



一、TL;DR
- 从多角度总结InternVL1-InternVL3的模型结构升级和训练演进过程
- 详细对比了InternVL1-InternVL3的训练手法和使用到的token数
- 提到了一些实践过程中的训练细节和使用细节
性能天梯图:
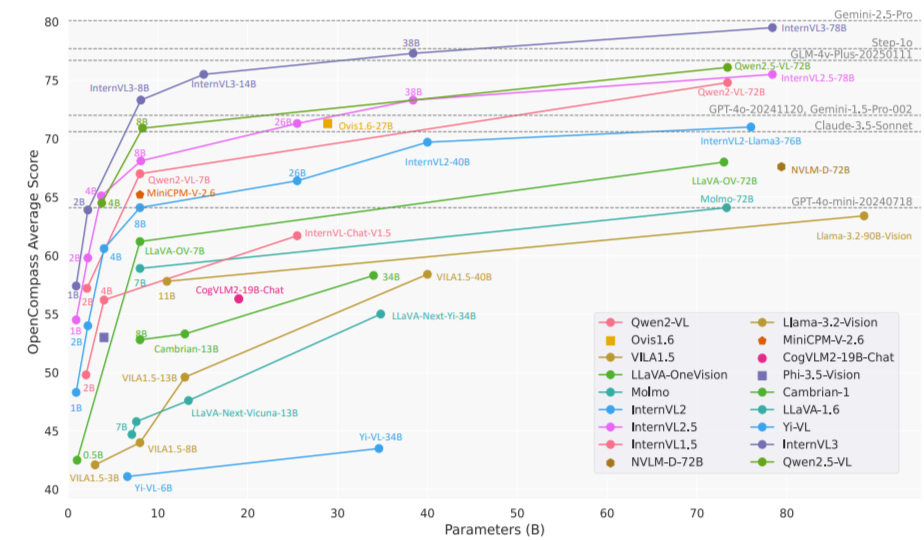
二、模型结构
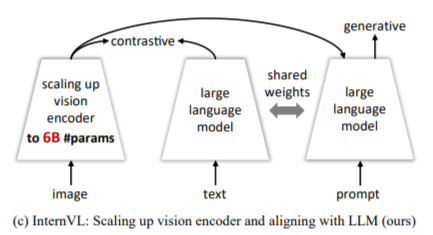
2.1 InternVL
关键点:
- 首次将VLM的视觉backbone参数量推至6B级别,参数量大小和LLM进行匹配
- 提出了使用QLLaMa作为中间件来粘合视觉和LLM,参数量达到8B,并使用LLaMA进行初始化 <注意:后续没有这个模块了,使用MLP连接>
- 使用了Vicuna-13B等LLM作为VLM的语言模块
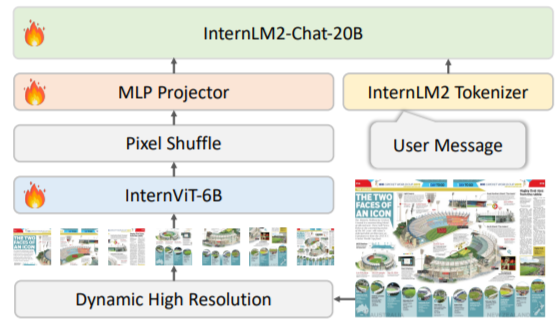
2.2 InternVL1.5
关键点:
- 正式提出InternVL系列最重要的encoder-decoder的固化结构(动态分辨率+InternVit6B视觉backbone+pixel-shuffle++MLP中间件+LLM)(后续一直沿用,3.5有没有用没来得及看)
- 注意:QLLaMa的中间件结构被淘汰了
- 这个版本的LLM和Tokenizer都换成了自己训练的,但根据paper的蛛丝马迹,大概率还是基于BBPE进行改进的
- InternVL1.5的参数量最大只有25B左右
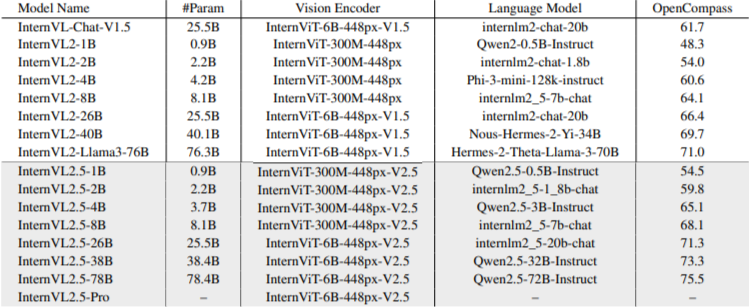
2.3 InternVL2和InternVL2.5
关键点:
- InternVL2是没有paper的,但推测和1.5/2.5是保持一致的
