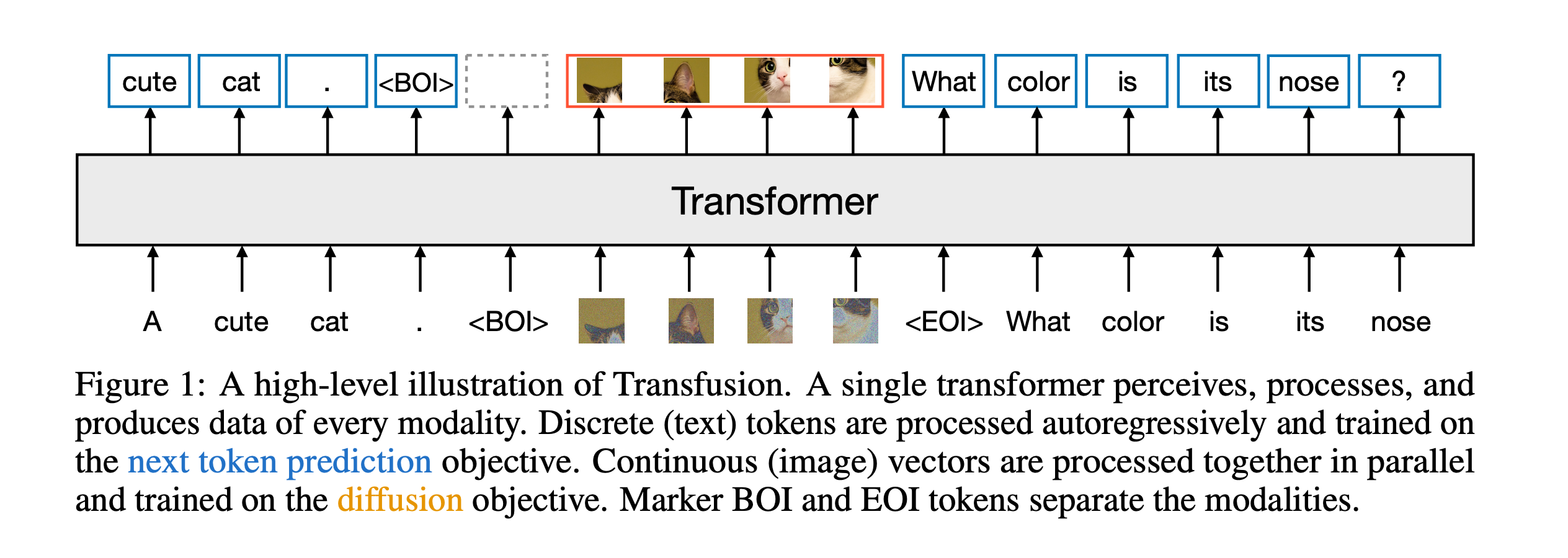
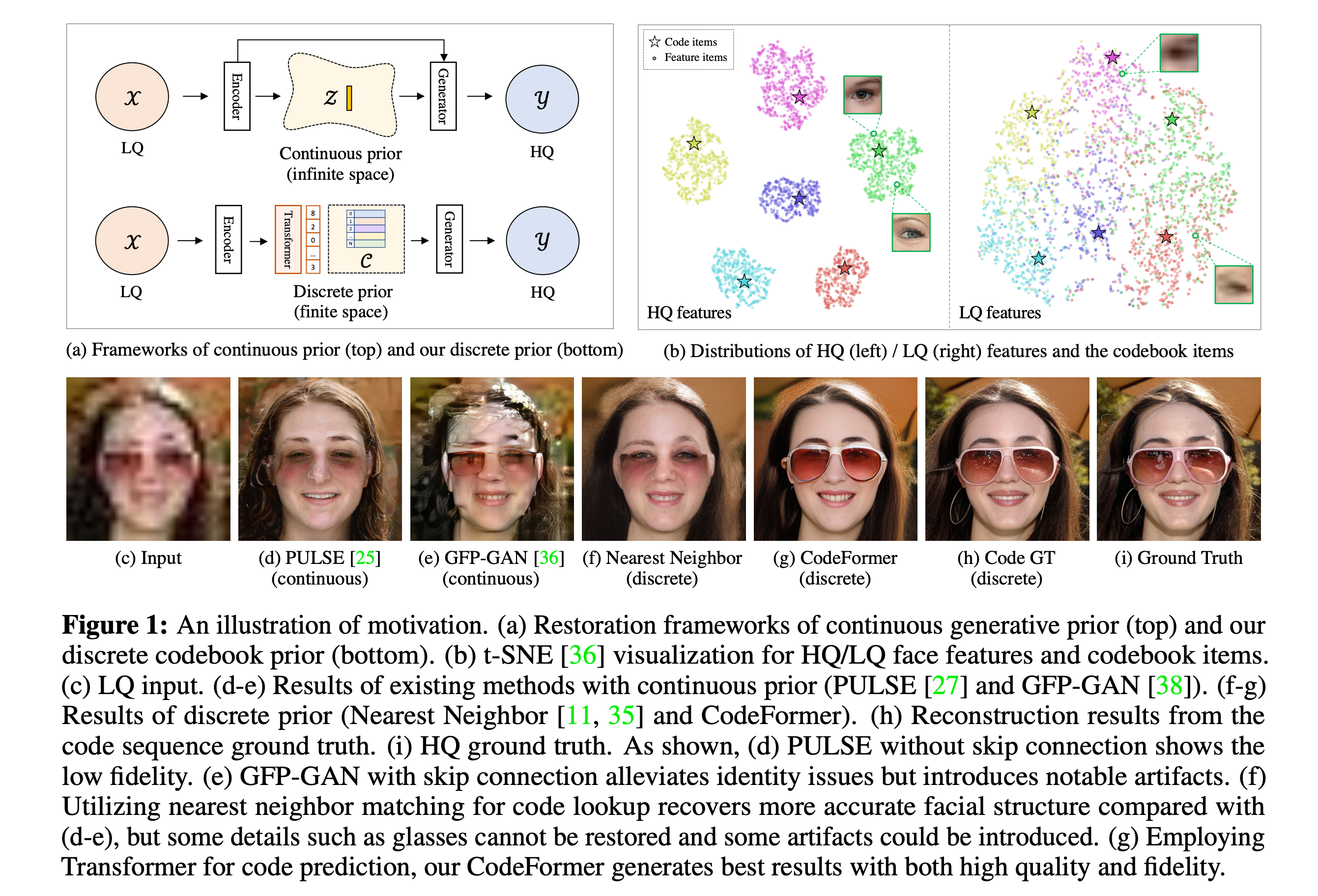
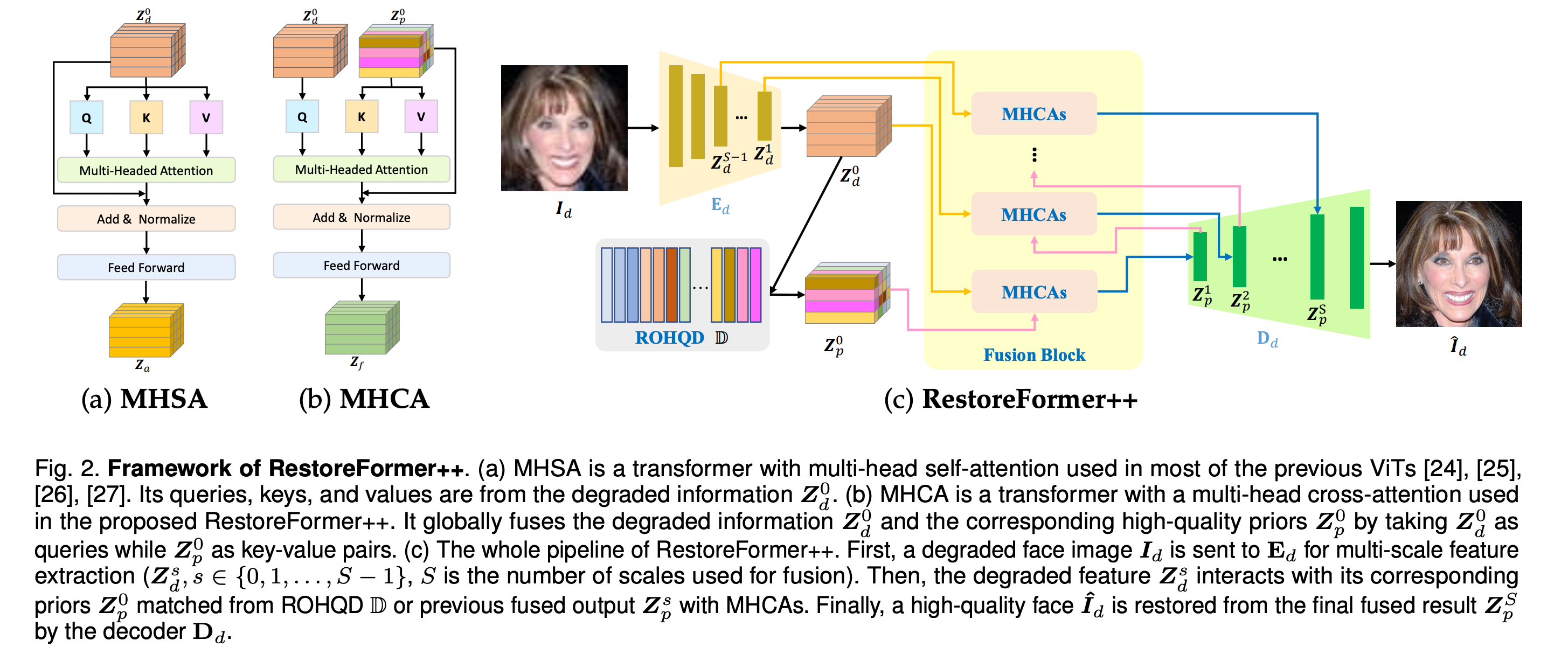
