



0、教程知识架构
这份教程建议按照下面的路线学习:
- 环境部署:先安装 Go,并确认
go version可以正常输出。 - 工程化入门:理解
go.mod、package main、main()、go run、go build。 - 语言基础:掌握变量、常量、基本类型、类型转换、字符串、流程控制、函数。
- 常用数据结构:重点理解数组、切片、map 的区别和使用场景。
- 核心抽象能力:理解指针、结构体、方法、接口、泛型。
- 错误处理:掌握
error、defer、panic/recover的使用边界。 - 并发编程:理解 goroutine、channel、select、WaitGroup、Mutex。
- 标准库:熟悉
fmt、time、encoding/json、net/http等常用库。 - Web 和微服务:掌握 Gin 写 HTTP 接口,了解 gRPC 的 proto、服务端、客户端。
- 测试和调试:掌握单元测试、表格驱动测试、Benchmark、race 检测。
学习建议:
- 每个代码示例都建议手动运行一遍,不要只看。
- 初学阶段优先理解“为什么这么写”,再记语法细节。
- 面试题穿插在对应知识点后面,适合学完后自测。
教程目录
建议按下面顺序学习,不建议一开始就跳到 Gin 或 gRPC:
- 环境部署:安装 Go,配置环境变量,验证
go version。 - Go 工程化入门:理解模块、包、命令、目录结构。
- 语言基础:变量、类型、控制结构、函数、错误处理。
- 核心类型与抽象:指针、结构体、接口、泛型、JSON。
- 并发编程:goroutine、channel、select、context、锁。
- 标准库入门:常用标准库和基础 Web 服务。
- Web 与微服务:Gin 写 HTTP API,gRPC 做服务间通信。
- 测试与调试:单元测试、表格驱动测试、Benchmark、race。
推荐学习方式
- 第一遍:重点跑通示例,知道每个知识点能解决什么问题。
- 第二遍:自己改参数、改返回值、故意写错,看报错信息。
- 第三遍:结合面试题,把概念讲出来。
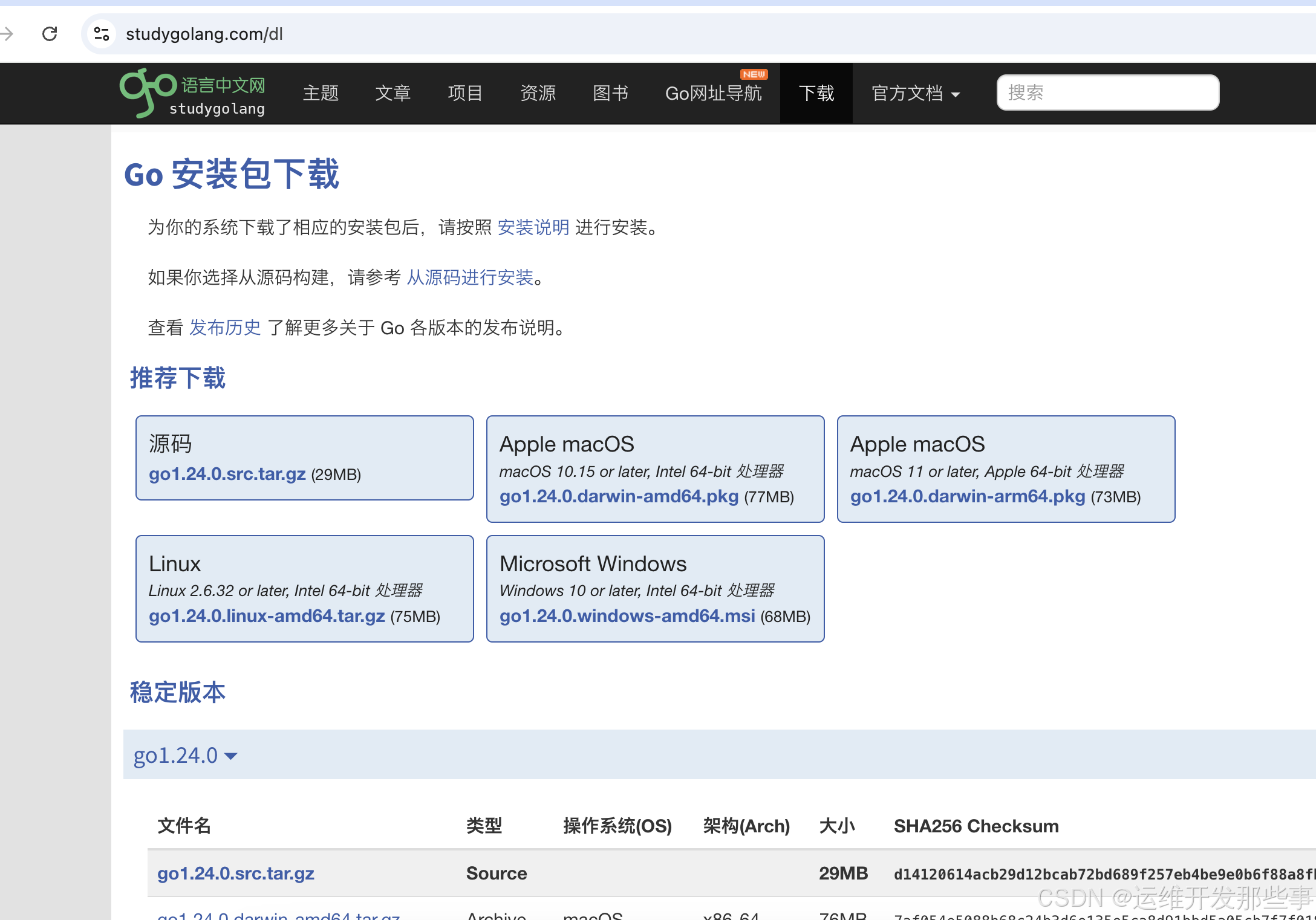
1、环境部署
https://studygolang.com/dl
选择对应的版本
1.1 Linux环境
# 1、下载安装包
wget https://studygolang.com/dl/golang/go1.24.0.linux-amd64.tar.gz
# 2、解压
tar -C /usr/local -xvzf go1.24.0.linux-amd64.tar.gz
# 3、配置环境变量
vim /etc/profile.d/go.sh
export GOROOT=/usr/local/go
export GOPATH=$HOME/go
export PATH=$PATH:$GOROOT/bin:$GOPATH/bin
source /etc/profile.d/go.sh
# 4、验证环境
go version
说明:
- GOROOT:Go 安装目录。这里假设 Go 已安装在 /usr/local/go。
- GOPATH:Go 的工作目录。通常可以设置为用户的 ~/go,用于存放 Go 下载的工具或旧版 GOPATH 项目。
- PATH:更新系统路径,方便在命令行中直接使用 go 命令。
1.2 Windows:
双击 .msi 文件,按照提示安装(默认安装路径:C:\Program Files\Go)。
安装完成后,打开终端(cmd 或 PowerShell),运行 go version,验证安装成功。
1.3 macOS:
双击 .pkg 文件,按照提示安装。
打开终端,运行 go version,验证安装成功。
2、Go 工程化入门:模块、命令与第一个程序
下面会用一个简单的例子,教会大家使用这些基础命令
go mod init :初始化模块
go mod tidy: 下载依赖
go run: 运行文件
go build: 编译打包
go fmt: 格式化代码
go test: 运行测试
go vet: 检查代码中可疑的问题
mkdir /opt/learn_go
cd /opt/learn_go
# 初始化模块
# 会生成go.mod,主要用来记录所用到的依赖
go mod init learn_go
# 打印helloworld
cat >main.go <<EOF
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
EOF
#设置国内镜像源(可选)
go env -w GO111MODULE=on
go env -w GOPROXY=https://goproxy.cn,direct
#下载依赖
go mod tidy
#执行
go run main.go
#编译打包成二进制文件
go build -o myapp
#执行二进制文件
./myapp
#格式化代码
go fmt ./...
#运行测试
go test ./...
#检查代码中潜在问题
go vet ./...
2.1 第一个 Go 程序说明
上面的 main.go 虽然只有几行,但包含了 Go 程序最核心的几个概念:
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
package main:表示这是一个可执行程序。只有main包里定义了main()函数,才能被编译成可直接运行的二进制文件。import "fmt":导入标准库中的fmt包,用来做格式化输入输出。func main():程序入口。执行go run main.go时,会从这里开始运行。go.mod:由go mod init生成,用来记录当前项目的模块名和依赖信息。
常用运行方式:
# 运行当前目录下的 main 包
go run .
# 只运行指定文件
go run main.go
2.2 包和目录
Go 代码通过 package 组织。一般情况下,同一个目录下的 .go 文件应该属于同一个包。
常见规则:
package main:表示当前包可以编译成可执行程序。- 普通包:通常用来封装可复用逻辑,比如
package user、package service。 - 导出标识符:首字母大写的变量、函数、结构体字段可以被其他包访问,比如
UserName;首字母小写只能在当前包内使用。
示例:
package main
import "fmt"
func sayHello() {
fmt.Println("hello")
}
func main() {
sayHello() // hello
}
常见面试题:
问题:Go 里面首字母大小写有什么区别?
