




01 有关影像的生成式 AI
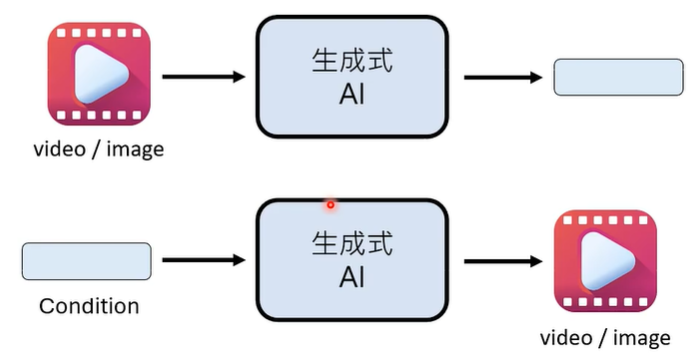
有关影像的生成式 AI 有两种,一种是根据影像生成一些内容,另一种是根据一些内容生成影像。
① 根据影像生成文字

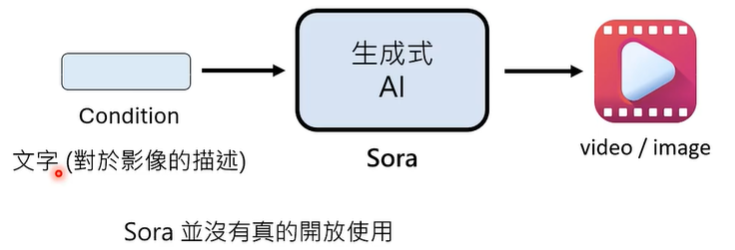
② 根据文字生成影像
一个小怪物在触碰蜡烛
一张纽约沉入海底的街景

一群小狼崽
一些考古学家

③ 根据影像生成影像
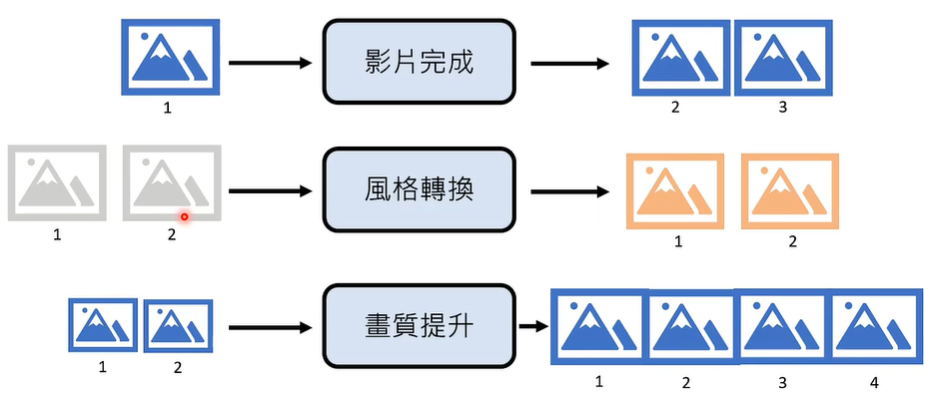
根据影像生成影像可以用做老片修复、画质提升等。
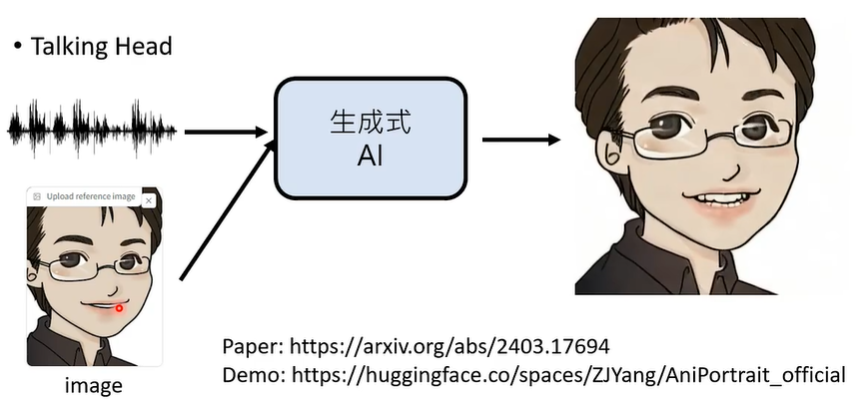
④ 根据录音生成影像(Talking Head)
⑤ 根据其他输入生成影像

02 人工智能如何看影像
图片是由像素所构成,影片是由图片(帧/frame)所构成。
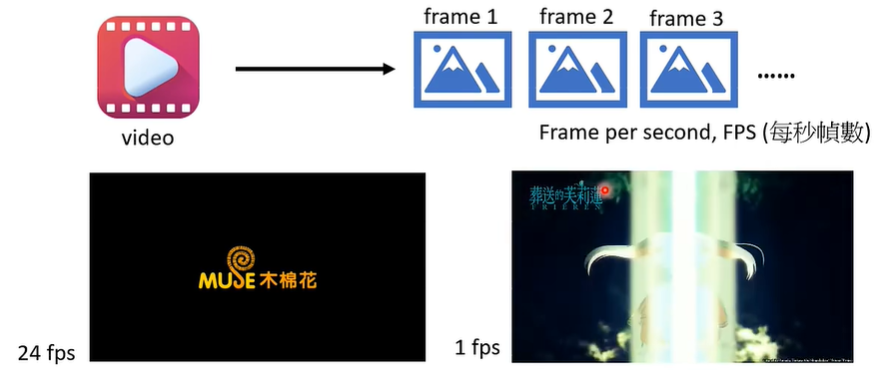
图片可以在宽、高两个维度做压缩。
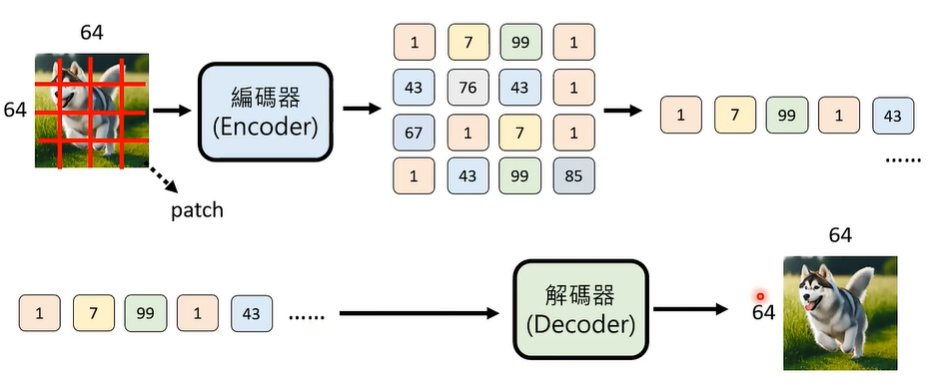
事实上,这里的编码器和解码器都是非常复杂的类神经网络,在计算每一个 patch 时,需要考虑到方方面面的计算。
