





嵌入式岗转测试工程师:Python+Selenium 入门指南(全代码 + 避坑)(持续更新)
- 前言
- 一、为什么需要 Selenium?(测试痛点直击)
- 二、环境搭建(VSCode 版,避坑指南)
- 三、基础语法
- 四、进阶场景实战(测试高频场景)
- 五、关键避坑指南(测试必看)
- 六、写在最后
前言
作为嵌入式专业毕业生,我转型测试岗位后,发现手动测试公司网站时,大量重复操作(如登录验证、表单提交)效率极低😫。为解决这一痛点,我系统学习了 Python+Selenium 自动化测试,整理出这份贴合转岗工程师的入门指南。
本文基于Windows 11、Python 3.14.2、VSCode、Selenium 4.39.0环境编写
一、为什么需要 Selenium?(测试痛点直击)
1. 你是否面临这些手工测试难题?
每天重复测试「用户登录」(多组账号密码组合),机械且易出错🤖;
多次回归「表单提交」(注册、下单、留言等固定字段场景),耗时耗力⌛;
验证「页面跳转」(导航栏、功能按钮点击),重复操作无技术价值🙅;
批量校验「数据显示」(商品列表、用户信息),人工对比效率低📊。
2. Selenium 的核心价值
一次编写脚本,无限次自动执行,覆盖更多测试场景✅,减少人为错误❌,快速反馈测试结果📨,且脚本可复用性强,大幅提升测试效率与准确性。
二、环境搭建(VSCode 版,避坑指南)
1. 安装 Python 与 VSCode
- Python 下载:Python 官网,选择 3.8-3.14 版本(兼容 Selenium 4.x),安装时务必勾选「Add Python to PATH」(自动配置环境变量)🟢。
- VSCode 下载:VSCode 官网,默认安装后,在扩展商店搜索「Python」,安装微软官方插件(支持代码高亮、运行调试)💻。
2. 安装 Selenium
打开 VSCode 终端(Ctrl + ` [esc下面的那个按键]),输入以下命令安装指定稳定版本:
# 安装Selenium 4.39.0(适配Python 3.8+)
pip install selenium==4.39.0
# 验证安装(终端输入,显示版本即成功)
pip show selenium
3. 配置浏览器驱动(关键步骤)
驱动是 Python 控制浏览器的桥梁🌉,需与浏览器版本匹配,推荐两种配置方式:
方式一:直接指定驱动路径(新手推荐)
- 下载对应浏览器驱动:
Chrome 驱动:ChromeDriver 官网
Edge 驱动:EdgeDriver 官网
Firefox 驱动:GeckoDriver 官网 - 解压驱动文件(如
chromedriver.exe),放置在固定文件夹(如D:\drivers)📂。 - 验证驱动有效性:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 指定驱动路径
driver_path = r"D:\drivers\chromedriver.exe"
service = Service(executable_path=driver_path)
# 启动Chrome浏览器(无报错即成功)
driver = webdriver.Chrome(service=service)
driver.quit()
方式二:配置环境变量(免写路径)
- 复制驱动所在文件夹路径(如
D:\drivers); - 电脑→属性→高级系统设置→环境变量→系统变量→Path→编辑→新建,粘贴路径🔗;
- 验证有效性
from selenium import webdriver
import time
# 无需指定驱动路径,直接启动
driver = webdriver.Chrome()
# 打开测试网页,2秒后关闭
driver.get("https://www.csdn.net")
time.sleep(2)
driver.close()
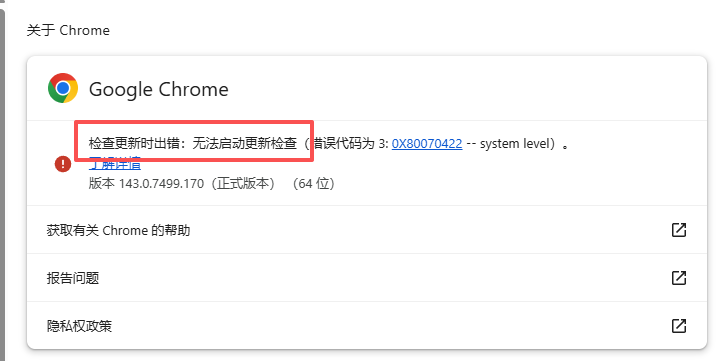
4. 特别设置:关闭 Chrome 自动更新
免浏览器更新后与驱动版本不匹配⚠️,步骤如下:
- 按下 Win+R,输入
services.msc回车,打开服务列表; - 找到
「Google 更新服务(gupdate)」和「Google 更新服务(gupdatem)」; - 分别双击,将「启动类型」改为「禁用」,点击「应用」→「确定」🚫;
- 验证:Chrome 地址栏输入
chrome://settings/help,显示「更新已由您的系统管理员管理」即成功✅。
三、基础语法
1. 环境初始化(所有脚本通用模板)
# 导入Selenium核心库
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
def init_driver():
"""
初始化Chrome浏览器,返回驱动对象
