






上周帮一个做电商的朋友调试工作流,需求很简单:批量生成商品描述文案,输入商品名称和几个关键属性,输出结构化的JSON。

听起来是不是很简单?大模型节点里写一句"请根据以下商品信息生成描述,输出JSON格式",然后把 {{商品名}} {{属性1}} 这些变量插进去,跑就完了。
结果呢?跑了10条数据,3条格式正常,4条多了markdown包裹,2条漏了字段,还有1条直接输出了一段"好的,我来帮你生成..."的废话。
改Prompt,换了3个模型,前后调了几十版,最后发现不是模型的问题,是5个底层坑没搞清。
今天把这5个坑全拆出来,你对照检查一下自己的工作流,大概率能省掉十几版的调试时间。
📌 关于作者:米核AI易山联合创始人,专注AI自动化和智能体搭建。官网:miheaii.com

第一个坑:变量插值被LLM"误解"
这是最常见的坑。
很多人的Prompt是这样写的:
请根据以下商品信息生成商品描述:
商品名:{{商品名}}
属性:{{属性1}},{{属性2}}
请输出JSON格式。
看起来没问题对吧?但实际跑起来,LLM经常把 {{商品名}} 这个占位符当成"需要我填充的内容",于是它开始自己编商品名。
更离谱的情况:如果 {{商品名}} 的值是"无线蓝牙耳机",LLM有时会输出:
{
"商品名": "无线蓝牙耳机",
"描述": "请根据以下商品信息生成商品描述..."
}
它把整个Prompt模板当成商品描述输出了。
根因是什么?
变量和指令没有做清晰的隔离。LLM分不清哪些是"你需要遵守的规则",哪些是"需要处理的数据"。
怎么修?
用明确的分隔符把变量包起来。比如用 XML 标签:
你是一个商品描述生成助手。请严格按照以下规则生成描述:
1. 输出必须是合法的JSON格式
2. 不要包含markdown标记
3. 不要输出任何解释性文字
商品信息如下:
<product_info>
商品名:{{商品名}}
属性:{{属性1}}、{{属性2}}
</product_info>
请根据<product_info>中的信息生成描述。
加了 <product_info> 标签后,LLM就知道这部分是"数据",外面的文字是"规则"。变量被误解的概率会大幅下降。
第二个坑:JSON输出格式漂移
这个坑最折磨人。
你让LLM输出JSON,前10条数据都正常,到第11条突然多了个 ```json 包裹。再跑几条,又开始在JSON里加注释。批量跑100条,大概有20%的格式是"变种"。
常见的变种有这几种:
- 加了
json 和包裹 - 在JSON里加了 // 注释
- 多输出了 "备注" 字段
- 数值类型变成了字符串("price": "99" 而不是 "price": 99)
- 数组和对象混用
为什么会出现这种情况?
因为LLM生成JSON不是"执行代码",而是"预测下一个token"。它的输出有随机性,尤其是在长文本生成时,格式一致性很难保证。
怎么修?
三管齐下:
第一,在System Prompt里明确写死输出规范:
输出规范:
1. 只输出纯JSON,不要包含任何markdown标记
2. 不要添加注释
3. 不要添加任何额外字段
4. 数值类型必须用数字,不要用字符串
第二,在Prompt末尾加一个"输出示例",让LLM照着抄:
输出示例:
{
"商品名": "无线蓝牙耳机",
"描述": "高品质无线蓝牙耳机,支持主动降噪...",
"价格": 299,
"标签": ["降噪", "无线"]
}
第三,也是最关键的——后处理必须兜底。
不管Prompt写得多完美,LLM总有概率输出异常格式。所以工作流里一定要加一个代码节点,做三件事:去掉markdown包裹、去掉注释、校验JSON合法性。解析失败的直接触发重试。
别指望Prompt能100%保证格式,后处理兜底才是正道。
第三个坑:System Prompt和User Prompt职责混乱
很多人写Prompt的时候,把所有内容都塞进User Prompt,System Prompt要么留空,要么就写一句"你是一个助手"。
结果就是:LLM分不清规则和数据的边界,输出忽左忽右。
比如你这样写:
User Prompt:你是一个商品描述专家。请根据商品信息生成描述。商品名是{{商品名}},属性是{{属性1}}。请输出JSON格式。
这里面混了3种东西:角色设定("你是专家")、数据处理指令("生成描述")、实际数据("商品名是...")。
LLM有时候会重点听"角色设定",输出一大段分析;有时候重点听"数据处理",格式又不对了。
怎么修?
把职责严格分开:
- System Prompt:只放"你是谁"和"输出规范"
- User Prompt:只放"具体任务"和"数据"
【System Prompt】
你是一个电商商品描述生成助手。
输出规范:
1. 必须输出合法JSON
2. 不包含markdown标记
3. 不输出解释性文字
【User Prompt】
请为以下商品生成描述:
<product_info>
商品名:{{商品名}}
属性:{{属性1}}、{{属性2}}
</product_info>
这样分清楚后,LLM的行为会稳定很多。System Prompt是"宪法",User Prompt是"具体任务",两者不能混。