影片可以在宽、高、时间三个维度做压缩。
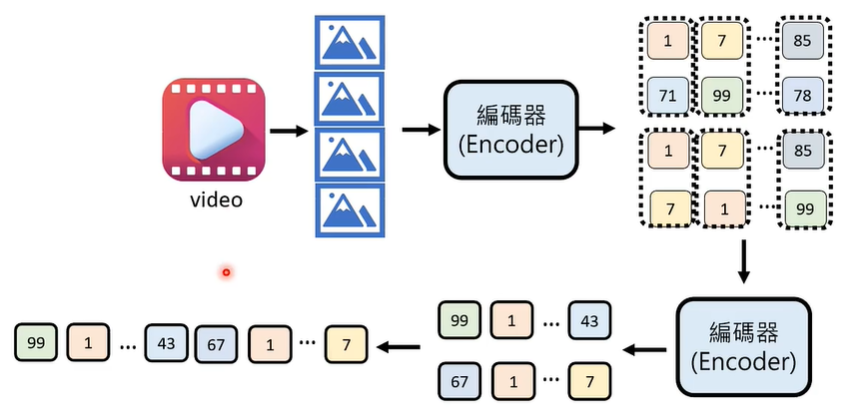
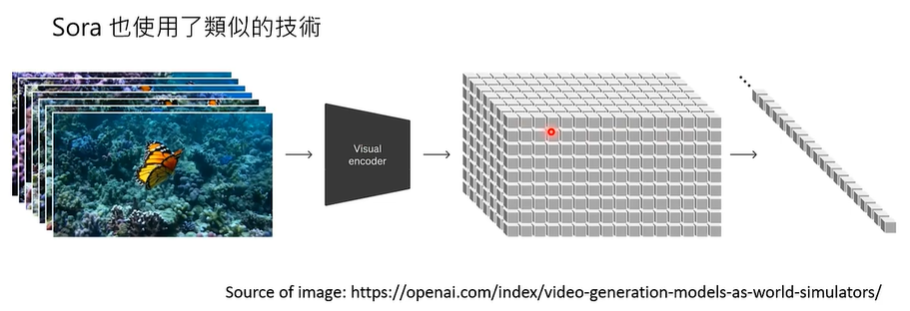
事实上,Sora 也使用了类似的技术,将一大堆图片生成三维立体的压缩,再拉直成一维,塞到解码器里面解码。
03 如何训练根据文字生成图片呢?

事实上,现在已经有大量的、开源的、文字生成图片的资料了,比如 LAION 中有网络搜集的 58 亿张图片,很多公司拿这些资料去做训练,然后被画手告了,因为没有使用权。
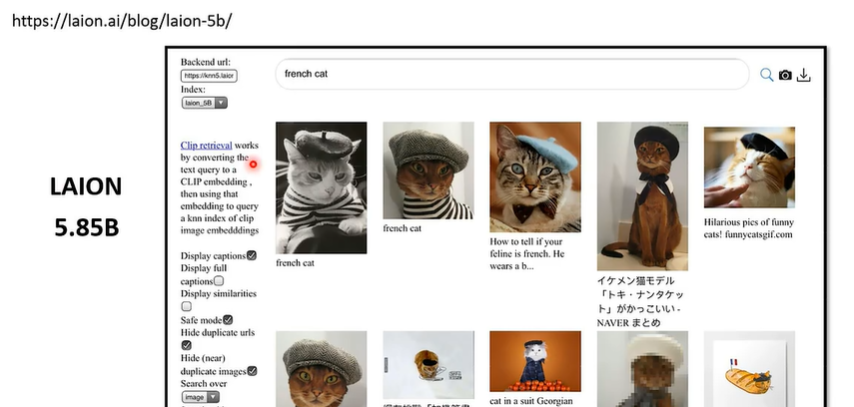
那么,人工智能是怎样训练的呢?
① patch 接龙
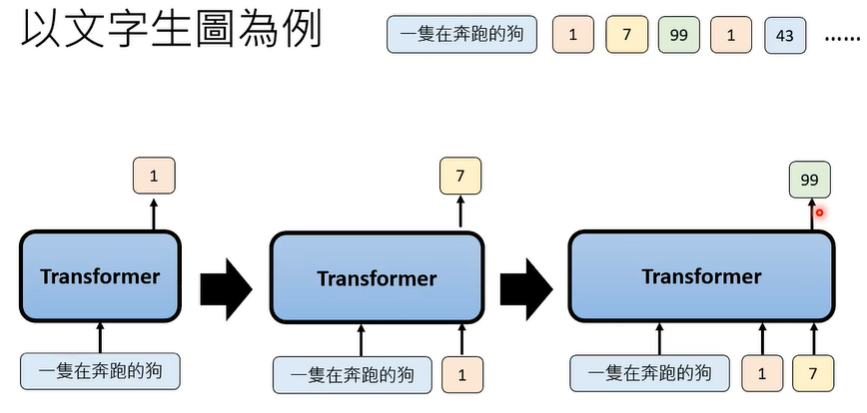
② patch 多位置生成
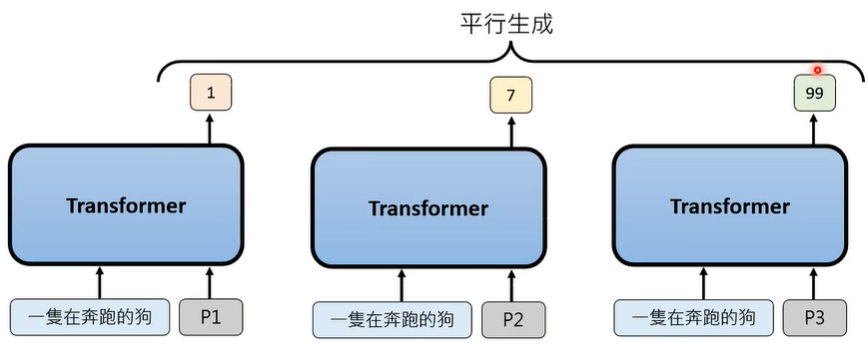
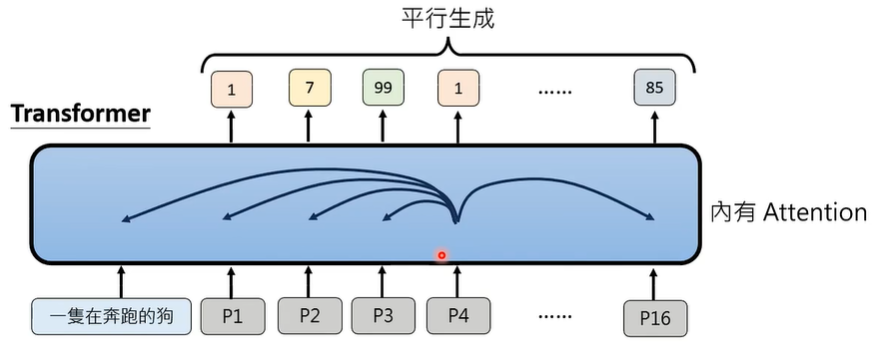
Attention 的作用是,在生成每一个位置的 patch 时,需要考虑到其他位置的 patch。
如何评价影像生成的好坏呢?