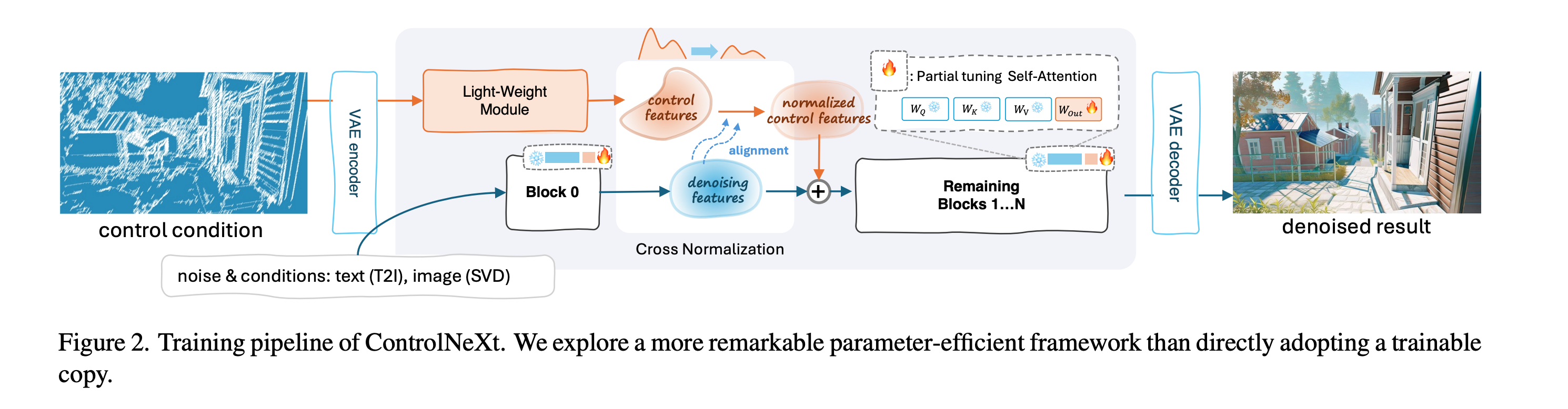
【无标题】
摘要 最新开源大模型训练技术报告显示,Kimi-K2.5、GLM-5、DeepSeek-V3和MiniMax-M1在模型架构和训练方法上均有突破。Kimi-K2.5采用万亿参数MoE架构,创新性地使用MuonClip优化器和PARL并行强化学习框架;GLM-5通过Slime异步RL基础设施显著提升训练效率;DeepSeek-V3的DualPipe流水线并行算法实现了通信开销的完全隐藏;MiniMax-M1则开发了CISPO强化学习算法优化长序列生成。这些技术共同推动了大规模语言模型在训练稳定性、计算效率和推