



这篇主要关注文件读写,同时涵盖着用户操作、联机帮助。
0、直观系统概览图
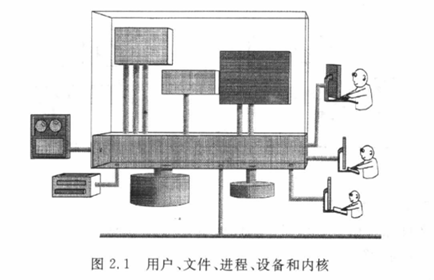
图2.1中最大的长方体代表计算机内存,它被分为用户空间和系统空间,用户通过终端连接到系统,一大一小两个柱状体代表两个硬盘,系统中还有一个打印机。靠上方的3个较小的长方体代表3个应用程序,它们运行在用户空间,通过内核与外界进行通信,应用程序和内核之间的连线代表通信管道。
1、编写who命令
(1)who命令能做些什么?
第一步,在终端直接输入who,能够看到输出的信息,这也是后面编写需要输出的信息。
第二步,了解who命令的用法,因为who命令还带参数和选项。这可以在终端输入man who,查看who命令的帮助信息(名字、概要、描述、选项、 参阅帮助等)。
现在,我们知道who命令显示当前系统中已经登录的用户信息,联机帮助中描述who的功能和用法。
接下来需要知道who怎么实现功能的。
(2)who命令是如何工作的?
通过联机帮助(man who -> man -k utmp -> man 5 utmp -> usr/include/utmp.h)。
通过阅读who和 utmp的联机帮助,以及头文件/usr/include/utmp.h,可以知道who的工作原理,who通过读文件来获得需要的信息,而每个登录的用户在文件中都有对应的记录。who的工作流程可以用图2.2来表示。
文件中的结构数组存放登录用户的信息,所以直接的想法就是把记录一个一个地读出并显示出来,是不是就这么简单呢?
(3)如何编写who命令?
编写who命令:从文件中读取数据结构;将结构中的信息以合适的形式显示出来。
(4)问题:如何从文件中读取数据结构
可以调用getc和fgets函数从文件中读字符或字符串,但是如何读出数据结构中的信息呢?当然可以用getc逐个字节地读取,但这样太繁琐,而且效率很低。要找一种可以一次读出整个数据结构的方法。
还是到联机帮助中寻找答案,可以找那些与file和read都有关的帮助:man file | grep read -> man 2 read
read这个系统调用可以将文件中一定数目的字节读入一个缓冲区,因为每次都要读入一个数据结构,所以要用sizeof(struct utmp)来指定每次读入的字节数。read函数需要一个文件描述符作为输入参数,如何得到文件描述符呢?man 2 open
(5)答案:使用open、read和close
使用上述3个系统调用可以从 utmp文件中取得用户登录信息。
(6)打开一个文件:open
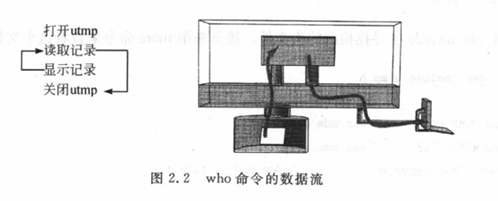
这个系统调用在进程和文件之间建立一条连接,这个连接被称为文件描述符,它就像一条由进程通向内核的管道,如图2.3所示。
open的基本用法如下。
要打开一个文件,必须指定文件名和打开模式,有3种打开模式:只读、只写、可读可写,分别对应于O_RDONLY、O_WRONLY、O_RDWR,这在头文件/usr/include/fcntl.h中有定义。
打开文件是内核提供的服务,如果在打开过程中内核检测到任何错误,这个系统调用就会返回-1。错误类型是各种各样的,如:要打开的文件不存在。即使文件存在,也可能因为权限不够而无法打开,或者是无权访问文件所在的目录。
当一个文件已经被打开,是否允许再次打开呢?这种情况发生在有多个进程要同时访问一个文件的时候。Unix并不禁止一个文件同时被多个进程访问。
如果文件被顺利打开,内核会返回一个正整数的值,这个数值就叫做文件描述符。刚才讲过,打开文件会建立进程和文件之间的连接,文件描述符就是用来惟一标识这个连接的,如果同时打开好几个文件,它们所对应的文件描述符是不同的,如果将一个文件打开多次,对应的文件描述符也不相同。
必须通过文件描述符对文件进行操作。
注意包含头文件 <fcntl. h>
(7)从文件读取数据:read
通过read函数来读取数据,read的用法如下:
read这个系统调用请求内核从fd所指定的文件中读取qty字节的数据,存放到buf所指定的内存空间中,内核如果成功地读取了数据,就返回所读取的字节数目,否则返回-1。
这里有个问题,就是最终读到的数据可能没有你所要求的那么多,为什么呢?可能是因为文件中剩余的数据没有要求的那么多。例如:程序要求读1000字节的数据,而文件的长度才500个字节,那么程序就只能读到500字节。当读到文件末尾时再要读的话,numread会是0,因为已经没有数据可读了。
注意包含头文件 <unistd. h>
(8)关闭文件:close
当不需要再对文件进行读写操作时,就要把文件关闭。close的用法如下。