我们可以引入一个叫做 CLIP 的模型,其训练资料是大量图片和文字的配对,配对成功打分高,配对失败打分低,这个模型现在已经被开源了。
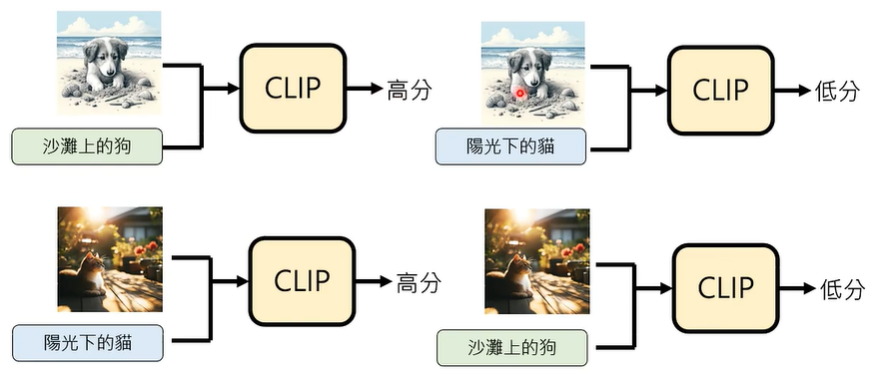
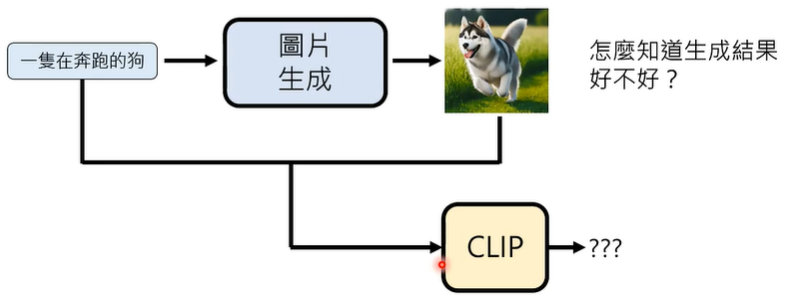
一张图片胜过千言万语,很多时候,图片是无法用语言来描述的,这个时候,因该怎么办呢?


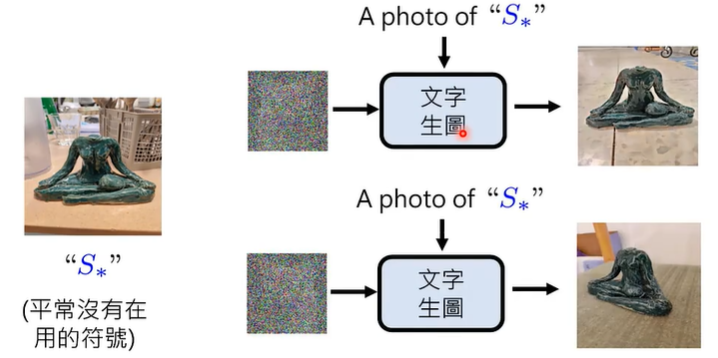
也许,我们可以做个人化的图像生成。
使用平常没有在用的符号代表你要特制化的这个对象,微调你的生成模型,使其理解这个图片,接下来,下达命令生成一些相似的图片,事实证明,三五张图片的训练就可以达到非常好的效果。

04 如何训练根据文字生成影片呢?