配置说明:保留窗口不关闭、禁用沙箱、隐式等待、窗口最大化
"""
# 1. 配置浏览器选项
chrome_options = Options()
# 调试必备:执行后不自动关闭浏览器
chrome_options.add_experimental_option("detach", True)
# 解决Windows/Linux权限问题
chrome_options.add_argument("--no-sandbox")
# 可选:无界面运行(后台执行,服务器部署用)
# chrome_options.add_argument("--headless=new")
# 2. 配置驱动路径(方式一:指定路径;方式二:已配环境变量可省略)
driver_service = Service("D:/drivers/chromedriver.exe")
# 3. 启动浏览器并配置全局设置
driver = webdriver.Chrome(service=driver_service, options=chrome_options)
driver.implicitly_wait(5) # 全局隐式等待5秒(元素未加载时自动等待)
driver.maximize_window() # 窗口最大化(避免元素遮挡)
return driver
# 初始化驱动(所有脚本的第一步)
driver = init_driver()
2. 基础页面操作
# 1. 打开目标网站(替换为你的测试网址)
driver.get("https://www.baidu.com")
# 2. 页面导航操作
print("=== 页面导航演示 ===")
time.sleep(1)
driver.back() # 后退🔙
time.sleep(1)
driver.forward() # 前进🔜
time.sleep(1)
driver.refresh() # 刷新🔄
# 3. 获取页面关键信息(验证操作结果)
print("=== 页面信息获取 ===")
print(f"当前页面标题:{driver.title}")
print(f"当前页面URL:{driver.current_url}")
print(f"当前窗口句柄:{driver.current_window_handle}")
# 4. 多标签页操作
print("=== 多标签页演示 ===")
# 新建标签页并打开淘宝
driver.execute_script("window.open('https://www.taobao.com')")
time.sleep(2)
# 获取所有窗口句柄(返回列表)
all_handles = driver.window_handles
print(f"当前打开的标签页数量:{len(all_handles)}")
# 切换到第二个标签页(索引从0开始)
driver.switch_to.window(all_handles[1])
print(f"切换后页面标题:{driver.title}")
# 5. 关闭操作(按需选择)
# driver.close() # 关闭当前标签页
# driver.quit() # 关闭所有标签页(退出浏览器)
3. 八种元素定位方法(优先级 + 实战)
素定位是 Selenium 核心🎯,按「优先级 + 实用性」排序,以百度页面为示例:
| 定位方式 | 核心语法 | 适用场景 |
|---|---|---|
| 1. ID定位(优先级最高) | find_element(By.ID, "元素ID") | 当元素拥有唯一ID时使用(例如:核心功能按钮、输入框等) |
| 2. Name定位 | find_element(By.NAME, "元素Name") | 主要用于表单元素,在没有ID的情况下可以考虑使用 |
| 3. 类名定位 | find_element(By.CLASS_NAME, "类名") | 如果元素通过唯一的类名来区分,则适合使用此方法(注意类名中不应包含空格) |
| 4. 标签名定位 | find_element(By.TAG_NAME, "标签名") | 当需要批量选择同一类型的元素时使用(比如所有的input标签) |
| 5. 链接文本定位 | find_element(By.LINK_TEXT, "完整文本") | 适用于精确匹配<a>标签内的链接文本 |
| 6. 部分链接文本定位 | find_element(By.PARTIAL_LINK_TEXT, "部分文本") | 对于较长的链接文本,可以通过部分内容进行模糊匹配 |
| 7. XPath定位(万能) | find_element(By.XPATH, "XPath路径") | 在遇到较为复杂的页面结构或当元素缺乏ID和Name属性时非常有用 |
| 8. CSS选择器定位(高效) | find_element(By.CSS_SELECTOR, "CSS表达式") | 几乎适用于所有情况,并且在性能上通常优于XPath定位 |
