



目录
博主智算菩萨,专注于人工智能、Python编程、音视频处理及UI窗体程序设计等方向。致力于以通俗易懂的方式拆解前沿技术,从零基础入门到高阶实战,陪伴开发者共同成长。目前已开设五大技术专栏,累计发布多篇原创技术文章,深受读者好评。
📌 专栏导航
- 人工智能前沿知识(已更191篇):深度剖析Transformer架构、生成式AI、强化学习、具身智能、神经符号系统、大模型及智能体(Agent)技术,系统性解析AI核心技术体系与前沿趋势。
- Python基础小白编程(已更232篇):从零开始,以保姆式教程讲解变量、数据类型、流程控制、函数等核心语法,配有大量实战代码与避坑指南,真正做到学以致用。
- 机器学习与深度学习(125篇):系统化拆解线性模型、决策树、随机森林、梯度提升树、神经网络等算法原理与工程实践,覆盖从公式推导到代码实现的全链路内容。
- 音频、图像与视频处理理论与实战(81篇):涵盖FFmpeg多媒体处理、audio_shop开源工具、ComfyUI-WanVideoWrapper视频生成等实用技术,从基础操作到高级应用一应俱全。
- UI窗体程序设计实战(78篇):深入讲解UI设计、动态窗体生成、游戏UI框架设计等实战技巧,提供从配置到编码的完整解决方案。
智算菩萨,以代码为经,以算法为纬,在人工智能的星辰大海中,做你前行路上最可靠的导航者。本人最常用AI工具为AIGCBAR。
本文适合Python编程用户及AI应用开发者,深入解析ProxyAI插件集成大模型的技术原理。API获取地址:AIGC bar。本文建议开发者收藏学习,掌握从插件原理到智能体构建的全链路技术。
1 引言:AI编程助手插件化的技术浪潮
2026年,大语言模型与集成开发环境(IDE)的深度融合已成为软件开发范式变革的核心驱动力。随着DeepSeek-V4-Flash、GLM-5.2等新一代大模型的相继发布与开源,开发者面临的核心问题已经从“能否使用大模型”转变为“如何高效、低成本地将大模型能力集成到日常开发工作流中”。
ProxyAI(前身为CodeGPT)作为JetBrains IDE生态中领先的开源AI编程助手插件,在这一背景下扮演着关键角色。它通过精心设计的插件架构与OpenAI API兼容接口,为开发者提供了一条将各类大模型无缝接入PyCharm等IDE的技术路径。
本文旨在从技术原理层面系统性地剖析ProxyAI插件的工作机制,深入阐述OpenAI兼容接口协议的设计哲学,并结合AIGC Bar这一多模型统一API入口,详细讲解如何在PyCharm中通过ProxyAI集成DeepSeek-V4-Flash与GLM-5.2等模型,最终构建具备自主决策能力的AI编程智能体。
2 ProxyAI插件架构深度解析
2.1 JetBrains插件系统的基础原理
要理解ProxyAI的工作原理,首先需要把握JetBrains IDE插件系统的基础架构。JetBrains系列产品(包括PyCharm、IntelliJ IDEA、WebStorm等)的插件系统基于Platform Plugin SDK构建,允许第三方工具通过定义扩展点(Extension Points) 与IDE核心功能进行交互。
从架构层面看,IDE插件与核心功能的交互包含三个关键层次:
第一层:扩展点注册机制。插件开发者通过在plugin.xml配置文件中声明扩展点,将自定义功能注册到IDE的特定生命周期与交互节点中。这些扩展点覆盖了从编辑器事件监听、代码补全触发到菜单项注入的各个方面。
第二层:服务代理与协议通信。插件通过实现特定的Provider接口(如CodeInsightProvider、CompletionContributor等),将外部AI服务的推理结果以结构化数据的形式注入到IDE的编辑器上下文中。这一层通常采用模块化架构,包含LLM服务代理层,支持gRPC/RESTful双协议通信。
第三层:上下文感知与交互反馈。插件能够捕获当前编辑器的上下文信息——包括打开的文件内容、选中的代码片段、项目结构等,将这些信息封装为AI推理请求的输入,并将AI返回的结果以代码补全、行内建议或对话窗口的形式呈现给开发者。
