
一、zlog介绍
zlog是一个高可靠性、高性能、线程安全、灵活、概念清晰的纯C日志函数库。
在C的世界里面没有特别好的日志函数库(就像JAVA里面的的log4j,或者C++的log4cxx)。C程序员都喜欢用自己的轮子。printf就是个挺好的轮子,但没办法通过配置改变日志的格式或者输出文件。syslog是个系统级别的轮子,不过速度慢,而且功能比较单调。
zlog在效率、功能、安全性上大大超过了log4c,并且是用c写成的,具有比较好的通用性。
zlog有这些特性:
- syslog分类模型,比log4j模型更加直接了当
- 日志格式定制,类似于log4j的pattern layout
- 多种输出,包括动态文件、静态文件、stdout、stderr、syslog、用户自定义输出函数
- 运行时手动、自动刷新配置文件(同时保证安全)
- 高性能,在我的笔记本上达到25万条日志每秒, 大概是syslog(3)配合rsyslogd的1000倍速度
- 用户自定义等级
- 多线程和多进程环境下保证安全转档
- 精确到微秒
- 简单调用包装dzlog(一个程序默认只用一个分类)
- MDC,线程键-值对的表,可以扩展用户自定义的字段
- 自诊断,可以在运行时输出zlog自己的日志和配置状态
- 不依赖其他库,只要是个POSIX系统就成(当然还要一个C99兼容的vsnprintf)
zlog1.2发布说明:
1.zlog 1.2 新增了这些功能
a.对管道的支持,从此zlog可以外接cronolog这样的日志过滤程序来输出
b.全面的日志转档支持,
c.其他兼容性的代码改动
2.zlog 1.2 在库方面是和zlog 1.0/1.1二进制兼容的,区别在于:
a.所有的宏改为小写,ZLOG_INFO->zlog_info,方便开发者手工输入,这是一个巨大的改变。如果zlog1.1/1.0的用户要用zlog 1.2的话,需要写一个脚本,把源代码中的大写批量替换为小写,然后重新编译你的程序。我提供了一个脚本:
sed -i -e 's/\b\wZLOG\w\b/\L&\E/g’ aa.c
s/:search and replace(查找并替换)
\b:边界匹配,保证只替换整个单词,不是单词内部的部分
\w*:匹配零个或多个字母、数字、下划线,即匹配前面可能存在的任何字符;ZLOG:查找字符串
\wZLOG\w:ZLOG前面或后面可以存在0个或多个字母、数字、下划线
\L:将匹配到的字符串全部转为小写字母
\E:结束正则表达式,结束转义状态
b.取消了auto tools的使用,也就是说,不论你在任何平台,都需要gcc和gnu make才能编译安装zlog。主流的操作系统(Aix, OpenSolaris…)都能安装gcc和gnu make。当然也可以自行修改makefile来完成编译,对于平台稍有经验的Geek都可以自行完成!
二、Syslog模型
zlog有3个重要的概念:分类(Category)、规则(Rule)和格式(Format)。
分类(Category)用于区分不同的输入。代码中的分类变量的名字是一个字符串,在一个程序里面可以通过获取不同的分类名用来后面输出不同分类的日志,用于不同的目的。
格式(Format)是用来描述输出日志的格式,比如是否有带有时间戳,是否包含文件位置信息等,格式simple就是简单的用户输入的信息+换行符。
规则(Rule)则是把分类、级别(日志等级)、输出文件、格式组合起来,决定一条代码中的日志是否输出,输出到哪里,以什么格式输出。
所以,当程序执行下面的语句的时候
zlog_category_t c;
c = zlog_get_category(“my_cat”);
zlog_info(c, “hello, zlog”);
zlog会找到c的名字是"my_cat",对应的配置文件中的规则是
[rules]
my_cat.DEBUG >stdout; simple
然后库会检查,目前这条日志的级别是否符合规则中的级别来决定是否输出。因为INFO>=DEBUG,所以这条日志会被输出。并且根据这条规则,会被输出到stdout(标准输出) ,输出的格式是simple,在配置文件中定义是
[formats]
simple = “%m%n”
最后在屏幕上打印
hello, zlog
这就是整个过程。用户要做就是写自己的信息。日志往哪里输出,以什么格式输出,都是库和配置文件来完成的。
