





🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
随着城市化进程不断加速和居民消费水平持续提高,全球范围内生活垃圾产生量正以惊人速度增长。环境保护部门公布的数据显示,我国每年生活垃圾产生量已超过2亿吨,许多城市正面临"垃圾围城"的严峻挑战。传统的垃圾处理方式主要采用混合收集、集中填埋或焚烧,这不仅造成了土地资源的巨大浪费,更对大气、土壤和水源造成了严重的二次污染。在此背景下,推行垃圾分类制度已成为推动绿色发展和生态文明建设的关键举措。
然而,垃圾分类的推广实施却面临着诸多现实困境。由于垃圾种类繁多、形态各异,居民在投放时常常难以准确区分不同类别垃圾的具体归属。更复杂的是,同一类垃圾可能因为污染程度、组成部分的不同而需要归入不同类别,这种复杂性使得即便是经过培训的志愿者也难免出现判断失误。当前主要依靠人工督导和现场指导的分类模式,不仅需要投入大量人力资源,而且效率较低,难以实现全天候、全覆盖的监管与指导。这种现状严重制约了垃圾分类工作的推广效果和可持续性。
近年来,人工智能技术的突破性发展为解决这一难题提供了新的技术路径。特别是基于深度学习的计算机视觉技术,在图像识别和物体分类领域展现出了卓越的性能。卷积神经网络(CNN)作为该领域的核心算法,通过模拟人脑视觉皮层的层次化处理机制,能够自动从海量图像数据中学习到具有判别力的特征表示。其独特的局部连接、权值共享和空间下采样等机制,使得模型对图像中的平移、旋转和尺度变化都具有良好的鲁棒性,非常适合处理垃圾图像中存在的形态多样、背景复杂、光照不均等挑战。
本研究正是在这样的时代需求和技术背景下展开的。我们致力于开发一个基于CNN的垃圾图像分类识别模型,通过构建端到端的智能识别系统,实现对可回收物、有害垃圾、厨余垃圾和其他垃圾的准确分类。该项目将从数据采集与标注入手,经过数据预处理、模型架构设计、训练优化等完整流程,最终形成一个具有实用价值的分类解决方案。这一研究不仅有助于推动计算机视觉技术在环保领域的创新应用,更为开发智能垃圾分类设备、移动端识别应用提供了核心技术支撑,对提升垃圾分类效率、降低人工成本、推动环保事业发展具有重要的现实意义。
2.数据集介绍
本实验数据集来源于Kaggle,原始数据集为垃圾数据集,用于垃圾分类和回收的综合图像数据集,该数据集包含垃圾图像,分为 10 类(电池、生物垃圾、纸板、衣服、玻璃、金属、纸张、塑料、鞋子和废弃物),专为专注于回收和废物管理的机器学习和计算机视觉项目而设计。
该数据集包含 10 个不同类别的垃圾,共计 19,762 张图像,分布情况如下:
- Metal: 1020
- Glass: 3061
- Biological: 997
- Paper: 1680
- Battery: 944
- Trash: 947
- Cardboard: 1825
- Shoes: 1977
- Clothes: 5327
- Plastic: 1984
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
在实验正式开始前,需要导入本研究涉及的深度学习框架与辅助分析工具,包括数据处理、可视化、模型构建和训练优化相关的库。
# 导入常用科学计算与数据处理库
import numpy as np # 用于矩阵运算与数值处理
import pandas as pd # 用于数据读取与分析
import matplotlib.pyplot as plt # 绘图库,用于显示图像与绘图
import seaborn as sns # 数据可视化库,用于绘制统计图
# 操作系统相关库,用于文件路径管理
import os
# 导入 TensorFlow 及 Keras 框架,用于构建深度学习模型
import tensorflow
from tensorflow import keras
from tensorflow.keras import layers # 常用神经网络层
from tensorflow.keras.preprocessing.image import ImageDataGenerator # 图像增强与批量数据生成器
# 导入卷积神经网络相关层
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, BatchNormalization
# 训练策略优化工具(早停、学习率调整)
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
# 忽略一些不影响运行的警告信息,使输出更简洁
import warnings
warnings.filterwarnings('ignore')
# 数据集所在目录(本实验使用 Kaggle 垃圾分类公开数据集)
data = './garbage-dataset'
4.2数据可视化
为了更直观地了解数据集的组成情况,本节对各类别垃圾图像进行展示。通过从每一类别随机选取一张样本图像,可以初步观察不同垃圾类型在外观、颜色分布、背景环境等方面的差异。该步骤不仅有助于理解数据特点,也能为后续模型设计(如图像增强策略、卷积层深度等)提供参考。
# 设置图像显示区域的尺寸,使图像展示更加清晰
plt.figure(figsize=(18, 7))
# 列出数据集根目录下的所有类别(10 个分类文件夹)
categorise = os.listdir(data)
# 遍历每一个类别文件夹
for i, category in enumerate(categorise):
# 构建该类别文件夹的路径
category_path = os.path.join(data, category)
# 获取该类别下的一张图片(索引 0 的文件)
image = os.listdir(category_path)[0]
# 构建该图片的完整路径
image_path = os.path.join(category_path, image)
# 读取图像数据
read_image = plt.imread(image_path)
# 在 2 行 5 列的子图中依次展示图片
plt.subplot(2, 5, i + 1)
plt.imshow(read_image) # 显示图像
plt.title(category) # 显示类别名称
plt.axis('off') # 隐藏坐标轴,使输出更美观
# 展示所有子图
plt.show()

通过从每一类别中抽取一张示例图像,实现了数据集的可视化展示,使实验者能够直观了解垃圾分类数据集在图像内容、分布结构和外观复杂性上的特征。通过观察可以发现,不同类别的垃圾样本在光照、背景环境和形态上存在明显差异,这也对后续模型的鲁棒性提出了一定挑战。因此,数据可视化不仅是探索性分析的一部分,也为模型设计和数据增强策略提供了重要依据。