closc这个系统调用会关闭进程和文件fd之间的连接,如果关闭的过程中出现错误,close返回-1,例如:fd所指的文件并不存在。
注意包含头文件 <unistd. h>
(9)编写who1.c
/*who1.c*/
#include <utmp.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
void show_info(struct utmp *utbufp);
int main(void) {
int utmpfd;
struct utmp current_utmp;
int len = sizeof(struct utmp);
if ((utmpfd = open(UTMP_FILE, O_RDONLY)) == -1) {
perror("can't open UTMP_FILE");
exit(-1);
}
while (read(utmpfd, ¤t_utmp, len) == len) {
show_info(¤t_utmp);
}
close(utmpfd);
return 0;
}
void show_info(struct utmp *utbufp) {
printf("%-8.8s", utbufp->ut_name);
printf(" ");
printf("%-8.8s", utbufp->ut_line);
printf(" ");
printf("%10ld", utbufp->ut_time);
printf(" ");
printf("(%s)", utbufp->ut_host);
printf("\n");
}
这段代码应用了前面学到的内容,在while循环内从文件中逐条地把数据读取出来,存放在记录current_record中,然后调用函数show_info把登录信息显示出来,当文件中已经没有数据时,循环结束,最后关闭文件返回。
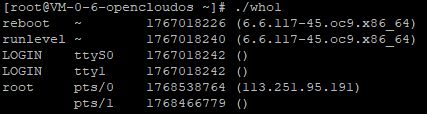
who1.c能正确显示出用户名、终端名、远程主机名,但跟系统的who比起来还不完善,至少在两处需要改进:消除空白记录、正确显示登录时间。
(10)编写who2.c
如刚才的输出中,用户名为LOGIN的那一行对应的是控制台,而不是一个真实的用户。最好有一种方法能够指出某一条记录确实对应着已登录的用户。
utmp结构中有一个成员 ut_type,当它的值为7(USER_PROCESS)时,表示这是一个已经登录的用户。
Unix存储时间的方式 typedef long int time_t,存储时间的结构time_t实际上就是long int。ctime将表示时间的整数值转换成人们日常所使用的时间形式。
/*who2.c*/
#include <utmp.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void show_info(struct utmp *utbufp);
int main(void) {
int utmpfd;
struct utmp current_utmp;
int len = sizeof(struct utmp);
if ((utmpfd = open(UTMP_FILE, O_RDONLY)) == -1) {
perror("can't open UTMP_FILE");
exit(-1);
}
while (read(utmpfd, ¤t_utmp, len) == len) {
show_info(¤t_utmp);
}
close(utmpfd);
return 0;
}
void show_info(struct utmp *utbufp) {
if (utbufp->ut_type != USER_PROCESS)
return;
printf("%-8.8s", utbufp->ut_name);
printf(" ");
printf("%-8.8s", utbufp->ut_line);
printf(" ");
printf("%12.12s", ctime((const time_t *)&(utbufp->ut_time)) + 4);
printf(" ");
printf("(%s)", utbufp->ut_host);
printf("\n");
}
在who命令中介绍了如何读文件,接下来要通过cp命令来学习如何写文件。
(11)编写cp
问题1:cp命令能做些什么:cp能够复制文件,典型的用法是: cp source - file target - file
如果target-file所指定的文件不存在,cp就创建这个文件,如果已经存在就覆盖,target-file的内容与source-file相同。
问题2:cp命令是如何创建/重写文件的?