扩展syslog模型:在syslog里面,设施(facility)是个int型,而且必须从系统定义的那几种里面选择;zlog走的远一点,用一个字符串来标识分类。syslog有一个通配符"“,匹配所有的设施(facility);zlog里面也一样,”*"匹配所有分类。这提供了一个很方便的办法来重定向你的系统中各个组件的错误。只要这么写:
[rules]
*.error "/var/log/error.log"
zlog强大而独有的特性是上下级分类匹配。如果你的分类是这样的:
c = zlog_get_category("my_cat");
然后配置文件是这样的
[rules]
my_cat.* "/var/log/my_cat.log"
my_.NOTICE "/var/log/my.log"
这两条规则都匹配c分类"my_cat"。通配符"" 表示上级分类。 "my"是"my_cat"和"my_dog"的上级分类。
三、配置文件
大部分的zlog的行为取决于配置文件:把日志打到哪里去,用什么格式,怎么转档,配置文件例子:
# comments
[global]
strict init = true
buffer min = 1024
buffer max = 2MB
rotate lock file = /tmp/zlog.lock
default format = "%d.%us %-6V (%c:%F:%L) - %m%n"
file perms = 600
[levels]
TRACE = 10
CRIT = 130, LOG_CRIT
[formats]
simple = "%m%n"
normal = "%d %m%n"
[rules]
default.* >stdout; simple
*.* "%12.2E(HOME)/log/%c.log", 1MB*12; simple
my_.INFO >stderr;
my_cat.!ERROR "/var/log/aa.log"
my_dog.=DEBUG >syslog, LOG_LOCAL0; simple
my_mice.* $user_define;
1、全局参数 全局参数以[global]开头。[]代表一个节的开始,四个小节的顺序不能变,依次为global-levels-formats-rules。这一节可以忽略不写。语法为 (key) = (value)
- strict init 如果"strict init"是true,zlog_init()将会严格检查所有的格式和规则,任何错误都会导致zlog_init() 失败并且返回-1。当"strict init"是false的时候,zlog_init()会忽略错误的格式和规则。 这个参数默认为true。
- reload conf period 这个选项让zlog能在一段时间间隔后自动重载配置文件。重载的间隔以每进程写日志的次数来定义,当写日志次数到了一定值后,内部将会调用zlog_reload()进行重载,每次zlog_reload()或者zlog_init()之后重新计数累加。因为zlog_reload()是原子性的,重载失败继续用当前的配置信息,所以自动重载是安全的。默认值是0,自动重载是关闭的。
- buffer min
- buffer max zlog在堆上为每个线程申请缓存,“buffer min"是单个缓存的最小值,zlog_init()的时候申请这个长度的内存。写日志的时候,如果单条日志长度大于缓存,缓存会自动扩充,直到到"buffer max”, 单条日志再长超过"buffer max"就会被截断。如果 “buffer max” 是 0,意味着不限制缓存,每次扩充为原先的2倍,直到这个进程用完所有内存为止。缓存大小可以加上 KB, MB 或 GB这些单位。默认来说"buffer min"是 1K , “buffer max” 是2MB。
- rotate lock file 这个选项指定了一个锁文件,用来保证多进程情况下日志安全转档。zlog会在zlog_init()时候以读写权限打开这个文件确认你执行程序的用户有权限创建和读写这个文件。转档日志的伪代码是: write(log_file, a_log) if (log_file > 1M) if (pthread_mutex_lock succ && fcntl_lock(lock_file) succ) if (log_file > 1M) rotate(log_file); fcntl_unlock(lock_file); pthread_mutex_unlock; mutex_lock用于多线程, fcntl_lock用于多进程。fcntl_lock是POSIX建议锁。