3.1 ID定位(优先级最高,唯一标识)
根据元素的id属性值定位,最为方便且存在即唯一,有可能不存在,也可能动态生成。
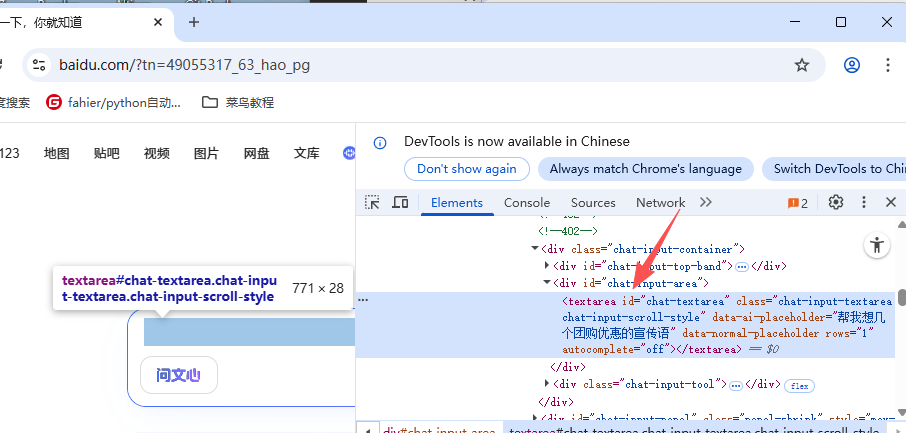
search_input = driver.find_element(By.ID, "chat-textarea")
search_input.send_keys("Selenium ID定位")
执行代码会把Selenium ID定位输入百度搜索框。
3.2 Name定位(适用于表单元素)
根据元素的name属性值定位,定位到的标签不一定是唯一的。
search_input.clear() # 清空输入框
search_input = driver.find_element(By.NAME, "wd")
search_input.send_keys("Selenium Name定位")
time.sleep(1)
3. 3 Class类名定位(注意:类名含空格时需用CSS选择器)
根据元素的class属性值定位,但可能受JS影响动态变化,定位到的标签不一定是唯一的。
# 3. 类名定位(注意:类名含空格时需用CSS选择器)
search_input.clear()
search_input = driver.find_element(By.CLASS_NAME, "s_ipt")
search_input.send_keys("Selenium 类名定位")
time.sleep(1)
3.4 TAG_NAME标签名定位(适合批量定位同类型元素)
根据元素的标签名定位,定位到的标签不一定是唯一的。
all_input_tags = driver.find_elements(By.TAG_NAME, "input")
print(f"页面中input标签总数:{len(all_input_tags)}")
3.5 LINK_TEXT链接文本定位(精确匹配标签文本)
search_input.clear()
search_input.send_keys("Selenium 链接定位")
time.sleep(1)
news_link = driver.find_element(By.LINK_TEXT, "新闻")
news_link.click()
time.sleep(1)
driver.back() # 切回百度首页
3.6 PARTIAL_LINK_TEXT部分链接文本定位(模糊匹配,适用于长文本链接)
tieba_link = driver.find_element(By.PARTIAL_LINK_TEXT, "贴")
tieba_link.click()
time.sleep(1)
driver.back()
3.7 XPath定位(万能定位,适合复杂场景)
XPath 支持多种灵活定位方式,解决复杂场景定位问题🔍:
# 3.7.1 绝对路径定位(不推荐,易失效)
driver.find_element(By.XPATH, "/html/body/div[1]/div[2]/div[1]/div[3]/a[1]")
# 3.7.2 利用元素属性定位(推荐)
driver.find_element(By.XPATH, "//input[@id='kw']") # ID属性
driver.find_element(By.XPATH, "//input[@name='wd']") # Name属性
driver.find_element(By.XPATH, "//*[@class='s_ipt']") # 任意标签+Class属性
# 3.7.3 层级与属性结合(元素无唯一属性时)
driver.find_element(By.XPATH, "//form[@id='form']/span[2]/input")
# 3.7.4 逻辑运算符(多属性联合定位)
driver.find_element(By.XPATH, "//input[@id='kw' and @class='s_ipt']")
# 3.7.5 contains方法(模糊匹配属性值)
driver.find_element(By.XPATH, "//span[contains(@class, 's_ipt_wr')]/input")
# 3.7.6 text()方法(匹配元素文本)
driver.find_element(By.XPATH, "//a[text()='新闻']") # 精确匹配
driver.find_element(By.XPATH, "//a[contains(text(), '很长的链接文本')]") # 模糊匹配
3.7.1绝对路径定位
xpath绝对路径的获得方式
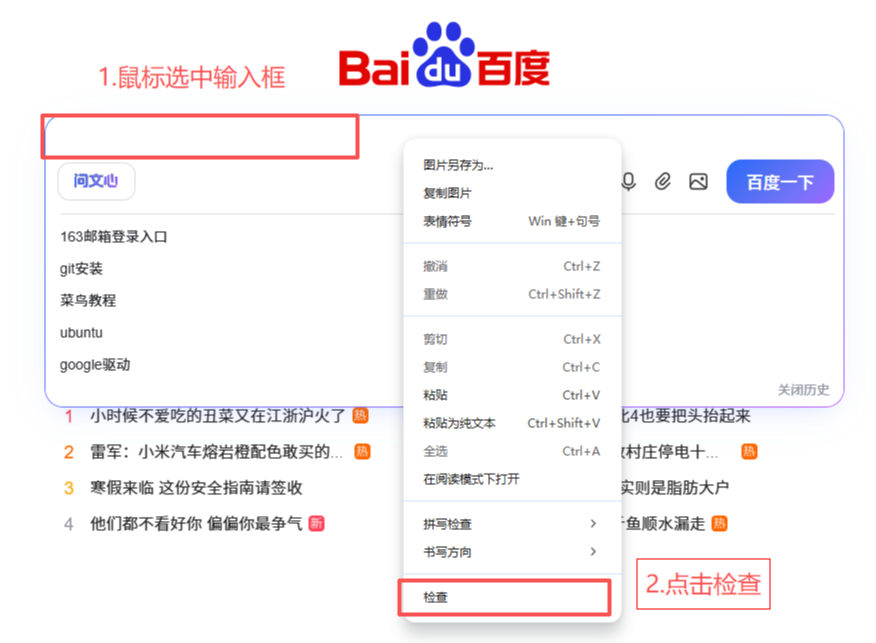