答:首字母大写表示可以被其他包访问,首字母小写表示只能在当前包内访问。这是 Go 控制可见性的方式。
2.3 最小项目结构
初学阶段不需要复杂目录,最简单的项目只需要两个文件:
learn_go/
├── go.mod # 记录模块名和依赖
└── main.go # 程序入口
更完整的工程目录(按层分包)会放到第 7 章 Web 与微服务部分介绍,等学到 Gin、gRPC 再看会更有体感。
3、语言基础:变量、类型、流程控制与函数
3.1 变量和常量
变量:
- 声明变量使用 var 或短变量声明(:=)。
- Go 支持类型推导,编译器根据初始值自动推断类型。
示例:
package main
import "fmt"
func main() {
// 显式声明类型
var x int = 10
var name string = "Golang"
// 类型推导:编译器根据初始值推断类型
var y = 3.14 // float64
// 短变量声明(只能在函数内使用)
z := true
fmt.Println(x, name, y, z) // 10 Golang 3.14 true
}
常量:
- 使用 const 定义,值不可更改。
- 通常用于固定值,如数学常数。
示例:
package main
import "fmt"
func main() {
const Pi = 3.14159
const AppName = "MyApp"
fmt.Println(Pi, AppName) // 3.14159 MyApp
}
注意事项:
变量未初始化时,默认值为类型的零值(int 为 0,string 为 “”,bool 为 false)。
短变量声明(:=)只能用于函数内部。
iota 枚举
iota 常用于定义一组连续的常量,适合表示状态、类型、枚举值等。
package main
import "fmt"
// iota 在每个 const 块中从 0 开始,每多一行 +1
const (
StatusPending = iota // 0
StatusRunning // 1
StatusDone // 2
)
func main() {
fmt.Println(StatusPending) // 0
fmt.Println(StatusRunning) // 1
fmt.Println(StatusDone) // 2
}
常见面试题:
问题:var、:=、const 有什么区别?
答:var 用来声明变量,可以在函数内外使用;:= 是短变量声明,只能在函数内部使用;const 用来声明常量,定义后不能修改。
3.2 基本数据类型
Go 的基本数据类型包括:
int:整数(如 1, -100)。
float64:双精度浮点数(如 3.14)。
string:字符串(如 “hello”)。
bool:布尔值(true/false)。
示例:
package main
import "fmt"
func main() {
// 数字类型
age := 25 // int
price := 19.99 // float64
fmt.Printf("age: %T %v\n", age, age) // age: int 25
fmt.Printf("price: %T %v\n", price, price) // price: float64 19.99
// 控制小数点后显示的位数,这里是 2 位
fmt.Printf("Price with 2 decimal places: %.2f\n", price) // Price with 2 decimal places: 19.99
// 字符串
message := "Hello" // string
// 多行字符串:使用反引号包裹,中间的换行和缩进都会被保留
message2 := `
hello
golang
`
isActive := true // bool
fmt.Printf("Age: %d, Price: %.2f, Message: %s, Active: %t\n", age, price, message, isActive)
// 输出:Age: 25, Price: 19.99, Message: Hello, Active: true
fmt.Println(message2)
// 输出(包含前后空行):
// hello
// golang
}
类型转换
Go 是强类型语言,不同类型之间通常不能直接计算,需要显式转换。
package main
import "fmt"
func main() {
var age int = 18
var price float64 = 9.9
// int 和 float64 不能直接相加,需要先转换类型
total := float64(age) + price
fmt.Println(total) // 27.9
// 数字转字符串常用 fmt.Sprintf
msg := fmt.Sprintf("年龄是 %d 岁", age)
fmt.Println(msg) // 年龄是 18 岁
}
零值和 nil
Go 中变量声明后即使不赋值,也会有默认值,这个默认值叫零值。
常见零值:
int的零值是0float64的零值是0string的零值是""bool的零值是false- 指针、切片、map、channel、函数、接口的零值是
nil
package main
import "fmt"
func main() {
var age int // 默认 0
var name string // 默认 ""
var scores []int // 默认 nil
var userInfo map[string]string // 默认 nil
fmt.Println(age) // 0
fmt.Println(name == "") // true
fmt.Println(scores == nil) // true
fmt.Println(userInfo == nil) // true
}
常见面试题:
问题:nil 切片和空切片有什么区别?
答:nil 切片没有分配底层数组,s == nil 为 true;空切片已经初始化,s == nil 为 false。但二者 len 都是 0,也都可以使用 append 添加元素。
字符串类型详解
字符串底层是一个byte数组,所以可以和[]byte类型相互转换
uint8类型,或者byte 型:代表了ASCII码的一个字符。
rune类型:代表一个 UTF-8字符
package main
import "fmt"
func main() {
s := "你好李四"
// 中文字符在 UTF-8 中占 3 个字节,直接用字节切片会乱码。
// 转成 []rune 后,每个元素就是一个字符,下标可以按字符算。
sRune := []rune(s)
fmt.Println("再见" + string(sRune[2:])) // 再见李四
}
字符串常见操作
package main
import (
"fmt"
"strings"
)
func main() {
// 字符串长度 len()
var str = "this is str"
fmt.Println(len(str)) // 11
// 字符串拼接
var str1 = "你好"
var str2 = "golang"
fmt.Println(str1 + ", " + str2) // 你好, golang
fmt.Println(fmt.Sprintf("%s, %s", str1, str2)) // 你好, golang
// 字符串分割 strings.Split()
var s = "123-456-789"
arr := strings.Split(s, "-") // 返回一个字符串切片 []string
fmt.Println(arr) // [123 456 789]
// 遍历字符串
str3 := "Hi, 世"
// 方法 1:for range 遍历(推荐,能正确处理中文等 Unicode 字符)
for index, char := range str3 {
fmt.Printf("位置 %d: 字符 %c, Unicode码点 %U\n", index, char, char)
}
// 输出:
// 位置 0: 字符 H, Unicode码点 U+0048
// 位置 1: 字符 i, Unicode码点 U+0069
// 位置 2: 字符 ,, Unicode码点 U+002C
// 位置 3: 字符 , Unicode码点 U+0020
// 位置 4: 字符 世, Unicode码点 U+4E16
// 方法 2:按字节遍历(中文字符会被拆成多个字节)
for i := 0; i < len(str3); i++ {
fmt.Printf("位置 %d: 字节 %d\n", i, str3[i])
}
// 方法 3:先转成 []rune 再遍历,下标即字符位置
runes := []rune(str3)
for i, r := range runes {
fmt.Printf("位置 %d: 字符 %c\n", i, r)
}
}
3.3 复合数据类型
学习数组、切片、map 时,建议先记住一个大原则:
- 数组是值类型,赋值或传参会复制整个数组。
- 切片、map、channel 更像引用类型,赋值或传参时不会复制底层数据。
- 结构体默认也是值类型,是否修改原始数据取决于传值还是传指针。
3.3.1 数组
数组是指 同一类型数据的集合
Go语言中数组的核心特点:
- 固定长度 - 数组长度在声明时确定,不可更改
- 值类型 - 赋值或传参时会复制整个数组
- 长度是类型的一部分 - [5]int和[10]int是不同类型
- 零值初始化 - 未赋值的元素自动设为零值
- 内存连续存储 - 元素在内存中连续排列
在实际开发中,Go程序员通常更倾向于使用切片(slice),因为它提供了动态长度和引用特性,更加灵活。
示例:
package main
import "fmt"
func main() {
// 定义并使用数组
var numbers = [3]int{1, 2, 3}
fmt.Println(numbers) // [1 2 3]
fmt.Println(numbers[1]) // 2
// 数组是值类型,赋值时会复制整个数组
arr := [3]int{1, 2, 3}
arr2 := arr
arr2[0] = 99
fmt.Println(arr, arr2) // [1 2 3] [99 2 3]
// 遍历数组
scores := [3]int{95, 85, 75}
// 方式 1:传统 for 循环
for i := 0; i < len(scores); i++ {
fmt.Printf("学生%d的成绩: %d\n", i+1, scores[i])
}
// 输出:
// 学生1的成绩: 95
// 学生2的成绩: 85
// 学生3的成绩: 75
// 方式 2:for-range 同时拿到索引和值
for index, score := range scores {
fmt.Printf("学生%d的成绩: %d\n", index+1, score)
}
}
常见面试题:
问题:数组和切片有什么区别?
答:数组长度固定,长度是类型的一部分,赋值会复制整个数组;切片长度可变,底层引用数组,更适合日常开发。
3.3.2 切片(slice)
切片(slice)是Go语言中比数组更灵活的数据结构
切片的核心特点:
- 动态长度 - 可以根据需要增长或缩小
- 引用类型 - 传递切片时只复制切片结构,不复制底层数据
- 底层结构 - 包含三部分:指向底层数组的指针、长度(len)和容量(cap)
- 零值是nil - 未初始化的切片值为nil,长度和容量都为0
- 可以使用append()函数 - 向切片添加元素,必要时会自动扩容
示例:
package main
import "fmt"
func main() {
// 声明切片的四种方式
var a []string // 仅声明,a == nil
f := make([]string, 4) // 用 make 创建,长度为 4
b := []int{} // 字面量初始化的空切片,b != nil
c := []int{1, 2, 3, 4} // 字面量初始化并赋值
fmt.Println(a == nil) // true
fmt.Println(len(f)) // 4
fmt.Println(b == nil) // false
fmt.Println(c) // [1 2 3 4]
// 添加元素
c = append(c, 5)
fmt.Println(c) // [1 2 3 4 5]
// 切片操作 slice[low:high]
// low:起始索引(包含),high:结束索引(不包含)
d := c[1:3]
fmt.Println(d) // [2 3]
fmt.Printf("长度:%d 容量:%d\n", len(d), cap(d)) // 长度:2 容量:4
}
切片常见坑:
- 多个切片可能共享同一个底层数组,修改其中一个可能影响另一个。
append可能触发扩容,扩容后会指向新的底层数组。- 使用
make([]int, len, cap)可以提前指定长度和容量,减少频繁扩容。
常见面试题:
问题:切片扩容时发生了什么?