详见man 3 fcntl。这个锁是全系统有效的。在某个进程意外死亡后,操作系统会释放此进程持有的锁。这就是我为什么用fcntl锁来保证安全转档。进程需要对锁文件有读写权限。 默认来说,rotate lock file = self。在这种情况下,zlog不会创建任何锁文件,用配置文件作为锁文件。fcntl是建议锁,所以用户可以自由的修改存储他们的配置文件。一般来说,单个日志文件不会被不同操作系统用户的进程转档,所以用配置文件作为锁文件是安全的。 如果你设置其他路径作为锁文件,例如/tmp/zlog.lock,zlog会在zlog_init()的时候创建这个文件。如果有多个操作系统用户的进程需要转档同一个日志文件,确认这个锁文件对于多个用户都可读写。默认值是/tmp/zlog.lock。
- default format 这个参数是缺省的日志格式,默认值为: “%d %V [%p:%F:%L] %m%n” 这种格式产生的输出类似这样: 2012-02-14 17:03:12 INFO [3758:test_hello.c:39] hello, zlog
- file perms 这个指定了创建日志文件的缺省访问权限。必须注意的是最后的产生的日志文件的权限为"file perms"& ~umask。默认为600,只允许当前用户读写。
- fsync period 在每条规则写了一定次数的日志到文件后,zlog会调用fsync(3)来让操作系统马上把数据写到硬盘。次数是每条规则单独统计的,并且在zlog_reload()后会被清0。必须指出的是,在日志文件名是动态生成或者被转档的情况下,zlog不能保证把所有文件都搞定,zlog只fsync()那个时候刚刚write()的文件描述符。这提供了写日志速度和数据安全性之间的平衡。例子: $ time ./test_press_zlog 1 10 100000 real 0m1.806s user 0m3.060s sys 0m0.270s $ wc -l press.log 1000000 press.log $ time ./test_press_zlog 1 10 100000 #fsync period = 1K real 0m41.995s user 0m7.920s sys 0m0.990s $ time ./test_press_zlog 1 10 100000
#fsync period = 10K real 0m6.856s user 0m4.360s sys 0m0.550s 如果你极度在乎安全而不是速度的话,用同步IO文件。默认值是0,由操作系统来决定什么时候刷缓存到文件。
2、日志等级自定义
这一节以[levels]开始。用于定义用户自己的日志等级,建议和用户自定义的日志记录宏一起使用。语法为:
(level string) = (level int), (syslog level, optional)
(level int)必须在[1,253]这个范围内,越大越重要。(syslog level)是可选的,如果不设默认为LOG_DEBUG。
内置的默认等级是(这些不需要写在配置文件里面)
DEBUG = 20, LOG_DEBUG
INFO = 40, LOG_INFO
NOTICE = 60, LOG_NOTICE
WARN = 80, LOG_WARNING
ERROR = 100, LOG_ERR
FATAL = 120, LOG_ALERT
UNKNOWN = 254, LOG_ERR
3、格式
这一节以[formats]开始。用来定义日志的格式。语法为:
(name) = “(actual formats)”
很好理解,(name)被后面的规则使用。(name)必须由数字和字母组成,下划线"_"也算字母。(actual format)前后需要有双引号。 (actual formats)可以由转换字符组成,见下一节。
4、转换格式串
转换格式串的设计是从C的printf函数里面抄来的,一个转换格式串由文本字符和转换说明组成。
转换格式串用在规则的日志文件路径和输出格式(format)中,你可以把任意的文本字符放到转换格式串里面。
每个转换说明都是以百分号(%)打头的,后面跟可选的宽度修饰符,最后以转换字符结尾。转换字符决定了输出什么数据,例如分类名、级别、时间日期、进程号等等。宽度修饰符控制了这个字段的最大最小宽度、左右对齐。下面是简单的例子。
如果转换格式串是:
“%d(%m-%d %T) %-5V [%p:%F:%L] %m%n”.