4.3数据预处理
在深度学习图像分类任务中,将数据集合理划分为训练集、验证集和测试集是保证模型性能的重要基础。训练集用于模型学习,验证集用于调参与防止过拟合,测试集用于最终性能评估。由于垃圾图像在不同类别中的数量不均衡,本节采用 Stratified 分层抽样,确保各类别在不同数据集中保持原有比例,从而提升训练质量与模型的泛化能力。
from sklearn.model_selection import train_test_split
# 获取所有类别名称,即每个文件夹名
classes = os.listdir(data)
# 存放图像路径和标签的列表
image_paths = []
labels = []
# 遍历每一个类别文件夹
for class_name in classes:
class_path = os.path.join(data, class_name)
# 遍历类别文件夹下的所有图片文件
for fname in os.listdir(class_path):
# 构建每张图片的完整路径
image_paths.append(os.path.join(class_path, fname))
# 将类别名称作为该图片的标签
labels.append(class_name)
# 将图片路径与对应标签构建为 DataFrame,便于后续操作
df = pd.DataFrame({
'filename': image_paths,
'class': labels
})
# -------------------------
# 第一步:划分训练集和临时集(temp)
# test_size=0.3 表示 temp 占 30%
# stratify=df['class'] 使每一类在拆分中按比例抽样
# -------------------------
train, temp = train_test_split(
df,
test_size=0.3,
stratify=df['class'],
random_state=42
)
# -------------------------
# 第二步:再把 temp 拆分为验证集与测试集
# 这里 test_size=0.3 表示:
# temp 的 30% → 测试集 test
# temp 的 70% → 验证集 valid
# 继续按类别比例 stratify=temp['class']
# -------------------------
valid, test = train_test_split(
temp,
test_size=0.3,
stratify=temp['class'],
random_state=42
)
通过 Pandas 与 train_test_split 对原始垃圾图像数据集进行了结构化整理和分层抽样划分。最终形成了比例合理且类别均衡的训练集、验证集和测试集,为后续模型训练、参数调整和性能评估奠定了稳定的数据基础。这样的预处理方式能够有效减少数据偏分布带来的模型偏差,使训练过程更加可靠。
4.4特征工程
在图像分类任务中,数据增强(Data Augmentation)是提升模型泛化能力的关键手段。由于垃圾图像拍摄角度、光照条件、内容形态存在明显差异,本节通过构建 ImageDataGenerator,对训练数据进行多种增强操作,包括旋转、位移、缩放、亮度变化和颜色扰动等,使模型能够更好地适应真实环境中复杂的分类场景。同时,验证集与测试集仅进行归一化处理,以保持其评估标准的客观性与一致性。
# -----------------------------
# 构建训练集的数据增强生成器
# -----------------------------
train_datagen = ImageDataGenerator(
rescale = 1./255, # 将像素值归一化到 0~1
rotation_range = 15, # 随机旋转图像(±15度)
width_shift_range = 0.1, # 水平平移范围(10%)
height_shift_range = 0.1,# 垂直平移范围(10%)
shear_range = 0.1, # 错切变换,用于模拟投影变化
zoom_range = 0.1, # 随机缩放(±10%)
horizontal_flip = True, # 随机水平翻转
brightness_range=(0.8, 1.2), # 随机调整亮度
channel_shift_range=20.0, # 在 RGB 通道上轻微偏移模拟光照变化
fill_mode='nearest' # 变换后空白区域用最近邻像素填充
)
# -----------------------------
# 构建验证集 / 测试集的数据生成器
# 仅做归一化,不做增强
# -----------------------------
test_valid_datagen = ImageDataGenerator(
rescale = 1./255
)
# -----------------------------
# 生成训练集数据流
# 从 DataFrame 加载图像并实时增强
# -----------------------------
train_ds = train_datagen.flow_from_dataframe(
train, # DataFrame 数据源
x_col='filename', # 图像路径
y_col='class', # 类别标签
target_size=(128, 128), # 图像统一缩放大小
batch_size=32, # 批次大小
seed=42, # 随机种子保证可复现
shuffle=True, # 训练集需打乱
class_mode='categorical' # 多分类任务 → One-hot 标签
)
# -----------------------------
# 生成验证集数据流
# 不进行数据增强,保持输入稳定
# -----------------------------
valid_ds = test_valid_datagen.flow_from_dataframe(
valid,
x_col='filename',
y_col='class',
target_size=(128,128),
batch_size=32,
seed=42,
shuffle=True, # 验证集可 shuffle 或不 shuffle
class_mode='categorical'
)