文字生成影片实际上是很大的挑战,相比于文字生成图片,生成影片的训练量成指数级增长。
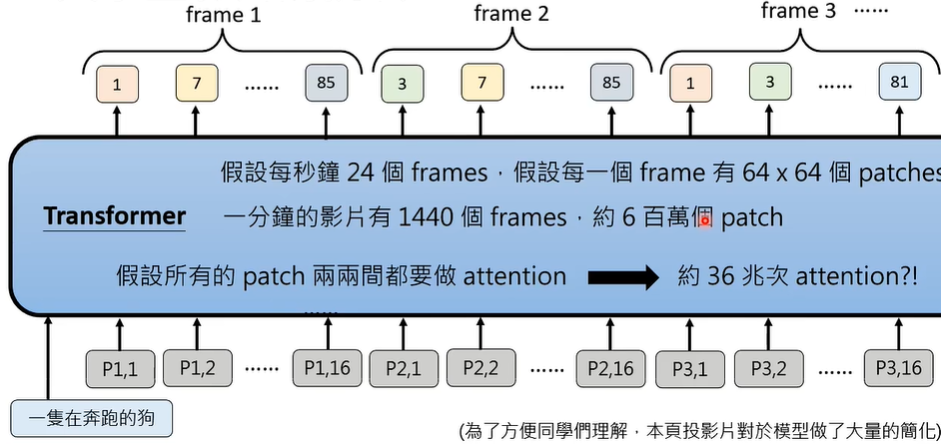
近年来,各个公司和高校的相关研究,都在想尽办法绞尽脑汁地减少运算量。
① 减少 Attention 的运算
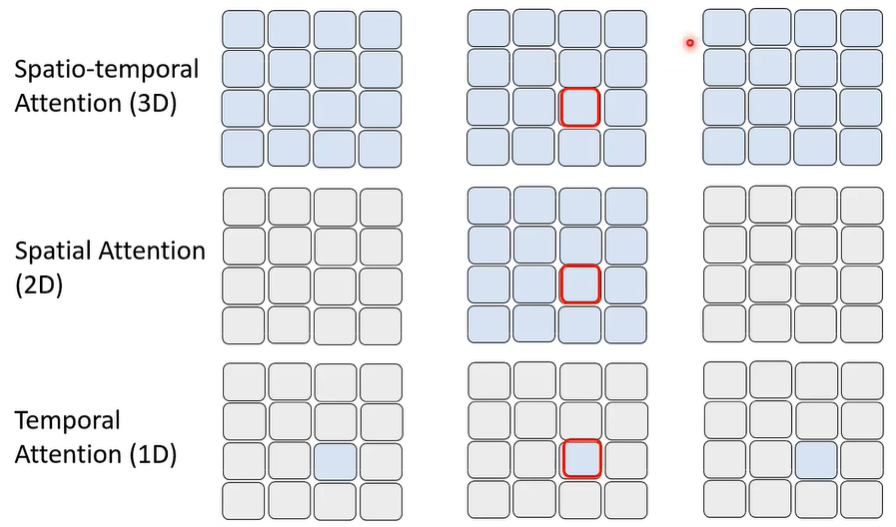
不要管 friend 与 friend 之间的区别,只考虑单个 friend 内部的 patch 之间的关系,或者,考虑另一个 friend 的相同位置的 patch 之间的关系。将两种方法叠加使用,可以创造伪 3D 效果。
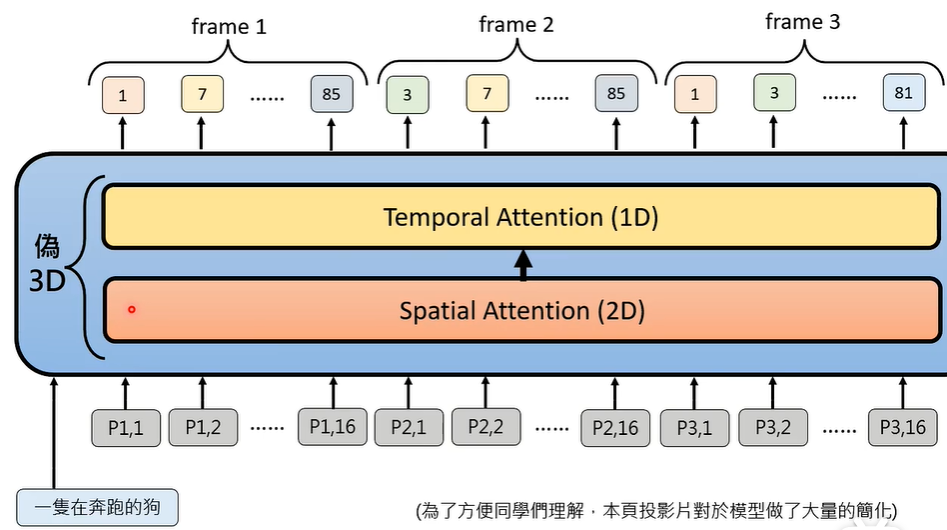

这样以来,大大减少了需要的运算量。
② 拆分多个步骤
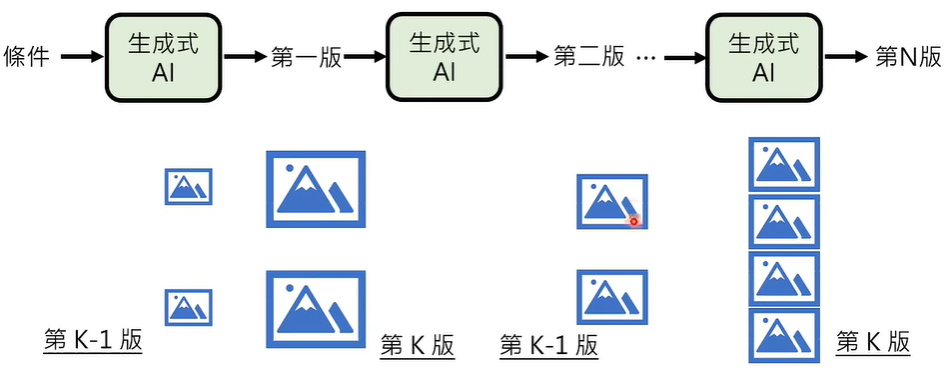
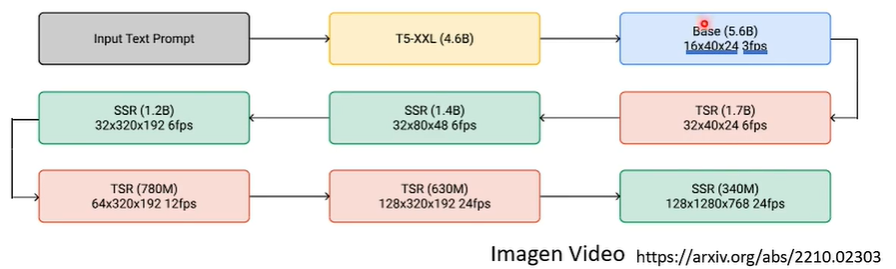
05 一些经典的影像生成方法
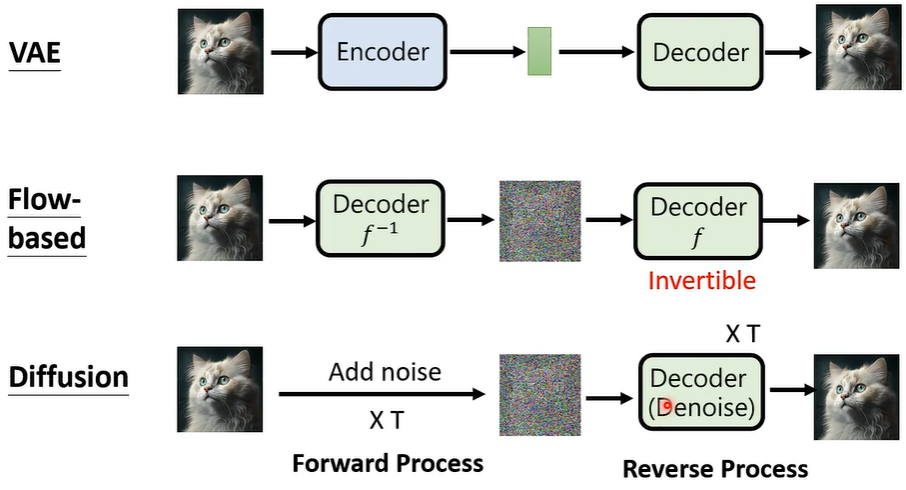
