



从多模态模型到推荐漏斗,揭秘推荐算法的底层逻辑
前言
打开抖音,连续滑动几次屏幕后,我们往往会发现一个有趣的现象:
喜欢篮球的人,首页几乎都是 NBA 集锦;
喜欢科技的人,总能刷到最新的数码评测;
喜欢游戏的人,推荐列表里充满了各种游戏实况与攻略视频。
仿佛抖音比我们自己更了解自己。
很多人都听过这样一句话:
当你在刷抖音的时候,抖音也在不断学习你的兴趣。
这句话虽然带有调侃意味,但从技术角度来看却并非毫无道理。
因为当用户不断浏览、点赞、评论和分享视频时,推荐系统也在不断收集数据、分析行为、更新用户画像,并重新计算下一批应该推荐给用户的内容。
而这一切的背后,离不开 用户画像、多模态模型、向量计算、双塔模型 以及复杂的 推荐排序系统。
本文将从推荐系统的整体工作流程出发,深入理解抖音推荐算法背后的核心思想。
一、当你在刷抖音时,抖音在干什么?
对于用户来说,刷抖音只是一个简单的动作:
打开APP
↓
观看视频
↓
滑动切换
↓
继续观看
但对于推荐系统而言,这个过程实际上是在持续收集用户兴趣数据。
例如:
- 观看了什么视频
- 停留了多久
- 是否点赞
- 是否评论
- 是否分享
- 是否关注作者
这些行为都会被系统记录下来。
随着数据不断积累,系统会逐渐建立属于每个用户的兴趣档案,也就是我们常说的 用户画像(User Profile)。
用户画像是什么?
用户画像(User Profile) 是系统对于用户兴趣的数字化描述。
例如一个用户可能具备以下兴趣标签:
科技
NBA
新闻
游戏
电影
早期推荐系统通常直接使用标签进行内容匹配。
例如:
用户喜欢NBA
↓
推荐篮球视频
但随着平台规模不断扩大,这种方式已经无法满足需求。
因为每天都有数千万用户产生新的行为数据,同时平台还会新增海量视频内容。
此时,推荐系统需要一种更高效的数据表达方式。
这就是 向量化表示(Vector Representation)。
从兴趣标签到 Vector(向量)
现代推荐系统并不会简单记录:
用户喜欢科技
而是会将用户兴趣转换成高维的 Vector(向量)。
例如:
[
0.85,
0.05,
0.03,
...
]
其中每个维度都代表某种潜在特征。
例如:
0.85 → 科技
0.05 → 幽默
0.03 → 体育
...
在工业级推荐系统中,一个用户通常会被表示成:
128维向量
256维向量
512维向量
甚至1024维向量
因此:
用户 = 512维向量
同样地,每一个视频也会被表示成:
视频 = 512维向量
此时推荐问题发生了变化。
原来的问题是:
用户喜欢什么视频?
变成了:
哪个视频向量与用户向量最接近?
推荐系统开始从内容匹配问题,转变为数学计算问题。
推荐系统的本质,是寻找与用户向量最接近的视频向量。
而这也是为什么短视频平台背后需要庞大计算资源的重要原因。
二、多模态模型:抖音如何理解一条视频
用户画像解决的是:
用户喜欢什么
那么另一个问题来了:
视频到底是什么内容?
对于人类来说,理解视频是一件非常简单的事情。
但对于计算机而言,视频本质上只是一堆数字和像素点。
因此推荐系统必须先理解视频内容,才能进行后续推荐。
这便引出了近年来人工智能领域最热门的方向之一:
多模态模型(Multimodal Model)。
什么是多模态?