第四个坑:换个模型就废了
这个问题做电商自动化的应该深有体会。
你在调试的时候用GPT-4o,Prompt写得漂漂亮亮,JSON输出稳如老狗。结果上线的时候老板说"用豆包吧,便宜",一换模型,格式全乱,字段顺序变了,有些字段甚至开始自由发挥。
又或者你用的是通义千问,测试环境跑得挺好,部署到生产环境发现换了个版本的模型,输出又开始漂移。
为什么会这样?
因为不同模型的"指令遵循能力"差异很大。GPT-4o这类强模型,你说"不要加markdown"它就真不加;但一些弱一点的模型,你说了它也可能忽略,或者理解偏了。
更麻烦的是,同一个模型的不同版本,行为也可能不一致。比如某模型从v2升级到v3,可能输出格式就变了。
怎么修?
第一,Prompt要做"模型无关"设计。
不要依赖模型的"聪明"来理解你的意图。把规则写得越明确、越傻瓜化越好。比如:
- 不要写"请输出JSON"(太模糊)
- 要写"请输出一个JSON对象,包含以下字段:商品名(字符串)、描述(字符串)、价格(数字)、标签(数组)"
第二,做跨模型测试。
Prompt写完后,至少用3个模型跑一遍:豆包、通义千问、DeepSeek。如果3个模型都稳定,上线后换模型的风险就小很多。
第三,后处理逻辑要更健壮。
不同模型的JSON格式差异可能不止是markdown包裹,还可能有字段顺序不同、字段名大小写不同。后处理代码要做兼容:统一字段名大小写、检查必需字段是否缺失、缺失字段补默认值。
别指望一个模型跑通就万事大吉,多模型验证才是生产环境的底线。
第五个坑:多轮对话上下文膨胀
这个坑比较隐蔽,但杀伤力很大。
场景是这样的:你的工作流里,大模型节点需要多轮交互。比如第一轮让LLM生成商品描述,第二轮让它根据描述生成标签,第三轮让它检查标签是否符合规范。
很多人实现多轮交互的方式是:每一轮都把前面所有的对话历史塞进去,让LLM"看到完整上下文"。
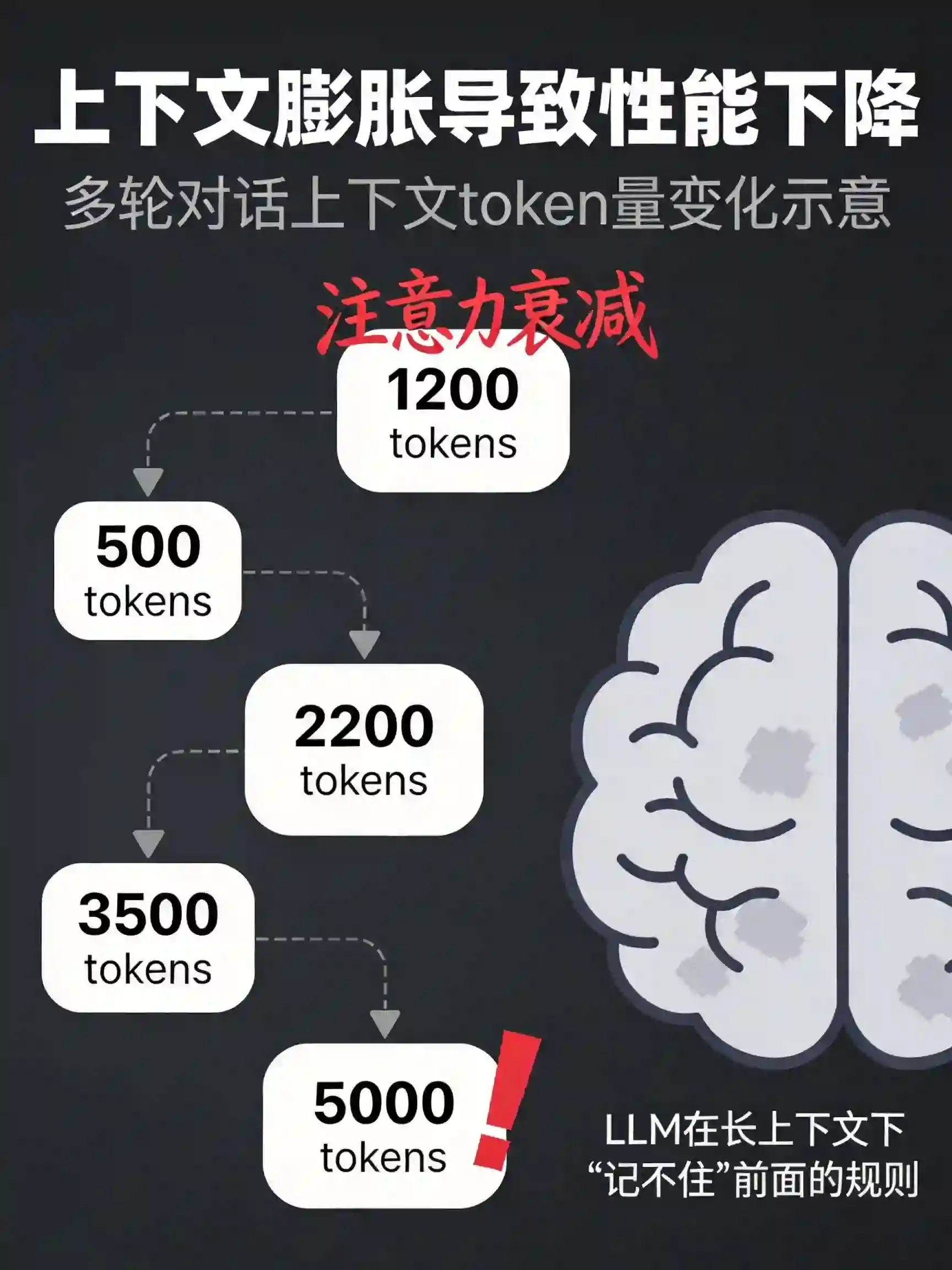
前3轮还好,到第5轮、第6轮,上下文已经很长了。这时候LLM开始"忘事"——你第一轮定的规则,它到第5轮就忘了。或者更糟,它开始胡言乱语,输出和任务完全无关的内容。
为什么会这样?