- Variational Auto-encoder (VAE)
- Flow-based Method
- Diffusion Method
- Generative Adversarial Network(GAN)

如何处理图像生成或影片生成的脑补问题呢?也许,我们可以训练一个资讯抽取的模型,将图片-文字中的关键信息提取出来,丢给 AI,让其根据文字生成图片。
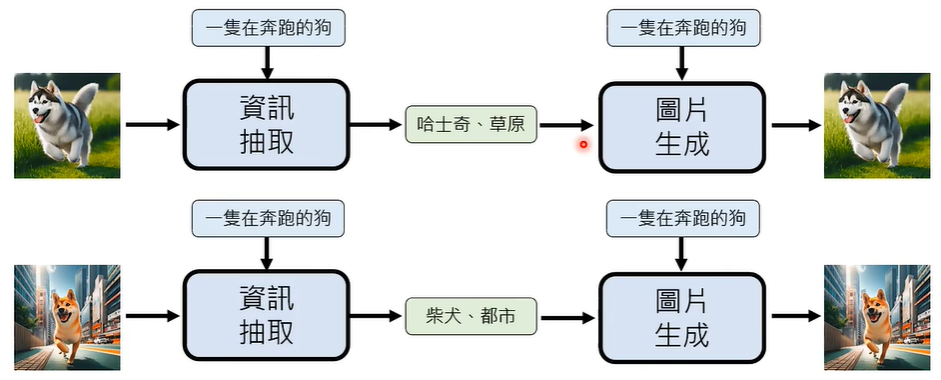
那么,如何训练这个资讯抽取模型呢?
图片生成模型和资讯抽取模型可以一起被训练,二者有一个共同的目标,即输入一张图片,不管内部经历怎样的风云变幻,最终输出一张图片,输出图片和输入图片要尽可能一样。这样的话,我们一下子就训练好了两个模型。
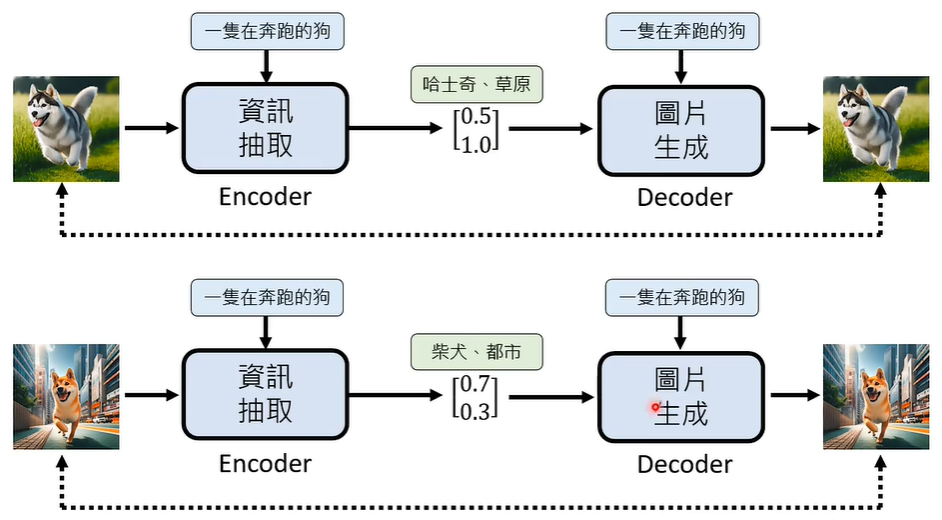
我们在训练的时候,是同时有文字-图片的输入的,但是在测试的时候,只有文字的输入,那么,模型是怎样知道输入的文字描述的是什么意思呢,那些需要脑补的资讯从哪里来呢?