源代码中的写日志语句是:
zlog_info(c, “hello, zlog”);
将会输出:
02-14 17:17:42 INFO [4935:test_hello.c:39] hello, zlog
可以注意到,在文本字符和转换说明之间没有显式的分隔符。zlog解析的时候知道哪里是转换说明的开头和结尾。在这个例子里面%-5p这个转换说明决定了日志级别要被左对齐,占5个字符宽。
4.1、转换字符

4.2、宽度修饰符
一般来说数据按原样输出。不过,有了宽度修饰符,就能够控制最小字段宽度、最大字段宽度和左右对齐。当然这要付出一定的性能代价。
4.3、时间字符
这里是转换字符d支持的时间字符,所有字符都是由strftime(2)生成的,在我的linux操作系统上支持的是:
5、规则(Rules)
描述了日志是怎么被过滤、格式化以及被输出的。语法是:
(category).(level) (output),(options,optional); (format name,optional)
当zlog_init()被调用的时候,所有规则都会被读到内存中。当zlog_get_category()被调用,规则就被分配给分类(链接为zlog标准手册)(5.5.2)。在实际写日志的时候,例如zlog_info()被调用的时候,就会比较这个INFO和各条规则的等级,来决定这条日志会不会通过这条规则输出。当zlog_reload()被调用的时候,配置文件会被重新读入,包括所有的规则,并且重新计算分类对应的规则。
5.1、级别匹配
zlog有6个默认的级别:“DEBUG”, “INFO”, “NOTICE”, “WARN”, “ERROR"和"FATAL”。就像其他的日志函数库那样,aa.DEBUG意味着任何大于等于DEBUG级别的日志会被输出。当然还有其他的表达式。配置文件中的级别是大小写不敏感的。
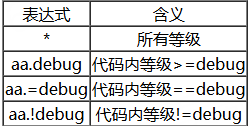
5.2、分类匹配
分类必须由数字和字母组成,下划线"_"也算字母。

5.3、输出动作
目前zlog支持若干种输出,语法是:[输出], [附加选项, 可选]; [format(格式)名, 可选]
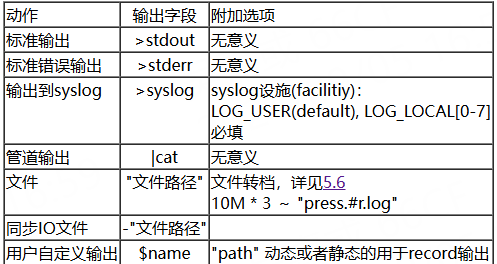
1、stdout, stderr, syslog
2、管道输出
3、文件
1.文件路径
可以是相对路径或者绝对路径,被双引号"包含,转换格式串可以用在文件路径上。例如文件路径是 “%E(HOME)/log/out.log”,环境变量
$HOME 是/home/harry,那最后的输出文件是/home/harry/log/output.log。
zlog的文件功能极为强大,例如 a、输出到命名管道(FIFO),必须在调用前由mkfifo(1)创建
. “/tmp/pipefile” b、输出到NULL,也就是不输出
. “/dev/null” c、在任何情况下输出到终端
. “/dev/tty” d、每线程一个日志,在程序运行的目录下
. “%T.log” e、输出到有进程号区分的日志,每天,在$HOME/log目录,每1GB转档一次,保持5个日志文件。
. “%E(HOME)/log/aa.%p.%d(%F).log”,1GB * 5 f、aa_及下级分类,每个分类一个日志 aa_.* “/var/log/%c.log”
2.文件转档
控制文件的大小和个数。zlog根据这个字段来转档,当日志文件太大的时候。例如
“%E(HOME)/log/out.log”, 1M * 3 ~ “%E(HOME)/log/out.log.#r”
这三个参数都不是必填项
3.同步IO文件
在文件路径前加上一个"-"就打开了同步IO选项。在打开文件(open)的时候,会以O_SYNC选项打开,这时候每次写日志操作都会等操作系统把数据写到硬盘后才返回,这个选项极为耗时:
$ time ./test_press_zlog 100 1000
real 0m0.732s
user 0m1.030s
sys 0m1.080s
$ time ./test_press_zlog 100 1000 # synchronous I/O open
real 0m20.646s
user 0m2.570s
sys 0m6.950s
4.格式名
是可选的,如果不写,用全局配置里面的默认格式:
[global]
default format = “%d(%F %T) %V [%p:%F:%L] %m%n”
6、文件转档
日志文件过大,可能导致系统硬盘被撑爆,或者单个日志文件过大而即使用grep也要花费很多时间来寻找匹配的日志。对于日志转档,有如下几种范式:
1.按固定时间段来切分日志
在zlog里面,这种需求不需要用日志转档功能来完成,简单的在日志文件名里面设置时间日期字符串就能解决问题:
. “aa.%d(%F).log”
或者用cronolog来完成,速度会更快一点
. | cronolog aa.%F.log
2.按照日志大小切分
这种日志的切分可以在事后用split等工具来完成,但对于开发而言会增加步骤,所以最好也是由日志库来完成。日志库存档有两种模式Sequence和Rolling。Sequence情况下:
aa.log (new)
aa.log.2 (less new)
aa.log.1
aa.log.0 (old)
Rolling情况下:
aa.log (new)
aa.log.0 (less new)
aa.log.1
aa.log.2 (old)
最简单的zlog的转档配置为
. “aa.log”, 10MB
这个配置是Rolling的情况,每次aa.log超过10MB的时候,会做这样的重命名
aa.log.2 -> aa.log.3
aa.log.1 -> aa.log.2