1.创建/重写文件
创建或重写文件的一种方法是使用系统调用函数creat。
creat的用法如下:creat告诉内核创建一个名为filename的文件,如果这个文件不存在,就创建它,如果已经存在,就把它的内容清空,把文件的长度设为0。
2.写文件
用write系统调用向已打开的文件中写入数据。
write这个系统调用告诉内核将内存中指定的数据写入文件,如果内核不能写入或写入失败,write返回-1,如果写入成功,则返回写入的字节数。
为什么实际写入的字节数会少于所要求的呢?有两个原因,第一个是有的系统对文件的最大尺寸有限制,第二个是磁盘空间接近满了。
在上述两种情况下,内核都会尽量把数据往文件中写,并将实际写入的字节数返回,所以调用write后都必须检查返回值是否与要写入的相同,如果不同,就要采取相应的措施。
问题3:编写cp1.c
文件在磁盘上,源文件在左边,右边的是目标文件,进程在用户空间,缓冲区是进程内存的一部分,进程有两个文件描述符,一个指向源文件,一个指向目标文件,从源文件中读取数据写入缓冲,再将缓冲中的数据写入目标文件。下面就是实现上述逻辑的代码:

图2.4显示了涉及的对象及数据流的走向。
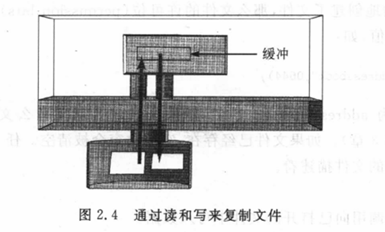
文件在磁盘上,源文件在左边,右边的是目标文件,进程在用户空间,缓冲区是进程内存的一部分,进程有两个文件描述符,一个指向源文件,一个指向目标文件,从源文件中读取数据写入缓冲,再将缓冲中的数据写入目标文件。下面就是实现上述逻辑的代码:
/*cp1.c*/
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#define PAGESIZE 4096
#define COPYMODE 0644
void oops(char *str1, char *str2);
int main(int argc, char *argv[]) {
int sourcefd,destinationfd;
int num;
char buf[PAGESIZE];
if (argc != 3) {
fprintf(stderr, "usage: %s source destination\n", argv[0]);
exit(1);
}
if ((sourcefd = open(argv[1], O_RDONLY)) == -1) {
oops("cannot open ", argv[1]);
}
if ((destinationfd = creat(argv[2], COPYMODE)) == -1) {
oops("cannot open ", argv[2]);
}
while ((num = read(sourcefd, buf, PAGESIZE)) > 0) {
if ((write(destinationfd, buf, num)) != num) {
oops("cannot write to ", argv[2]);
}
}
if (num == -1) {
oops("cannot read from ", argv[1]);
}
if (close(sourcefd) == -1 || close(destinationfd) == -1) {
oops("Error close file", "");
}
return 0;
}
void oops(char *str1, char *str2) {
fprintf(stderr, "Error: %s ",str1);
perror(str2);
exit(1);
}
cp1.c中定义了BUFFERSIZE这个常量,用于标识每次读/写操作的数据长度,这里的值是4096,接下来是个很重要的问题:缓冲区的大小对性能有影响吗?
(12)缓冲区的大小对性能的影响
缓冲区的大小对性能有很大的影响,举例来说,用勺子把汤从一个碗里舀到另一个碗里,用较大的勺子就可以少舀几次,从而节省时间。
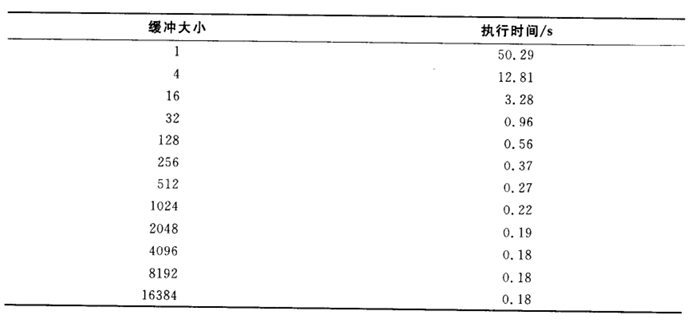
对文件操作而言也是这样的,来看对一个2500字节的文件的copy操作:文件大小=2500字节。如果缓冲区大小=100字节,那么需要25次read()和25次write();如果缓冲区大小=1000字节,那么需要3次read()和3次write()。把缓冲区从100字节增加到1000字节会使系统调用的次数从50次减少到6次,这确实很可观。
缓冲区的大小影响系统调用的次数,系统调用几乎影响程序的执行时间。对应着复制一个5MB大小的文件,不同的缓冲区所对应的执行时间如下:
(13)为什么系统调用需要很多时间?