- 网络结构保持不变,但是引入了视频和多图像的输入,且对应不同的预处理
- 注意:一旦涉及到视频和高分辨率输入,尤其要注意token压缩或者max_seq_length的设置和处理
- 此时的LLM模块适配了多个主流的大模型,包括qwen2.5、internlm等
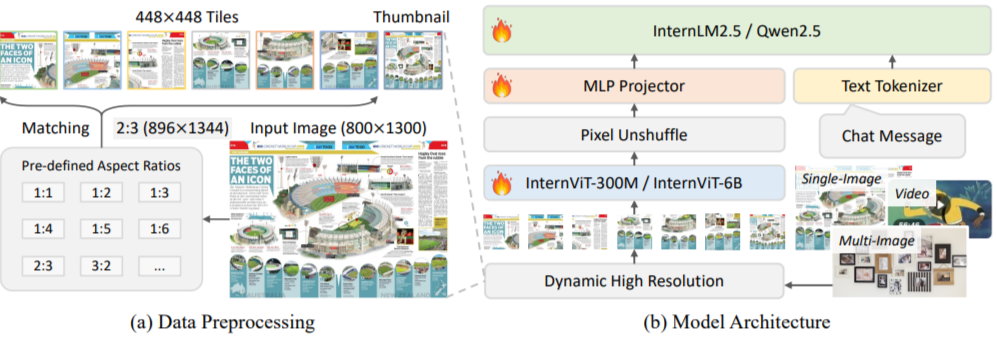
2.4 InternVL3
关键点:
- 网络结构保持不变,没有任何修改
- 整合了可变视觉位置编码(V2PE),它为视觉token使用更小、更灵活的位置增量,能处理更长的多模态上下文。
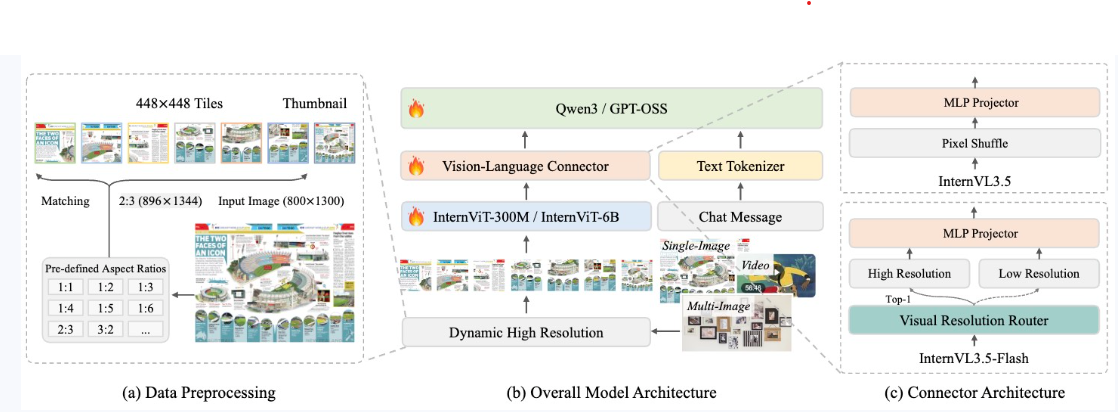
2.5 InternVL3.5
关键点:
- 增加了一个IntenVL-3.5-Flash模块,目的是通过token压缩来使得token得以被更高效的利用
- 这个细节由于我没有阅读3.5,感兴趣的自己去看
三、模型对齐和训练
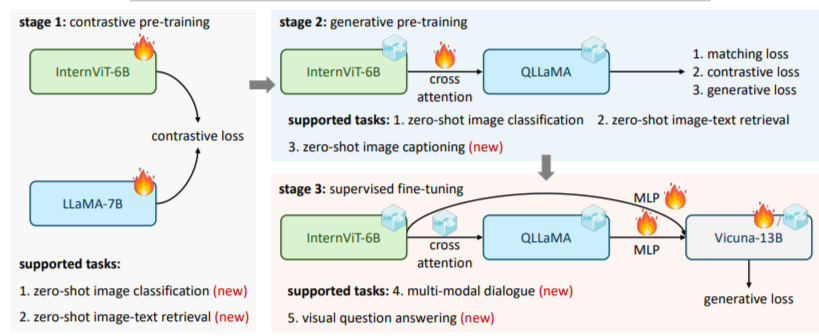
3.1 InternVL
关键点:
- Internvl采用的是渐进式对齐,即先和LLama做对比学习完成对齐
- 再和QLLaMA做生成式学习,注意,此时就能够做caption生成了
- 最后,再使用整个VLM训练做全量的VQA式的生成学习
损失函数:
- 图像-文本对比(ITC)损失、图像-文本匹配(ITM)损失和基于图像的文本生成(ITG)损失。
- NTP的损失
3.2 InternVL1.5
关键点:
- 基于internvl1.2利用动态分辨率做持续预训练,并且丢掉了最后3层(倒数第四层的特征在多模态任务效果最好)
- 注意:持续预训练是直接做NTP的,不是对比学习,意味着1.5也是没有检索能力的!