答:当容量不够时,append 会申请新的底层数组,把旧数据复制过去,再追加新元素。扩容后,新切片可能不再和旧切片共享同一个底层数组。
3.3.3 映射(map)
Map是Go语言中的内置关联数据结构,它提供了键值对的存储方式,类似于其他语言中的哈希表、字典或关联数组。
Map的核心特点:
- 键值对存储 - 每个值都与一个唯一的键关联
- 无序集合 - Map中的元素没有固定顺序
- 引用类型 - 传递Map时只复制引用,不复制数据
- 动态大小 - 会根据需要自动扩容
- 零值是nil - 未初始化的Map值为nil,不能直接使用
- 键类型限制 - 键必须是可比较的类型(如数字、字符串、布尔等)
- 值类型无限制 - 值可以是任何类型
示例:
package main
import "fmt"
func main() {
// 1. 创建 map 的不同方式
scoresEmpty1 := map[string]int{} // 字面量空 map
scoresEmpty2 := make(map[string]int) // make 创建的空 map
fmt.Println(scoresEmpty1, scoresEmpty2) // map[] map[]
scores := map[string]int{
"张三": 85,
"李四": 92,
"王五": 78,
}
fmt.Println("学生成绩:", scores) // 学生成绩: map[张三:85 李四:92 王五:78]
// 2. 添加和修改元素
scores["张三"] = 90
scores["刘六"] = 60
fmt.Println("学生成绩:", scores) // map[刘六:60 张三:90 李四:92 王五:78]
// 3. 获取元素
zhang := scores["张三"]
fmt.Println("张三的成绩:", zhang) // 张三的成绩: 90
// 4. 检查 key 是否存在
score, ok := scores["赵六"]
if ok {
fmt.Println("赵六的成绩:", score)
} else {
fmt.Println("赵六不在成绩单中") // 赵六不在成绩单中
}
// 5. 删除元素
delete(scores, "王五")
fmt.Println("删除王五后:", scores) // map[刘六:60 张三:90 李四:92]
// 6. 遍历 map(顺序是随机的)
for name, s := range scores {
fmt.Printf("%s: 成绩=%d\n", name, s)
}
// 7. 只取 key
for k := range scores {
fmt.Println(k)
}
// 8. 获取 map 长度
fmt.Println("学生人数:", len(scores)) // 学生人数: 3
}
map 常见坑:
- 未初始化的 nil map 不能写入,否则会 panic。
- map 遍历顺序是随机的,不能依赖遍历顺序。
- map 不是并发安全的,多个 goroutine 同时读写需要加锁或使用
sync.Map。
常见面试题:
问题:为什么 map 的 key 必须是可比较类型?
答:map 底层需要通过 key 计算哈希并判断是否相等,所以 key 必须支持 == 比较。切片、map、函数不能作为 map 的 key。
3.4 控制结构
if-else:
支持初始化语句,作用域限于 if 块。
示例:
package main
import "fmt"
func main() {
score := 85
if score >= 90 {
fmt.Println("A")
} else if score >= 60 {
fmt.Println("Pass") // 输出:Pass
} else {
fmt.Println("Fail")
}
}
for 循环:
Go 只有 for 循环,没有 while。
示例:
package main
import "fmt"
func main() {
// 标准 for 循环
for i := 0; i < 3; i++ {
fmt.Println(i)
}
// 输出:0、1、2
// 类似 while 的写法(只有条件判断)
sum := 0
for sum < 3 {
sum++
fmt.Println(sum)
}
// 输出:1、2、3
// 遍历切片
numbers := []int{10, 20, 30}
for index, value := range numbers {
fmt.Printf("Index: %d, Value: %d\n", index, value)
}
// 输出:
// Index: 0, Value: 10
// Index: 1, Value: 20
// Index: 2, Value: 30
}
switch-case:
自动 break,支持各种表达式。
示例:
package main
import "fmt"
func main() {
day := 3
switch day {
case 1:
fmt.Println("Monday")
case 2:
fmt.Println("Tuesday")
case 3:
fmt.Println("Wednesday") // 输出:Wednesday
default:
fmt.Println("Other")
}
}
3.5 函数
使用方法
使用 func 关键字,指定参数和返回值类型。
示例:
package main
import "fmt"
// 普通函数
func add(a int, b int) int {
return a + b
}
func main() {
result := add(2, 3)
fmt.Println(result) // 5
// 匿名函数:把函数赋值给变量
addFunc := func(a int, b int) int {
return a + b
}
fmt.Println(addFunc(1, 2)) // 3
}
多返回值
Go 函数可以返回多个值,最常见的是返回“结果 + 错误”。
package main
import (
"errors"
"fmt"
)
func divide(a int, b int) (int, error) {
if b == 0 {
return 0, errors.New("除数不能为0")
}
return a / b, nil
}
func main() {
result, err := divide(10, 2)
if err != nil {
fmt.Println("计算失败:", err)
return
}
fmt.Println(result) // 5
}
常见面试题:
问题:Go 为什么经常返回两个值,比如 result, err?
答:Go 没有传统的异常机制,通常通过返回 error 让调用方显式处理错误,这样错误处理路径更清晰。
命名返回值
返回值可以提前命名,函数体内直接给它赋值,最后写一个 return 即可。这种写法在写文档和复杂返回时比较常见。
package main
import "fmt"
// result 和 err 是命名返回值,函数开始时会被自动初始化为零值。
func divide(a, b int) (result int, err error) {
if b == 0 {
err = fmt.Errorf("除数不能为0")
return
}
result = a / b
return
}
func main() {
r, err := divide(10, 2)
fmt.Println(r, err) // 5 <nil>
}
注意:命名返回值会让函数变得稍微复杂,初学时优先用普通返回值。
变长参数
函数最后一个参数可以写成 ...T,表示接收任意数量的同类型参数。
package main
import "fmt"
// nums 是一个 []int,调用时可以传 0 个或多个 int。
func sum(nums ...int) int {
total := 0
for _, n := range nums {
total += n
}
return total
}
func main() {
fmt.Println(sum()) // 0
fmt.Println(sum(1, 2, 3)) // 6
fmt.Println(sum(1, 2, 3, 4, 5)) // 15
// 已经有切片时,使用 ... 把切片展开传进去。
nums := []int{10, 20, 30}
fmt.Println(sum(nums...)) // 60
}
fmt.Println 自己也是一个变长参数函数,所以它能接收任意数量的参数。
Init函数和main函数
main函数
Go语言程序的默认入口函数
init函数
go语言中 init函数用于包 (package)的初始化,该函数是go语言的一个重要特性。
有下面的特征:
- init函数是用于程序执行前做包的初始化的函数,比如初始化包里的变量等
- 每个包可以拥有多个init函数
- 同一个包中多个init函数的执行顺序go语言没有明确的定义(说明)
- 不同包的init函数按照包导入的依赖关系决定该初始化函数的执行顺序
- init函数不能被其他函数调用,而是在main函数执行之前,自动被调用
init函数和main函数的异同
相同点:
- 两个函数在定义时不能有任何的参数和返回值,且Go程序自动调用。
不同点:
- init可以应用于任意包中,且可以重复定义多个。
- main函数只能用于main包中,且只能定义一个。
- 两个函数的执行顺序:
对同一个go文件的 init() 调用顺序是从上到下的。
对同一个package中不同文件是按文件名字符串比较“从小到大”顺序调用各文件中的 init() 函数。
对于不同的 package ,如果不相互依赖的话,按照main包中"先 import 的后调用"的顺序调用其包中的init()
如果 package 存在依赖,则先调用最早被依赖的 package 中的 init() ,最后调用 main 函数。
示例:
package main
import "fmt"
func init() {
fmt.Println("init 先执行,通常用来做初始化")
}
func main() {
fmt.Println("main 后执行,是程序入口")
}
输出:
init 先执行,通常用来做初始化
main 后执行,是程序入口
defer
defer 用来延迟执行一段代码,常用于关闭文件、关闭网络连接、释放锁等清理操作。它会在当前函数结束前执行。
package main
import "fmt"
func main() {
fmt.Println("打开文件")
defer fmt.Println("关闭文件")
fmt.Println("读取文件内容")
}
输出顺序:
打开文件
读取文件内容
关闭文件
常见面试题:
问题:多个 defer 的执行顺序是什么?
答:后进先出,类似栈。最后注册的 defer 会最先执行。
闭包
闭包是一个函数能够记住并访问其创建时的环境变量,简单来说,就像一个函数随身带着一个小背包,里面装着它需要的变量。
案例 1:工厂函数
package main
import "fmt"
// makeMultiplier 返回一个会用 factor 做乘法的函数。
func makeMultiplier(factor int) func(int) int {
return func(x int) int {
return x * factor
}
}
func main() {
double := makeMultiplier(2)
triple := makeMultiplier(3)
fmt.Println(double(5)) // 10
fmt.Println(triple(5)) // 15
}
说明:makeMultiplier 是一个工厂函数,它返回一个根据特定因子进行乘法的函数。返回的函数“记住”了创建时传入的 factor 值。
案例2: 计数器
package main
import "fmt"
func makeCounter() func() int {
count := 0
return func() int {
count++
return count
}
}
func main() {
counter := makeCounter()
fmt.Println(counter()) // 1
fmt.Println(counter()) // 2
fmt.Println(counter()) // 3
}
说明:makeCounter 返回了一个函数,这个函数一直记得外层的 count 变量,所以每次调用都会在上一次的基础上加 1。
这个案例只说明一个核心点:闭包可以“记住”函数外面的变量。
3.6 错误处理
error处理
大部分的内置包或者外部包,都有自己的报错处理机制。因此我们使用的任何函数可能报错,这些报错都不应该被忽略,
而是在调用函数的地方,优雅地处理报错
示例:
package main
import (
"fmt"
"net/http"
)
func main() {
resp, err := http.Get("http://example.com/")
if err != nil {
fmt.Println(err)
return
}
defer resp.Body.Close()
fmt.Println(resp)
}
错误包装:
package main
import (
"errors"
"fmt"
)
var ErrUserNotFound = errors.New("用户不存在")
func findUser(id int) error {
if id == 0 {
// %w 会保留原始错误,方便后续用 errors.Is 判断
return fmt.Errorf("查询用户失败: %w", ErrUserNotFound)
}
return nil
}
func main() {
err := findUser(0)
fmt.Println(err) // 查询用户失败: 用户不存在
if errors.Is(err, ErrUserNotFound) {
fmt.Println("可以根据具体错误做特殊处理") // 可以根据具体错误做特殊处理
}
}
常见面试题:
问题:panic 和 error 有什么区别?