模态(Modality)指的是信息的表现形式。
例如:
文字
图片
音频
视频
都属于不同模态。
而视频本身就是一个典型的多模态数据。
因为它同时包含:
- 视觉信息
- 音频信息
- 文本信息
- 情绪信息
推荐系统必须同时理解这些内容。
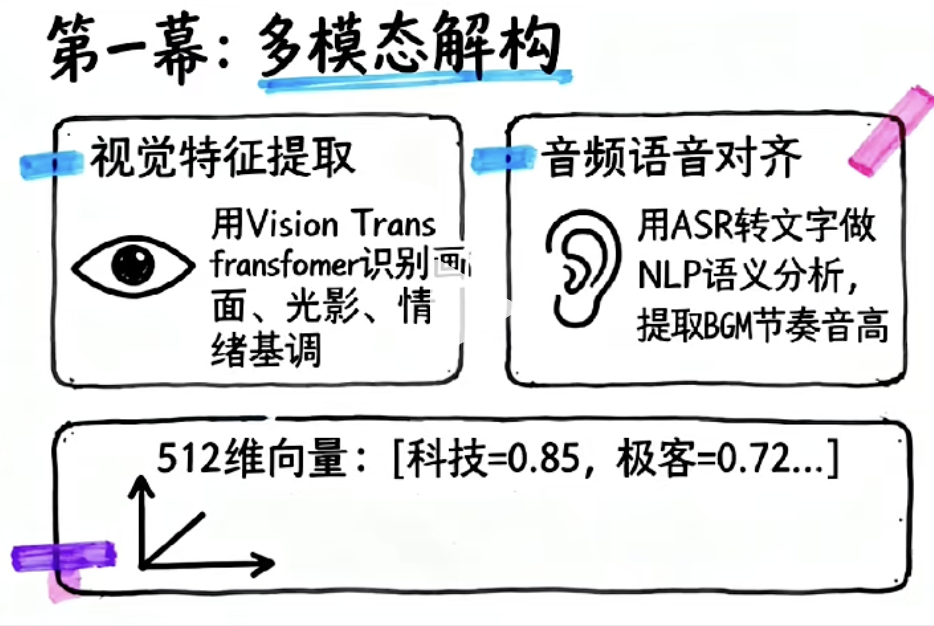
视觉特征提取
首先需要处理的是视频画面。
系统会对视频进行逐帧分析。
例如一个视频中出现:
猫
程序员
电脑
篮球比赛
寝室看世界杯
模型都能够识别出来。
目前主流方案之一是:
Vision Transformer(ViT)
即视觉 Transformer。
Vision Transformer 的核心思想
在传统计算机视觉领域,CNN(卷积神经网络)长期占据主导地位。
而近年来 Transformer 架构被引入视觉领域后,产生了 Vision Transformer。
其核心思想是:
把图片切分成大量小块(Patch)。
例如:
Patch1
Patch2
Patch3
...
随后像处理单词一样处理这些图像块。
利用 Transformer 的自注意力机制建立全局关联。
相比传统 CNN:
- 能获得更强的全局理解能力
- 更适合大规模数据训练
- 与大语言模型架构保持统一
因此系统不仅能够识别:
这是一只猫
还能进一步判断:
猫正在晒太阳
视频整体氛围温暖治愈
甚至能够分析画面的色彩风格和情绪基调。
ViT是近年来计算机视觉领域最重要的突破之一,也是多模态大模型的重要基础。
音频特征提取
视频不仅有画面。
还有声音。
因此推荐系统还需要处理音频信息。
首先会使用 ASR(Automatic Speech Recognition) 技术。
即自动语音识别。
其作用是:
语音
↓
文本
例如视频中的配音:
今天带大家学习Python
会被自动转换成文字。
随后进入 NLP 模型进行分析。
NLP语义分析
NLP(Natural Language Processing) 即自然语言处理。
其任务是理解文本含义。
例如:
机器学习
深度学习
大模型
系统会自动提取这些关键词。
从而判断视频主题属于:
AI
编程
科技
相关领域。
情绪特征分析
除了内容本身,推荐系统还会分析声音中的情绪信息。
例如:
- 音量大小
- 说话速度
- 情绪变化
- 背景音乐风格
系统能够区分:
激情演讲
和:
轻声讲述故事
之间的差异。
最终,视觉信息、音频信息、文本信息以及情绪特征会被融合。
形成统一表示:
视觉特征
+
音频特征
+
文本特征
+
情绪特征
↓
512维视频向量
而这正是后续推荐流程的输入数据。
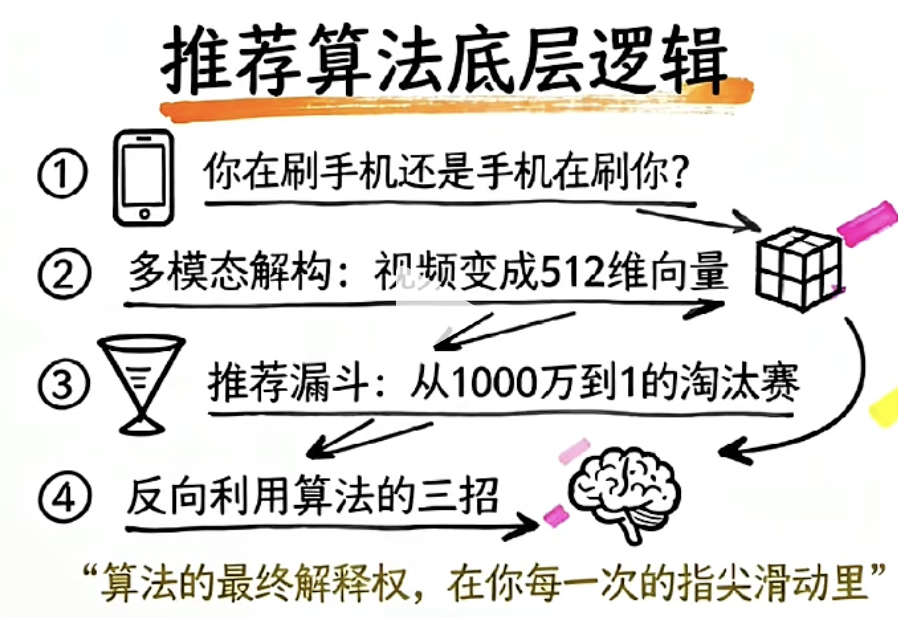
三、推荐漏斗:从1000万条视频到你的首页
假设平台拥有:
1000万条视频
如果系统对每一条视频都进行完整计算,成本将极其恐怖。