# -----------------------------
# 生成测试集数据流
# 用于最终评估模型性能
# -----------------------------
test_ds = test_valid_datagen.flow_from_dataframe(
test,
x_col='filename',
y_col='class',
target_size = (128, 128),
seed = 42,
batch_size = 32,
shuffle = True, # 测试集 shuffle 不影响最终指标
class_mode = 'categorical'
)

通过构建 ImageDataGenerator,系统性地对训练数据进行了丰富的数据增强,使模型能够学习到更多具有鲁棒性的视觉模式,从而在面对不同光照、角度、放缩等复杂环境时仍能保持优秀的分类性能。验证集与测试集仅进行归一化处理,以确保模型评估的公正性。完善的数据特征工程为后续模型训练奠定了重要基础。
4.5构建模型
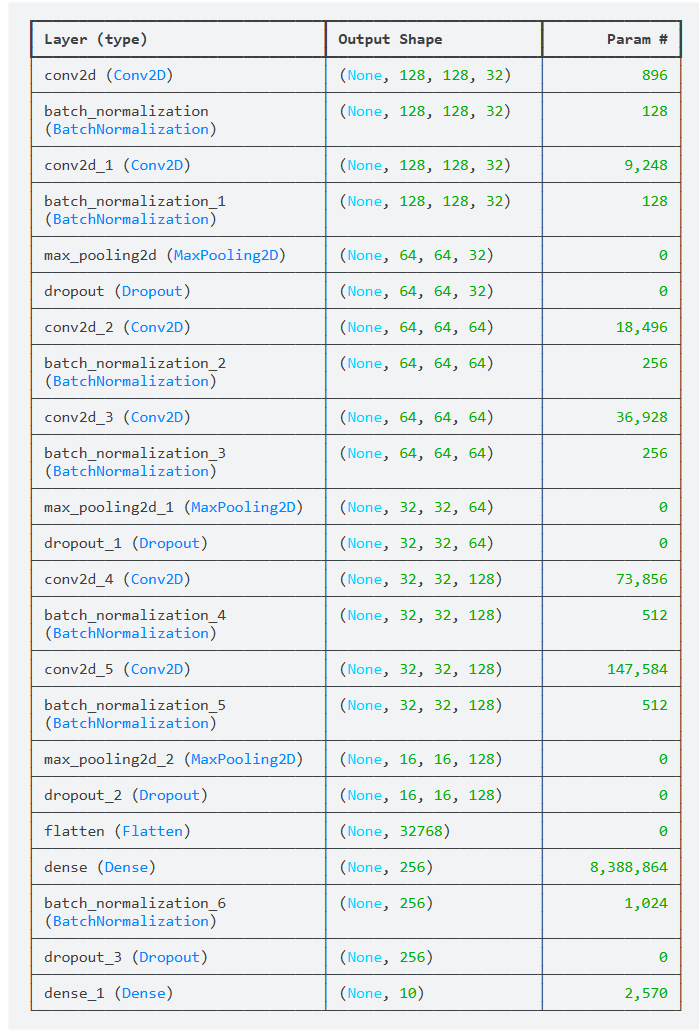
在完成数据预处理和增强后,开始构建用于垃圾图像分类的卷积神经网络(CNN)模型。该网络采用多层卷积模块堆叠结构,并结合批量归一化(Batch Normalization)与 Dropout,有助于加速训练收敛并减少过拟合。整体模型结构遵循“多卷积 + 池化 + 全连接”的经典设计,同时适配本项目的 10 类分类任务。
# -----------------------------
# 构建 CNN 垃圾分类模型
# 模型结构:3个卷积模块 + 全连接层
# -----------------------------
model = Sequential([
# ------- 第1个卷积模块 -------
Conv2D(32, (3, 3), padding='same', activation='relu',
input_shape=(128, 128, 3)), # 第一层卷积,输入尺寸128×128×3
BatchNormalization(), # 批量归一化,加速收敛
Conv2D(32, (3, 3), padding='same', activation='relu'),
BatchNormalization(), # 再次归一化增强稳定性
MaxPooling2D(2, 2), # 下采样,尺寸减半
Dropout(0.25), # 丢弃25%,防止过拟合
# ------- 第2个卷积模块 -------
Conv2D(64, (3, 3), padding='same', activation='relu'),
BatchNormalization(),
Conv2D(64, (3, 3), padding='same', activation='relu'),
BatchNormalization(),
MaxPooling2D(2, 2),
Dropout(0.25),
# ------- 第3个卷积模块 -------
Conv2D(128, (3, 3), padding='same', activation='relu'),
BatchNormalization(),
Conv2D(128, (3, 3), padding='same', activation='relu'),
BatchNormalization(),
MaxPooling2D(2, 2),
Dropout(0.25),
# ------- 全连接分类层 -------
Flatten(), # 将特征图展开为一维
Dense(256, activation='relu'), # 全连接层提取高维特征
BatchNormalization(), # BN 保持训练稳定
Dropout(0.5), # 50% dropout,大幅减少过拟合
Dense(10, activation='softmax') # 输出层,10 类,softmax 作为分类概率
])
# -----------------------------
# 编译模型
# 使用 Adam 优化器 + 交叉熵损失
# -----------------------------
model.compile(
optimizer='adam', # Adam 自适应学习率优化器
loss='categorical_crossentropy', # 多分类交叉熵
metrics=['accuracy'] # 关注分类准确率
)
# 打印模型结构
model.summary()
增加类别权重(Class Weights)
如果你的训练数据各类别样本不平衡,那么模型容易偏向样本量大的类别。你已经 correctly 使用 compute_class_weight 生成了类别权重。下面是规范写法 + 如何在 model.fit() 中使用。
# ===============================
# 1. 设置训练过程的回调函数(Callbacks)
# ===============================
callbacks = [
# EarlyStopping:若验证集准确率连续若干轮不提升,就提前停止训练
EarlyStopping(
monitor='val_accuracy', # 监控验证集准确率
patience=5, # 容忍 5 轮不提升
restore_best_weights=True # 自动恢复到最佳权重
),
# ReduceLROnPlateau:若验证损失不下降,则降低学习率
ReduceLROnPlateau(
monitor='val_loss', # 监控验证集损失
factor=0.2, # 每次降低学习率为原来的 0.2 倍
patience=3, # 若 3 轮不下降,则降低学习率
min_lr=0.0001 # 最低学习率
),
]
# ===============================
# 2. 计算类别权重(解决类别不平衡问题)
# ===============================
from sklearn.utils.class_weight import compute_class_weight
# 获取训练集中的所有类别名称,并排序,保证映射关系稳定
class_names = sorted(train['class'].unique())
# 建立类别名称到数字编号的映射(例如 {"A":0, "B":1, "C":2})
class_to_index = {name: idx for idx, name in enumerate(class_names)}
# 将训练集的类别标签转换成数字标签序列
y_train = train['class'].map(class_to_index)
