




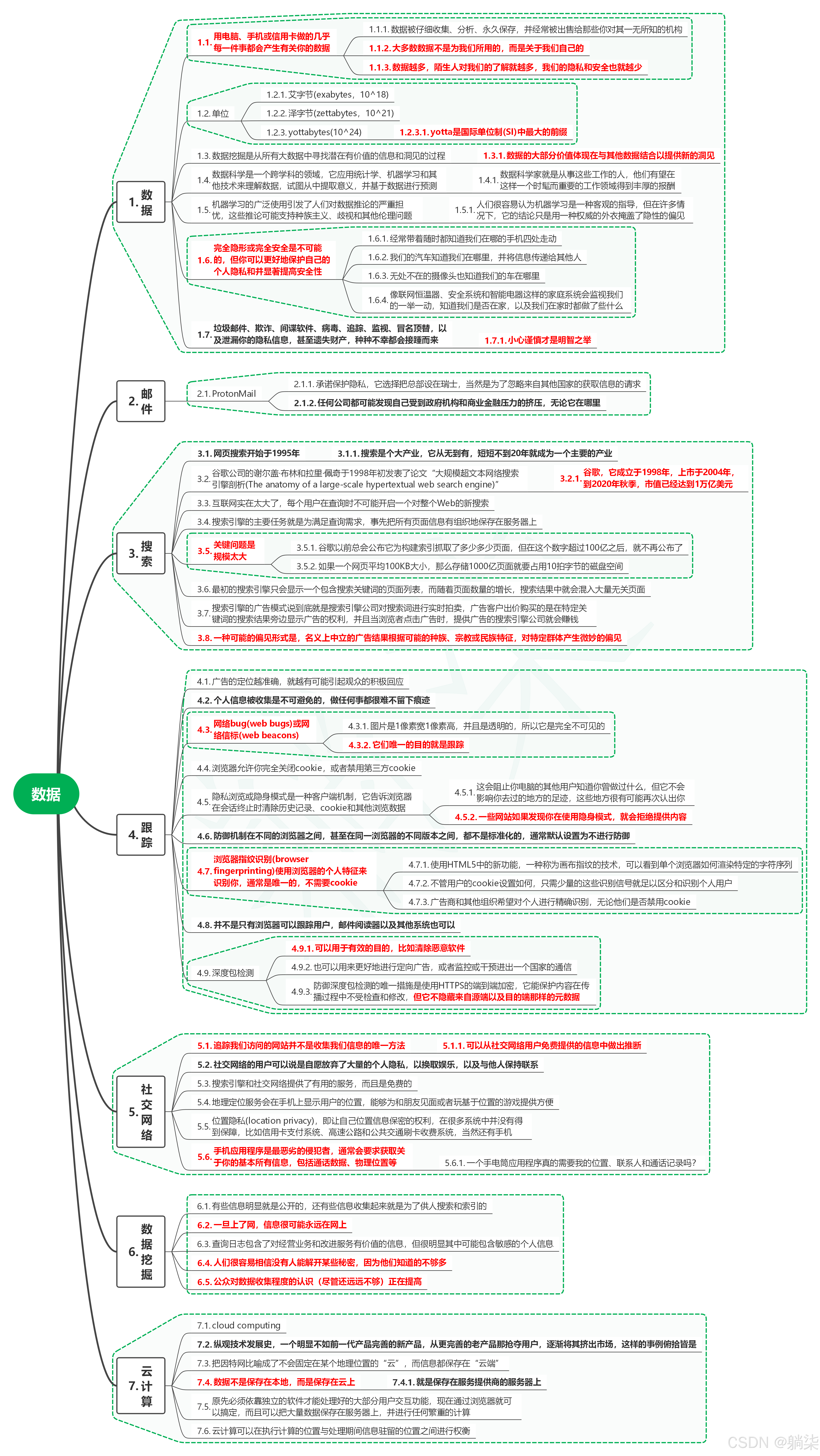
1. 数据
1.1. 用电脑、手机或信用卡做的几乎每一件事都会产生有关你的数据
-
1.1.1. 数据被仔细收集、分析、永久保存,并经常被出售给那些你对其一无所知的机构
-
1.1.2. 大多数数据不是为我们所用的,而是关于我们自己的
-
1.1.3. 数据越多,陌生人对我们的了解就越多,我们的隐私和安全也就越少
1.2. 单位
-
1.2.1. 艾字节(exabytes,10^18)
-
1.2.2. 泽字节(zettabytes,10^21)
-
1.2.3. yottabytes(10^24)
- 1.2.3.1. yotta是国际单位制(SI)中最大的前缀
1.3. 数据挖掘是从所有大数据中寻找潜在有价值的信息和洞见的过程
- 1.3.1. 数据的大部分价值体现在与其他数据结合以提供新的洞见
1.4. 数据科学是一个跨学科的领域,它应用统计学、机器学习和其他技术来理解数据,试图从中提取意义,并基于数据进行预测
- 1.4.1. 数据科学家就是从事这些工作的人,他们有望在这样一个时髦而重要的工作领域得到丰厚的报酬
1.5. 机器学习的广泛使用引发了人们对数据推论的严重担忧,这些推论可能支持种族主义、歧视和其他伦理问题
- 1.5.1. 人们很容易认为机器学习是一种客观的指导,但在许多情况下,它的结论只是用一种权威的外衣掩盖了隐性的偏见
1.6. 完全隐形或完全安全是不可能的,但你可以更好地保护自己的个人隐私和并显著提高安全性
-
1.6.1. 经常带着随时都知道我们在哪的手机四处走动
-
1.6.2. 我们的汽车知道我们在哪里,并将信息传递给其他人
-
1.6.3. 无处不在的摄像头也知道我们的车在哪里
-
1.6.4. 像联网恒温器、安全系统和智能电器这样的家庭系统会监视我们的一举一动,知道我们是否在家,以及我们在家时都做了些什么
1.7. 垃圾邮件、欺诈、间谍软件、病毒、追踪、监视、冒名顶替,以及泄漏你的隐私信息,甚至遗失财产,种种不幸都会接踵而来
- 1.7.1. 小心谨慎才是明智之举
2. 邮件
2.1. ProtonMail
-
2.1.1. 承诺保护隐私,它选择把总部设在瑞士,当然是为了忽略来自其他国家的获取信息的请求
-
2.1.2. 任何公司都可能发现自己受到政府机构和商业金融压力的挤压,无论它在哪里
3. 搜索
3.1. 网页搜索开始于1995年
- 3.1.1. 搜索是个大产业,它从无到有,短短不到20年就成为一个主要的产业
