




 本文介绍了PostgreSQL 9.6后引入的并行处理能力,包括并行顺序扫描、聚合加速和索引扫描的原理及性能提升案例。通过实例展示,展示了如何利用多核优势,以及如何配置以优化查询性能。
本文介绍了PostgreSQL 9.6后引入的并行处理能力,包括并行顺序扫描、聚合加速和索引扫描的原理及性能提升案例。通过实例展示,展示了如何利用多核优势,以及如何配置以优化查询性能。
目录
Components of Parallelism in PostgreSQL
下面是计划的一个例子,当一个聚合被并行计算时。您可以在这里清楚地看到性能的改进。
使用并行聚合,在这个特定的例子中,当涉及到10个并行工作者时,2025419.744的执行时间减少到1737817.346,我们的性能提升略高于16% 。
PostgreSQL是最好的对象关系型数据库之一,它的架构是基于进程而不是基于线程。虽然目前几乎所有的数据库系统都利用线程来实现并行性,但PostgreSQL的基于进程的架构是在POSIX线程之前实现的。PostgreSQL在启动时启动一个进程 "postmaster",之后每当有新的客户端连接到PostgreSQL时就会产生一个新的进程。openGauss 这里是通过线程池来做的。
在第10版之前,单个连接中没有并行性。诚然,由于进程的架构,来自不同客户端的多个查询可以有并行性,但它们不能从彼此中获得任何性能上的好处。换句话说,单个查询是串行运行的,没有并行性。这是一个巨大的限制,因为单个查询不能利用多核。PostgreSQL中的并行性是从9.6版本开始引入的。并行性,从某种意义上说,就是一个进程可以有多个线程来查询系统,利用系统中的多核。这使得PostgreSQL具有查询内的并行性。
PostgreSQL的并行性是作为多个功能的一部分来实现的,这些功能包括顺序扫描、聚合和连接。
Components of Parallelism in PostgreSQL
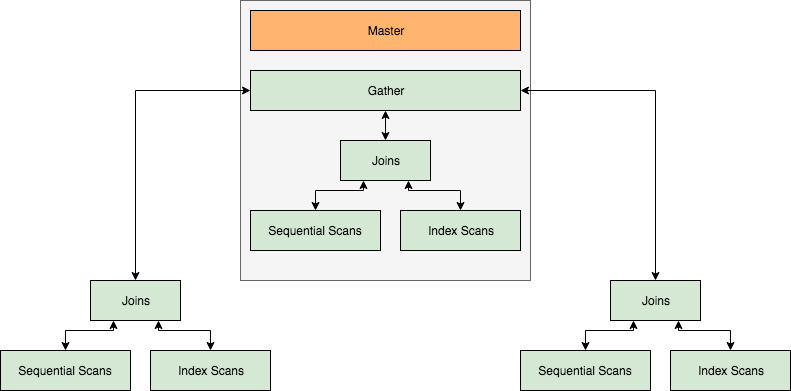
在PostgreSQL中,有三个重要的并行组件。它们是进程本身、聚集(gather)和 workers。在没有并行的情况下,进程本身处理所有的数据,然而,当 planner 决定一个查询或其部分可以被并行化时,它会在计划的可并行化部分中添加一个Gather节点,并使该子树的根节点成为一个Gather节点。 查询的执行从进程(leader)层面开始,计划的所有串行部分都由 leader 运行。然而,如果查询的任何部分(或全部)启用并允许并行,那么将为其分配带有一组 workers 的 gather节点。workers 是与需要并行化的树(部分计划)的一部分并行运行的线程。关系的区块在线程之间进行划分,从而使关系保持顺序性。线程的数量是由PostgreSQL的配置文件中的设置来控制的。工作者使用共享内存进行协调/沟通,一旦 workers 完成了他们的工作,结果就会发给 leader 进行累积。
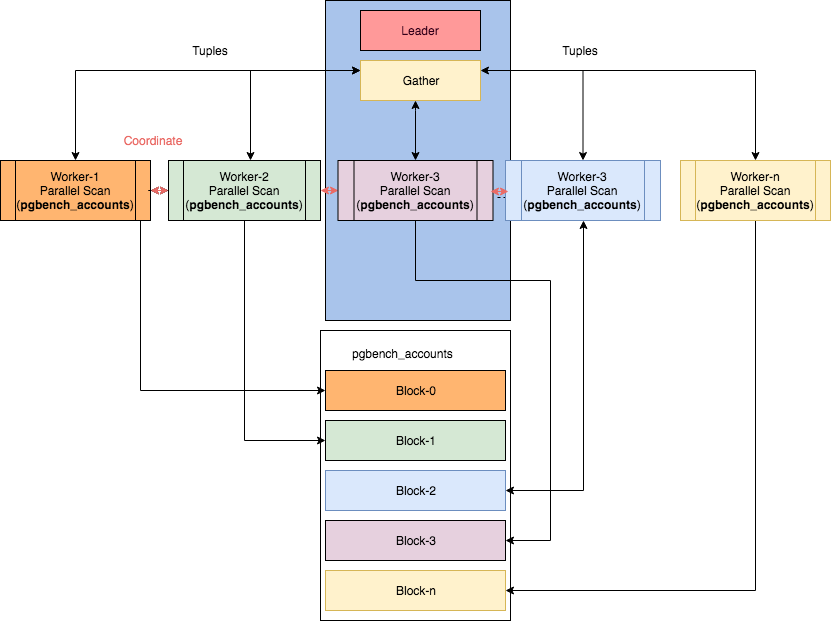
并行顺序Scan
