



 在使用tsfresh时遇到HTTPSConnectionPool错误,尝试多种网络解决方案无效。最终通过手动下载github上的数据集文件并放入指定目录解决问题。详细步骤包括访问github仓库下载代码,将lp1.data.txt复制到tsfresh的data目录并重命名,从而避免连接拒绝错误。
在使用tsfresh时遇到HTTPSConnectionPool错误,尝试多种网络解决方案无效。最终通过手动下载github上的数据集文件并放入指定目录解决问题。详细步骤包括访问github仓库下载代码,将lp1.data.txt复制到tsfresh的data目录并重命名,从而避免连接拒绝错误。
ps:搜集了一天的tsfresh资料,准备自己写一个jupyter文档,然后斗志昂扬的开始,从官网上copy下来代码——运行——嗯——报错——解决问题。emmmm……然后我就解决了一下午问题,网上说到的方法真是试尽了都不行,真是脑壳疼啊,然后看了两集电视剧突然有了新的解决问题的思路,然后在我的不放弃下,现在终于把报错解决了,有必要含泪记录下来,以便下次出现类似的问题。
问题描述
在tsfresh官网中,教程案例中需要下载文件,代码如下:
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, \
load_robot_execution_failures
download_robot_execution_failures()
timeseries, y = load_robot_execution_failures()
然后报错:
HTTPSConnectionPool(host=‘raw.githubusercontent.com’, port=443): Max retries exceeded with url: /MaxBenChrist/robot-failure-dataset/master/lp1.data.txt (Caused by NewConnectionError(’<urllib3.connection.HTTPSConnection object at 0x7f27e9ea9af0>: Failed to establish a new connection: [Errno 111] Connection refused’))
找了一堆方法,修改了自己的DNS为8.8.8.8,以为成功,结果报错:
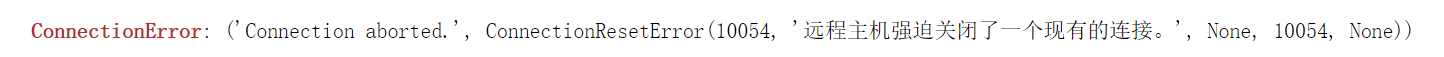
然后继续找各种方法,最终解决。
问题解决
简单来说,报错的原始是因为在获取https://raw.githubusercontent.com/MaxBenChrist/robot-failure-dataset/master/lp1.data.txt数据集时访问被拒导致不能下载成功,所以要想办法自己下载下来。
具体方法
- 打开https://github.com/MaxBenChrist/robot-failure-dataset.git ,手动download code
- 将其中的lp1.data.txt手动复制到~/anaconda3/lib/site-packages/tsfresh/examples/data/robotfailure-mld 下并重命名为lp1.data。
然后,代码就不会报错了,数据可以加载了!!!
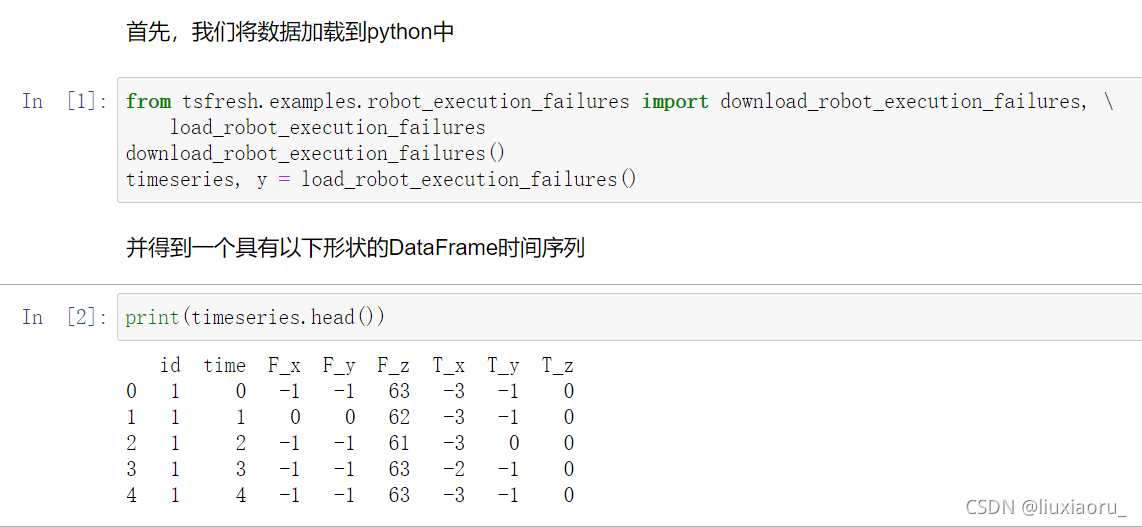
最后,在这里感谢这两个博主的帮助!



















 6859
6859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