参见图2.5所示的控制流程。
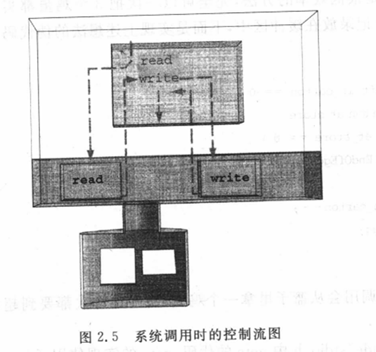
图2.5中,内核把持着对磁盘、终端、打印机等设备的访问。程序cp1.c要读取磁盘上的数据只能通过系统调用read,而read的代码在内核中,所以当read调用发生时,执行权会从用户代码转移到内核代码,执行内核代码是需要时间的。
系统调用的开销大不仅仅是因为要传输数据,当运行内核代码时,CPU工作在管理员(supervisor,又称超级用户)模式,这对应于一些特殊的堆栈和内存环境,必须在系统调用发生时建立好。系统调用结束后(read返回时),CPU要切换到用户模式,必须把堆栈和内存环境恢复成用户程序运行时的状态,这种运行环境的切换要消耗很多时间。在运行时刻,系统会根据需要不断地在两种模式间切换。
举个影片超人的例子,当肯特(生活中的超人)要从用户模式(普通人)切换到管理员模式(超人)时,他得先找个地方,比如电话亭,脱下西装,摘掉眼镜,再改变发型,变成超人后才能去拯救别人,事情完了以后,还得找个地方变回普通人。变来变去是需要时间的,要是肯特整天忙于变来变去,就不会有太多的时间来拯救人类了。
程序也是一样,所以要尽可能地减少模式间的切换。
(14)在who2.c中运用缓冲技术
在who2.c中加入缓冲机制可以提高程序的运行效率。
修改原来的主函数main,通过调用 utmp_next来取得数据,当缓冲区的数据都被取出后,utmp_next会调用read,通过内核再次获得16条记录充满缓冲区。用这种方法可以使read的调用次数减少到原来的1/16。
/*who3.c*/
#include <utmp.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void show_info(struct utmp *utbufp);
int main(void) {
int utmpfd;
struct utmp *utbufp;
if ((utmpfd = utmp_open(UTMP_FILE)) == -1) {
perror("can't open UTMP_FILE");
exit(-1);
}
while ((utbufp = utmp_next()) != (struct utmp *)NULL) {
show_info(utbufp);
}
utmp_close();
return 0;
}
void show_info(struct utmp *utbufp) {
if (utbufp->ut_type != USER_PROCESS)
return;
printf("%-8.8s", utbufp->ut_name);
printf(" ");
printf("%-8.8s", utbufp->ut_line);
printf(" ");
printf("%12.12s", ctime((const time_t *)&(utbufp->ut_time)) + 4);
printf(" ");
printf("(%s)", utbufp->ut_host);
printf("\n");
}
用一个能容纳16个utmp结构的数组作为缓冲区,在图2.6中标识为buffer,就像你次会买很多个鸡蛋一样,buffer可以存放很多数据。编写utmp_next函数来从缓冲区中取得下一个utmp结构的数据。以上算法在utmplib.c中加以实现。
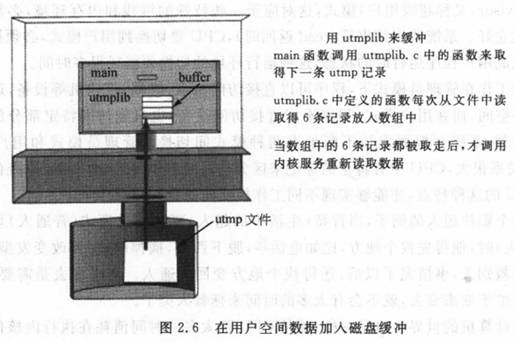