在 PostgreSQL 9.6中,增加了对并行顺序扫描的支持。顺序扫描是对一个表的扫描,其中一个块的序列被一个接一个地求值。就其本质而言,这允许并行性。所以这是第一个并行实现的自然选择。在这种情况下,将在多个工作线程中顺序扫描整个表。下面是一个简单的查询,我们查询 pgbench _ accounts table rows (63165) ,它有1500000000个元组。总执行时间为4343080ms。由于没有定义索引,因此使用顺序扫描。整个表在一个没有线程的进程中进行扫描。因此,不管有多少核心可用,CPU 的单核心都会被使用。
db=# EXPLAIN ANALYZE SELECT *
FROM pgbench_accounts
WHERE abalance > 0;
QUERY PLAN
----------------------------------------------------------------------
Seq Scan on pgbench_accounts (cost=0.00..73708261.04 rows=1 width=97)
(actual time=6868.238..4343052.233 rows=63165 loops=1)
Filter: (abalance > 0)
Rows Removed by Filter: 1499936835
Planning Time: 1.155 ms
Execution Time: 4343080.557 ms
(5 rows)如果这1,500,000,000行在一个进程中使用“10” 个worker 并行扫描会怎样? 这将大大减少执行时间。
db=# EXPLAIN ANALYZE select * from pgbench_accounts where abalance > 0;
QUERY PLAN
----------------------------------------------------------------------
Gather (cost=1000.00..45010087.20 rows=1 width=97)
(actual time=14356.160..1628287.828 rows=63165 loops=1)
Workers Planned: 10
Workers Launched: 10
-> Parallel Seq Scan on pgbench_accounts
(cost=0.00..45009087.10 rows=1 width=97)
(actual time=43694.076..1628068.096 rows=5742 loops=11)
Filter: (abalance > 0)
Rows Removed by Filter: 136357894
Planning Time: 37.714 ms
Execution Time: 1628295.442 ms
(8 rows)现在总的执行时间是1628295 ms; 当使用10个workers线程用于扫描时,性能提升了266%。
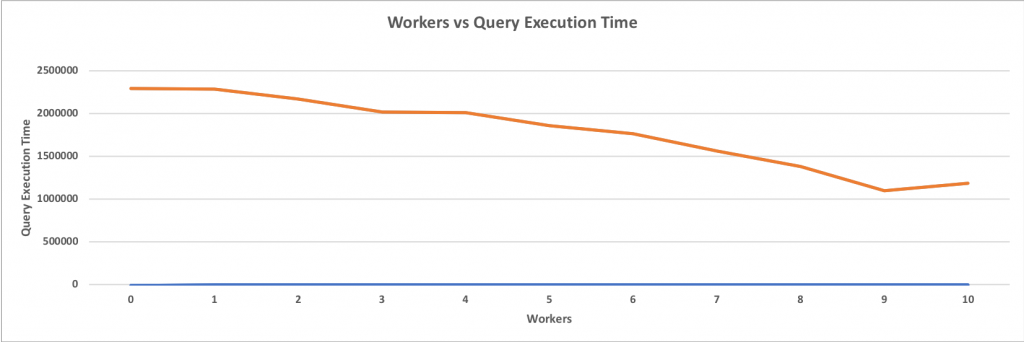