3.3 InternVL2.5
关键点:
- paper通过蒸馏得到了internvit300M的backbone,还是提到了先做预训练对齐,但此次不是重点
- 重点是后续的直接基于整个VLM模块做持续预训练,是利用NTP进行预测
- 注意:预训练的NTP和post training的NTP的含义是不一样的,预训练的NTP代表得到最大似然的参数,SFT的训练代表最有可能发生预测下一个token(这个地方没说太明白,感兴趣的同学自己去GPT就好了)
- 引入随机 JPEG 压缩、平方损失重加权和多模态数据打包技术。
注意哈,2.5里面对比学习不是重点哈,有可能在蒸馏阶段使用过,但是正代的2.5是直接做NTP loss的,也就意味着2.5的backbone是没有检索能力的!!!
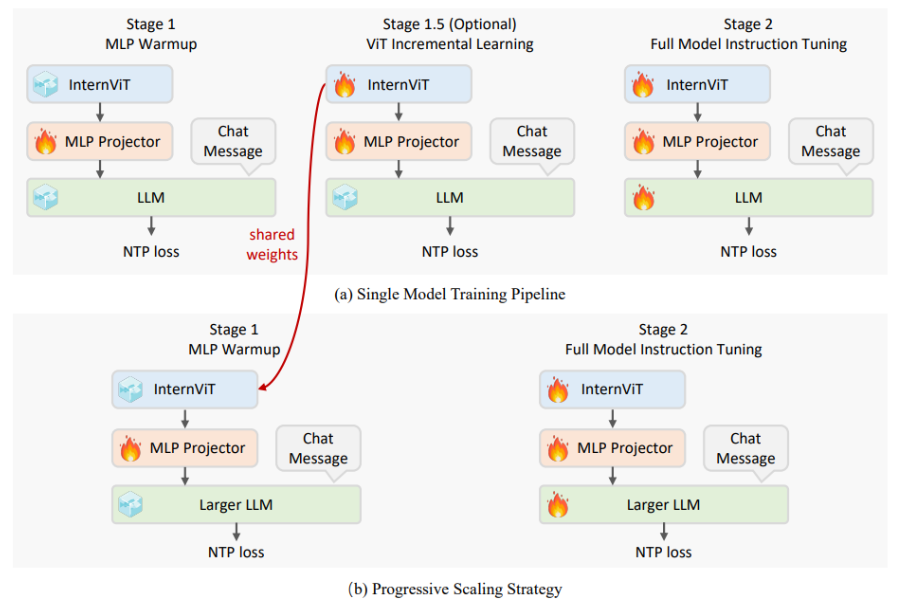
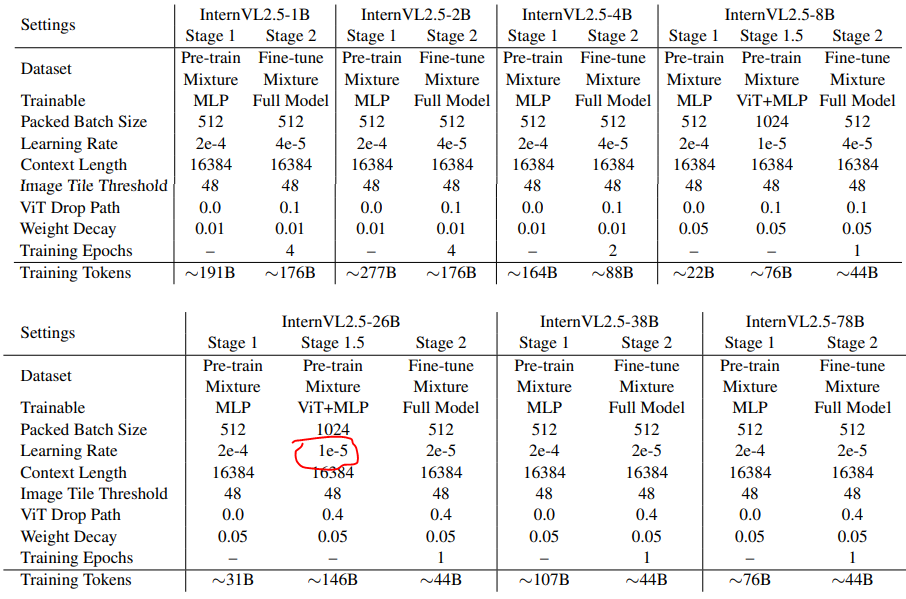
不同的size的模型的训练超参数:
3.4 InternVL3
关键点:
- 预训练过程中交错使用多模态数据(例如图像-文本、视频-文本或交错的图像-文本序列)与大规模文本语料库进行集成优化,使预训练模型能够同时学习语言和多模态能力,最终增强其处理视觉-语言任务的能力,而无需引入额外的桥接模块或后续的跨模型对齐程序。
- 在多模态预训练期间联合更新所有模型参数
- 完成原生多模态预训练后,采用两阶段后训练策略:SFT+MPO
- 相较InternVL2.5,InternVL3 在 SFT 阶段的主要改进在于使用了更高质量和更多样化的训练数据。
