




Source
[1] introductory: https://medium.com/@ngiengkianyew/understanding-rotary-positional-encoding-40635a4d078e
[2] rope with good visualization: https://huggingface.co/blog/designing-positional-encoding
[3] with clean math: Rotary Embeddings: A Relative Revolution | EleutherAI Blog
comments usually follow "==>"
Absulute vs. Relative Position Embedding [1]
The Main disadvantage of absolute positional encoding
Does not include relative positional information
- While absolute positional encoding captures the positional information for a word, it does not capture the positional information for the entire sentence (or sequence!)
Example:
- A common way to create absolute positional encoding of length 3 is to do random initialization.
→ Suppose we get the following:[0.1, 0.01, 0.5].
(This absolute positional encoding will ensure that the same words in different positions will have different attention outputs) - However, notice what happens if we were to analyze the absolute position encoding:
[0.1, 0.01, 0.05]: - (1) No relationships between positions.
- Positional encoding at bigger position indices can be more than or less than smaller position indices
→ The positional encoding at position 1 (0.1) can be more than the positional encoding at position 2(0.01), i.e. [0.1 > 0.01]
→ The positional encoding at position 1 (0.1) can also be less than the positional encoding at position 3 (0.5), i.e. [0.1 < 0.5] - (2) Relative distances are inconsistent.
- Differences in positional encoding do not tell us how far apart the words are.
→ The distance from position 1 to position 2 isabs(0.1-0.01) = 0.09.
→ The distance from position 1 to position 3 isabs(0.1-0.05) = 0.05.
(Ideally distance from position 1 to position 3 should be larger than the distance from position 1 to position 2) - This means that absolute positional encoding does not capture the positional information for the entire sentence (or sequence!)
The main disadvantages of Relative Positional Encoding
1. Computationally inefficient:
- Need to create an extra step to self-attention later.
→ Remember that we had to create the pair-wise positional encoding matrix, and then perform quite a bit of tensor manipulation to get the relative positional encodings at each time step.
2. Not suitable for inference
- During inference, researchers like to use a method called KV cache which helps to reduce the inference speed.
- One requirement to use KV cache is for the positional encoding for the words that had already been generated, to not change when new words are generated (which absolute positional encoding provides)
- Relative positional encodings are therefore not suitable for inferencing because the embeddings for each token change for each new time step.
Example:
- When your sequence is of length 2, the relative positions for a word will be [-1, 0, 1].
- When your input sequence is of length 3, the relative positions for a word will be [-2,-1,0,1,2].
- Since we are using these relative positions to get the relative positional encodings for each word, when the set of relative positions changes, your positional encodings for each word change.
- This means that given the sentence
[‘this’, ‘is’, ‘awesome’], your positional encoding of the word‘this’changes at each time step as you generate tokens for inference. - This is why relative positional encoding is not commonly used.
RoPE
==> key takewaway: RoPE provides absolution embedding perturbation by assigning an arbitrary value to each position from 0~max_position_encoding-1 while includes relative position by ensuring:
1. difference in perturbation of 2 positions is determined by their distance,
2. the dot product of 2 word vectors are generally smaller if further apart.
==> proposal: for each position m, rotate q/k along Dim. pairwise
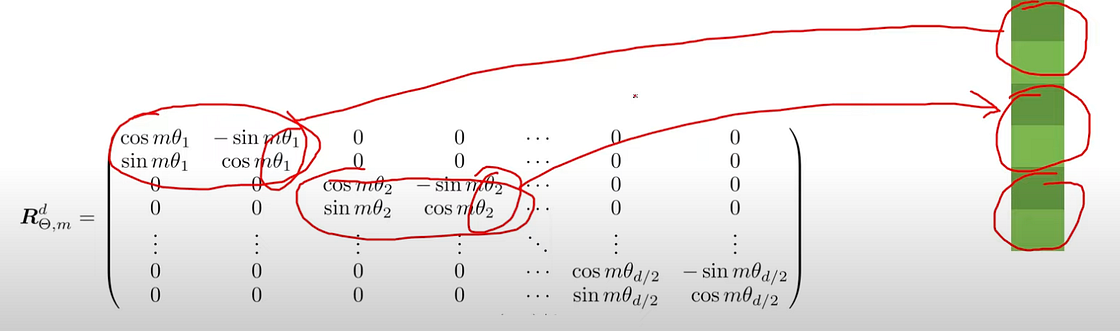
https://www.youtube.com/watch?v=o29P0Kpobz0&ab_channel=EfficientNLP
in practice

Rotary Positional Embeddings (RoPE)
a better formulation is:[3]