指的是从网页的HTML代码结构的最外层一层层的写到需要被定位的页面元素为止。
绝对路径起始于/html,每一层都用/进行分割。
- 可以用中括号选择分支,
div[2]代表的是当前层级下的第二个div标签; - 一般情况下较少使用绝对路径的方式做定位,原因在于绝对路径的表达式一般太长,不便于后期的代码维护,代码的微小改变就可能导致这个路径失效,从而无法完成元素定位。
a1.find_element(By.XPATH, value='/html/body/div[1]/div[2]/div[1]/div[3]/a[1]')
3.7.2利用元素属性定位(也称为相对路径定位)
不是从根目录写起,而是从网页文本的任意目录开始写。
相对路径起始于//,//所表示的含义是“任意标签下”,如//input[@id='kw']
- 示例的含义:在当前页面查找任意目录下的input元素,且该元素的id属性取值为kw
- 在xpath里,属性以@开头
- 所选取的属性可以是任意属性,只要其有利于标识这个元素即可
- 推荐使用相对路径结合属性的这种xpath表达式,它往往更简洁更易于维护
- 有时候可能会出现一个属性不足以标识某个元素,可以使用逻辑运算符and来连接多个属性进行标识。//input[@xx=‘aa’ and @yy=‘bb’]
- 有时候一个元素它本身没有可以唯一标识它的属性,这时我们可以找它的上层或者上上层, 然后再往下写。//input[@xx=‘aa’]/p
a1.find_element(By.XPATH, value='//input[@id='kw']')
a1.find_element(By.XPATH, value='//input[@name='wd']')
a1.find_element(By.XPATH, value='//input[@class='s_ipt']')
a1.find_element(By.XPATH, value='//*[@id='kw']')
a1.find_element(By.XPATH, value='//*[@name='wd']')
a1.find_element(By.XPATH, value='//*[@class='s_ipt']')
a1.find_element(By.XPATH, value='//input[@maxlength='100']')
a1.find_element(By.XPATH, value='//input[@autocomplete='off']')
a1.find_element(By.XPATH, value='//input[@type='submit']')
3.7.3.层级与属性结合
若一个元素没有唯一标识的属性值,则可以查找其上一级元素。若其上一级元素有可以唯一标识属性的值,则可以拿来用。

a1.find_element(By.XPATH, value='//span[@class='s_btn_wr']/input')
a1.find_element(By.XPATH, value='//form[@id='form']/span/input')
a1.find_element(By.XPATH, value='//form[@id='form']/span[2]/input')
3.7.4 使用逻辑运算符
若一个元素没有唯一标识的属性值。
a1.find_element(By.XPATH, value='//input[[@id='kw' and @class='s_ipt_wr']')
3.7.5使用contains方法
用于匹配一个属性中包含的字符串。
contains方法只取了class属性中的s_ipt_wr部分。
a1.find_element(By.XPATH, value='//span[contains(@class, 's_ipt_wr')]/input')
3.7.6使用text()方法
用于匹配显示文本信息。例如
a1.find_element(By.XPATH, value='//a[text(), '新闻']')
a1.find_element(By.XPATH, value='//a[contains(text(),'一个很长的')]')
3.8. CSS 选择器定位进阶技巧(高效方案)
CSS 定位速度比 XPath 快⚡,支持 7 种常用查找方式:
# 1. 类选择器(. + class值)
driver.find_element(By.CSS_SELECTOR, ".s_ipt")
# 2. ID选择器(# + ID值)
driver.find_element(By.CSS_SELECTOR, "#kw")
# 3. 标签选择器(直接写标签名)
driver.find_elements(By.CSS_SELECTOR, "textarea")[2]
# 4. 精准属性选择器([属性='值'])
driver.find_element(By.CSS_SELECTOR, "[autocomplete='off']")
