方式,感兴趣的朋友可以自己尝试以下,我这里就不再次实现了。
w = Variable(torch.randn(3, 1), requires_grad=True)
b = Variable(torch.zeros(1), requires_grad=True)
# 将 x 和 y 转换成 Variable
x_train = Variable(x_train)
y_train = Variable(y_train)
def multi_linear(x):
return torch.mm(x, w) + b定义损失函数与优化函数
criterion = nn.MSELoss() # 损失函数
optimizer = torch.optim.SGD([w, b], lr=1e-3)模型训练
epoch = 0
while True:
y_pred = multi_linear(x_train)
loss = criterion(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch += 1
if loss.data < 0.001:
print('epoch {}, Loss: {:.5f}'.format(epoch, loss.data))
breakepoch 42571, Loss: 0.00100,可以看出最后训练了42571次,损失为1e-3,已经是很精确的,下面我们来看看实际效果:
# 画出更新之后的结果
y_pred = multi_linear(x_train)
plt.plot(x_train.data.numpy()[:, 0], y_pred.data.numpy(), label='fitting curve', color='r')
plt.plot(x_train.data.numpy()[:, 0], y_sample, label='real curve', color='b')
plt.legend()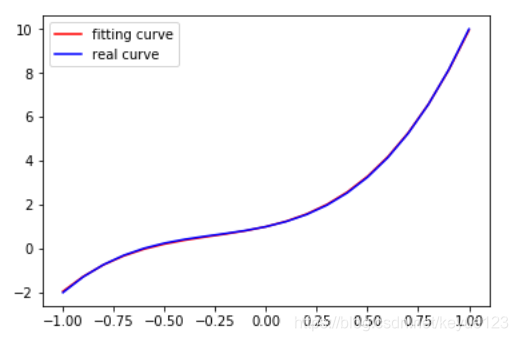


















 4429
4429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