aa.log.0 -> aa.log.1
aa.log -> aa.log.0
上面的配置可以写的更加罗嗦一点
. “aa.log”, 10MB * 0 ~ “aa.log.#r”
逗号后第一个参数表示文件达到多大后开始进行转档,第二个参数表示保留多少个存档文件(0代表不删除任何存档文件),第三个参数表示转档的文件名,其中#r表示存档文件的序号,r是rolling的缩写,还可以放#s,是sequence的缩写,转档文件名必须包含#r或者#s。
3.按照日志大小切分,但同时加上时间标签
aa.log
aa.log-20070305.00.log
aa.log-20070501.00.log
aa.log-20070501.01.log
aa.log-20071008.00.log
这种情况适合于程序本身的日志一般不是很受关注,但是又在某一天想要找出来看的情况。当然,在这种情况下,万一在20070501这一天日志的量超过了指定值,例如100MB,就又要退回到第二种状态,在文件名中加后缀。
zlog对应的配置是:
. “aa.log”, 100MB ~ “aa-%d(%Y%m%d).#2s.log”
每到100MB的时候转档,转档文件名也支持转换字符,可以把转档当时的时间串作为转档文件名的一部分。#2s的意思是序号的长度最少为2位,从00开始编号,Sequence转档。这是zlog对转档最复杂的支持了!
4.压缩、移动、删除旧的日志
首先,压缩不应该由日志库来完成,因为压缩消耗时间和CPU,日志库的任务是配合压缩。
对于第一种和第三种,管理较为简单,只要符合某些文件名规则或修改日期的,可以用shell脚本+crontab轻易的压缩、移动和删除。
对于第二种,其实不是非常需要压缩,只需要删除就可以了。
如果一定需要转档的同时进行压缩,只有logrotate能干这活儿,毕竟他是独立的程序,能在转档同时搞压缩,不会有混淆的问题。
5.zlog对外部转档工具,例如logrotate的支持
zlog的转档功能已经极为强大,当然也有几种情况是zlog无法处理的,例如按时间条件进行转档,转档前后调用一些自制的shell脚本……这会把zlog的配置和表达弄得过于复杂而缺乏美感。
这时候你也许喜欢用一些外部转档工具,例如logrotate来完成工作。问题是,在linux操作系统下,转档工具重命名日志文件名后,应用进程还是往原来的文件描述符写日志,没办法重新打开日志文件写新的日志。标准的做法是给应用程序一个信号,让他重新打开日志文件,对于syslogd是
kill -SIGHUP ‘cat /var/run/syslogd.pid‘
对于zlog,因为是个函数库,不适合接受信号。zlog提供了函数接口zlog_reload(),这个函数会重载配置文件,重新打开所有的日志文件。应用程序在logrotate的信号,或者其他途径,例如客户端的命令后,可以调用这个函数,来重新打开所有的日志文件。
7、配置文件工具(怎么使用?目前使用官方编译好的可以使用,自己怎么生成?)
$ zlog-chk-conf -h
Useage: zlog-chk-conf [conf files]…
-q, suppress non-error message
-h, show help message
zlog-chk-conf 尝试读取配置文件,检查语法,然后往屏幕上输出这些配置文件是否正确。我建议每次创建或者改动一个配置文件之后都用一下这个工具。输出可能是这样:
$ ./zlog-chk-conf zlog.conf
03-08 15:35:44 ERROR (10595:rule.c:391) sscanf [aaa] fail, category or level is null
03-08 15:35:44 ERROR (10595:conf.c:155) zlog_rule_new fail [aaa]
03-08 15:35:44 ERROR (10595:conf.c:258) parse configure file[zlog.conf] line[126] fail
03-08 15:35:44 ERROR (10595:conf.c:306) zlog_conf_read_config fail
03-08 15:35:44 ERROR (10595:conf.c:366) zlog_conf_build fail
03-08 15:35:44 ERROR (10595:zlog.c:66) conf_file[zlog.conf], init conf fail
03-08 15:35:44 ERROR (10595:zlog.c:131) zlog_init_inner[zlog.conf] fail
—[zlog.conf] syntax error, see error message above
这个告诉你配置文件zlog.conf的126行,是错的。第一行进一步告诉你[aaa]不是一条正确的规则。
zlog-chk-conf可以同时分析多个配置文件,举例:
$ zlog-chk-conf zlog.conf ylog.conf
–[zlog.conf] syntax right
–[ylog.conf] syntax right
四、zlog接口(API)
zlog的所有函数都是线程安全的,使用的时候只需要
#include “zlog.h”
1、初始化和清理
int zlog_init(const char *confpath);
int zlog_reload(const char *confpath);
void zlog_fini(void);