因为LLM的注意力机制有"长文本衰减"问题。上下文越长,它对中间部分的注意力越弱。你的关键规则如果藏在第1轮的对话里,到第5轮它可能就"看不见"了。
怎么修?
第一,不要无脑堆历史。
每一轮只传"上一轮的输出"和"当前轮的指令",不要把前面所有的对话都塞进去。如果确实需要历史信息,做摘要后传入。简单说就是:第3轮只需要知道第2轮的结果,不需要知道第1轮问了什么。
第二,关键规则要"重复强调"。
如果某些规则每一轮都要遵守(比如"必须输出JSON"),不要只在System Prompt里写一次,而是在每一轮的User Prompt里都重复一遍。虽然看起来冗余,但能对抗长文本衰减。
第三,控制每轮的输出长度。
如果每一轮LLM都输出一大段,上下文膨胀会很快。在Prompt里明确要求"简洁输出",或者限制输出字段数量。
5个坑的修复清单
最后汇总一下,你对照检查:

| 坑 | 根因 | 解法 | 验证方法 |
|---|---|---|---|
| 变量插值被误解 | 变量和指令没隔离 | 用XML标签包裹变量 | 让LLM输出变量原文,检查是否被篡改 |
| JSON格式漂移 | LLM输出有随机性 | System Prompt明确规范 + 后处理兜底 | 批量跑50条,统计格式异常率 |
| System/User职责混乱 | 规则和数据混在一起 | 严格分层:System放规则,User放数据 | 检查Prompt结构,确认职责清晰 |
| 换模型就废 | 模型指令遵循能力差异 | Prompt做"模型无关"设计 + 多模型测试 | 用3个模型各跑20条,对比稳定性 |
| 多轮上下文膨胀 | 历史对话堆太长 | 只传上一轮输出 + 关键规则重复强调 | 跑6轮,检查第5轮是否还记得第1轮的规则 |
这5个坑我基本全踩过,前后改了几十版Prompt才摸清楚。如果你在做电商AI自动化,遇到大模型节点输出不稳定的问题,可以对照这个清单逐一排查。
我后来整理了一套电商场景的工作流Prompt模板,商品描述生成、标签提取、文案优化这些场景基本能直接复用。有需要的可以私信交流。


















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