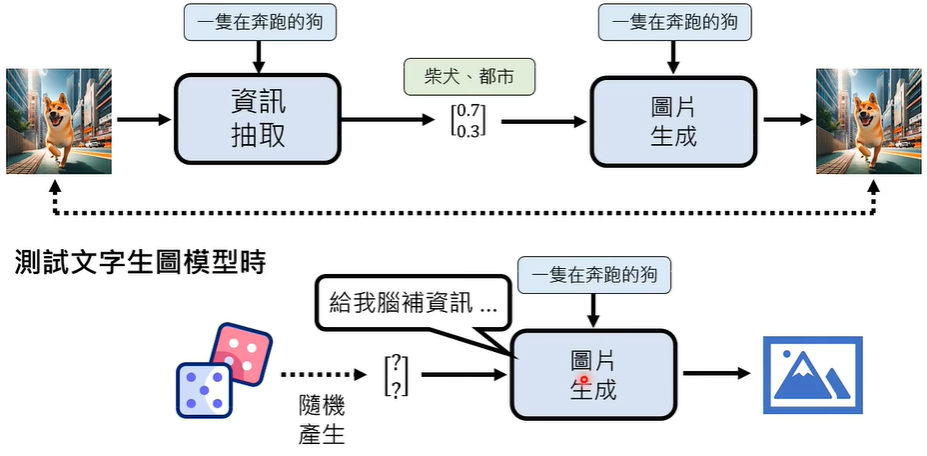
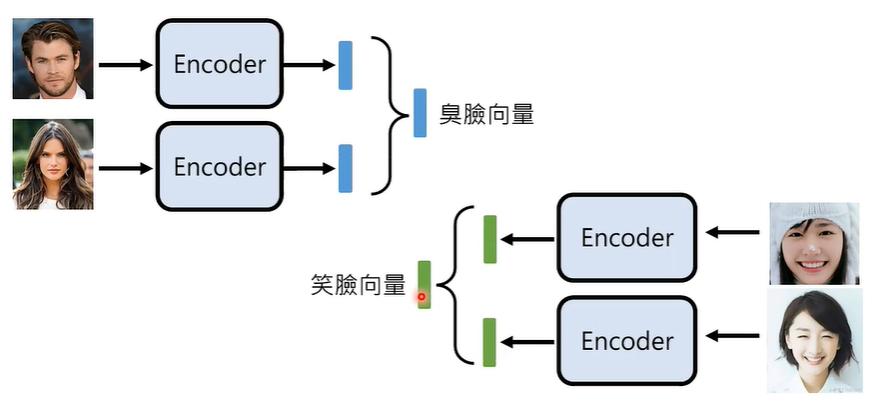
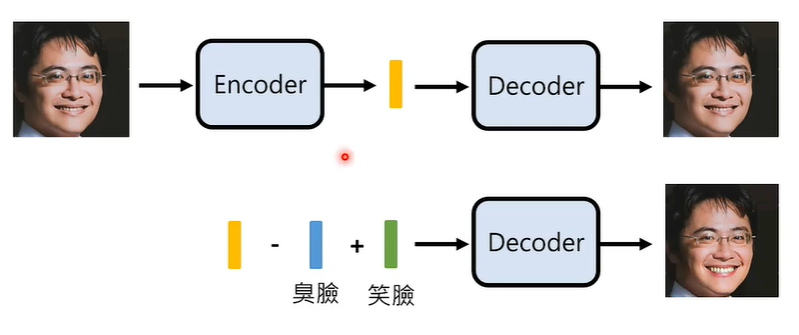
我们知道,资讯抽取模型的输出可能是一堆向量数字,那么,我们在测试时,先通过掷色子随机产生一堆向量数字,在将其代替图片输入到被测试的模型当中,这个模型,就是 VAE。
① Variational Auto-encoder (VAE)
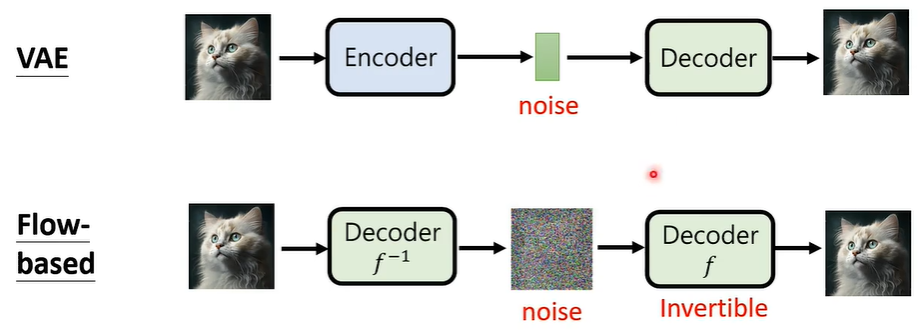
noise 中,包含了关于图片生成的十分重要的资讯。
② Diffusion Model
去除杂讯
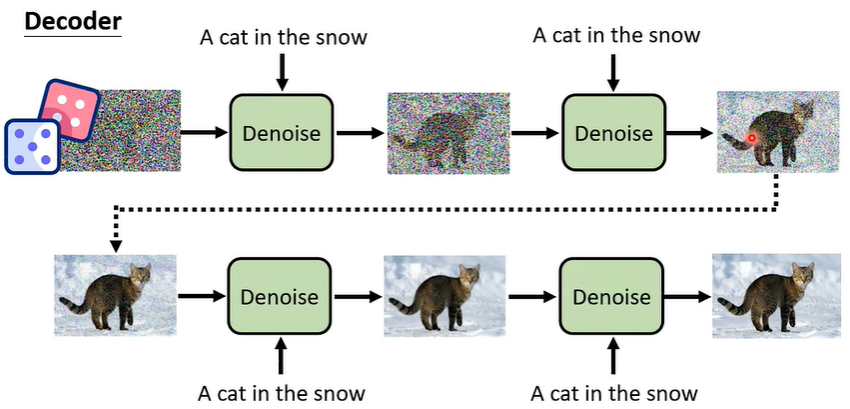
**如何去除杂讯?**你可以自己制造训练资料,结合的类神经网络就是 transformer。
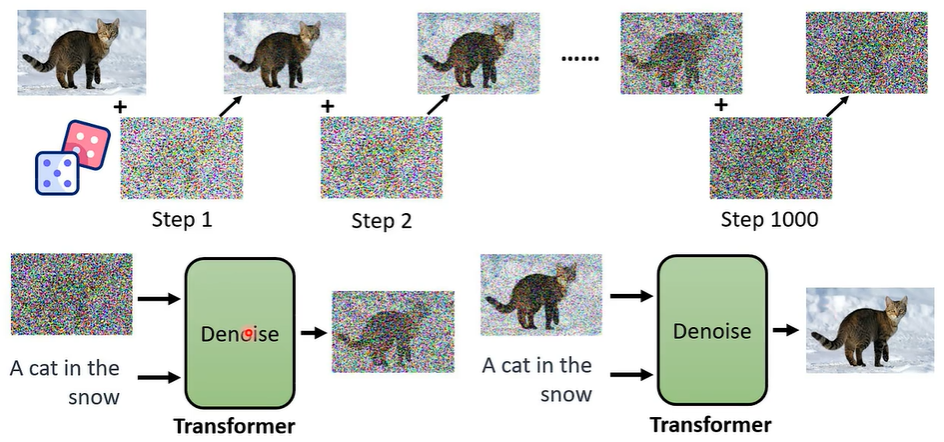
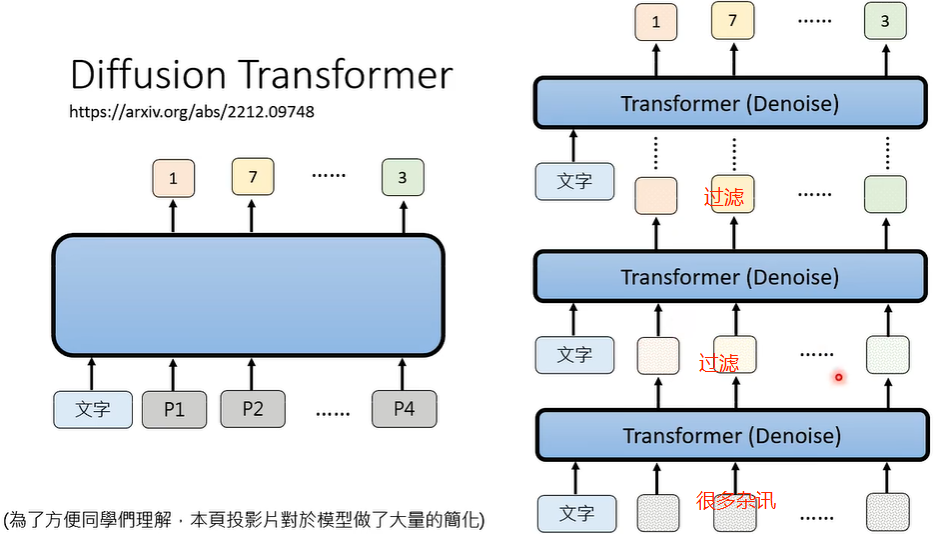
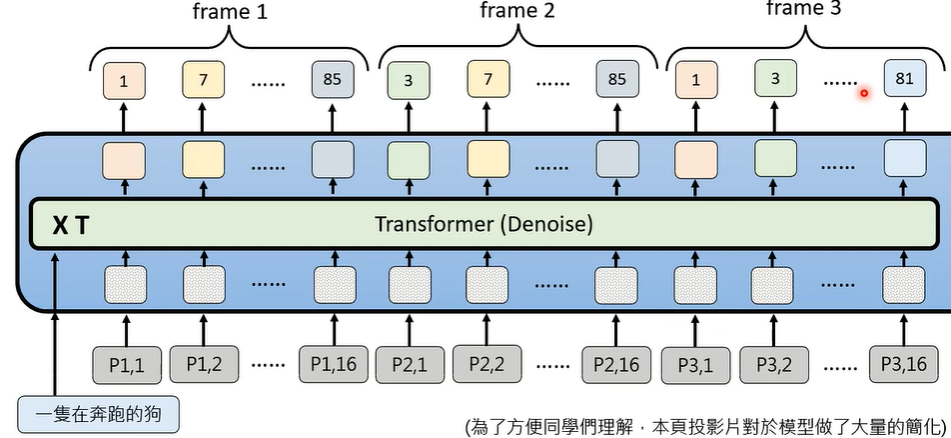