/*utmplib.c*/
#include <utmp.h>
#include <fcntl.h>
#include <unistd.h>
#define UTSIZE 16
#define UTMPSIZE sizeof(struct utmp)
static int utmp_fd = -1;
static int curr_bufp;
static int num_bufp;
static char buf[UTSIZE * UTMPSIZE];
static int utmp_reload(void);
int utmp_open(char *filename) {
utmp_fd = open(filename, O_RDONLY);
num_bufp = 0;
curr_bufp = 0;
return utmp_fd;
}
struct utmp* utmp_next(void) {
struct utmp *recp;
if (utmp_fd == -1)
return NULL;
if (curr_bufp == num_bufp && utmp_reload() == 0)
return NULL;
recp = (struct utmp *)&buf[curr_bufp * UTMPSIZE];
curr_bufp++;
return recp;
}
static int utmp_reload(void) {
int num;
num = read(utmp_fd, buf, UTSIZE * UTMPSIZE);
curr_bufp = 0;
num_bufp = num / UTMPSIZE;
return num_bufp;
}
void utmp_close(void) {
if (utmp_fd != -1)
close(utmp_fd);
}
(15)内核使用缓冲吗?
磁盘的I/O操作消耗的时间更多,为了提高效率,内核也使用缓冲技术来提高对磁盘的访问速度,如图2.7所示。
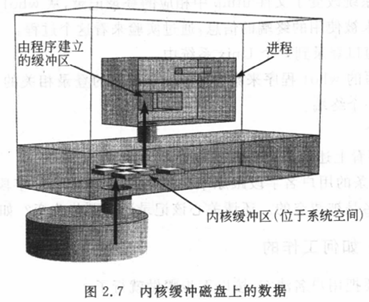
正如utmp文件是用户登录记录的集合,磁盘是数据块的集合,内核会对磁盘上的数据块作缓冲,就像who程序缓冲utmp记录一样。内核将磁盘上的数据块复制到内核缓冲区中,当一个用户空间中的进程要从磁盘上读数据时,内核一般不直接读磁盘,而是将内核缓冲区中的数据复制到进程的缓冲区中。
当进程所要求的数据块不在内核缓冲区时,内核会把相应的数据块加入到请求数据列表中,然后把该进程挂起,接着为其他进程服务。一段时间之后(很短),内核把相应的数据块从磁盘读到内核缓冲区,然后再把数据复制到进程的缓冲区中,最后唤醒被挂起的进程。
理解内核缓冲技术的原理有助于更好地掌握系统调用read和write,read把数据从内核缓冲区复制到进程缓冲区,write把数据从进程缓冲区复制到内核缓冲区,它们并不等价于数据在内核缓冲和磁盘之间的交换。
从理论上讲,内核可以在任何时候写磁盘,但并不是所有的write操作都会导致内核的写动作。内核会把要写的数据暂时存在缓冲区中,积累到一定数量后再一次写入。有时会导致意外情况,比如突然断电,内核还来不及把内核缓冲区中的数据写到磁盘上,这些更新的数据就会丢失。
应用内核缓冲技术导致的结果:提高磁盘I/O效率、优化磁盘的写操作、需要及时地将缓冲数据写入磁盘。
(16)文件读写
who是从文件读数据,cp从一个文件读数据写入到另一个文件中,会不会有对同一个文件既读又写的情况呢?
