



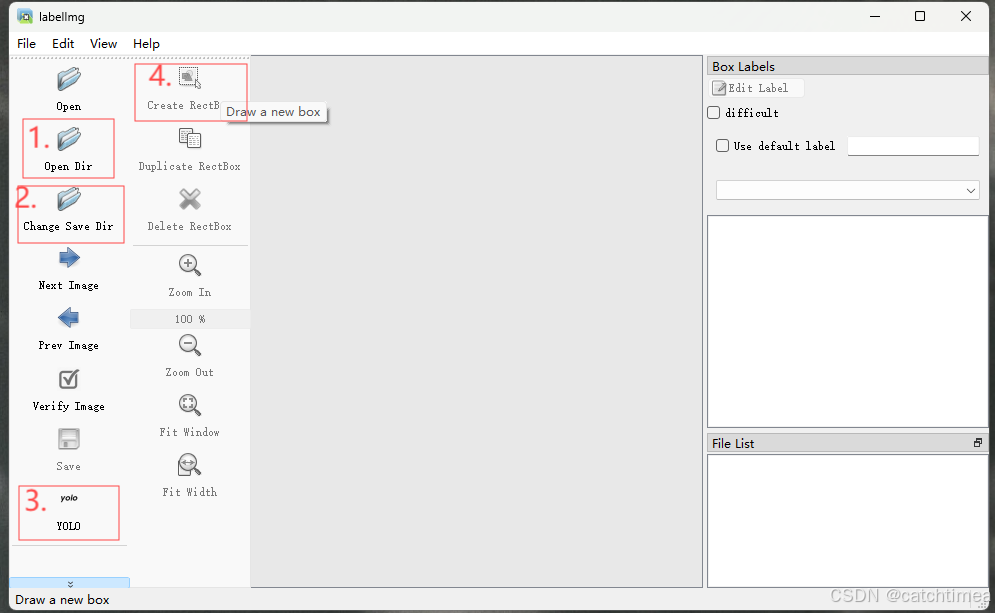
首先需要安装 labelimg,用于给图片数据打标注,其页面如下图所示。第一步点击 Open Dir,选择你所要进行标注的图片数据集;第二部点击 Change Save Dir,选择图片标签(labels)的保存路径;第三步选择数据格式为 YOLO;第四步点击 RectBox,在图片中框出实体进行标注。
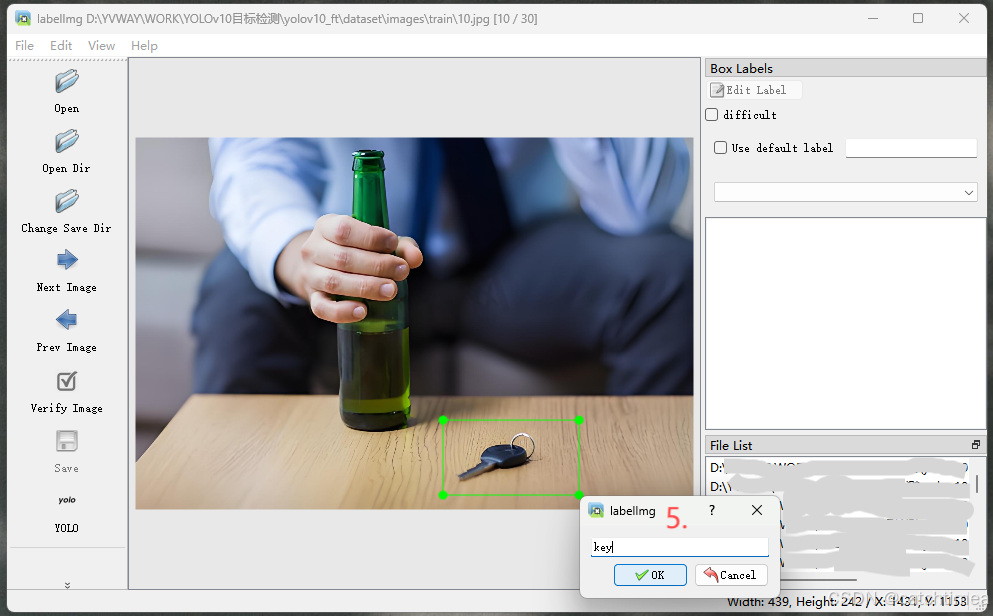
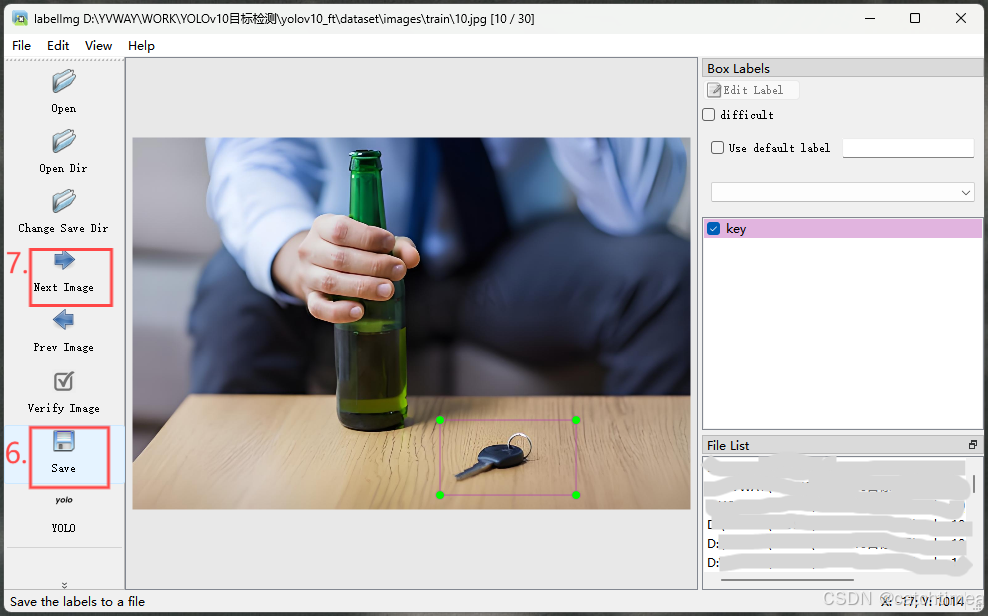
第六步点击 Save,进行保存;第七步点击 Next Image,进行下一张图片的标注。
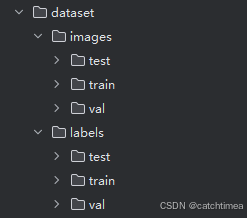
YOLOv10的训练集格式如下图所示。images中放图片数据,labels中放对应图片打好的标注(labels)。例如我的数据集大小为30张图片,总共三个类别。即 images/train 中有30张图片,val 有6张(从train中抽取),test有9张(也是从train中抽取)。图片的名称为1.jpg,2.jpg,...,30.jpg。
labels/train 中的标签文件如下如所示。
YOLOv10训练需要准备一个数据集的配置文件 data.yaml,配置文件中的内容如下图所示。

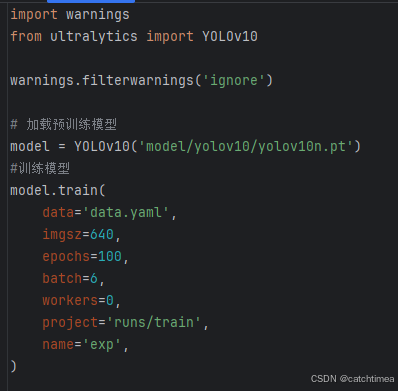
训练代码如下图所示。
使用训练后的模型进行推理。



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