ProxyAI正是基于这一插件化架构设计实现的。它在JetBrains Marketplace上的官方描述明确指出,其设计目标是作为Cursor、Windsurf、GitHub Copilot等工具的强大开源替代方案。
2.2 ProxyAI的核心架构组件
ProxyAI的架构可以划分为四个核心功能模块:
(1)多Provider连接层。这是ProxyAI最核心的架构设计。它支持连接多种类型的模型服务提供商,包括OpenAI、Anthropic、Azure、Mistral等云服务商,也支持Ollama等本地部署方案,以及通过OpenAI API兼容配置接入自定义的私有化部署模型。这一层的设计哲学是“Bring Your Own Key”——开发者使用自己的API密钥连接偏好的模型提供商。
(2)上下文工程模块。ProxyAI能够自动检测并利用当前IDE中的上下文信息,包括打开的文件、选中的代码、最近的更改等,来生成有针对性的建议和响应。该模块还支持手动引用项目文件、文件夹以及外部Web文档,实现更精准的上下文感知编程辅助。
(3)交互界面层。ProxyAI提供了类似ChatGPT的对话界面,支持文本与图像输入。其“Auto Apply”功能允许开发者以Diff视图预览AI建议的代码修改,并通过单击批准或拒绝。
(4)离线与本地优先支持。ProxyAI是连接本地运行LLM与JetBrains IDE的领先开源扩展,支持在不发送外部数据或不需要互联网连接的情况下享受完整的AI辅助。这通过Ollama集成、GGUF格式支持以及LLaMA C/C++集成实现。
2.3 ProxyAI与IDE的交互数据流
从数据流的角度看,ProxyAI在PyCharm中的工作流程可以形式化地描述为以下步骤:
步骤一(上下文采集) :插件通过IDE的PSI(Program Structure Interface)获取当前编辑器的语法树、光标位置、选中文本等信息,同时收集项目级别的上下文(如依赖关系、文件结构)。
步骤二(请求构造) :将采集到的上下文信息按照目标Provider所要求的API格式(通常为OpenAI Chat Completions格式)封装为HTTP请求,包含messages数组、model参数、temperature等超参数。
步骤三(推理调用) :通过HTTP客户端向配置的API端点发送请求,支持流式(streaming)和非流式两种响应模式。
步骤四(结果注入) :将模型返回的推理结果解析后,通过IDE的编辑器API注入到代码编辑器中——可以是行内补全、代码片段插入或对话面板展示。
3 OpenAI兼容接口协议:统一接入的技术基石
3.1 OpenAI兼容API的设计哲学
ProxyAI之所以能够灵活对接DeepSeek-V4-Flash、GLM-5.2等不同厂商的模型,其技术基础在于OpenAI兼容API协议的广泛采用。
OpenAI Compatible API可以理解为一种 “接口形状兼容” ——某个服务虽然不一定由OpenAI提供,但其HTTP路径、请求参数、返回结构均按照OpenAI API的格式来设计。这种兼容性设计使得开发者无需为每个模型服务重写调用代码,只需调整少量配置即可完成迁移。
从工程实践角度看,OpenAI API已经在事实上成为了应用程序与推理后端之间的标准接口——整个生态系统已经将API兼容性作为一种协调机制而收敛。这种标准化带来的核心价值包括:
- 可移植性(Portability) :开发者可以在不同的模型提供商之间自由切换
- 降低学习曲线:一套API规范适用于所有兼容服务
- 生态加速:工具链(如ProxyAI、LangChain、Continue等)可以无缝对接任何兼容服务
3.2 Chat Completions API的核心数据结构
OpenAI Chat Completions API是ProxyAI最常用的接口形态,其核心请求结构包含以下关键字段:
请求结构:
{
"model": "deepseek-v4-flash",
"messages": [
{"role": "system", "content": "系统提示词"},
{"role": "user", "content": "用户输入"}
],
"temperature": 0.7,
"max_tokens": 2048,
