




 本文详细介绍了如何从Logistic回归逐步演化到支持向量机(SVM)算法,通过调整代价函数,引入正则化参数,并最终形成SVM的独特优化目标。文中探讨了在Logistic回归中正则化参数λ的作用,而在SVM中这一作用由参数C承担,用于平衡训练样本的代价与正则化项。通过对成本函数的修改,明确了在SVM中,当目标变量为1时,预测值z需大于等于1,目标变量为0时,预测值z需小于等于-1,以找到最优解。
本文详细介绍了如何从Logistic回归逐步演化到支持向量机(SVM)算法,通过调整代价函数,引入正则化参数,并最终形成SVM的独特优化目标。文中探讨了在Logistic回归中正则化参数λ的作用,而在SVM中这一作用由参数C承担,用于平衡训练样本的代价与正则化项。通过对成本函数的修改,明确了在SVM中,当目标变量为1时,预测值z需大于等于1,目标变量为0时,预测值z需小于等于-1,以找到最优解。
在监督学习中,许多学习算法的性能非常相似,下面介绍一个更加强大的广泛应用于工业界和学术界的算法------支持向量机算法,支持向量机可以理解为从Logistic回归模型一点一点修改而来。
我们先回顾一下Logistic回归的假设函数:

当z → +∞ g(z) → 1
当z → -∞ g(z) → 0
Logistic回归的代价函数:
将‘—’负号移进去,上式可以写成:
下面从Logistic回归的代价函数开始一点一点修改:
第一步、简化Logistic回归代价函数的
因 为常量,且m>0,则m的取值对 求代价函数J最小值时 的最优解θ 无影响:
---------------------------------(1)
举例说明:
假设表达式为
在y存在最小值、并且m > 0的前提下,y取得最小值时的 x 不会随m变化而变化(始终都是 x=1 时取得最小值)。
因此,简化后(1)式变为:
---------------------------------(2)
(2)式的结构可以写为 A + λ×B
第二步、改造 A + λ×B
延续第一步,代价函数可写成 J(θ) = A + λ×B 的结构形式,在Logistic回归中:
A:表示训练样本的代价