Sinusoidal Position Encoding[2]
RoPE is clearly inspired by the original encoding scheme from Attention is All You Need, and we shall see indeed the method is absolute rotary in nature.
We've now arrived at Sinusoidal embeddings; originally defined in the Attention is all you need paper. Let's look at the equations:
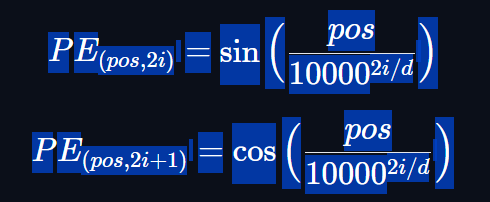
where pospos is the tokens position index, i is the component index in the positional encoding vector, and dd is the model dimension. 10,000 is the base wavelength (henceforth referred to as θ), which we stretch or compress as a function of the component index.
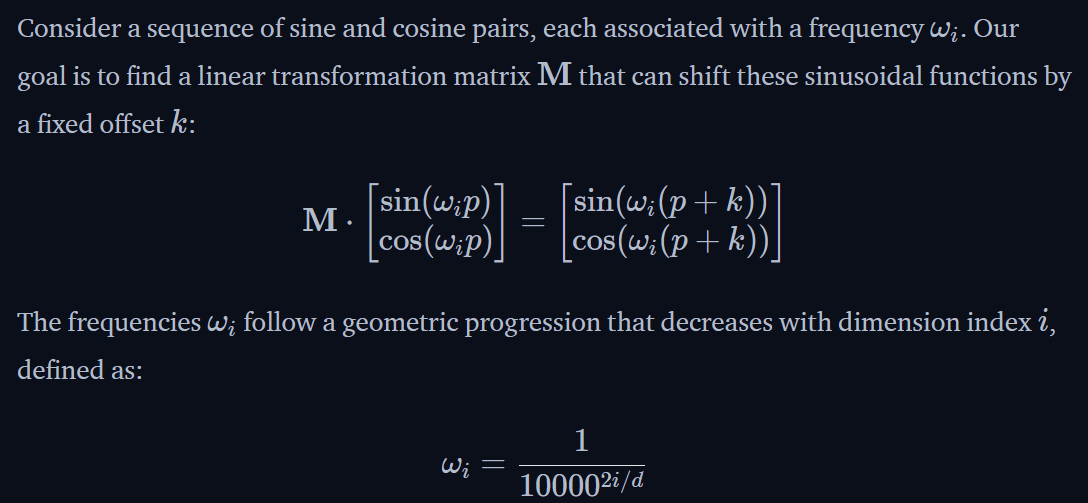
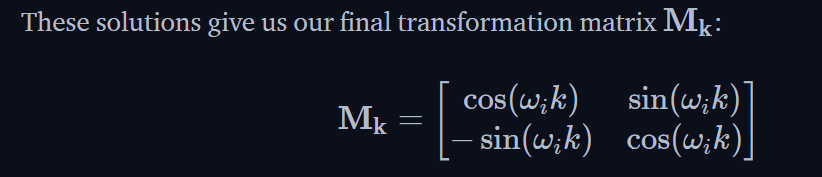
the key difference is sinusoidal encoding alternates between sin and cos, while RoPE explicitly uses rotary sin + cos for neighboring dims.
Positional encoding in context[2]
From this point on, it's key to consider positional encoding in the context of self attention. To reiterate, the self-attention mechanism enables the model to weigh the importance of different elements in an input sequence and dynamically adjust their influence on the output.
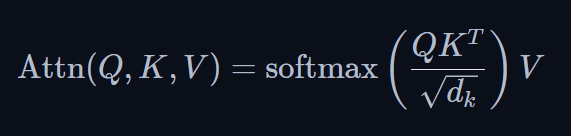
In all our previous iterations, we've generated a separate positional encoding vector and added it to our token embedding prior to our Q, K and V projections ==> in practice, it's usually just Q/K projections. By adding the positional information directly to our token embedding, we are polluting the semantic information with the positional information. We should be attempting to encode the information without modifying the norm. Shifting to multiplicative is the key.
Using the dictionary analogy, when looking up a word (query) in our dictionary (keys), nearby words should have more influence than distant ones. The influence of one token upon another is determined by the QK^T dot product - so that's exactly where we should focus our positional encoding!
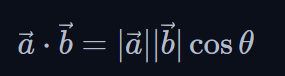
The geometric interpretation of the dot product shown above gives us a magnificent insight. We can modulate the result of our dot product of two vectors purely by increasing or decreasing the angle between them. Furthermore, by rotating the vector, we have absolutely zero impact on the norm of the vector, which encodes the semantic information of our token.
So now we know where to focus our attention, and have seen from another angle why a rotation might be a sensible "channel" in which to encode our positional information, ...
Much like in Sinusoidal Encoding, we decompose our vectors q or k, instead of pre-projection x) into 2D pairs/chunks. Rather than encoding absolute position directly by adding a vector we drew from sinusoidal functions of slowly decreasing frequencies, we cut to the chase and encode relative position by multiplying each pair with the rotation matrix.
The future of positional encoding[2]
Is RoPE the final incarnation of positional encoding? This recent paper from DeepMind deeply analyses RoPE and highlights some fundamental problems. TLDR: RoPE isn't a perfect solution, and the models mostly focus on the lower frequencies, but the paper shows that removing (not rotating) the lowest frequencies improves performance on Gemma 2B!
I anticipate some future breakthroughs, perhaps taking inspiration from signal processing with ideas like wavelets or hierarchical implementations. As models are increasingly quantized for deployment, I'd also expect to see some innovation in encoding schemes that remain robust under low-precision arithmetic.


















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