3.2. 谷歌公司的谢尔盖·布林和拉里·佩奇于1998年初发表了论文“大规模超文本网络搜索引擎剖析(The anatomy of a large-scale hypertextual web search engine)”
- 3.2.1. 谷歌,它成立于1998年,上市于2004年,到2020年秋季,市值已经达到1万亿美元
3.3. 互联网实在太大了,每个用户在查询时不可能开启一个对整个Web的新搜索
3.4. 搜索引擎的主要任务就是为满足查询需求,事先把所有页面信息有组织地保存在服务器上
3.5. 关键问题是规模太大
-
3.5.1. 谷歌以前总会公布它为构建索引抓取了多少多少页面,但在这个数字超过100亿之后,就不再公布了
-
3.5.2. 如果一个网页平均100KB大小,那么存储1000亿页面就要占用10拍字节的磁盘空间
3.6. 最初的搜索引擎只会显示一个包含搜索关键词的页面列表,而随着页面数量的增长,搜索结果中就会混入大量无关页面
3.7. 搜索引擎的广告模式说到底就是搜索引擎公司对搜索词进行实时拍卖,广告客户出价购买的是在特定关键词的搜索结果旁边显示广告的权利,并且当浏览者点击广告时,提供广告的搜索引擎公司就会赚钱
3.8. 一种可能的偏见形式是,名义上中立的广告结果根据可能的种族、宗教或民族特征,对特定群体产生微妙的偏见
4. 跟踪
4.1. 广告的定位越准确,就越有可能引起观众的积极回应
4.2. 个人信息被收集是不可避免的,做任何事都很难不留下痕迹
4.3. 网络bug(web bugs)或网络信标(web beacons)
-
4.3.1. 图片是1像素宽1像素高,并且是透明的,所以它是完全不可见的
-
4.3.2. 它们唯一的目的就是跟踪
4.4. 浏览器允许你完全关闭cookie,或者禁用第三方cookie
4.5. 隐私浏览或隐身模式是一种客户端机制,它告诉浏览器在会话终止时清除历史记录、cookie和其他浏览数据
-
4.5.1. 这会阻止你电脑的其他用户知道你曾做过什么,但它不会影响你去过的地方的足迹,这些地方很有可能再次认出你
-
4.5.2. 一些网站如果发现你在使用隐身模式,就会拒绝提供内容
4.6. 防御机制在不同的浏览器之间,甚至在同一浏览器的不同版本之间,都不是标准化的,通常默认设置为不进行防御
4.7. 浏览器指纹识别(browser fingerprinting)使用浏览器的个人特征来识别你,通常是唯一的,不需要cookie
-
4.7.1. 使用HTML5中的新功能,一种称为画布指纹的技术,可以看到单个浏览器如何渲染特定的字符序列
-
4.7.2. 不管用户的cookie设置如何,只需少量的这些识别信号就足以区分和识别个人用户
-
4.7.3. 广告商和其他组织希望对个人进行精确识别,无论他们是否禁用cookie