zlog_init()从配置文件confpath中读取配置信息到内存。如果confpath为NULL,会寻找环境变量ZLOG_CONF_PATH的值作为配置文件名,如果环境变量ZLOG_CONF_PATH也没有,所有日志以内置格式写到标准输出上。每个进程只有第一次调用zlog_init()是有效的,后面的多余调用都会失败并不做任何事情。
zlog_reload()从confpath重载配置,并根据这个配置文件来重新计算内部的分类规则匹配、重建每个线程的缓存、并设置原有的用户自定义输出函数,可以在配置文件发生改变后调用这个函数,这个函数使用次数不限。如果confpath为NULL,会重载上一次zlog_init()或者zlog_reload()使用的配置文件。如果zlog_reload()失败,上一次的配置依然有效,所以zlog_reload()具有原子性。
zlog_fini()释放所有zlog API申请的内存,关闭它们打开的文件,使用次数不限。
返回值
如果成功,zlog_init()和zlog_reload()返回0;失败的话,zlog_init()和zlog_reload()返回-1。详细错误会被写在由环境变量ZLOG_PROFILE_ERROR指定的错误日志里面。
2、分类操作(category)
typedef struct zlog_category_s zlog_category_t;
zlog_category_t *zlog_get_category(const char cname);
描述:
zlog_get_category()从zlog的全局分类表里面找到分类,用于以后输出日志。如果没有的话,就建一个。然后它会遍历所有的规则,寻找和cname匹配的规则并绑定。配置文件规则中的分类名匹配cname的规律描述如下:
1、 匹配任意cname。
2、以下划线_结尾的分类名同时匹配本级分类和下级分类。例如aa_匹配aa, aa_, aa_bb, aa_bb_cc这几个cname。
3、不以下划线_结尾的分类名精确匹配cname。例如aa_bb匹配aa_bb这个cname。
4、! 匹配目前还没有规则的cname。每个zlog_category_t *对应的规则,在zlog_reload()的时候会被自动重新计算,不用担心内存释放,zlog_fini() 最后会清理一切。
返回值:
成功,返回zlog_category_t的指针,如果失败,返回NULL。详细错误会被写在由环境变量ZLOG_PROFILE_ERROR指定的错误日志里面。
3、写日志函数及宏
void zlog(zlog_category_t * category, const char *file, size_t filelen, const char *func, size_t funclen,long line, int level, const char *format, …);
void vzlog(zlog_category_t * category,const char *file, size_t filelen, const char *func, size_t funclen, long line, int level,const char *format, va_list args);
void hzlog(zlog_category_t * category,const char *file, size_t filelen, const char *func, size_t funclen,
long line, int level,const void buf, size_t buflen);
level是一个整数,应该是在下面几个里面取值。
typedef enum {ZLOG_LEVEL_DEBUG = 20,
ZLOG_LEVEL_INFO = 40,
ZLOG_LEVEL_NOTICE = 60,
ZLOG_LEVEL_WARN = 80,
ZLOG_LEVEL_ERROR = 100,
ZLOG_LEVEL_FATAL = 120
} zlog_level;
每个函数都有对应的宏,简单使用。例如:#define zlog_fatal(cat, format, args…) \
zlog(cat, FILE, sizeof(FILE)-1,
func, sizeof(func)-1, LINE, \
ZLOG_LEVEL_FATAL, format, ##args)
所有的宏列表:
/ zlog macros /
zlog_fatal(cat, format, …)
zlog_error(cat, format, …)
zlog_warn(cat, format, …)
zlog_notice(cat, format, …)
zlog_info(cat, format, …)
zlog_debug(cat, format, …)
/ vzlog macros /
vzlog_fatal(cat, format, args)
vzlog_error(cat, format, args)
vzlog_warn(cat, format, args)
vzlog_notice(cat, format, args)
vzlog_info(cat, format, args)
vzlog_debug(cat, format, args)
/ hzlog macros */
hzlog_fatal(cat, buf, buf_len)
hzlog_error(cat, buf, buf_len)
hzlog_warn(cat, buf, buf_len)
hzlog_notice(cat, buf, buf_len)
hzlog_info(cat, buf, buf_len)
hzlog_debug(cat, buf, buf_len)
返回值