因此工业级推荐系统通常采用一种经典架构:
推荐漏斗(Recommendation Funnel)
整体流程如下:
召回
↓
粗排
↓
精排
↓
重排
通过层层筛选不断缩小候选集合。
这样既保证推荐效果,又能够控制计算成本。
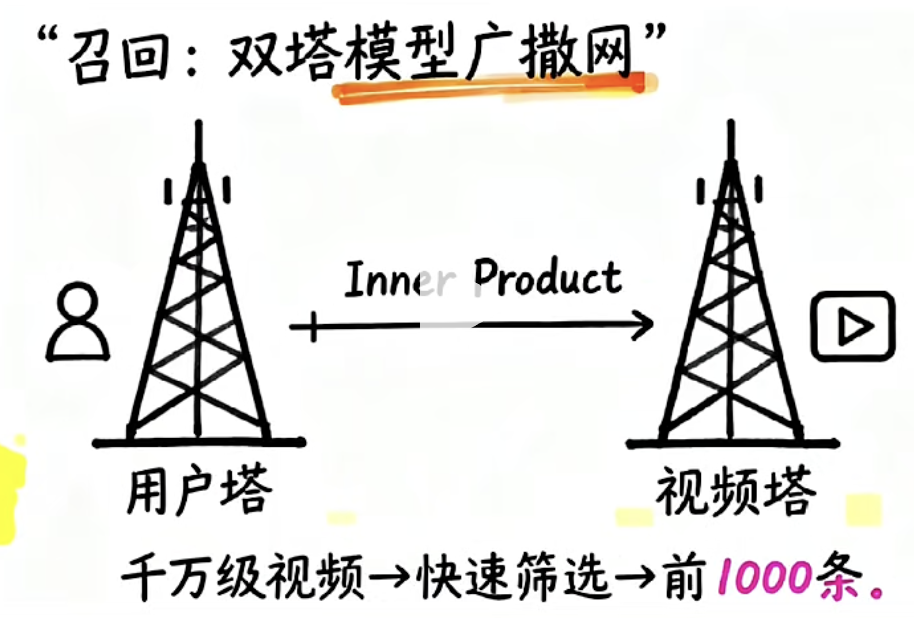
双塔模型:推荐系统的第一道筛选
推荐漏斗的第一步是 召回(Recall)。
召回阶段的核心目标是:
从海量视频中快速找到用户可能感兴趣的内容。
这里通常会使用:
双塔模型(Two Tower Model)
双塔模型由两部分组成:
用户塔(User Tower)
视频塔(Item Tower)
用户塔负责学习用户兴趣特征,最终生成:
用户向量
视频塔负责学习视频内容特征,最终生成:
视频向量
最终形成:
用户向量
VS
视频向量
之间的匹配关系。
由于用户和视频都已经被转换成向量,因此推荐问题本质上变成了向量匹配问题。
Cosine Similarity:如何判断用户是否喜欢某个视频
系统如何知道两个向量是否相似?
最常见的方法就是:
Cosine Similarity(余弦相似度)
其核心思想非常简单:
两个向量夹角越小,相似度越高。
例如:
用户向量:
[0.90, 0.08, 0.02]
视频向量:
[0.88, 0.10, 0.02]
两个向量方向十分接近。
说明该视频与用户兴趣高度匹配。
因此系统会优先推荐。
通过向量检索与余弦相似度计算,系统能够从:
1000万条视频
中迅速筛选出:
1000条候选视频
这就是召回阶段的作用。
需要注意的是:
召回阶段并不追求绝对精准。
它更像是在海量内容中先进行一次“大海捞针”。
只要能够把可能感兴趣的视频找出来即可。
粗排:进一步缩小候选范围
召回得到的1000条视频仍然太多。
如果直接进入复杂模型计算,服务器压力依然非常大。
因此需要进入下一阶段:
粗排(Coarse Ranking)
粗排通常使用相对轻量级的机器学习模型。
快速计算一些基础特征,例如:
- 视频质量
- 用户兴趣匹配程度
- 视频热度
- 发布时间
- 作者质量
经过粗排后:
1000条视频
↓
300条视频
进入下一阶段。
此时虽然淘汰了大量内容,但大多数用户真正感兴趣的视频仍然被保留下来。
精排:预测用户的下一步行为
精排是整个推荐系统最核心的环节之一。
因为它决定了:
用户最终会看到什么内容,以及内容出现的顺序。
此时系统不再只考虑简单匹配。
而是会预测用户对于每个视频可能产生的行为。
例如:
- 是否点击
- 是否看完
- 是否点赞
- 是否评论
- 是否分享
- 是否关注作者
这些行为都会被模型预测对应概率。
随后计算综合得分:
Score =
w1 × 点击率
+
w2 × 完播率
+
w3 × 点赞率
+
w4 × 评论率
+
w5 × 分享率
其中:
w1
w2
w3
...