- 引入MPO,通过引入正负样本的额外监督,使模型的响应分布与真值分布对齐,从而提升推理性能。
四、模型的数据使用
4.1 InternVL
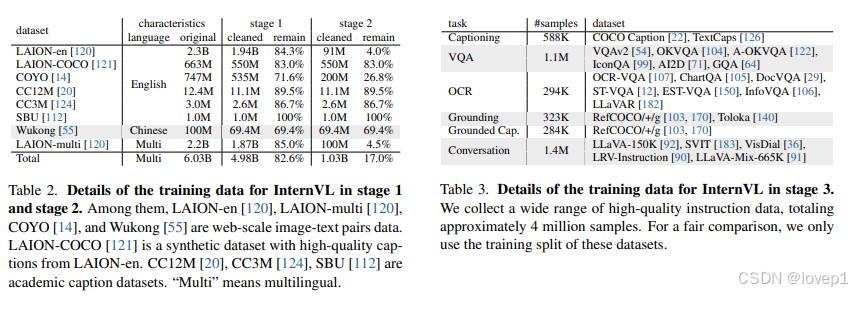
- starge1:60.3亿图像-文本对,清理后剩下49.8亿
- stage2:49.8亿减少到10.3亿
- stage3:400万高质量指令数
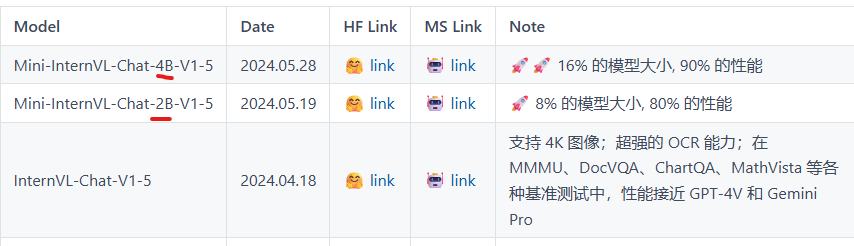
4.2 InternVL1.5
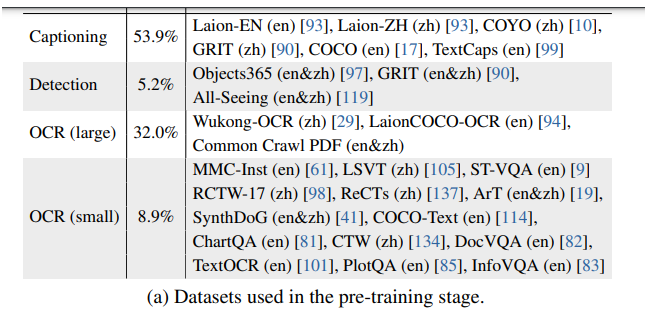
跟1.0比起来,尤其是finetune-stage里面,增加了大量的文档、science等数据集
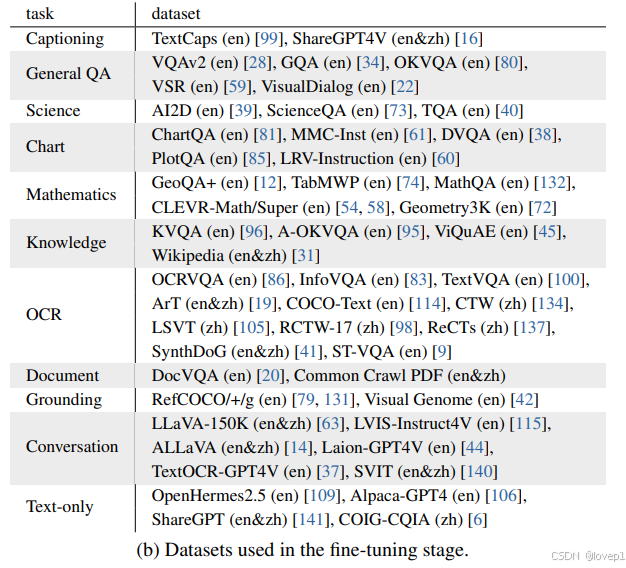
4.3 InternVL2.5
4.3.1 微调数据集
- 规模上:InternVL 1.5约510万数据,InternVL 2.0的730万,InternVL 2.5的1630万
- 多样性上:覆盖了多个领域,包括通用问答、图表、文档、OCR、科学、医学、GUI、代码、数学等,同时涵盖了单图像45.92%、多图像9.37%、视频39.79%和文本4.92%等多种模态
- 质量上:通过统一对话模板、使用语言模型对数据进行评分和精炼、去除重复模式、应用启发式规则过滤低质量样本,以及将简短回答改写为高质量且更长的互动。
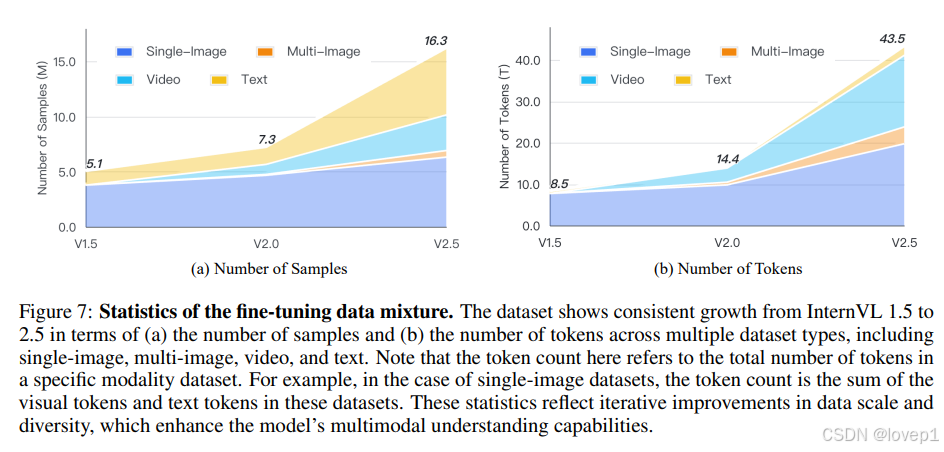
4.3.2 预训练数据

4.4 InternVL3
关键点:
- 语言数据与多模态数据的比例为 1:3 时,能够在单模态和多模态基准测试中取得最佳的整体表现
- 预训练总训练token数约为 2000 亿,其中 500 亿来自语言数据,1500 亿来自多模态数据。
SFT手法:
- 沿用了 InternVL2.5 中提出的随机 JPEG 压缩、平方损失重加权和多模态数据打包技术。
- 与 InternVL2.5 相比,InternVL3 在 SFT 阶段的主要改进在于使用了更高质量和更多样化的训练数据。具体来说,扩展了工具使用、3D 场景理解、图形用户界面(GUI)操作、长文本任务、视频理解、科学图表、创意写作和多模态推理的训练样本。
- 没有详细提及后训练的token数
五、参考博客
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models论文理解-CSDN博客
InternVL2.5:Expanding Performance Boundaries of Open-SourceMultimodal Models 论文理解-CSDN博客
InternVL1.5:How Far Are We to GPT-4V?Closing the Gap to Commercial Multimodal Models _gpt-4v vqa v2-CSDN博客



















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