Query used for the Benchmark: SELECT * FROM pgbench_accounts WHERE abalance > 0;
Size of Table: 426GB
Total Rows in Table: 1500000000
The system used for the Benchmark:
CPU: 2 Intel(R) Xeon(R) CPU E5-2643 v2 @ 3.50GHz
RAM: 256GB DDR3 1600
DISK: ST3000NM0033
上图清楚地显示了并行性如何提高顺序扫描的性能。当添加一个工作者时,性能会因为没有并行性而降低,这是可以理解的,但是创建一个额外的gather节点和一个单独的worker会增加开销。但是,对于多个woker线程,性能会显著提高。另外,值得注意的是,性能并不是以线性或指数形式增长的。它逐渐改善,直到增加更多的woker不会有任何性能提升,有点像接近一个水平渐近线。这个基准测试是在一个64核的机器上执行的,很明显,拥有超过10个worker不会带来任何显著的性能提升。
并行聚合 Parallel Aggregates
在数据库中,计算聚合是非常昂贵的操作。如果在单个进程中进行计算,则需要相当长的时间。在 PostgreSQL 9.6中,通过简单地将这些数据分块(一种分治策略) ,增加了并行计算这些数据的能力。这允许多个工作者在领导者计算基于这些计算的最终值之前计算聚合的部分。从技术上讲,可以将 PartialAggregate 节点添加到计划树中,每个 PartialAggregate 节点获取一个工作者的输出。然后将这些输出发送到组合了多个(所有) PartialAggregate 节点的聚合的 FinalizeAggregate 节点。因此,实际上,并行部分计划包括根节点上的 FinalizeAggregate 节点和一个 Gather 节点,后者将具有 PartialAggregate 节点作为子节点。
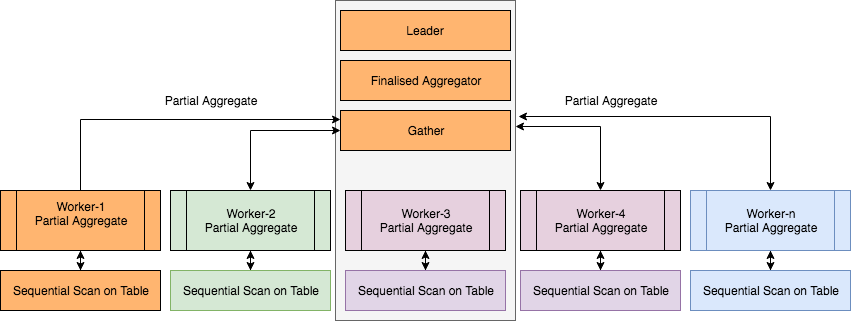
db=# EXPLAIN ANALYZE SELECT count(*) from pgbench_accounts;
QUERY PLAN
----------------------------------------------------------------------
Aggregate (cost=73708261.04..73708261.05 rows=1 width=8)
(actual time=2025408.357..2025408.358 rows=1 loops=1)
-> Seq Scan on pgbench_accounts (cost=0.00..67330666.83 rows=2551037683 width=0)
(actual time=8.162..1963979.618 rows=1500000000 loops=1)
Planning Time: 54.295 ms
Execution Time: 2025419.744 ms
(4 rows)下面是计划的一个例子,当一个聚合被并行计算时。您可以在这里清楚地看到性能的改进。