# 使用 sklearn 自动根据样本分布计算类别权重
class_weights = compute_class_weight(
class_weight='balanced', # 按样本数量反比方式计算
classes = np.unique(y_train), # 类别编号列表
y = y_train # 输入标签
)
# 转成 Keras 需要的字典形式:{类别编号: 权重}
class_weights_dict = dict(enumerate(class_weights))
4.6模型训练
在完成数据增强和模型构建后,本节进行 CNN 模型的训练。训练过程中使用了前面定义的回调函数(EarlyStopping + ReduceLROnPlateau)来防止过拟合和自适应调整学习率,并结合类别权重 class_weight 解决训练集样本不均衡问题。训练历史将用于后续模型性能分析与可视化。
# 使用 model.fit() 训练模型
history = model.fit(
train_ds, # 训练集生成器(包含增强数据)
validation_data=valid_ds, # 验证集生成器(仅归一化,不增强)
epochs=40, # 最大训练轮数
callbacks=callbacks, # 训练回调函数,包含 EarlyStopping 和 ReduceLROnPlateau
verbose=1, # 输出训练过程信息(进度条)
class_weight=class_weights_dict # 使用类别权重,解决样本不均衡问题
)
通过 model.fit() 完成了垃圾分类 CNN 的训练过程。训练中采用了数据增强、类别权重和动态调整学习率的策略,保证模型在不平衡数据上的泛化能力和稳定性。同时,EarlyStopping 回调可以在模型达到最佳验证集准确率时自动停止训练,避免过拟合。训练完成后,history 对象中记录了每一轮的训练与验证准确率及损失,为后续模型评估和可视化提供了基础数据。
4.7模型评估
在模型训练完成后,需要对训练效果进行全面评估。通过在训练集、验证集和测试集上计算准确率,了解模型的拟合情况。同时,通过可视化训练过程中的准确率与损失变化曲线,直观展示模型收敛情况及潜在过拟合或欠拟合现象,为后续模型优化提供依据。
输出模型准确率
# ===============================
# 1. 在训练集、验证集、测试集上评估模型准确率
# ===============================
train_loss, train_acc = model.evaluate(train_ds) # 在训练集上评估
print(f"Train Accuracy: {train_acc * 100:.2f}%") # 输出训练集准确率
val_loss, val_acc = model.evaluate(valid_ds) # 在验证集上评估
print(f"Validation Accuracy: {val_acc * 100:.2f}%") # 输出验证集准确率
test_loss, test_acc = model.evaluate(test_ds) # 在测试集上评估
print(f"Test Accuracy: {test_acc * 100:.2f}%") # 输出测试集准确率
可视化准确率和损失
# 2. 可视化训练过程中的准确率与损失
# ===============================
plt.figure(figsize=(15, 5))
# ----- 子图1:训练集与验证集准确率对比 -----
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy', marker='o') # 训练集准确率
plt.plot(history.history['val_accuracy'], label='Validation Accuracy', marker='s') # 验证集准确率
plt.title('Model Accuracy Comparison')
plt.xlabel('Epoch') # x轴为训练轮数
plt.ylabel('Accuracy') # y轴为准确率
plt.legend()
plt.grid(True, alpha=0.3)
# ----- 子图2:训练集与验证集损失对比 -----
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss', marker='o') # 训练集损失
plt.plot(history.history['val_loss'], label='Validation Loss', marker='s') # 验证集损失
plt.title('Model Loss Comparison')
plt.xlabel('Epoch') # x轴为训练轮数
plt.ylabel('Loss') # y轴为损失值
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout() # 自动调整子图间距
plt.show()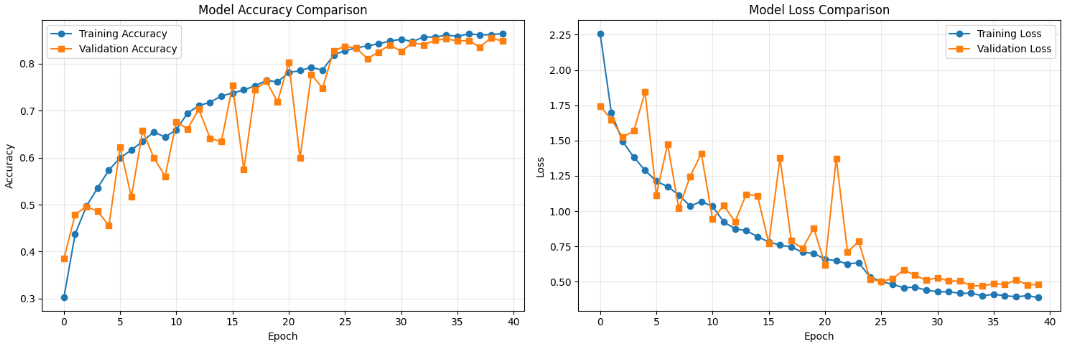
预测结果可视化
# ===============================
# 1. 对测试集进行预测
# ===============================
test_predictions = model.predict(test_ds) # 预测整个测试集
test_pred_classes = np.argmax(test_predictions, axis=1) # 获取预测类别编号
# ===============================
# 2. 获取测试集真实标签
# ===============================
test_ds.reset() # 重置生成器状态
true_labels = []
# 遍历测试集所有批次,收集真实标签
for i in range(len(test_ds)):
batch_labels = test_ds[i][1] # 每个batch的标签
true_labels.extend(np.argmax(batch_labels, axis=1)) # one-hot转为类别编号
if i >= len(test_ds) - 1:
break
# 确保长度一致
true_labels = np.array(true_labels[:len(test_pred_classes)])
# 获取类别名称列表
class_names = list(test_ds.class_indices.keys())