"stream": false
}
响应结构:
{
"id": "chatcmpl-xxx",
"object": "chat.completion",
"created": 1234567890,
"model": "deepseek-v4-flash",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "模型生成的文本"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 100,
"completion_tokens": 200,
"total_tokens": 300
}
}
流式响应(Streaming) 则通过Server-Sent Events(SSE)协议逐块返回增量内容,每个数据块的结构为:
delta i = { "choices" : [ { "delta" : { "content" : token i } } ] } \text{delta}_i = \{ \text{"choices"}: [\{ \text{"delta"}: \{ \text{"content"}: \text{token}_i \} \}] \} deltai={"choices":[{"delta":{"content":tokeni}}]}
其中 token i \text{token}_i tokeni表示第 i i i个增量token。流式响应能够显著改善用户体验,尤其适用于长文本生成场景。
3.3 兼容层实现的工程技术
AIGC Bar等聚合平台正是基于OpenAI兼容协议构建的 “兼容层” 。从技术实现角度看,这类兼容层通常包含以下核心组件:
请求路由与转换:兼容层接收符合OpenAI格式的请求后,根据请求中的model参数将请求路由到对应的上游模型服务。如果上游服务使用非OpenAI格式(如Anthropic的Claude API),兼容层还需要进行请求格式的双向转换。
认证与密钥管理:开发者使用AIGC Bar提供的统一API Key,兼容层在后台将其映射到各个上游模型服务所需的认证凭证。
计费与额度控制:兼容层在请求转发过程中记录token消耗,按照模型官方的计费口径(基于token数量)进行计费。
这种“中心辐射型(Hub-and-Spoke)”架构使得开发者可以通过同一套工程框架、同一套密钥管理、同一套账单/额度心智模型,稳定地连接到不同模型上。
4 AIGC Bar:多模型统一API入口的技术架构
4.1 兼容层设计的本质与价值
AIGC Bar作为一个多模型统一API入口平台,其核心定位并非“某一个模型的替代品”,而是 “模型入口的兼容层” 。具体而言,它在你和上游模型服务之间做了一个分发与适配层:你的请求先到达AIGC Bar,它再按你选择的模型或分组路由到对应的上游服务,然后把响应以你熟悉的协议返回给你。
这种架构设计的工程价值体现在以下维度:
| 维度 | 传统方式 | AIGC Bar兼容层方式 |
|---|---|---|
| 接入门槛 | 需分别注册各厂商、绑卡、配网络 | 一次注册,统一接入 |
| 多模型切换 | 需修改代码中的endpoint和认证 | 仅需修改model参数 |
| 密钥管理 | 多套密钥分散管理 | 统一密钥,按项目隔离 |
| 账单与成本 | 分散在各厂商控制台 | 统一控制台聚合查看 |
| 网络可用性 | 依赖各厂商网络状况 | 平台层做路由与容灾 |
4.2 令牌分组与权限管理
AIGC Bar通过 “令牌分组(Token Group)” 机制实现不同模型能力的权限管理与调用路由。分组的核心意义在于将令牌绑定到某一类上游能力或协议形态上。
对于本文关注的场景,OpenSource-MultiModal分组提供了GLM-5.2、Kimi-K2.6、Qwen3.5等开源多模态模型的调用入口。该分组面向需要进行多模型协作的开发者场景——通过统一的API接口按需调用不同模型构建智能体。
| 分组类型 | 典型用途 | 包含模型示例 |
|---|---|---|
| Free分组 | 免费测试与入门体验 | DeepSeek-V4-Flash等 |