代表不同指标的重要程度。
例如某个平台可能更加重视:
完播率
那么对应权重就会更高。
如果更加重视内容传播:
分享率
权重也会提升。
最终:
Score 越高
↓
排序越靠前
↓
越容易被用户看到
这也是为什么有些视频会突然爆火。
因为模型预测它能够获得更高的用户反馈。
四、重排机制与探索机制
如果推荐系统永远按照分数排序,会产生一个问题。
假设最近你对 AI 内容特别感兴趣。
那么系统可能会推荐:
AI
AI
AI
AI
AI
AI
AI
虽然非常精准。
但很快就会产生内容疲劳。
用户的新鲜感会逐渐下降。
因此推荐系统还需要进行最后一步:
重排(Re-Ranking)
重排机制:主动打散内容
重排阶段并不是为了提高准确率。
而是为了提高内容多样性。
例如前十个视频全部属于:
AI
领域。
系统可能会主动插入:
美食
旅行
舞蹈
音乐
等内容。
形成更加丰富的信息流。
例如:
AI
AI
美食
AI
旅行
AI
舞蹈
这样既能保持用户兴趣,又能避免审美疲劳。
重排机制的目标不是提高预测准确率,而是提升用户体验。
这也是现代推荐系统不可缺少的重要环节。
Explore 与 Exploit:推荐系统最经典的问题
在推荐系统领域,有一个极其经典的问题:
Explore(探索) 与 Exploit(利用)。
几乎所有推荐平台都必须解决这个问题。
Exploit:利用已知兴趣
系统已经知道:
你喜欢AI
那么最安全的做法就是:
继续推荐AI
因为这样能够获得更高的点击率。
这种策略被称为:
Exploit(利用)
即充分利用已经掌握的信息。
Explore:探索潜在兴趣
但问题在于:
用户兴趣并不是固定不变的。
例如某一天。
你偶然刷到一个:
野外求生视频
并且停留了几秒钟。
对于推荐系统来说,这可能意味着:
用户出现了新的兴趣方向
于是系统会尝试继续推荐几条类似内容。
观察你的后续反应。
这种行为就叫:
Explore(探索)
即主动寻找用户可能喜欢的新内容。
用户画像为什么会不断变化
很多人认为:
用户画像建立完成后就固定不变了。
实际上并非如此。
推荐系统中的用户画像始终是动态更新的。
例如最开始:
科技:80%
篮球:20%
经过一段时间后:
科技:60%
篮球:20%
野外求生:20%
继续观看相关内容后:
科技:45%
篮球:15%
野外求生:40%
用户画像会随着每一次点击、停留、点赞和分享不断调整。
用户画像不是静态数据,而是实时变化的数据模型。
因此推荐系统才能持续理解用户不断变化的兴趣。
为什么很多推荐系统采用 80% + 20% 策略
如果系统只做 Exploit。
用户容易产生疲劳。
如果系统只做 Explore。
推荐准确率又会大幅下降。
因此很多平台都会采用类似策略:
80% 已知兴趣
+
20% 潜在兴趣探索
例如:
80%
推荐用户已经喜欢的内容
20%
测试用户是否喜欢新的内容
这样既能够保证推荐效果。
又能够不断发现新的兴趣标签。
从长期来看,能够显著提高用户活跃度与停留时间。
总结
从表面上看,刷抖音只是不断上下滑动屏幕的过程。
但在背后,一个复杂而庞大的推荐系统正在高速运转。
它会通过用户行为构建 用户画像,利用 多模态模型 理解视频内容,通过 向量化表示 建立用户与视频之间的联系,再经过 双塔模型召回、粗排、精排、重排 等多个阶段,最终将最适合用户的视频推送到首页。
整个流程可以概括为:
用户行为
↓
用户画像
↓
向量化表示
↓
多模态理解视频
↓
双塔模型召回
↓
粗排
↓
精排
↓
重排
↓
最终推荐
当我们下一次打开抖音时,不妨换个角度思考:
你看到的每一条视频,都不是随机出现的,而是推荐系统经过海量数据分析与复杂算法计算后,为你量身定制的结果。
也正因为如此,才有了我们熟悉的:
千人千面。


















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










