




 本文介绍了一种称为GILE的通用输入标签嵌入方法,用于文本分类,强调了对标签本身的考虑。该模型通过计算输入文本和标签的联合表示来预测类别,适用于未见过的样本。其核心包括对标签和输入文档的嵌入处理,以及通过点乘和激活函数融合这些信息来决定文本的分类。
本文介绍了一种称为GILE的通用输入标签嵌入方法,用于文本分类,强调了对标签本身的考虑。该模型通过计算输入文本和标签的联合表示来预测类别,适用于未见过的样本。其核心包括对标签和输入文档的嵌入处理,以及通过点乘和激活函数融合这些信息来决定文本的分类。
背景
当前文本分类的方法和框架有很多,但往往缺乏了对label本身的关注,所以分享一篇相关的论文,希望抛砖引玉。原文名称:《GILE: A Generalized Input-Label Embedding for Text Classification》。
目的
本文就是使用了一些新的连接input和label的方式,更好地去做文本分类,同时也能应用于unseen的样本中。
模型
1.先获取label的embedding; ε ∈ IR|Y|×d ,其中label的每个class的embedding就是label每个word的embedding的平均。
2.再将Input的document做成向量 h ∈ IRdh,这个h是将word—(全联接) —> sentence —(全联接) —> document.
3.Label的部分,通过U ∈ IRd×dj 和 bu ∈ IRdj ,将每个类的ej进行点乘U,再加上b,再经过relu/Than得到新的向量ej‘(1, dj). 经过Y个类的处理后
得到ε’ ∈ IR|Y|×dj
4.Input document的部分,通过V ∈ IRdj×dh 和 bv ∈ IRdj ,再经过relu/Than得到h‘(1, dj).
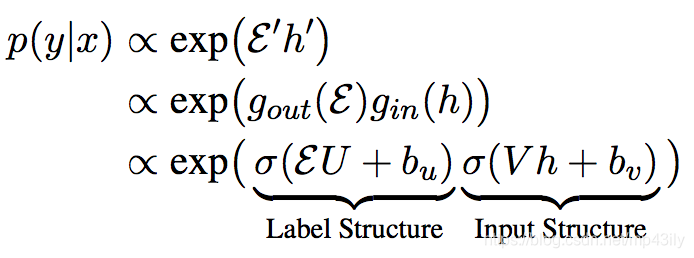
5.计算联合goint . 将每个ej’(1, dj)和h‘(1, dj)做点乘得到一个scala值再加上b得到Pval; 将h’跟每个类算一个Pval,得到Y个Pval。
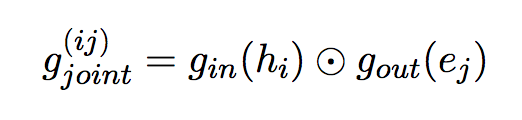
6.最后再把每个Pval过一个sigmoid得到一个(0,




















 5841
5841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