答:error 用于可预期、可处理的错误,比如文件不存在、请求失败;panic 用于不可恢复的严重错误,比如数组越界、空指针解引用。业务代码中优先返回 error,不要滥用 panic。
panic/recover
panic 用于触发严重错误,会让程序崩溃;recover 必须在 defer 中调用,用来捕获 panic,让程序继续运行。
简化示例:
package main
import "fmt"
func safeDivide(a, b int) {
// defer 中的匿名函数会在 safeDivide 返回前执行。
// 如果 safeDivide 中发生了 panic,可以在这里捕获。
defer func() {
if r := recover(); r != nil {
fmt.Println("捕获到 panic:", r)
}
}()
fmt.Println(a / b) // 当 b 为 0 时会触发 panic
}
func main() {
safeDivide(10, 2) // 5
safeDivide(10, 0) // 捕获到 panic: runtime error: integer divide by zero
fmt.Println("程序继续运行") // 程序继续运行
}
理解要点:
panic触发时,函数会停止正常执行,开始回溯调用栈并执行每一层的defer。recover()只在defer中有效,能拿到 panic 时传入的值。- 业务代码不要滥用 panic/recover,主要用于框架层兜底(比如 Web 框架自动捕获 handler 中的 panic)。
4、核心类型与抽象:指针、结构体、接口、泛型
4.0 内存分配:new 和 make
写到这一章前,你可能已经用过 make([]int, 3) 或 make(map[string]int)。这里专门把 new 和 make 放在一起讲,方便对照记忆。
阅读提示:本节会出现
*T这种指针写法,如果你还不了解指针,可以先快速浏览,再到 4.1 指针小节学完后回来。
为什么需要它们?看下面的例子:
package main
func main() {
var studentscore map[string]int
studentscore["lisi"] = 80 // 运行时 panic: assignment to entry in nil map
}
var studentscore map[string]int 只声明了 map,但还没有为它分配实际的内存空间,此时它的值是 nil,不能直接写入。
Go 提供了两个内建函数来分配内存:
make:只用于切片、map、channel,返回的是初始化后可以直接用的值。new:可以用于任何类型,返回的是指向零值的指针。
对比:
| 项目 | make | new |
|---|---|---|
| 适用类型 | slice / map / channel | 任意类型 |
| 返回值 | 已经初始化好的值 | 指向零值的指针 *T |
| 是否可以直接使用 | 是 | 是(解引用后) |
代码示例:
package main
import "fmt"
func main() {
// make 用于创建切片、map、channel
slice := make([]int, 3) // 长度为 3 的切片
m := make(map[string]int) // 空的 map
ch := make(chan int, 2) // 缓冲区为 2 的 channel
fmt.Println(slice, m, ch) // [0 0 0] map[] 0xc0000aa000
// new 返回的是指针
ptr := new(int)
fmt.Println(ptr) // 0xc00001a0a8(地址)
fmt.Println(*ptr) // 0
*ptr = 100
fmt.Println(*ptr) // 100
// new 一个结构体,返回的是结构体指针
type User struct {
Name string
Age int
}
u := new(User)
u.Name = "张三"
u.Age = 18
fmt.Println(u) // &{张三 18}
fmt.Println(*u) // {张三 18}
}
什么时候用哪一个?
- 创建切片、map、channel:用
make。 - 创建结构体或基础类型并希望拿到指针:用
new,或者更常见地用&User{}。
常见面试题:
问题:new 和 make 有什么区别?
答:make 只用于切片、map、channel,返回的是已经初始化好的值;new 用于任意类型,返回的是指向零值的指针。
问题:为什么 nil map 不能直接赋值?
答:nil map 没有底层的哈希表结构,写入会触发 panic。需要用 make 或字面量 map[string]int{} 创建后再写入。
4.1 指针(Pointer)
指针是一个变量,其值为另一个变量的内存地址。在 Go 中:
使用 *T 表示指向类型 T 的指针类型
使用 & 运算符获取变量的内存地址
使用 * 运算符解引用指针(获取指针指向的值)
作用:
指针是存储变量内存地址的数据类型,主要作用是允许函数修改外部变量、避免复制大型数据结构
指针使用说明
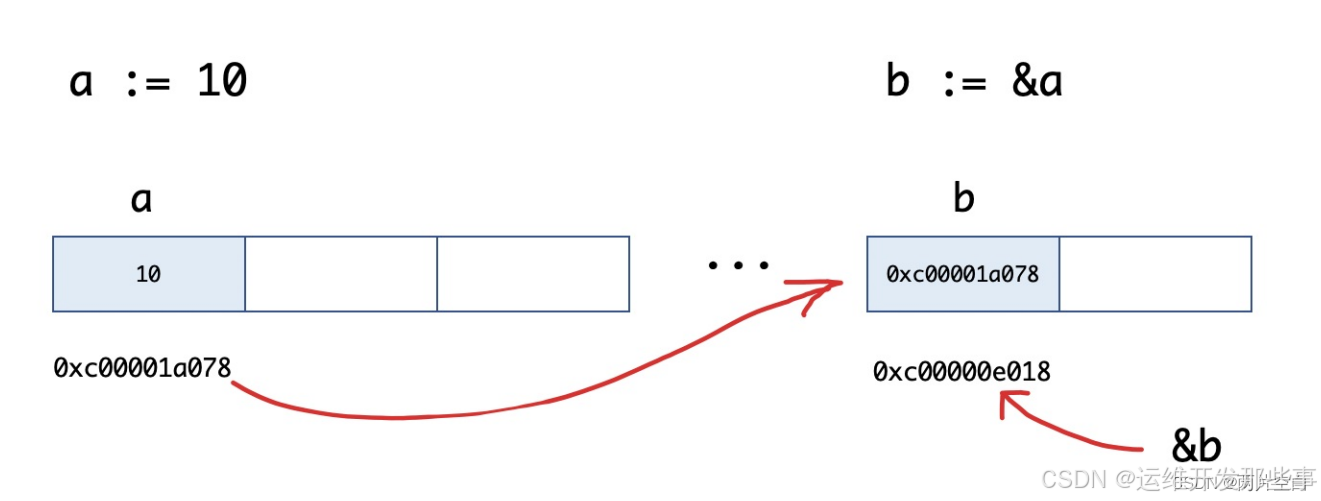
核心概念:(a是一个变量)
- 指针地址:" &a "
- 指针取值: " *&a "
- 指针类型: " *T " , eg: *int
原理如图所示
代码示例:
package main
import "fmt"
func main() {
a := 10
b := &a // b 是指向 a 的指针,存的是 a 的地址
c := *&a // 先取地址再解引用,等价于 a 本身
fmt.Println(a, b, c)
// 输出示例:10 0xc0000a4010 10
// 中间这一段是 a 在内存里的地址,每次运行可能不同。
fmt.Printf("a的类型是%T, b的类型是%T, c的类型是%T\n", a, b, c)
// 输出:a的类型是int, b的类型是*int, c的类型是int
}
提示:
new和make的完整对比已经在 4.0 节单独讲解,这里 4.1 只关注指针本身。
4.2 结构体
结构体定义和初始化
结构体(struct)是一种自定义的数据类型,用来把一组相关的字段组织在一起。
package main
import "fmt"
// 定义一个 Person 结构体
type Person struct {
Name string
Age int
}
func main() {
// 方式 1:字面量初始化(最常用)
p1 := Person{Name: "John", Age: 30}
fmt.Println(p1) // {John 30}
// 方式 2:先声明后赋值
var p2 Person
p2.Name = "Amy"
p2.Age = 25
fmt.Println(p2) // {Amy 25}
// 方式 3:使用 new 创建指针
p3 := new(Person)
p3.Name = "Xiaoming"
p3.Age = 28
fmt.Println(p3) // &{Xiaoming 28}
fmt.Println(*p3) // {Xiaoming 28}
// 方式 4:使用 & 直接得到指针(推荐)
p4 := &Person{Name: "Liuqiang", Age: 32}
fmt.Println(p4) // &{Liuqiang 32}
}
方法(method)
方法可以理解成“绑定到某个类型上的函数”。给结构体定义方法之后,调用方式从 函数(对象) 变成 对象.方法()。
方法分两种:
- 值接收者:方法内修改字段不会影响原结构体。
- 指针接收者:方法内修改字段会影响原结构体。
package main
import "fmt"
type Person struct {
Name string
Age int
}
// 值接收者:方法体里修改 p 不会影响原始结构体。
func (p Person) SayHello() {
fmt.Println("Hello, my name is", p.Name)
}
// 指针接收者:可以修改原始结构体。
func (p *Person) Grow() {
p.Age++
}
func main() {
p := Person{Name: "John", Age: 30}
p.SayHello() // Hello, my name is John
p.Grow()
fmt.Println(p.Age) // 31
// Go 会自动取地址,所以 p.Grow() 等价于 (&p).Grow()
}
经验法则:
- 需要修改字段,或者结构体较大:用指针接收者。
- 只读取小结构体:用值接收者。
- 同一类型的方法尽量统一接收者形式,避免一会儿值一会儿指针。
常见面试题:
问题:值接收者和指针接收者怎么选择?
答:如果方法需要修改结构体字段,使用指针接收者;如果结构体较大,为了避免复制也建议使用指针接收者;如果只是读取小结构体,可以使用值接收者。
问题:方法和函数有什么区别?