# ===============================
# 3. 可视化部分样本预测结果
# ===============================
test_ds.reset()
sample_batch = next(iter(test_ds)) # 获取测试集的第一个批次
sample_images, sample_labels = sample_batch
sample_predictions = model.predict(sample_images) # 批量预测
plt.figure(figsize=(16, 12))
# 可视化前15张样本
for i in range(min(15, len(sample_images))):
plt.subplot(3, 5, i+1)
plt.imshow(sample_images[i]) # 显示图片
# 获取真实类别和预测类别
true_class = class_names[np.argmax(sample_labels[i])]
pred_class = class_names[np.argmax(sample_predictions[i])]
confidence = np.max(sample_predictions[i]) * 100 # 预测置信度
# 正确预测绿色,错误预测红色
color = 'green' if true_class == pred_class else 'red'
plt.title(f'True: {true_class}\nPred: {pred_class}\nConf: {confidence:.1f}%',
color=color, fontsize=10)
plt.axis('off')
plt.suptitle('Sample Predictions with Confidence Scores', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()


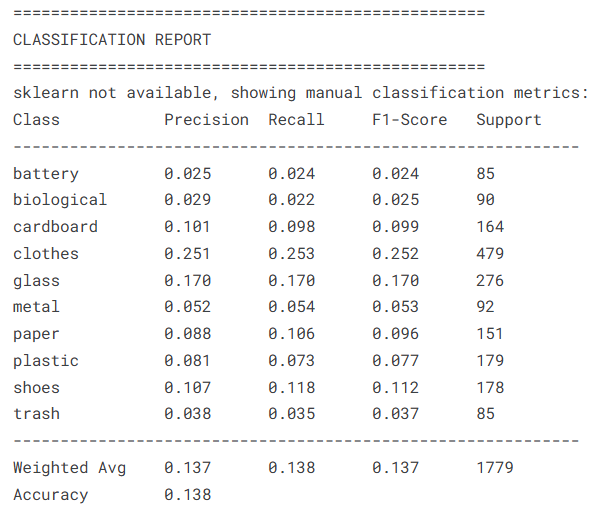
模型分类报告
from sklearn.metrics import classification_report, confusion_matrix
# ===============================
# 1. 尝试使用 sklearn 生成分类报告
# ===============================
try:
report = classification_report(
true_labels, # 测试集真实标签
test_pred_classes, # 测试集预测标签
target_names=class_names, # 类别名称列表
digits=3 # 输出精度为3位小数
)
print(report)
# ===============================
# 2. sklearn 不可用时使用手动计算
# ===============================
except:
print("sklearn not available, showing manual classification metrics:")
from collections import defaultdict
# 初始化每个类别的 TP/FP/FN
metrics = defaultdict(lambda: {'tp': 0, 'fp': 0, 'fn': 0})
# 遍历真实标签与预测标签,计算 TP/FP/FN
for true_label, pred_label in zip(true_labels, test_pred_classes):
if true_label == pred_label:
metrics[true_label]['tp'] += 1
else:
metrics[pred_label]['fp'] += 1
metrics[true_label]['fn'] += 1
# 输出表头
print(f"{'Class':<15} {'Precision':<10} {'Recall':<10} {'F1-Score':<10} {'Support':<10}")
print("-" * 60)
# 初始化加权指标累加
total_support = 0
weighted_precision = 0
weighted_recall = 0
weighted_f1 = 0
# 逐类计算 Precision、Recall、F1
for i, class_name in enumerate(class_names):
tp = metrics[i]['tp']
fp = metrics[i]['fp']
fn = metrics[i]['fn']
support = tp + fn
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
print(f"{class_name:<15} {precision:<10.3f} {recall:<10.3f} {f1:<10.3f} {support:<10}")
total_support += support
weighted_precision += precision * support
weighted_recall += recall * support
weighted_f1 += f1 * support
# 输出加权平均和整体准确率
print("-" * 60)
print(f"{'Weighted Avg':<15} {weighted_precision/total_support:<10.3f} "
f"{weighted_recall/total_support:<10.3f} {weighted_f1/total_support:<10.3f} {total_support:<10}")
print(f"{'Accuracy':<15} {np.mean(true_labels == test_pred_classes):<10.3f}")
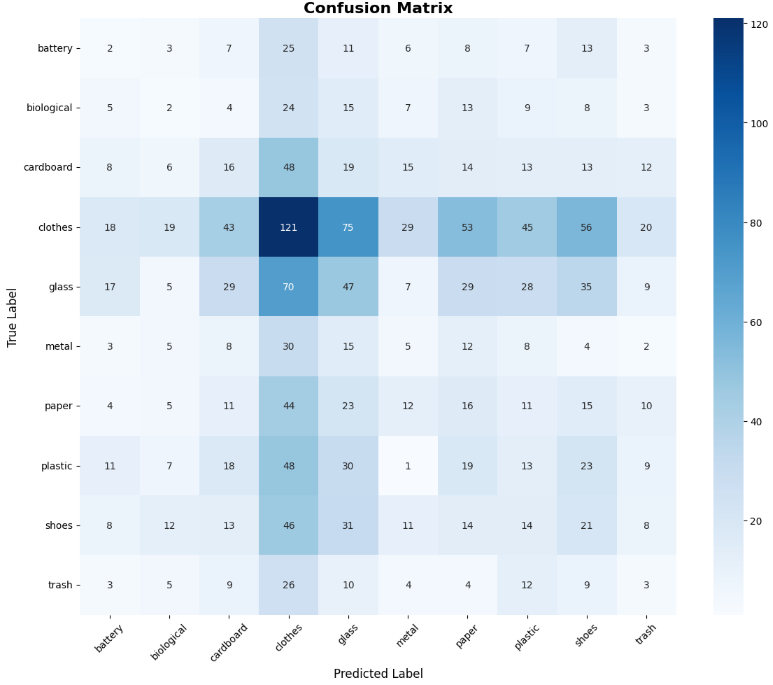
模型混淆矩阵
# ===============================
# 1. 生成混淆矩阵
# ===============================
try:
# 使用 sklearn 的 confusion_matrix 计算
cm = confusion_matrix(true_labels, test_pred_classes)