4.8. 并不是只有浏览器可以跟踪用户,邮件阅读器以及其他系统也可以
4.9. 深度包检测
-
4.9.1. 可以用于有效的目的,比如清除恶意软件
-
4.9.2. 也可以用来更好地进行定向广告,或者监控或干预进出一个国家的通信
-
4.9.3. 防御深度包检测的唯一措施是使用HTTPS的端到端加密,它能保护内容在传播过程中不受检查和修改,但它不隐藏来自源端以及目的端那样的元数据
5. 社交网络
5.1. 追踪我们访问的网站并不是收集我们信息的唯一方法
- 5.1.1. 可以从社交网络用户免费提供的信息中做出推断
5.2. 社交网络的用户可以说是自愿放弃了大量的个人隐私,以换取娱乐,以及与他人保持联系
5.3. 搜索引擎和社交网络提供了有用的服务,而且是免费的
5.4. 地理定位服务会在手机上显示用户的位置,能够为和朋友见面或者玩基于位置的游戏提供方便
5.5. 位置隐私(location privacy),即让自己位置信息保密的权利,在很多系统中并没有得到保障,比如信用卡支付系统、高速公路和公共交通刷卡收费系统,当然还有手机
5.6. 手机应用程序是最恶劣的侵犯者,通常会要求获取关于你的基本所有信息,包括通话数据、物理位置等
- 5.6.1. 一个手电筒应用程序真的需要我的位置、联系人和通话记录吗?
6. 数据挖掘
6.1. 有些信息明显就是公开的,还有些信息收集起来就是为了供人搜索和索引的
6.2. 一旦上了网,信息很可能永远在网上
6.3. 查询日志包含了对经营业务和改进服务有价值的信息,但很明显其中可能包含敏感的个人信息
6.4. 人们很容易相信没有人能解开某些秘密,因为他们知道的不够多
6.5. 公众对数据收集程度的认识(尽管还远远不够)正在提高
7. 云计算
7.1. cloud computing
7.2. 纵观技术发展史,一个明显不如前一代产品完善的新产品,从更完善的老产品那抢夺用户,逐渐将其挤出市场,这样的事例俯拾皆是
7.3. 把因特网比喻成了不会固定在某个地理位置的“云”,而信息都保存在“云端”
7.4. 数据不是保存在本地,而是保存在云上
- 7.4.1. 就是保存在服务提供商的服务器上
7.5. 原先必须依靠独立的软件才能处理好的大部分用户交互功能,现在通过浏览器就可以搞定,而且可以把大量数据保存在服务器上,并进行任何繁重的计算
7.6. 云计算可以在执行计算的位置与处理期间信息驻留的位置之间进行权衡


















 4563
4563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