答:方法绑定在某个类型上,调用形式是 对象.方法();函数是独立的,调用形式是 函数(参数)。方法本质上可以看成是第一个参数为接收者的函数。
结构体嵌入 / 组合
Go 语言没有传统面向对象里的“继承”,更常用的是结构体嵌入和组合。可以把一个结构体放到另一个结构体中,达到复用字段和方法的效果。
package main
import (
"fmt"
)
type Person struct {
Name string
Age int
}
// 通过嵌入 *Person 进行组合
type Student struct {
*Person
School string
}
// 通过嵌入 Person 进行组合
type Teacher struct {
Person
School string
}
// 注意:嵌入结构体指针和嵌入结构体值有区别。
// 嵌入结构体指针时,赋值后多个对象可能共享同一份 Person;
// 嵌入结构体值时,赋值会复制一份新的 Person。
func main() {
stu := Student{
Person: &Person{Name: "John", Age: 20},
School: "MIT",
}
fmt.Println(stu) // {0xc0000a4060 MIT}
// 嵌入字段可以直接通过结构体名访问
stu.Person.Age = 21
fmt.Println(stu.Person.Age) // 21
tea := Teacher{
Person: Person{Name: "Amy", Age: 30},
School: "Harvard",
}
fmt.Println(tea) // {{Amy 30} Harvard}
tea.Person.Age = 31
fmt.Println(tea.Person.Age) // 31
// 嵌入值类型 vs 嵌入指针类型的区别:
// 嵌入值:赋值会复制一份新的 Person。
tea1 := tea
tea1.Person.Age = 32
fmt.Println(tea1.Person.Age) // 32
fmt.Println(tea.Person.Age) // 31(不受影响)
// 嵌入指针:多个对象共享同一份 Person。
stu1 := stu
stu1.Person.Age = 22
fmt.Println(stu1.Person.Age) // 22
fmt.Println(stu.Person.Age) // 22(一起被改了)
}
常见面试题:
问题:Go 支持继承吗?
答:Go 不支持传统面向对象里的继承,通常通过结构体嵌入和接口实现组合复用。Go 更推荐“组合优于继承”。
结构体 tag
结构体字段后面用反引号包起来的内容叫 tag,是给字段附加的元信息。常见用途:
json:"xxx":序列化/反序列化时使用的字段名。gorm:"column:xxx":ORM 框架用来映射数据库字段。binding:"required":Gin 校验请求参数时用。
package main
import "fmt"
import "reflect"
type User struct {
Name string `json:"name" binding:"required"`
Age int `json:"age"`
}
func main() {
u := User{Name: "张三", Age: 18}
fmt.Println(u) // {张三 18}
// 通过 reflect 也可以读到 tag 内容(一般框架在背后做这件事)
t := reflect.TypeOf(u)
field, _ := t.FieldByName("Name")
fmt.Println(field.Tag.Get("json")) // name
fmt.Println(field.Tag.Get("binding")) // required
}
注意:tag 是字符串,用空格分隔多个 key。tag 内容不会改变结构体本身的行为,需要框架(如 encoding/json、gorm、gin)配合解析才会生效。
encoding/json 包
encoding/json 包可以实现结构体和 JSON 之间的相互转换
package main
import (
"encoding/json"
"fmt"
)
type Person struct {
Name string
Age int
}
// 指定序列化后的字段
type Person2 struct {
Name string `json:"name"`
Age int `json:"age"`
}
func main() {
// 序列化:对象转 JSON
person := Person{Name: "John", Age: 30}
jsonData, err := json.Marshal(person) // 返回值类型是 []byte
if err != nil {
fmt.Println("Error marshalling to JSON:", err)
return
}
fmt.Printf("jsonData type: %T\n", jsonData) // jsonData type: []uint8
fmt.Println(string(jsonData)) // {"Name":"John","Age":30}
// 反序列化:JSON 转对象
// 反引号包围的字符串是原始字符串字面量,不会处理转义字符
jsonStr := `{"Name":"John","Age":30}`
var person2 Person
err = json.Unmarshal([]byte(jsonStr), &person2)
if err != nil {
fmt.Println("Error unmarshalling from JSON:", err)
return
}
fmt.Println(person2) // {John 30}
// 序列化:使用 tag 控制 JSON 字段名
person3 := Person2{Name: "Amy", Age: 30}
jsonData, err = json.Marshal(person3)
if err != nil {
fmt.Println("Error marshalling to JSON:", err)
return
}
fmt.Println(string(jsonData)) // {"name":"Amy","age":30}
// 反序列化:使用 tag 控制 JSON 字段名
jsonStr = `{"name":"Amy","age":30}`
var person4 Person2
err = json.Unmarshal([]byte(jsonStr), &person4)
if err != nil {
fmt.Println("Error unmarshalling from JSON:", err)
return
}
fmt.Println(person4) // {Amy 30}
}
4.3 接口
如何使用
Go 语言中的接口定义是非常简单的,接口定义了一组方法,但是不包含方法的具体实现。实现接口的类型需要提供该接口所定义的所有方法
接口的作用
- 多态性:通过接口,可以让不同的类型实现相同的行为,代码可以对不同类型的对象进行相同的操作。
- 解耦:接口使得代码中的模块和功能解耦,减少了对具体类型的依赖,增强了灵活性和可扩展性。
package main
import (
"fmt"
)
// 定义一个接口 Animal,包含一个 Speak 方法
type Animal interface {
Speak() string
}
// 定义一个函数,传入一个 Animal 类型的参数,并调用其 Speak 方法
func Speak(a Animal) {
fmt.Println(a.Speak())
}
// 定义一个 Dog 结构体,包含一个 Name 字段
type Dog struct {
Name string
}
// 实现 Animal 接口的 Speak 方法
func (d Dog) Speak() string {
return "Woof!"
}
// 定义一个 Cat 结构体,包含一个 Name 字段
type Cat struct {
Name string
}
// 实现 Animal 接口的 Speak 方法
func (c Cat) Speak() string {
return "Meow!"
}
func main() {
dog := Dog{Name: "Rex"}
cat := Cat{Name: "Whiskers"}
// Speak 函数接收 Animal 接口,不管哪个结构体,
// 只要实现了 Animal 接口的 Speak 方法,就可以传入。
Speak(dog) // Woof!
Speak(cat) // Meow!
}
常见面试题:
问题:Go 的接口是显式实现还是隐式实现?
答:Go 是隐式实现。一个类型只要实现了接口要求的所有方法,就自动实现了这个接口,不需要写 implements。
空接口
Golang 中空接口可以表示任意类型,常用于暂时无法确定具体类型的场景。注意:空接口不是泛型;Go 1.18 之后真正的泛型是通过类型参数实现的。
package main
import (
"fmt"
)
// 定义一个函数接收空接口
func print(a interface{}) {
fmt.Println(a)
}
func main() {
print(1) // 1
print("hello") // hello
print(true) // true
// 空接口类型的切片:里面可以放任意类型
a := []interface{}{"nihao", 2, true}
print(a) // [nihao 2 true]
// key 为 string,value 为空接口的 map
b := map[string]interface{}{"name": "张三", "age": 20, "gender": "男"}
print(b) // map[age:20 gender:男 name:张三]
// 结构体字段使用空接口
c := struct {
Name interface{}
}{Name: "张三"}
print(c) // {张三}
}
类型断言
是用来检查接口类型的动态类型
语法:
value, ok := x.(T)
- x 是一个接口类型的变量。
- T 是我们希望断言的目标类型。
- value 是断言成功后的值,如果 x 是 T 类型,value 将包含 x 的值。
- ok 是一个布尔值,如果断言成功,ok 为 true,否则为 false。
如果没有使用 ok 变量,断言失败会导致程序 panic。通过 ok 方式,可以避免这种情况并优雅地处理类型断言失败的情况。
package main
import "fmt"
func main() {
var x interface{} = "Hello, Go!" // 空接口,可以接受任何类型
// 断言 x 是不是 string
if value, ok := x.(string); ok {
fmt.Println("x 是 string:", value) // x 是 string: Hello, Go!
} else {
fmt.Println("x 不是 string")
}
// 断言 x 是不是 int
if value, ok := x.(int); ok {
fmt.Println("x 是 int:", value)
} else {
fmt.Println("x 不是 int") // x 不是 int
}
}
泛型
泛型适合用来写“逻辑相同,只是类型不同”的函数。比如下面的函数既可以打印 int,也可以打印 string。
package main
import "fmt"
func printValue[T any](value T) {
fmt.Println(value)
}
func main() {
printValue(100) // 100
printValue("hello") // hello
}
说明:
T是类型参数,可以理解成一个临时的类型名字。any表示任意类型,等价于interface{}。- 初学阶段不需要大量使用泛型,先知道它是“写通用函数”的工具即可。
常见面试题:
问题:空接口和泛型有什么区别?