# 5. 模糊属性选择器([属性*='包含值'])
driver.find_element(By.CSS_SELECTOR, "[autocomplete*='of']")
# 6. 开头属性选择器([属性^='开头值'])
driver.find_element(By.CSS_SELECTOR, "[autocomplete^='o']")
# 7. 结尾属性选择器([属性$='结尾值'])
driver.find_element(By.CSS_SELECTOR, "[autocomplete$='f']")
XPath 与 CSS 区别:
- XPath 属性值必须加引号,CSS 可加可不加(需区分表达式引号);
- 无 ID/Name 或元素属性动态变化时,优先用 XPath/CSS 定位🎯。
这两种方法相比于其它方法好在:理想状态下,一个页面当中每个元素都有唯一的ID和name,可以通过它们来查找元素。但实际中,有时候一个元素没有id和name,或者页面上有多个元素属性是相同的;更有甚是 id值是随机变化的。
四、进阶场景实战(测试高频场景)
1.表单登录操作
# 初始化驱动
driver = init_driver()
# 打开目标登录页(替换为你的测试地址)
driver.get("https://xxx.com/login")
print("=== 表单登录演示 ===")
# 输入账号
driver.find_element(By.ID, "username").send_keys("test_user_001")
# 输入密码
driver.find_element(By.ID, "password").send_keys("test_pwd_123456")
# 勾选"记住密码"
remember_check = driver.find_element(By.ID, "rememberMe")
if not remember_check.is_selected():
remember_check.click()
# 点击登录按钮
driver.find_element(By.ID, "loginBtn").click()
# 验证登录成功(显式等待欢迎信息)
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "welcomeMsg"))
)
print("登录成功!当前登录用户:", driver.find_element(By.ID, "welcomeMsg").text)
2. 下拉框操作(3 种选择方式)
from selenium.webdriver.support.select import Select
# 初始化驱动并打开含下拉框的页面
driver = init_driver()
driver.get("https://xxx.com/form")
print("=== 下拉框操作演示 ===")
# 定位下拉框(必须是<select>标签)
select_element = driver.find_element(By.ID, "citySelect")
city_select = Select(select_element)
# 方式1:通过索引选择(从0开始)
city_select.select_by_index(2)
time.sleep(1)
print(f"通过索引选择:{city_select.first_selected_option.text}")
# 方式2:通过value属性选择
city_select.select_by_value("shanghai")
time.sleep(1)
print(f"通过value选择:{city_select.first_selected_option.text}")
# 方式3:通过可见文本选择
city_select.select_by_visible_text("北京")
time.sleep(1)
print(f"通过文本选择:{city_select.first_selected_option.text}")
# 遍历所有下拉框选项
print("=== 所有下拉框选项 ===")
for option in city_select.options:
print(option.text)
3. 弹窗处(alert/confirm/prompt)
# 初始化驱动并打开含弹窗的页面
driver = init_driver()
driver.get("https://xxx.com/popup")
print("=== 弹窗处理演示 ===")
# 1. 处理alert弹窗(仅确认按钮)
driver.find_element(By.ID, "showAlertBtn").click()
time.sleep(1)
