




1. 引言
Protobuf 是一种与语言无关、与平台无关的可扩展机制,用于序列化结构化数据协议。Protobuf最初由 Google 于 2001 年在内部开发,目前已发布到第三个版本(Proto 3)。自发布以来,Protobuf已经成为一种非常流行的序列化解决方案,包括在嵌入式领域中。
- https://github.com/nanopb/nanopb(C + Python)
实现 protobuf 编码/解码的最著名库是 Nanopb —— 一个开源的 ANSI-C 库,专为嵌入式系统开发,具有极低的 RAM 和代码空间需求。
在 Zephyr 操作系统中,protobuf也被默认作为序列化选项之一。
由于nanopb库的使用极为广泛,因此深入了解nanopb的配置选项是有意义的。下面列出了一些常见陷阱及在项目中使用 nanopb 时值得考虑的配置调整。
2. 陷阱 #1:Submessage子消息太多
取决于如何使用 protobuf 和 nanopb,一个显著的性能瓶颈可能是编码速度——即在通过通信链路发送 protobuf 时的编码耗时。
默认情况下,nanopb 为了节省代码空间,会牺牲一定的编码速度。
最容易掉入的陷阱是:
- 如果proto 消息中包含大量子消息(submessage)。
在编码过程中,nanopb 实际上会对每个子消息编码两次:
- 第一次用于计算消息大小,
- 第二次才是真正将其写入 protobuf 缓冲区。
可以很容易地想象,当子消息层级增加时,编码时间会迅速上升。
这就是一个典型的权衡:结构化组织性(使用子消息方便管理数据) vs 编码时间。
要避免这种问题,请确保在嵌入式系统中需要编码/解码的 protobuf 消息中,尽量减少子消息数量。
如果只有一两个(甚至包含少量嵌套消息)一般没问题,但如果层级达到 5、10 层甚至更深,就会严重影响编码效率。
3. 陷阱 #2:流(Stream)抽象
另一个限制是:
- nanopb 的默认配置是以 流式写入(stream writing) 为核心设计的。
- 如果确实需要支持从流中读写数据,这当然是个优点;
- 但如果仅仅需要将 nanopb 输出到内存缓冲区(memory buffer),那么默认配置其实会带来额外开销。
幸运的是,nanopb 的开发者已经意识到这种权衡,并提供了一个编译标志用于回退到“仅使用内存缓冲区”的模式。
这个编译选项叫做 PB_BUFFER_ONLY,它会有条件地移除额外的回调逻辑,从而减少 nanopb 的最终代码体积,并通过减少函数调用数量来加快编码过程。
可以在编译时添加这个宏定义,或者直接在 nanopb 库顶部加入:
#define PB_BUFFER_ONLY
这是一种快速且简单的优化方式,能显著加速基于内存缓冲的 protobuf 编码过程。
4. 避开这些陷阱能带来什么帮助?
4.1 问题背景
需要将一系列体积较小但嵌套层次很深的 protobuf 消息发送到另一个模块。
在每次发送前,这些消息都必须通过 nanopb 进行编码。
原计划是每 100ms 发送一条消息,但在实际运行中发现偶尔会错过时序,于是团队开始调查为什么编码过程这么耗时。
4.2 优化前