答:空接口是在运行时接收任意类型,使用时通常要做类型断言;泛型是在编译期保留类型信息,能写出更安全的通用代码。
5、并发编程:goroutine、channel 与同步
5.1 并发和并行
并发是指多个任务在同一时间段内交替进行,而并行是指多个任务在同一时刻同时进行
5.2 进程、线程、协程
1、进程是操作系统分配资源的最小单位,每个进程有自己的内存空间和资源,进程间相互独立。
2、线程是进程中的执行单位,同一个进程中的线程共享内存和资源,因此线程间的通信和协作更高效。
3、协程是用户级的轻量级线程,协程通过协作式调度,不需要操作系统干预,能够实现高效的并发执行,且开销远低于线程
协程被称为用户级的轻量级线程,是因为:
-
用户级调度:协程的调度由用户程序控制,而不是由操作系统内核控制。操作系统只知道线程的调度,而协程的切换完全是在用户代码中通过程序实现,避免了内核的上下文切换开销。
-
栈空间小:与线程相比,协程占用的内存栈空间非常小。线程需要为每个任务分配独立的内存空间,通常需要几百KB甚至更多,而协程的栈空间可以控制得非常小,通常只需要几KB。
-
上下文切换低成本:线程的上下文切换需要保存和恢复大量的寄存器状态及内核栈,耗费较多的系统资源。而协程的切换只需要保存和恢复一些基本的状态信息(如栈指针、程序计数器等),这一过程由用户空间的库进行管理,因此切换速度更快、开销更低。
-
无需内核干预:线程的调度由操作系统内核完成,涉及内核态和用户态之间的切换,涉及上下文切换和系统调用,这些都需要消耗较多的时间和资源。而协程完全在用户空间调度,避免了内核干预,减少了上下文切换的成本。
5.3 goroutine
- 多线程编程的缺点
- 在 java/c 中我们要实现并发编程的时候,我们通常需要自己维护一个线程池
- 并且需要自己去包装一个又一个的任务,同时需要自己去调度线程执行任务并维护上下文切换
- goroutine
- Goroutine 是 Go 语言中的一种轻量级线程,但 goroutine是由Go的运行时(runtime)调度和管理的。
- Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经 内置了 调度和上下文切换的机制 。
- 在Go语言编程中你不需要去自己写进程、线程、协程,你的技能包里只有一个技能–goroutine
当你需要让某个任务并发执行的时候,只需要把这个任务包装成一个函数,然后开启一个 goroutine 去执行这个函数。
5.4 协程使用
package main
import (
"fmt"
"time"
)
func sayHello() {
fmt.Println("hello goroutine")
}
func main() {
go sayHello()
// 简单等待协程执行完成。实际项目中更推荐使用 WaitGroup 或 channel。
time.Sleep(time.Second)
fmt.Println("main finished")
}
输出(顺序固定):
hello goroutine
main finished
如果去掉 time.Sleep,main 函数会在 goroutine 还没执行时就结束,可能看不到 hello goroutine。
WaitGroup
用于等待一组 goroutines 完成
主要方法:
- Add (int): 增加等待的 goroutine 数量,`` 通常是一个正数,表示将增加多少个 goroutine。
- Done(): 在一个 goroutine 完成时调用,表示这个 goroutine 已经结束,WaitGroup 的计数器减少 1。
- Wait(): 阻塞当前 goroutine,直到 WaitGroup 中的计数器减少到 0,即所有的 goroutines 都完成。
package main
import (
"fmt"
"sync"
"time"
)
func task(i int, waitGroup *sync.WaitGroup) {
// 在函数结束时,调用 Done 方法,减少 WaitGroup 的计数器
defer waitGroup.Done()
fmt.Printf("任务%d开始执行\n", i)
// 模拟任务执行时间 1s
time.Sleep(time.Second * 1)
fmt.Printf("任务%d执行完成\n", i)
}
func main() {
var waitGroup sync.WaitGroup
for i := 1; i <= 5; i++ {
// 每启动一个 goroutine,就先把等待计数加 1。
waitGroup.Add(1)
go task(i, &waitGroup)
}
// 阻塞等待,直到 5 个任务都调用 Done。
waitGroup.Wait()
// 所有 goroutines 完成后,输出
fmt.Println("All tasks finished")
}
运行现象:
- 5 个任务几乎同时开始执行。
- 每个任务睡眠 1 秒后完成。
- 所有任务完成后,才会打印
All tasks finished。
此处跑出一个关于值传递的问题,如果task方法接受的是结构体,go task()传入的也是sync.WaitGroup结构体,会发生什么?
答: waitGroup.Wait()这行会报错 fatal error: all goroutines are asleep - deadlock!
1、sync.WaitGroup 是一个结构体,当按值传递时,会创建一个副本;
2、在副本上调用 Done() 方法不会影响原始的 WaitGroup,所以waitGroup.Wait()永远都没办法结束
3、通过使用指针,我们确保所有协程都在操作同一个 WaitGroup 实例
常见面试题:
问题:goroutine 和线程有什么区别?
答:goroutine 由 Go runtime 调度,初始栈更小,创建成本更低;线程由操作系统调度,创建和切换成本更高。Go runtime 会把大量 goroutine 调度到少量系统线程上执行。
问题:WaitGroup 使用时有哪些注意点?
答:Add 通常要在启动 goroutine 之前调用;每个 goroutine 完成后要调用 Done;WaitGroup 不要按值传递,应该传指针。
5.5 channel
channel 是一种用于在 goroutine 之间传递数据的机制
主要作用:
- 通信:通过 channel,可以让多个 goroutines 之间交换数据。
- 同步:使用 channel 可以使得某个 goroutine 在完成特定操作后通知其他 goroutine,或者等待其他 goroutine 完成任务。
- 阻塞行为:发送和接收数据时会自动阻塞,直到操作可以继续。
用法:
package main
import "fmt"
func main() {
// 创建一个 int 类型的无缓冲 channel
ch := make(chan int)
fmt.Printf("channel: %v, Type: %T\n", ch, ch)
// 输出:channel: 0xc0000b0060, Type: chan int(地址每次运行不同)
// 启动一个协程,向 channel 中写入数据
go func() {
ch <- 1 // 把 1 发送到 channel
}()
// 从 channel 中读取数据(会阻塞,直到有数据可读)
result := <-ch
fmt.Println(result) // 1
}
案例:生产者消费者
可以把 channel 理解成一个队列:生产者往里面放数据,消费者从里面取数据。
package main
import (
"fmt"
"time"
)
// 生产者:做包子
func producer(ch chan string) {
for i := 1; i <= 5; i++ {
bun := fmt.Sprintf("第%d个包子", i)
fmt.Println("生产者做好了", bun)
// 把包子放进 channel。
// 如果没有消费者接收,无缓冲 channel 会在这里阻塞。
ch <- bun
}
// 生产者写完后关闭 channel,消费者的 range 才知道可以结束
close(ch)
}
// 消费者:吃包子
func consumer(ch chan string) {
// range 会一直从 channel 中取数据。
// 当 channel 被关闭并且数据取完后,循环自动结束。
for bun := range ch {
fmt.Println("消费者吃掉了", bun)
time.Sleep(time.Second)
}
fmt.Println("包子吃完了")
}
func main() {
// 无缓冲 channel,可以理解成一个只能当面交接的窗口:
// 生产者递一个,消费者接一个。
ch := make(chan string)
// 生产者放到 goroutine 中运行,否则会因为没人接收而阻塞。
go producer(ch)
// 消费者放在 main goroutine 中运行,可以保证 main 等到消费结束再退出。
consumer(ch)
}
这里没有把消费者放到 goroutine 里,是为了让 main 函数等待消费完成。初学时可以先记住:main 函数结束,整个程序就结束。
无缓冲 channel 和有缓冲 channel
// 无缓冲 channel:发送和接收必须同时准备好
ch1 := make(chan int)
// 有缓冲 channel:缓冲区没满时,发送不会阻塞
ch2 := make(chan int, 3)
常见面试题:
问题:向已经关闭的 channel 发送数据会发生什么?
答:会 panic。
问题:从已经关闭的 channel 读取数据会发生什么?
答:可以继续读取。如果缓冲区还有数据,会先读出缓冲区数据;数据读完后,会读到该类型的零值,并且 ok 为 false。
示例:
value, ok := <-ch
if !ok {
fmt.Println("channel 已关闭")
}
5.6 select多路复用
select 语句用于实现多路复用,可以在多个通道(channels)之间进行选择,并且在某个通道准备好进行操作时执行相应的操作。它类似于操作系统中的 I/O 多路复用,使得程序能够同时处理多个事件或任务。
作用:
- 多通道监听:select 可以同时等待多个 channel。
- 阻塞等待:如果没有任何 channel 准备好,select 会阻塞。
- 超时处理:结合
time.After可以避免一直等待。
基本结构:
select {
case value := <-ch1:
// ch1 有数据时执行
fmt.Println(value)
case <-time.After(time.Second):
// 1 秒内没有等到数据时执行
fmt.Println("超时")
}
案例:等待任务完成或超时
package main
import (
"fmt"
"time"
)
func main() {
// done 用来通知 main:任务已经完成。
done := make(chan string)
go func() {
// 模拟任务执行 1 秒。
time.Sleep(time.Second)
done <- "任务完成"
}()
select {
case msg := <-done:
fmt.Println(msg)
case <-time.After(2 * time.Second):
fmt.Println("任务超时")
}
}
说明:
- 如果任务在 2 秒内完成,会打印
任务完成。 - 如果任务超过 2 秒还没完成,会打印
任务超时。 - 初学时先理解 select 的核心作用:同时等待多个 channel,哪个先有结果就先处理哪个。
5.7 context
实际项目中,context 经常用于控制任务超时。
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
select {
case <-time.After(3 * time.Second):
fmt.Println("任务完成")
case <-ctx.Done():
fmt.Println("任务超时:", ctx.Err())
}
}
常见面试题:
问题:context 主要用来解决什么问题?
答:context 主要用来在 goroutine 之间传递取消信号、超时时间和请求级别的数据。常见场景是 HTTP 请求超时、数据库查询超时、服务关闭时通知 goroutine 退出。
5.8 互斥锁
互斥锁(Mutex,Mutual Exclusion Lock)用于保护共享资源,防止多个 goroutine 同时访问或修改共享数据,从而避免数据竞争(data race)问题。Go 的标准库 sync 包提供了 sync.Mutex 类型来实现互斥锁
案例:100 个 goroutine 同时给计数器加 1
package main
import (
"fmt"
"sync"
)
func main() {
var waitGroup sync.WaitGroup
var lock sync.Mutex
num := 0
for i := 1; i <= 100; i++ {
waitGroup.Add(1)
go func() {
defer waitGroup.Done()
// 多个 goroutine 会同时修改 num,所以修改前先加锁。
lock.Lock()
num += 1
// 修改完成后解锁,其他 goroutine 才能继续修改。
lock.Unlock()
}()
}
waitGroup.Wait()
fmt.Println(num) //100
}
常见面试题:
问题:什么是数据竞争?怎么排查?
答:多个 goroutine 同时访问同一份数据,并且至少有一个 goroutine 在写,就可能发生数据竞争。可以用 go test -race 或 go run -race main.go 检测。
问题:Mutex 和 RWMutex 有什么区别?