Sora 也是使用类似的原理训练生成影片的。
③ Generative Adversarial Network(GAN)
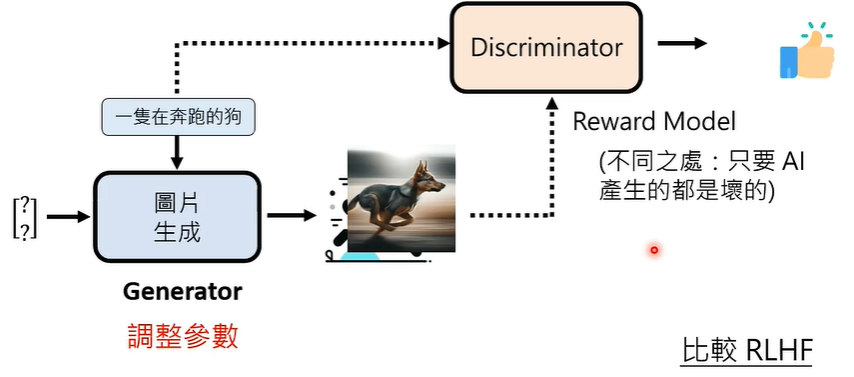
和 CLIP 很相似的是,有一个评价模型叫 Discriminator 对图片-文字配对打分,比如,看到真实的狗说这是好的,看到抽象的狗说这是不好的。
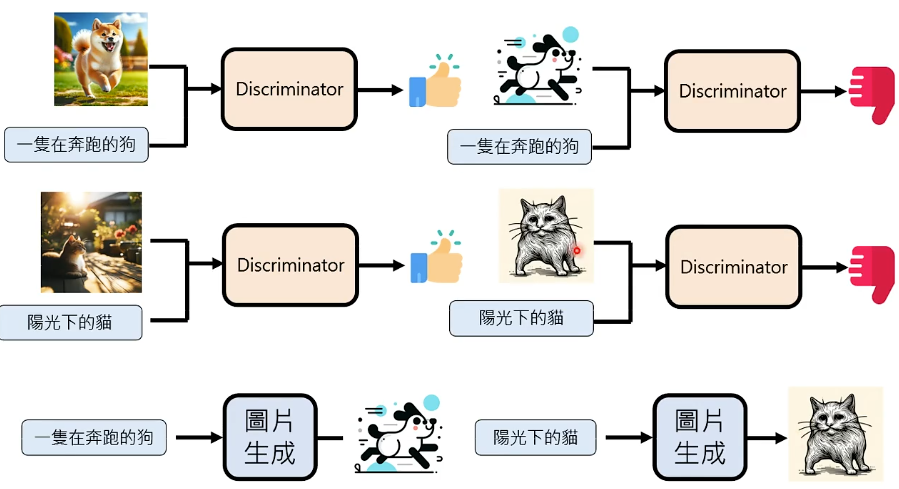
Generator 所做的事情,是不断地生成图片,获得 Discriminator 的评价,根据评价反馈生成新的图片,如此循环,此为 Generator 和 Discriminator 的交替训练, Discriminator 跟那个 Reward Model 差不多,只不过涉及的资料不相同。
对于一个 Generator 来说,还要不要生成随机向量,输入其中呢?不太需要。
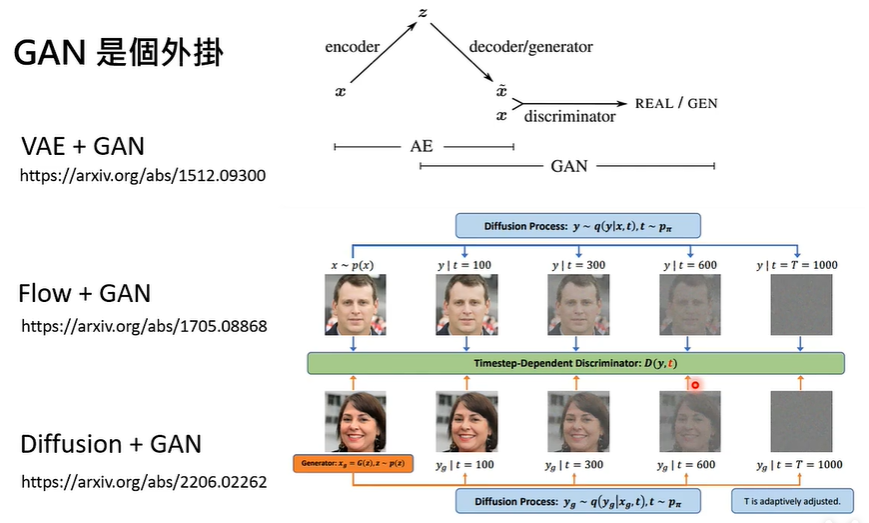
GAN 就像一个外挂,它可以挂在 VAE 上,也可以挂在 Flow 上,也可以挂在 Diffusion 上。

06 有没有可能跟生成的影像有更强的互动呢?