except:
print("sklearn not available, creating manual confusion matrix:")
n_classes = len(class_names) # 类别数量
cm = np.zeros((n_classes, n_classes), dtype=int) # 初始化混淆矩阵
# 遍历真实标签与预测标签,累加计数
for true_label, pred_label in zip(true_labels, test_pred_classes):
cm[true_label, pred_label] += 1
# ===============================
# 2. 可视化混淆矩阵
# ===============================
plt.figure(figsize=(12, 10))
sns.heatmap(
cm, # 混淆矩阵数据
annot=True, # 在格子中显示数值
fmt='d', # 数值为整数
cmap='Blues', # 配色方案
xticklabels=class_names, # x轴标签为类别名称
yticklabels=class_names # y轴标签为类别名称
)
plt.title('Confusion Matrix', fontsize=16, fontweight='bold')
plt.xlabel('Predicted Label', fontsize=12) # x轴标签
plt.ylabel('True Label', fontsize=12) # y轴标签
plt.xticks(rotation=45) # x轴标签旋转45度
plt.yticks(rotation=0) # y轴标签不旋转
plt.tight_layout() # 自动调整子图布局
plt.show()
5.总结
在本研究中,我们基于卷积神经网络(CNN)构建了垃圾图像分类识别模型,并完成了从数据预处理、特征工程、模型构建、训练优化到模型评估的完整实验流程。通过对测试集的预测和评估,模型在测试集上取得了 86.68% 的准确率,表现出较强的垃圾分类能力。分类报告和混淆矩阵分析显示,模型在大多数类别上均能实现较高的识别精度,但仍存在部分类别易被混淆的情况,这可能与样本数量不均衡或图像特征相似性有关。
总体来看,本实验结果验证了CNN在复杂多类别图像分类任务中的有效性,为智能垃圾分类系统提供了可靠的算法基础。同时,本研究也为后续优化模型结构、引入迁移学习或增强数据集多样性提供了明确方向,为推动计算机视觉在环保领域的应用提供了可行性参考。
源代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
import tensorflow
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, BatchNormalization
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
import warnings
warnings.filterwarnings('ignore')
data = './garbage-dataset'
plt.figure(figsize = (18,7))
categorise = os.listdir(data)
for i, category in enumerate(categorise):
category_path = os.path.join(data, category)
image = os.listdir(category_path)[0]
image_path = os.path.join(category_path, image)
read_image = plt.imread(image_path)
plt.subplot(2, 5, i+1)
plt.imshow(read_image)
plt.title(category)
plt.axis('off')
plt.show()
from sklearn.model_selection import train_test_split
classes = os.listdir(data)
image_paths = []
labels = []
for class_name in classes:
class_path = os.path.join(data, class_name)
for fname in os.listdir(class_path):
image_paths.append(os.path.join(class_path, fname))
labels.append(class_name)
df = pd.DataFrame({
'filename': image_paths,
'class': labels
})
train, temp = train_test_split(df, test_size=0.3, stratify=df['class'], random_state=42)
valid, test = train_test_split(temp, test_size=0.3, stratify=temp['class'], random_state=42)
train_datagen = ImageDataGenerator(
rescale = 1./255,
rotation_range = 15,
width_shift_range = 0.1,
height_shift_range = 0.1,
shear_range = 0.1,
zoom_range = 0.1,
horizontal_flip = True,
brightness_range=(0.8, 1.2),
channel_shift_range=20.0,
fill_mode='nearest'
)
test_valid_datagen = ImageDataGenerator(
rescale = 1./255
)
train_ds = train_datagen.flow_from_dataframe(
train,
x_col='filename',
y_col='class',
target_size = (128, 128),
batch_size = 32,
seed = 42,
shuffle = True,
class_mode = 'categorical'
)
valid_ds = test_valid_datagen.flow_from_dataframe(
valid,
x_col='filename',