答:Mutex 是普通互斥锁,同一时间只允许一个 goroutine 访问;RWMutex 是读写锁,允许多个读同时进行,但写操作会独占锁。读多写少的场景可以考虑 RWMutex。
5.9 其他同步工具
除了 Mutex,Go 还提供了一些常用同步工具:
sync.Once:保证某段代码只执行一次,常用于单例初始化。sync.Map:并发安全的 map,适合读多写少或 key 集合变化大的场景。atomic:原子操作,适合简单计数器等场景。
package main
import (
"fmt"
"sync"
)
func main() {
var once sync.Once
for i := 0; i < 3; i++ {
once.Do(func() {
fmt.Println("只会执行一次")
})
}
}
常见面试题:
问题:sync.Once 常用在什么场景?
答:常用于只需要初始化一次的资源,比如配置加载、数据库连接池初始化、单例对象创建等。
6、标准库入门
6.1 fmt
- Println(常用):一次输入多个值的时候 Println 中间有空格,Println 会自动换行
- Print:一次输入多个值的时候 Print 没有 中间有空格,不会自动换行
- Printf(常用):是格式化输出,在很多场景下比 Println 更方便
- Sprintf(常用):是格式化输出,返回字符串,不打印,常用于变量的拼接以及赋值
package main
import "fmt"
func main() {
fmt.Print("zhangsan", "lisi", "wangwu")
// 输出:zhangsanlisiwangwu(注意:参数之间没有空格,也没有换行)
fmt.Println("zhangsan", "lisi", "wangwu")
// 输出:zhangsan lisi wangwu(参数之间空格分隔,最后自动换行)
name := "zhangsan"
age := 20
fmt.Printf("%s 今年 %d 岁\n", name, age)
// 输出:zhangsan 今年 20 岁
info := fmt.Sprintf("姓名:%s, 年龄: %d", name, age)
fmt.Println(info)
// 输出:姓名:zhangsan, 年龄: 20
}
- 格式化符号
%v: 默认格式值。
%T: 变量类型。
%d: 整数。
%f: 浮点数。
%t: 布尔值。
%s: 字符串。
%x, %X: 十六进制表示
6.2 reflect
reflect.TypeOf查看数据类型
package main
import (
"fmt"
"reflect"
)
func main() {
c := 10
fmt.Println(reflect.TypeOf(c)) // int
}
6.3 time
package main
import (
"fmt"
"time"
)
func main() {
// 获取当前时间
now := time.Now()
fmt.Println(now)
// 输出(值会随运行时间不同):2026-06-03 16:00:00.123456789 +0800 CST m=+0.000000001
// 获取年月日时分秒
fmt.Println(now.Year(), now.Month(), now.Day(), now.Hour(), now.Minute(), now.Second())
// 输出示例:2026 June 3 16 0 0
// 格式化时间。Go 的格式串是固定的参考时间:2006-01-02 15:04:05
fmt.Println(now.Format("2006-01-02 15:04:05"))
// 输出示例:2026-06-03 16:00:00
// 当前时间戳(秒)
timestamp := now.Unix()
fmt.Println(timestamp)
// 输出示例:1780000000
}
6.4 strconv
strconv 常用于字符串和数字之间的转换。
package main
import (
"fmt"
"strconv"
)
func main() {
ageStr := "18"
// 字符串转 int
age, err := strconv.Atoi(ageStr)
if err != nil {
fmt.Println("转换失败:", err)
return
}
fmt.Println(age + 1) // 19
fmt.Println(strconv.Itoa(age)) // "18"(int 转字符串)
}
常见面试题:
问题:字符串转 int 用什么?
答:常用 strconv.Atoi。如果需要指定进制和位数,可以用 strconv.ParseInt。
6.5 os 和 io:文件读写
文件读写是后端开发中很常见的操作。
package main
import (
"fmt"
"os"
)
func main() {
// 写文件:把 []byte 写到 hello.txt,0644 是文件权限
content := []byte("hello go")
if err := os.WriteFile("hello.txt", content, 0644); err != nil {
fmt.Println("写文件失败:", err)
return
}
// 读文件:返回 []byte,转成 string 才能正常打印
data, err := os.ReadFile("hello.txt")
if err != nil {
fmt.Println("读文件失败:", err)
return
}
fmt.Println(string(data)) // hello go
}
6.6 net/http
net/http 可以用来发送 HTTP 请求,也可以用来写简单的 Web 服务。
package main
import (
"fmt"
"net/http"
)
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "hello go")
}
func main() {
http.HandleFunc("/hello", hello)
fmt.Println("server start at :8080")
http.ListenAndServe(":8080", nil)
}
运行后访问:
curl http://localhost:8080/hello
7、Web 与微服务入门:Gin 和 gRPC
Go 在后端开发中很常见,常用方向包括:
- 使用 Gin 写 HTTP API,对外提供 RESTful 接口。
- 使用 gRPC 做微服务之间的高性能 RPC 调用。
- 使用
context、日志、配置、数据库、缓存等组件把服务串起来。
建议学习顺序:
- 先用 Gin 写一个能访问的 HTTP 接口。
- 再学习如何接收路径参数、Query 参数和 JSON 请求体。
- 然后学习中间件,理解日志、鉴权这类公共逻辑应该放在哪里。
- 最后再看 gRPC,理解服务之间如何通过 proto 约定接口。
7.0 推荐项目目录结构
写到 Gin、gRPC 这一步,代码量已经比较多,建议按下面的目录组织代码。这种结构在中小型 Go 后端项目里很常见。
learn_go/
├── go.mod # Go 模块文件,记录模块名和依赖
├── main.go # 程序入口,适合放启动逻辑
├── internal/ # 项目内部代码,外部项目无法直接 import
│ ├── handler/ # HTTP 接口处理层,接收请求、返回响应
│ ├── service/ # 业务逻辑层,处理核心业务
│ ├── repository/ # 数据访问层,负责数据库/缓存操作
│ └── model/ # 数据结构定义,比如 User、Order
├── proto/ # gRPC 的 .proto 文件和生成代码
├── config/ # 配置文件,比如 yaml/json/toml
└── pkg/ # 可被其他项目复用的公共代码
每一层的职责:
handler:只处理 HTTP 请求和响应,不写复杂业务。service:写业务规则,比如创建用户、查询用户、修改用户信息。repository:只负责数据读写,比如查询数据库、写 Redis。model:定义数据结构,避免结构体散落在各处。proto:放 gRPC 接口定义,方便服务端和客户端共同使用。
一个请求的大致流转:
HTTP 请求 -> handler -> service -> repository -> 数据库
如果是微服务调用:
HTTP 请求 -> Gin handler -> service -> gRPC client -> 其他微服务
常见面试题:
问题:为什么很多 Go 项目会使用 internal 目录?
答:internal 是 Go 官方支持的特殊目录。放在 internal 下面的代码只能被当前模块内部引用,外部项目不能直接 import,适合放项目内部实现细节。
7.1 Gin 框架
Gin 是 Go 生态中常用的 Web 框架,特点是简单、性能好、上手快。它适合用来写 API 服务、管理后台接口、网关接口等。
安装:
go get github.com/gin-gonic/gin
第一个 Gin 服务
这个例子只做一件事:启动一个 HTTP 服务,访问 /ping 时返回 JSON。
package main
import "github.com/gin-gonic/gin"
func main() {
// gin.Default() 会创建一个默认路由引擎,并自动带上日志和异常恢复中间件。
r := gin.Default()
// 注册 GET /ping 路由。
// 当浏览器或 curl 访问 /ping 时,会执行后面的处理函数。
r.GET("/ping", func(c *gin.Context) {
// c.JSON 用来返回 JSON 响应。
// 200 表示 HTTP 状态码,gin.H 本质上是 map[string]any。
c.JSON(200, gin.H{
"message": "pong",
})
})
// 启动 HTTP 服务,监听 8080 端口。
r.Run(":8080")
}
运行:
go run main.go
另开一个终端访问:
curl http://localhost:8080/ping
返回结果:
{"message":"pong"}
路由参数
路由参数适合查询某个具体资源,比如根据用户 ID 查询用户。
package main
import "github.com/gin-gonic/gin"
func main() {
r := gin.Default()
// :id 是路径参数,可以匹配 /users/1001、/users/abc 等路径。
r.GET("/users/:id", func(c *gin.Context) {
// c.Param("id") 用来获取路径里的 id。
id := c.Param("id")
c.JSON(200, gin.H{
"id": id,
"name": "张三",
})
})
r.Run(":8080")
}
访问:
curl http://localhost:8080/users/1001
返回结果:
{"id":"1001","name":"张三"}
Query 参数
Query 参数常用于搜索、分页、过滤。
package main
import "github.com/gin-gonic/gin"
func main() {
r := gin.Default()
r.GET("/users", func(c *gin.Context) {
// DefaultQuery 表示如果没有传 page,就默认使用 "1"。
page := c.DefaultQuery("page", "1")
// Query 获取 URL 里的查询参数,比如 ?keyword=go。
keyword := c.Query("keyword")
c.JSON(200, gin.H{
"page": page,
"keyword": keyword,
})
})
r.Run(":8080")
}
访问:
curl "http://localhost:8080/users?page=1&keyword=go"
返回结果:
{"keyword":"go","page":"1"}
接收 JSON 请求体
写新增、修改接口时,经常需要接收 JSON 参数。
package main
import "github.com/gin-gonic/gin"
type CreateUserRequest struct {
// json:"name" 表示 JSON 字段名是 name。
// binding:"required" 表示这个字段必传,否则 ShouldBindJSON 会返回错误。
Name string `json:"name" binding:"required"`
Age int `json:"age" binding:"required"`
}
func main() {
r := gin.Default()
r.POST("/users", func(c *gin.Context) {
var req CreateUserRequest
// 把请求体里的 JSON 解析到 req 结构体中。
// 如果 JSON 格式不对,或者 required 字段没传,就返回错误。
if err := c.ShouldBindJSON(&req); err != nil {
c.JSON(400, gin.H{
"error": err.Error(),
})
return
}
c.JSON(200, gin.H{
"message": "创建成功",
"user": req,
})
})
r.Run(":8080")
}
访问:
curl -X POST http://localhost:8080/users \
-H "Content-Type: application/json" \
-d '{"name":"张三","age":18}'
返回结果:
{"message":"创建成功","user":{"name":"张三","age":18}}
中间件
中间件适合处理通用逻辑,比如日志、鉴权、跨域、限流、异常恢复等。
package main
import (
"fmt"
"time"
"github.com/gin-gonic/gin"
)
func costMiddleware() gin.HandlerFunc {
return func(c *gin.Context) {
// 请求进入时记录开始时间。
start := time.Now()
// c.Next() 表示继续执行后面的中间件和真正的业务处理函数。
c.Next()
// 请求处理完成后,计算整个请求耗时。
fmt.Println("请求路径:", c.Request.URL.Path, "耗时:", time.Since(start))
}
}
func main() {
r := gin.Default()
r.Use(costMiddleware())
r.GET("/hello", func(c *gin.Context) {
c.JSON(200, gin.H{"message": "hello gin"})
})
r.Run(":8080")
}
常见面试题:
问题:Gin 中间件的作用是什么?