Genie: Generative Interactive Environments
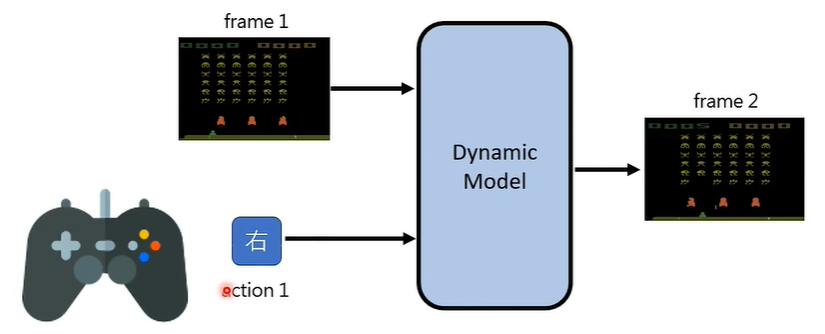
首先,输入一个画面给模型,玩家操作遥感,比如往右,那么就可以生成一个往右的画面,这个画面作为模型新的输入,如此类推,玩家可以自主控制影像生成的结果。
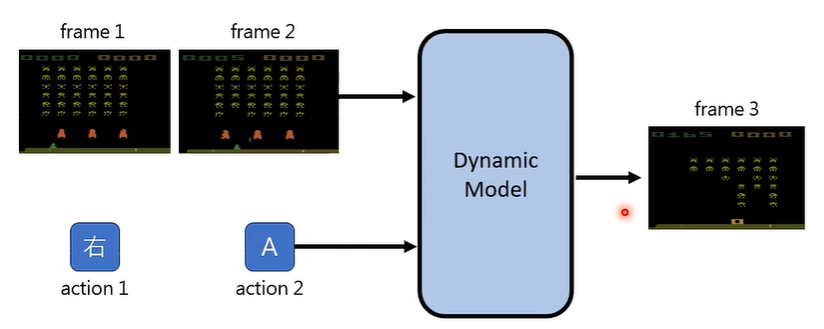
这是一个横向 2D 卷轴游戏,那么,我们应当怎样训练模型呢?
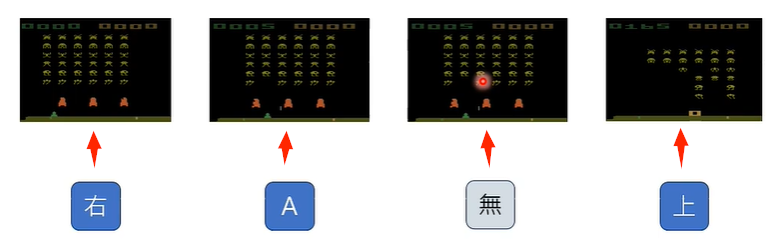
事实上,市场上并没有大量游戏画面和玩家操作配对的资料,因为玩家操作根本没有被记录,那么怎么办呢?答案是,利用前文提到的资讯抽取模型反推玩家在某个画面使用了什么操作!
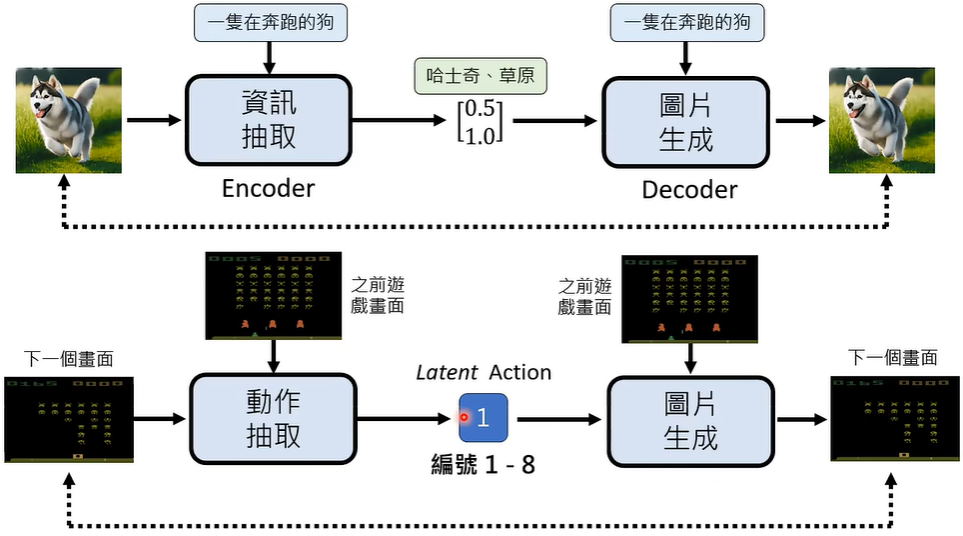
此时,这个 Action 是被 Latent(猜测)出来的,Action 的编号为 1-8,我来猜猜,因该代表↑、↓、←、→、↗、↖、↘、↙。
![pe6-1760190114213)]](https://i-blog.csdnimg.cn/direct/6284904c784d47948c200cf60511b4cb.png)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