alert = driver.switch_to.alert
print(f"alert弹窗内容:{alert.text}")
alert.accept() # 点击确定✅
# 2. 处理confirm弹窗(确认/取消按钮)
driver.find_element(By.ID, "showConfirmBtn").click()
time.sleep(1)
confirm_alert = driver.switch_to.alert
print(f"confirm弹窗内容:{confirm_alert.text}")
confirm_alert.dismiss() # 点击取消❌(确认用accept())
# 3. 处理prompt弹窗(可输入内容)
driver.find_element(By.ID, "showPromptBtn").click()
time.sleep(1)
prompt_alert = driver.switch_to.alert
print(f"prompt弹窗内容:{prompt_alert.text}")
prompt_alert.send_keys("测试输入内容") # 输入文本📝
prompt_alert.accept() # 确认提交
4. iframe 切换(高频避坑点)
# 初始化驱动并打开含iframe的页面
driver = init_driver()
driver.get("https://xxx.com/iframe-page")
print("=== iframe切换演示 ===")
# 方式1:通过iframe的ID切换(推荐)
driver.switch_to.frame("loginIframe")
# 方式2:通过索引切换(页面第一个iframe)
# driver.switch_to.frame(0)
# 方式3:通过元素定位切换
# iframe_element = driver.find_element(By.XPATH, "//iframe[@name='loginFrame']")
# driver.switch_to.frame(iframe_element)
# 操作iframe内的元素(示例:登录)
driver.find_element(By.ID, "iframeUsername").send_keys("test_iframe")
driver.find_element(By.ID, "iframePwd").send_keys("iframe_pwd123")
driver.find_element(By.ID, "iframeLoginBtn").click()
# 切回主页面(必须操作,否则无法定位主页面元素)
driver.switch_to.default_content()
print("已切回主页面,可继续操作主页面元素✅")
五、关键避坑指南(测试必看)
-
驱动版本不匹配:确保 chromedriver 版本与 Chrome 浏览器前三位版本一致(如 Chrome 143.x 对应驱动 143.x),路径无中文和空格⚠️。
-
元素加载慢:优先用显式等待(
WebDriverWait),避免time.sleep()(固定等待不灵活,易导致脚本不稳定)⏳。 -
动态元素定位失败:ID/Name 带随机数时,改用 XPath/CSS 模糊匹配(如
//input[starts-with(@id, 'kw_')])🔍。 -
iframe 陷阱:元素定位失败时,先检查是否在 iframe 内(F12 查看 HTML 结构),切换 iframe 后再操作🌀。
-
窗口遮挡:启动浏览器后先执行
maximize_window(),避免元素被侧边栏、弹窗遮挡🚪。 -
版本兼容问题:Selenium 4.x 已移除
find_element_by_id()等旧写法,统一使用find_element(By.ID, "xxx")📌。 -
类名含空格:直接用
By.CLASS_NAME会报错,改用 CSS 选择器(如类名bg s_ipt对应".bg.s_ipt")💡。
六、写在最后
Python 3.14.2 + Selenium 4.39.0 本地验证通过✅,替换成你的测试网址/元素属性即可直接运行!
如果这篇文章对你有帮助,别忘了 点赞👍+收藏🌟,也欢迎在评论区聊聊你转岗测试时遇到的「踩坑瞬间」😣,我们一起交流进步~
技术相通,只要找准方向🧭,持续落地实践,测试岗位也能发挥嵌入式的技术优势~🚀



















(持续更新)&spm=1001.2101.3001.5002&articleId=157360667&d=1&t=3&u=8d1ef80593814e158ff0d794bdcd5b19)
 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