答:中间件用来处理多个接口都需要的公共逻辑,比如日志、鉴权、跨域、限流、统计请求耗时等。通过 c.Next() 可以继续执行后面的中间件和业务处理函数。
问题:c.Param、c.Query、ShouldBindJSON 有什么区别?
答:c.Param 获取路径参数,比如 /users/:id;c.Query 获取 URL 查询参数,比如 ?page=1;ShouldBindJSON 解析请求体中的 JSON 数据。
7.2 gRPC
gRPC 是一种高性能 RPC 框架,常用于微服务之间通信。它基于 HTTP/2,默认使用 Protocol Buffers 作为接口描述和数据序列化格式。
这部分属于进阶内容,初学时先掌握调用流程即可:
写 proto -> 生成 Go 代码 -> 写服务端 -> 写客户端 -> 调用方法
可以简单理解:
- HTTP API 更像“浏览器/客户端调用服务”。
- gRPC 更像“服务 A 直接调用服务 B 的函数”。
gRPC 核心概念
.proto文件:定义服务名、方法名、请求参数、响应参数。- service:服务定义,类似接口。
- message:请求和响应的数据结构。
- server:服务端,实现 proto 中定义的方法。
- client:客户端,像调用本地函数一样调用远程服务。
推荐先按下面的目录组织 gRPC 示例:
learn_go/
├── go.mod
├── proto/
│ ├── user.proto # 手写的接口定义文件
│ ├── user.pb.go # protoc 生成的数据结构代码
│ └── user_grpc.pb.go # protoc 生成的 gRPC 服务代码
├── cmd/
│ ├── server/
│ │ └── main.go # gRPC 服务端入口
│ └── client/
│ └── main.go # gRPC 客户端入口
安装工具:
go install google.golang.org/protobuf/cmd/protoc-gen-go@latest
go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest
go get google.golang.org/grpc
go get google.golang.org/protobuf
proto 文件示例
新建 proto/user.proto:
syntax = "proto3";
package user;
option go_package = "./proto;proto";
// UserService 表示用户服务。
// 里面定义的方法就是客户端可以远程调用的方法。
service UserService {
// GetUser 表示根据用户 ID 查询用户信息。
rpc GetUser(GetUserRequest) returns (GetUserResponse);
}
// 请求参数:客户端传一个用户 ID。
message GetUserRequest {
int64 id = 1;
}
// 响应结果:服务端返回用户 ID、姓名、年龄。
message GetUserResponse {
int64 id = 1;
string name = 2;
int32 age = 3;
}
生成 Go 代码:
protoc --go_out=. --go-grpc_out=. proto/user.proto
生成后重点看两个文件:
user.pb.go:包含GetUserRequest、GetUserResponse这些结构体。user_grpc.pb.go:包含服务端接口、注册函数、客户端调用代码。
gRPC 服务端示例
服务端要做三件事:
- 监听端口。
- 实现 proto 中定义的
GetUser方法。 - 把实现注册到 gRPC Server 中。
package main
import (
"context"
"fmt"
"net"
pb "learn_go/proto"
"google.golang.org/grpc"
)
type userServer struct {
// 嵌入 UnimplementedUserServiceServer 是官方推荐写法。
// 这样以后 proto 新增方法时,旧代码也更容易兼容。
pb.UnimplementedUserServiceServer
}
// GetUser 是真正的业务方法。
// 客户端调用 GetUser 时,最终会执行到这里。
func (s *userServer) GetUser(ctx context.Context, req *pb.GetUserRequest) (*pb.GetUserResponse, error) {
// 这里为了演示直接返回固定数据。
// 实际项目中一般会根据 req.Id 查询数据库。
return &pb.GetUserResponse{
Id: req.Id,
Name: "张三",
Age: 18,
}, nil
}
func main() {
// 监听 9000 端口,等待客户端连接。
listener, err := net.Listen("tcp", ":9000")
if err != nil {
panic(err)
}
// 创建 gRPC 服务端。
server := grpc.NewServer()
// 把 userServer 注册到 gRPC 服务端。
// 注册后,客户端才能调用 UserService 里的方法。
pb.RegisterUserServiceServer(server, &userServer{})
fmt.Println("grpc server start at :9000")
if err := server.Serve(listener); err != nil {
panic(err)
}
}
运行服务端:
go run cmd/server/main.go
gRPC 客户端示例
客户端要做三件事:
- 连接 gRPC 服务端。
- 创建
UserServiceClient。 - 像调用本地函数一样调用
GetUser。
package main
import (
"context"
"fmt"
"time"
pb "learn_go/proto"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
func main() {
// 建立到 gRPC 服务端的连接。
// insecure.NewCredentials() 表示本地演示不启用 TLS。
conn, err := grpc.Dial("localhost:9000", grpc.WithTransportCredentials(insecure.NewCredentials()))
if err != nil {
panic(err)
}
defer conn.Close()
// 创建客户端对象,后面通过它调用远程方法。
client := pb.NewUserServiceClient(conn)
// 设置 1 秒超时,避免服务端无响应时一直卡住。
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
defer cancel()
// 调用远程 GetUser 方法。
resp, err := client.GetUser(ctx, &pb.GetUserRequest{Id: 1001})
if err != nil {
panic(err)
}
fmt.Println(resp.Id, resp.Name, resp.Age)
}
运行客户端:
go run cmd/client/main.go
预期输出:
1001 张三 18
Gin 调用 gRPC 的常见架构
实际项目里经常是:
- 用户通过 HTTP 请求访问 Gin 服务。
- Gin 作为 API 层,做参数校验、鉴权、返回 JSON。
- Gin 内部通过 gRPC 调用用户微服务。
- 用户微服务查询用户信息,并把结果返回给 Gin。
- Gin 再把结果转换成 JSON 返回给前端。
简单理解:
前端/客户端 -> Gin HTTP API -> gRPC Client -> gRPC Server -> 数据库/缓存
常见面试题:
问题:gRPC 和 HTTP REST API 有什么区别?
答:REST API 通常使用 JSON,易读、调试方便,适合对外接口;gRPC 使用 proto 和 HTTP/2,性能更好、类型约束更强,适合服务内部调用。
问题:为什么微服务之间常用 gRPC?
答:gRPC 有明确的接口定义,序列化效率高,支持流式通信和超时控制,适合服务之间高频、强类型的调用。
问题:proto 文件的作用是什么?
答:proto 文件用于定义服务接口和数据结构,是服务端和客户端共同遵守的契约。通过 proto 可以生成不同语言的客户端和服务端代码。
8、测试与调试
Go 内置了测试工具,不需要额外安装测试框架。测试文件通常以 _test.go 结尾,测试函数以 Test 开头。
先写一个业务函数 calc.go:
package main
func Add(a int, b int) int {
return a + b
}
再写测试文件 calc_test.go:
package main
import "testing"
func TestAdd(t *testing.T) {
got := Add(2, 3)
want := 5
if got != want {
t.Errorf("Add(2, 3) = %d, want %d", got, want)
}
}
运行测试:
go test
如果想看详细输出:
go test -v
说明:
got表示实际结果。want表示期望结果。- 如果结果不一致,就用
t.Errorf报错。
8.1 表格驱动测试
Go 项目中很常见的一种写法是表格驱动测试:把多组输入和期望结果放到切片里,然后循环测试。
package main
import "testing"
func TestAddTable(t *testing.T) {
cases := []struct {
name string
a int
b int
want int
}{
{name: "正数相加", a: 1, b: 2, want: 3},
{name: "包含负数", a: -1, b: 2, want: 1},
{name: "包含0", a: 0, b: 2, want: 2},
}
for _, tc := range cases {
t.Run(tc.name, func(t *testing.T) {
got := Add(tc.a, tc.b)
if got != tc.want {
t.Errorf("got %d, want %d", got, tc.want)
}
})
}
}
8.2 Benchmark 性能测试
性能测试函数以 Benchmark 开头,参数是 *testing.B。
package main
import "testing"
func BenchmarkAdd(b *testing.B) {
for i := 0; i < b.N; i++ {
Add(1, 2)
}
}
运行:
go test -bench=.
8.3 race 检测
如果代码里有并发读写,可以用 race 检测数据竞争:
go test -race ./...
go run -race main.go
常见面试题:
问题:Go 的测试文件有什么命名要求?
答:测试文件以 _test.go 结尾,测试函数以 Test 开头,性能测试函数以 Benchmark 开头。
问题:什么是表格驱动测试?
答:把多组测试数据放到一个切片中,用循环逐个执行测试。这样可以减少重复代码,也方便补充更多测试用例。

















&spm=1001.2101.3001.5002&articleId=147601280&d=1&t=3&u=8b19b8966e3448438584d159cdd56c3c)
 4836
4836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