这些函数不返回。如果有错误发生,详细错误会被写在由环境变量ZLOG_PROFILE_ERROR指定的错误日志里面。
4、dzlog接口
int dzlog_init(const char *confpath, const char *cname);
int dzlog_set_category(const char *cname);
void dzlog(const char *file, size_t filelen,
const char *func, size_t funclen,
long line, int level,
const char *format, …);
void vdzlog(const char *file, size_t filelen,
const char *func, size_t funclen,
long line, int level,
const char *format, va_list args);
void hdzlog(const char *file, size_t filelen,
const char *func, size_t funclen,
long line, int level,
const void *buf, size_t buflen);
dzlog是忽略分类(zlog_category_t)的一组简单zlog接口。它采用内置的一个默认分类,这个分类置于锁的保护下。这些接口也是线程安全的。忽略了分类,意味着用户不需要操心创建、存储、传输zlog_category_t类型的变量。当然也可以在用dzlog接口的同时用一般的zlog接口函数,这样会更爽。
dzlog_init()和zlog_init()一样做初始化,就是多需要一个默认分类名cname的参数。zlog_reload()、 zlog_fini() 可以和以前一样使用,用来刷新配置,或者清理。
dzlog_set_category()是用来改变默认分类用的,上一个分类会被替换成新的。同样不用担心内存释放的问题,zlog_fini()最后会清理。
dzlog的宏也定义在zlog.h里面。更简单的写法。
dzlog_fatal(format, …)
dzlog_error(format, …)
dzlog_warn(format, …)
dzlog_notice(format, …)
dzlog_info(format, …)
dezlog_debug(format, …)
vdzlog_fatal(format, args)
vdzlog_error(format, args)
vdzlog_warn(format, args)
vdzlog_notice(format, args)
vdzlog_info(format, args)
vdzlog_debug(format, args)
hdzlog_fatal(buf, buf_len)
hdzlog_error(buf, buf_len)
hdzlog_warn(buf, buf_len)
hdzlog_noticebuf, buf_len)
hdzlog_info(buf, buf_len)
hdzlog_debug(buf, buf_len)
返回值
成功情况下dzlog_init()和dzlog_set_category()返回0。失败情况下dzlog_init()和 dzlog_set_category()返回-1。详细错误会被写在由环境变量ZLOG_PROFILE_ERROR指定的错误日志里面。
5、用户自定义输出
总览:
typedef struct zlog_msg_s {
char *buf;
size_t len;
char *path;
} zlog_msg_t;
typedef int (*zlog_record_fn)(zlog_msg_t msg);
int zlog_set_record(const char rname, zlog_record_fn record);
描述:
zlog允许用户自定义输出函数,输出函数需要绑定到某条特殊的规则上。这种规则的例子是:. name,"recordpathzlogsetrecord()做绑定动作。规则中输出段有name, "record path %c %d"; simple
zlog_set_record()做绑定动作。规则中输出段有name,"recordpathzlogsetrecord()做绑定动作。规则中输出段有name的,会被用来做用户自定义输出,输出函数为record,这个函数需要为zlog_record_fn的格式。
zlog_msg_t结构的各个成员描述如下:
path来自规则的逗号后的字符串,这个字符串会被动态的解析,输出当前的path,就像动态文件路径一样。
buf和len 是zlog格式化后的日志信息和长度。所有zlog_set_record()做的绑定在zlog_reload()使用后继续有效。
返回值:
成功情况下zlog_set_record()返回0。失败情况下zlog_set_record()返回-1。详细错误会被写在由环境变量ZLOG_PROFILE_ERROR指定的错误日志里面。
6、调试和诊断
总览:
void zlog_profile(void);
描述:
环境变量ZLOG_PROFILE_ERROR指定zlog本身的错误日志。
环境变量ZLOG_PROFILE_DEBUG指定zlog本身的调试日志。
zlog_profile()打印所有内存中的配置信息到ZLOG_PROFILE_ERROR,在运行时,可以把这个和配置文件比较,看看有没有问题。













 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