在执行该过程前后通过控制 GPIO 的开关来标记时间点,并用逻辑分析仪记录。
逐步分析性能瓶颈后发现,单条消息的编码过程大约耗时 1.5ms,而生成要发送的数据又需要额外的 0.5ms。
下图是通过 PulseView 捕获的一系列 protobuf 编码信号:
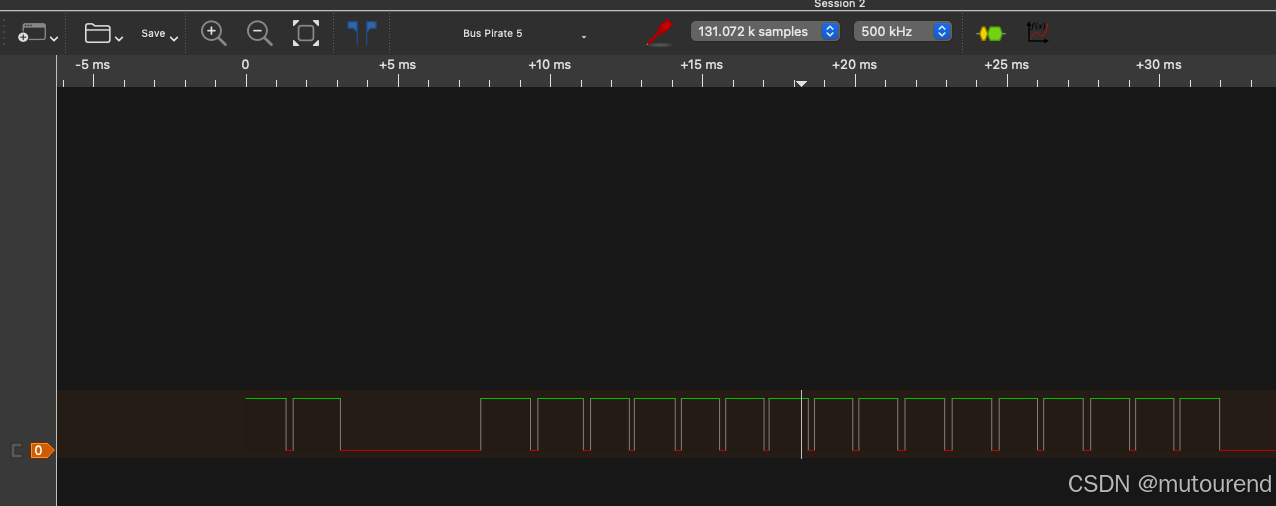
4.3 优化后
通过移除大部分子消息(submessage),并修改 nanopb 的配置为仅使用内存缓冲区(PB_BUFFER_ONLY),编码时间降至 约 0.6ms(同样通过逻辑分析仪验证)。
另一张 PulseView 截图如下:
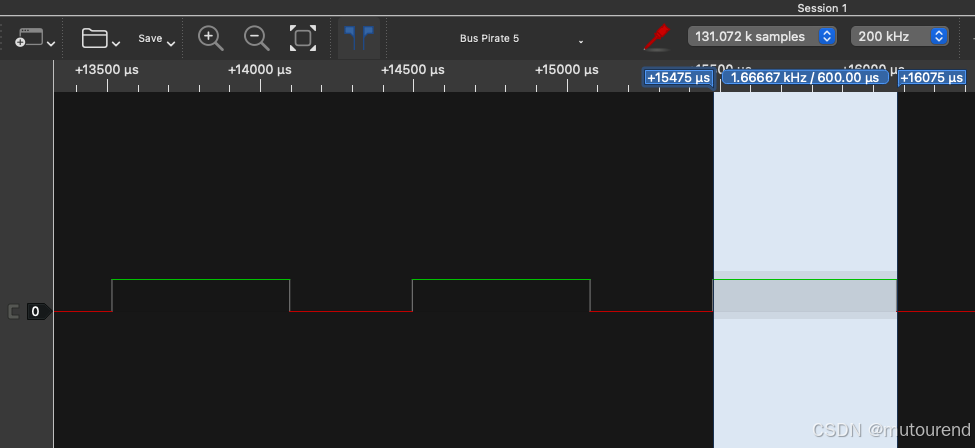
将编码时间缩短到原来的 40% 是一个相当显著的改进,尤其是考虑到其中一个改动只是调整 nanopb 的单个配置值!
当然,减少 protobuf 消息中的子消息数量可能比较复杂,特别是当这些消息已被多个模块使用时。
但始终可以弃用(deprecate)旧字段,并逐步迁移到新的结构上。
前提是——得知道 protobuf 的弃用机制是怎么工作的……
5. 陷阱 #3:弃用(Deprecation)支持
当前 Protobuf 3 的实现支持在字段上添加 deprecated 选项,用于标记该字段已弃用。
然而,Google 提供的官方 proto 编译器只有在生成 Java 或 C++ 代码时才会对该选项做出处理。
而作为 ANSI-C 库 的 Nanopb,会完全忽略这个选项。
那么,该如何在 nanopb 中强制弃用某个字段呢?
在 2024 年之前,如果想弃用 nanopb 的字段,可以设置 FT_IGNORE 标志。
这样做会直接移除该字段,使得继续使用该字段时会导致编译错误(hard failure),而非像 Google 建议的那样仅仅发出警告。
在 2024 年初,nanopb 做出了一项改进,增加了 discard_deprecated 选项。当 discard_deprecated 选项 与官方的 deprecated 标签配合使用时,效果等同于 FT_IGNORE:
也就是说,虽然目前 deprecated 标签的机制已为未来做好准备,但在现阶段,仍需手动“硬性移除”该字段。
在执行移除时,Google 官方文档 提供了一个非常重要的建议:
如果该字段已无人使用,并且希望防止新用户使用它,请考虑将该字段声明替换为
reserved语句。
这样可以防止未来的开发者重复使用相同的字段编号,否则可能会导致严重问题。
6. 总结
Nanopb 之所以被广泛用于 Zephyr 等系统,是有充分理由的——Nanopb是开源的,稳定可靠的 protobuf 实现。
但如果不了解Nanopb底层机制,很容易遇到各种性能瓶颈或设计陷阱,这些问题不仅会拖慢开发进度,甚至可能影响产品性能与稳定性。
参考资料
[1] 2025年5月博客 Nanopb Traps and How to Avoid Them


















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