db=# EXPLAIN ANALYZE SELECT count(*) from pgbench_accounts;
QUERY PLAN
----------------------------------------------------------------------
Finalize Aggregate (cost=45010088.14..45010088.15 rows=1 width=8)
(actual time=1737802.625..1737802.625 rows=1 loops=1)
-> Gather (cost=45010087.10..45010088.11 rows=10 width=8)
(actual time=1737791.426..1737808.572 rows=11 loops=1)
Workers Planned: 10
Workers Launched: 10
-> Partial Aggregate
(cost=45009087.10..45009087.11 rows=1 width=8)
(actual time=1737752.333..1737752.334 rows=1 loops=11)
-> Parallel Seq Scan on pgbench_accounts
(cost=0.00..44371327.68 rows=255103768 width=0)
(actual time=7.037..1731083.005 rows=136363636 loops=11)
Planning Time: 46.031 ms
Execution Time: 1737817.346 ms
(8 rows)使用并行聚合,在这个特定的例子中,当涉及到10个并行worker时,2025419.744的执行时间减少到1737817.346,我们的性能提升略高于16% 。
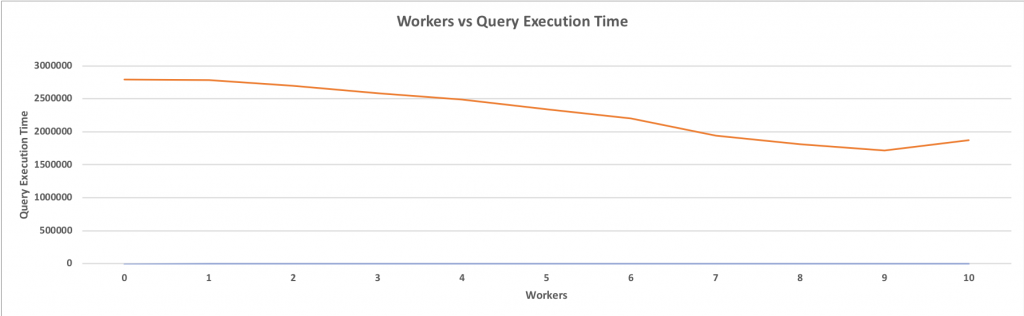
Query used for the Benchmark: SELECT count(*) FROM pgbench_accounts WHERE abalance > 0;
Size of Table: 426GB
Total Rows in Table: 1500000000
The system used for the Benchmark:
CPU: 2 Intel(R) Xeon(R) CPU E5-2643 v2 @ 3.50GHz
RAM: 256GB DDR3 1600
DISK: ST3000NM0033
Parallel Index (B-Tree) Scans
对 B-Tree 索引的并行支持意味着索引页面可以并行扫描。B-Tree 索引是 PostgreSQL 中最常用的索引之一。在一个并行版本的 b 树中,一个工作者扫描 b 树,当它到达叶节点时,它扫描该块并触发被阻塞的等待工作者扫描下一个块。
困惑吗?让我们来看一个例子。假设我们有一个包含 id 和 name 列、18行数据的表 foo。我们在表 foo 的 id 列上创建一个索引。每一行表附加一个系统列 CTID,用于标识行的物理位置。在 CTID 列中有两个值: 块号和偏移量。