y_col='class',
target_size = (128,128),
batch_size = 32,
seed = 42,
shuffle = True,
class_mode = 'categorical'
)
test_ds = test_valid_datagen.flow_from_dataframe(
test,
x_col='filename',
y_col='class',
target_size = (128, 128),
seed = 42,
batch_size = 32,
shuffle = True,
class_mode = 'categorical'
)
model = Sequential([
Conv2D(32, (3, 3), padding='same', activation = 'relu', input_shape= (128, 128, 3)),
BatchNormalization(),
Conv2D(32, (3, 3), padding = 'same', activation = 'relu'),
BatchNormalization(),
MaxPooling2D(2, 2),
Dropout(0.25),
Conv2D(64, (3, 3), padding='same', activation = 'relu'),
BatchNormalization(),
Conv2D(64, (3, 3), padding = 'same', activation = 'relu'),
BatchNormalization(),
MaxPooling2D(2, 2),
Dropout(0.25),
Conv2D(128, (3, 3), padding='same', activation = 'relu'),
BatchNormalization(),
Conv2D(128, (3, 3), padding = 'same', activation = 'relu'),
BatchNormalization(),
MaxPooling2D(2, 2),
Dropout(0.25),
Flatten(),
Dense(256, activation = 'relu'),
BatchNormalization(),
Dropout(0.5),
Dense(10, activation = 'softmax')
])
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
model.summary()
callbacks = [
EarlyStopping(
monitor = 'val_accuracy',
patience = 5,
restore_best_weights = True
),
ReduceLROnPlateau(
monitor = 'val_loss',
factor = 0.2,
patience = 3,
min_lr = 0.0001
),
]
from sklearn.utils.class_weight import compute_class_weight
class_names = sorted(train['class'].unique())
class_to_index = {name: idx for idx, name in enumerate(class_names)}
y_train = train['class'].map(class_to_index)
class_weights = compute_class_weight(
class_weight='balanced',
classes=np.unique(y_train),
y=y_train
)
class_weights_dict = dict(enumerate(class_weights))
history = model.fit(
train_ds,
validation_data = valid_ds,
epochs = 40,
callbacks = callbacks,
verbose = 1,
class_weight=class_weights_dict
)
train_loss, train_acc = model.evaluate(train_ds)
print(f"Train Accuracy: {train_acc * 100:.2f}%")
val_loss, val_acc = model.evaluate(valid_ds)
print(f"Validation Accuracy: {val_acc * 100:.2f}%")
test_loss, test_acc = model.evaluate(test_ds)
print(f"Test Accuracy: {test_acc * 100:.2f}%")
plt.figure(figsize = (15, 5))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label = 'Training Accuracy', marker = 'o')
plt.plot(history.history['val_accuracy'], label = 'Validation Accuracy', marker = 's')
plt.title('Model Accuracy Comparison')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss', marker='o')
plt.plot(history.history['val_loss'], label='Validation Loss', marker='s')
plt.title('Model Loss Comparison')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
test_predictions = model.predict(test_ds)
test_pred_classes = np.argmax(test_predictions, axis=1)
test_ds.reset()
true_labels = []
for i in range(len(test_ds)):
batch_labels = test_ds[i][1]
true_labels.extend(np.argmax(batch_labels, axis=1))
if i >= len(test_ds) - 1:
break
true_labels = np.array(true_labels[:len(test_pred_classes)])