λ:表示正则化参数
λ×B:表示正则化项(用来平衡A,防止过拟合)
Logistic回归中我们是通过设置不同的正则参数 λ 达到优化目的,这样我们就能够权衡对应的项,是使得训练样本拟合的更好(即最小化A),还是保证正则参数足够小;但在支持向量机中,使用一个不同的参数来替换这里使用的 λ ,来权衡这两项,这个参数称为C,于是 J(θ) = A + λ×B 改造为 J(θ) = C×A + B 。
在 Logistic回归中:J(θ) = A + λ×B ,如果给定 λ 一个非常大的值,意味着给予B更大的权重;
在支持向量机中:J(θ) = C×A + B,如果给定C一个非常小的值,意味着给予B更大的权重;
可以理解为无论 A + λ×B 还是 C×A + B 只是以不同的方式来控制这种权衡而已 ,即用一个参数来决定是更关心第一项的优化还是更关心第二项的优化。
因此,改造后(2)式变为:
---------------------------------(3)
第三步、根据y的取值进一步修改
针对一个训练样本而言,
Cost =
![]()
-> Cost =
-> Cost =
那么:
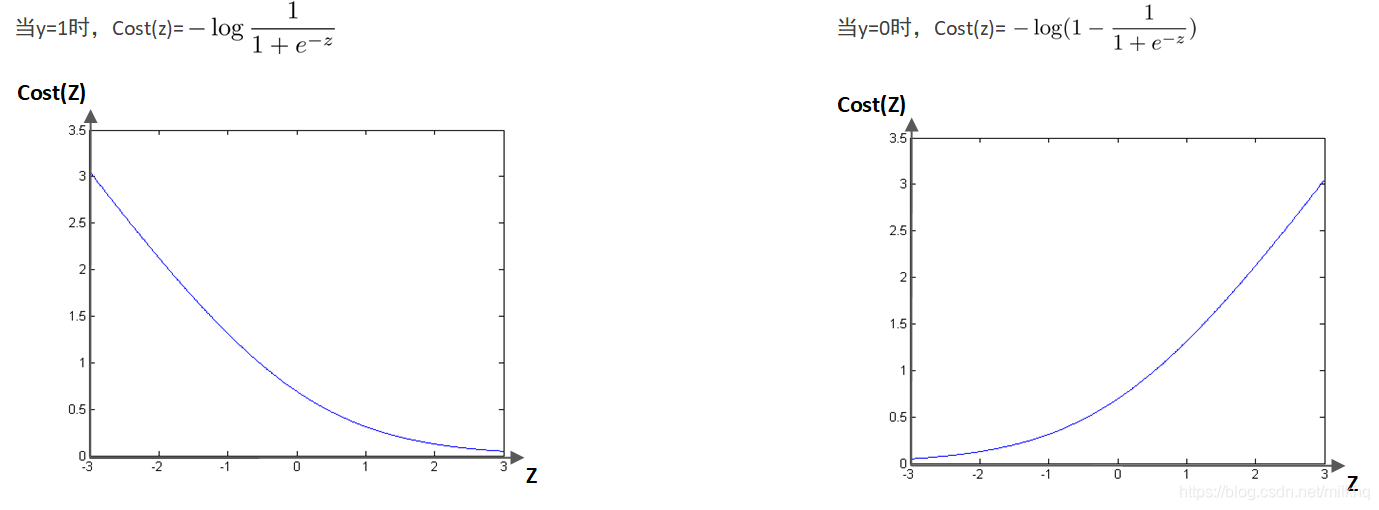 我们将上图图像做一点修改,如下图中粉色线所示,得到新的代价函数:
我们将上图图像做一点修改,如下图中粉色线所示,得到新的代价函数:
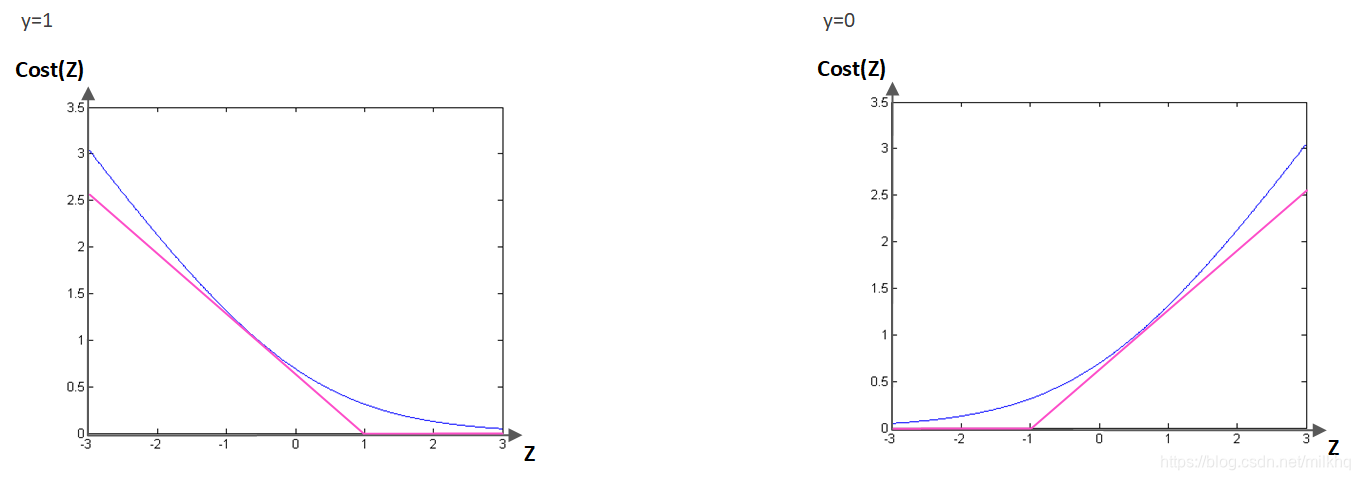
令:
当y=1时,cost记为
当y=0时,cost记为
则,由上图可知:
当y=1时,如果 z≥1 ,则 = 0
当y=0时,如果 z≤-1 ,则 = 0
即 :
当y=1时, z≥1(即≥1),代价函数可以取得最优解
当y=0时,z≤-1(即≤-1),代价函数可以取得最优解
因此,(3)式变为:
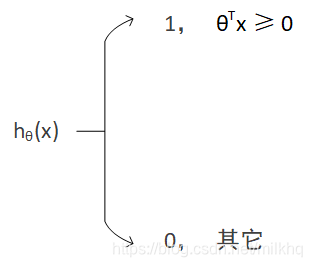
对应的假设函数:


















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