postgres=# <strong>SELECT</strong> ctid, id <strong>FROM</strong> foo;
ctid | id
--------+-----
(0,55) | 200
(0,56) | 300
(0,57) | 210
(0,58) | 220
(0,59) | 230
(0,60) | 203
(0,61) | 204
(0,62) | 300
(0,63) | 301
(0,64) | 302
(0,65) | 301
(0,66) | 302
(1,31) | 100
(1,32) | 101
(1,33) | 102
(1,34) | 103
(1,35) | 104
(1,36) | 105
(18 rows)让我们在该表的 id 列上创建 B-Tree 索引。
CREATE INDEX foo_idx ON foo(id)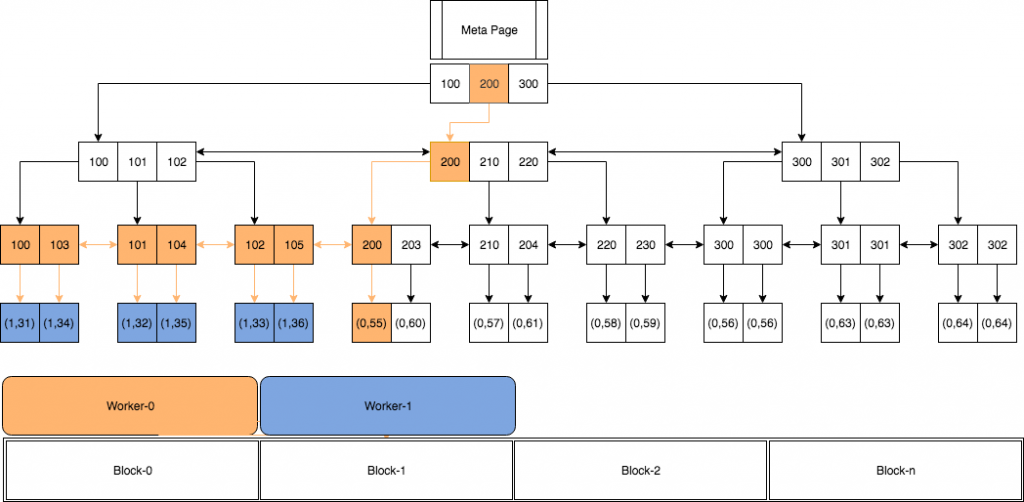
假设我们希望选择 id < = 200的值,其中包含2个工作者。Worker-0将从根节点开始并扫描,直到叶节点200。它将把节点105下的下一个块移交给处于阻塞和等待状态的 Worker-1。如果有其他工人,则将block划分给workers。重复同样的模式,直到扫描完成。
并行位图扫描
为了并行化一个位图堆扫描,我们需要能够以一种非常类似于并行顺序扫描的方式在工作线程之间分块。为此,对一个或多个索引进行扫描,并创建一个指示要访问哪些块的位图。这是由一个先导进程完成的,也就是说,这部分扫描是按顺序运行的。但是,当识别出的块传递给工作线程时,并行性就开始了,这与并行顺序扫描的方式相同。
并行Join
合并联接支持中的并行性也是此版本中添加的最热门的特性之一。在这种情况下,表与其他表的内部循环哈希或合并联接。在任何情况下,内部循环都不支持并行性。整个循环作为一个整体进行扫描,当每个工作线程作为一个整体执行内部循环时,就会出现并行性。每个发送到收集的连接的结果都会累积并产生最终结果。
总结
从我们在本博客中已经讨论过的内容中可以明显看出,并行性为某些方面带来了显著的性能提升,而为其他方面带来了轻微的提升,并且在某些情况下可能会导致性能下降。确保正确设置并行 _setup _ cost 或 parallel _ tuple _ cost,以使查询计划器能够选择并行计划。即使在为这些 gui 设置了较低的值之后,如果没有生成并行计划,请参考 PostgreSQL 文档中关于并行性的详细信息。
对于并行计划,您可以获得每个计划节点的每个工作者统计信息,以了解负载是如何在工作者之间分配的。你可以通过 EXPLAIN (分析,详细)来做到这一点。与任何其他性能特性一样,不存在适用于所有工作负载的单一规则。不管需要什么,都应该仔细地对并行性进行配置,并且必须确保获得性能的概率大大高于性能下降的概率。


















 2322
2322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