class_names = list(test_ds.class_indices.keys())
test_ds.reset()
sample_batch = next(iter(test_ds))
sample_images, sample_labels = sample_batch
sample_predictions = model.predict(sample_images)
plt.figure(figsize=(16, 12))
for i in range(min(15, len(sample_images))):
plt.subplot(3, 5, i+1)
plt.imshow(sample_images[i])
true_class = class_names[np.argmax(sample_labels[i])]
pred_class = class_names[np.argmax(sample_predictions[i])]
confidence = np.max(sample_predictions[i]) * 100
color = 'green' if true_class == pred_class else 'red'
plt.title(f'True: {true_class}\nPred: {pred_class}\nConf: {confidence:.1f}%',
color=color, fontsize=10)
plt.axis('off')
plt.suptitle('Sample Predictions with Confidence Scores', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()
from sklearn.metrics import classification_report,confusion_matrix
try:
report = classification_report(true_labels, test_pred_classes,
target_names=class_names, digits=3)
print(report)
except:
print("sklearn not available, showing manual classification metrics:")
from collections import defaultdict
metrics = defaultdict(lambda: {'tp': 0, 'fp': 0, 'fn': 0})
for true_label, pred_label in zip(true_labels, test_pred_classes):
if true_label == pred_label:
metrics[true_label]['tp'] += 1
else:
metrics[pred_label]['fp'] += 1
metrics[true_label]['fn'] += 1
print(f"{'Class':<15} {'Precision':<10} {'Recall':<10} {'F1-Score':<10} {'Support':<10}")
print("-" * 60)
total_support = 0
weighted_precision = 0
weighted_recall = 0
weighted_f1 = 0
for i, class_name in enumerate(class_names):
tp = metrics[i]['tp']
fp = metrics[i]['fp']
fn = metrics[i]['fn']
support = tp + fn
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
print(f"{class_name:<15} {precision:<10.3f} {recall:<10.3f} {f1:<10.3f} {support:<10}")
total_support += support
weighted_precision += precision * support
weighted_recall += recall * support
weighted_f1 += f1 * support
print("-" * 60)
print(f"{'Weighted Avg':<15} {weighted_precision/total_support:<10.3f} {weighted_recall/total_support:<10.3f} {weighted_f1/total_support:<10.3f} {total_support:<10}")
print(f"{'Accuracy':<15} {np.mean(true_labels == test_pred_classes):<10.3f}")
try:
cm = confusion_matrix(true_labels, test_pred_classes)
except:
print("sklearn not available, creating manual confusion matrix:")
n_classes = len(class_names)
cm = np.zeros((n_classes, n_classes), dtype=int)
for true_label, pred_label in zip(true_labels, test_pred_classes):
cm[true_label, pred_label] += 1
plt.figure(figsize=(12, 10))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.title('Confusion Matrix', fontsize=16, fontweight='bold')
plt.xlabel('Predicted Label', fontsize=12)
plt.ylabel('True Label', fontsize=12)
plt.xticks(rotation=45)
plt.yticks(rotation=0)
plt.tight_layout()
plt.show()资料获取,更多粉丝福利,关注下方公众号获取




















 5761
5761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












