




 超级会员免费看
超级会员免费看
1.理解使用KNN进行分类
KNN特点
- 近邻分类器:一种懒惰学习器,即把未标记的案例归类为与它们最相似的带有标记的案例所在的类。当一个概念很难定义,但你看到它时知道它是什么,就适合用KNN分类。
- KNN优点:简单有效;数据分布无要求;训练快
- KNN缺点:不产生模型(发现特征间关系能力有限);分类慢;内存大;名义变量和缺失值需要处理
- KNN算法将特征处理为一个多维特征空间内的坐标。如标记配料为水果、蔬菜和蛋白3种类型,每种配料有脆度crunshiness和甜度sweetness 2个维度特征,体现在坐标内就是x轴、y轴。
KNN步骤
1)计算距离
距离函数度量:如欧氏距离(最短的直线距离),曼哈顿距离(类似城市街区路线)。欧氏距离公式:
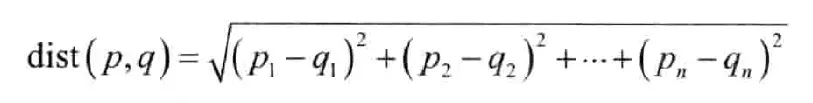
p,q为比较的案例,n为特征
假设我们已知葡萄、绿豆、坚果、橙子等食品的分类和特征(脆度和甜度),现在想知道已知特征(甜度=6,脆度=4)的西红柿属于哪一类?计算与它的几个近邻之间的欧氏距离:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















&spm=1001.2101.3001.5002&articleId=135674608&d=1&t=3&u=b193363e4ae8431b92f85083819fd7fd)
 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