(17)以注销过程为例
这其实很简单,要把用户名清空,按以下步骤做就行了:1.打开文件utmp;2.从utmp中找到包含你所在终端的登录记录;3.对当前记录做修改;4.关闭文件。
负责注销的程序修改当前记录;再把它写回到文件 utmp中。具体来说,要把 ut_type的值从USER_PROCESS改成 DEAD_PROCESS;把 ut_time字段的值改为注销时间,也就是当前时间。
那如何把修改过的记录写回文件?可以用write吗?不行,write只会更新下一条记录,而不是当前那条要修改的记录。因为系统每次打开一个文件都会保存一个指向文件当前位置的指针,当读写操作完成时,指针会移到下一个记录位置,这个指针与文件描述符相关联。在这种情况下,指针是指向下一条登录记录的头一个字节,这引出了一个重要的问题:在文件操作中,如何改变一个文件的当前读/写位置?答题:使用系统调用lseek。
(18)改变文件的当前位置
Unix每次打开一个文件都会保存一个指针来记录文件的当前位置,如图2.8所示。
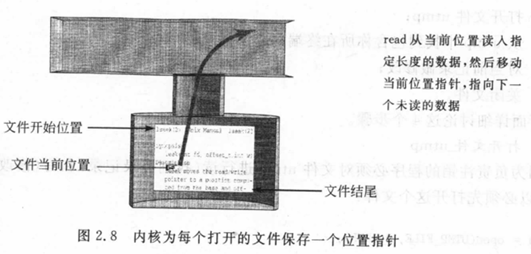
当从文件读数据时,内核从指针所标明的地方开始,读取指定的字节,然后移动位置指针,指向下一个未被读取的字节,写文件的操作也是类似的。
指针是与文件描述符相关联的,而不是与文件关联,所以如果两个程序同时打开一个文件,这时会有两个指针,两个程序对文件的读操作不会互相干扰。
lseek改变文件描述符所关联的指针的位置,新的位置由dist和base来指定,base是基准位置,dist是从基准位置开始的偏移量。基准位置可以是文件的开始(0)、当前位置(1)或文件的结尾(2)。
(19)终端注销的代码
int logout_tty(char *line) {
int fd;
struct utmp rec;
int len = sizeof(struct utmp);
int retval = -1;
if ((fd = open(UTMP_FILE, O_RDWR)) == -1)
return -1;
while (read(fd, &rec, len) == len) {
if (strncmp(rec.ut_line, line, sizeof(rec.ut_line)) == 0) {
rec.ut_type = DEAD_PROCESS;
if (time(&rec.ut_time) != -1) {
if (lseek(fd, -len, SEEK_CUR) != -1) {
if (write(fd, &rec, len) == len) {
retval = 0;
}
}
}
break;
}
}
if (close(fd) == -1)
retval = -1;
return retval;
}
(20)处理系统调用中的错误
如果open无法打开指定的文件,它会返回-1。同样地,当read无法读的时候,它会返回-1,当lseek无法指定指针位置时,它也会返回-1,-1是表示在系统调用中出了些问题,调用者每次都必须检查返回值,一旦检测到错误,必须做出相应的处理。
(21)确定错误的种类:errno
内核通过全局变量errno来指明错误的类型,每个程序都可以访问到这个变量。在error(3)的联机帮助和<errno.h>中包含错误代码和相应的说明,以下是一些例子:
#define EPERM 1 /* Operation not permitted */
#define ENOENT 2 /* No such file or directory */
#define ESRCH 3 /* No such process */
#define EINTR 4 /* Interrupted system call */
#define EIO 5 /* I/O error */
(22)不同的错误需要不同的处理
根据以上列出的错误类型,应该在程序中进行相应的处理:
int sample()
{
int fd;
fd = open("file", O_RDONLY);
if(fd == -1)
{
printf("Cannot open file:");
if ( errno == ENOENT )
printf("There is no such file.");
else if(errno == EINTR)
printf("Interrupted while opening file.");
else if ( errno == EACCES ) // 修复:EACCESS → EACCES
printf("You do not have permission to open file.");
}
return 0; // 补充:int函数必须有返回值
}
(23)显示错误信息:perror(3)
另外一种更简便的方法是用 perror(string)这个函数,它会自己查找错误代码,在标准错误输出中显示出相应的错误信息,参数string是要同时显示出的描述性信息。
应用了perror的sample:
int sample()
{
int fd;
fd = open("file", O_RDONLY);
if (fd == -1)
{
perror("Cannot open file");
return -1;
}
close(fd);
return 0;
}
当有错误发生时,可能会看到如下的信息:
Cannot open file: No such file or directory
Cannot open file: Interrupted system call
显示的第一部分是用户传递进去的描述性信息,第二部分是根据错误代码查到的错误提示。


















 1612
1612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