| OpenSource-MultiModal分组 | 开源多模型智能体构建 | GLM-5.2、Kimi-K2.6、Qwen3.5 |
| CC分组 | 高性价比商业模型调用 | GPT系列、Claude系列等 |
5 GLM-5.2:长程任务时代的编程旗舰
5.1 模型架构与核心参数
GLM-5.2是智谱AI于2026年6月17日正式发布并开源的新一代旗舰模型。该模型采用744B总参数的MoE(混合专家)架构,每次token推理激活40B参数。模型支持1M token的上下文窗口,最大输出长度达128,000 token。
| 技术指标 | GLM-5.2参数 |
|---|---|
| 总参数 | 744B(MoE架构) |
| 激活参数/Token | 40B |
| 上下文窗口 | 1,000,000 tokens |
| 最大输出长度 | 128,000 tokens |
| 输入价格 | ¥8 / 1M tokens |
| 输出价格 | ¥28 / 1M tokens |
| 开源协议 | MIT License |
5.2 1M无损上下文与IndexShare架构
GLM-5.2的核心技术突破在于实现了真正可用的1M无损上下文。此前的1M上下文模型在超过数百K之后大多开始劣化,主要问题在于未同时增强Coding Agent环境及数据的情况下,单纯扩展到1M帮助有限。
GLM-5.2通过IndexShare架构解决了这一问题——在每四层稀疏注意力层之间复用同一个索引器(indexer),将1M上下文下的单位token FLOPs降低至2.9倍。这一架构创新使得模型能够在1M上下文中保持稳定的推理性能与生成质量。
在真实场景测试中,GLM-5.2成功处理了74万条服务器日志的根因分析,并能单次会话完成跨四份合同文档的条款冲突识别。模型可在一轮连续任务中处理88万以上token,自主完成从开发、联调、测试到打包上线的完整软件交付流程。
5.3 编程能力评测
GLM-5.2在多个权威编程基准测试中取得了领先表现:
| 评测基准 | GLM-5.2成绩 | 对比说明 |
|---|---|---|
| Code Arena | 1595分 | 全球可用模型第一 |
| FrontierSWE | 74.4分 | 介于Claude Opus 4.7与4.8之间 |
| GDPval-AA v2 | 1524分 | 与GPT-5.5(xhigh reasoning)平起平坐 |
在FrontierSWE、Terminal-Bench等多个权威评测中,GLM-5.2与当前海外最强的Claude Opus 4.8仅相差约1%–4%,是排名最高的开源模型。
5.4 国产算力生态与MIT开源协议
GLM-5.2的训练与线上推理均未依赖海外算力。发布首日即完成了与华为昇腾、平头哥、摩尔线程、寒武纪、昆仑芯、沐曦、海光、壁仞等八大国产算力平台的全适配。模型权重已在Hugging Face与ModelScope同步开源,遵循最高权限的MIT License,支持自由下载、部署与商用。vLLM、SGLang、transformers等主流推理框架已经支持GLM-5.2的推理部署。
6 PyCharm中ProxyAI集成DeepSeek-V4-Flash与GLM-5.2实战
6.1 环境准备与AIGC Bar注册
步骤一:注册AIGC Bar账号
访问AIGC Bar官方注册页面:AIGC bar
完成注册后登录控制台,在令牌管理页面创建新的API令牌。根据需求选择对应的分组:
- Free分组:可免费调用DeepSeek-V4-Flash等模型
- OpenSource-MultiModal分组:可调用GLM-5.2、Kimi-K2.6、Qwen3.5等开源多模态模型
步骤二:获取API密钥
创建令牌后,系统会生成一个API Key(形如sk-xxxxxxxxxxxxxxxx)。该密钥将作为ProxyAI连接AIGC Bar的认证凭证。
步骤三:PyCharm环境检查
确保PyCharm版本在2023.3或更高版本。建议使用PyCharm Professional 2025.1或更高版本以获得最佳插件兼容性。
6.2 安装与配置ProxyAI插件
第一步:安装ProxyAI插件
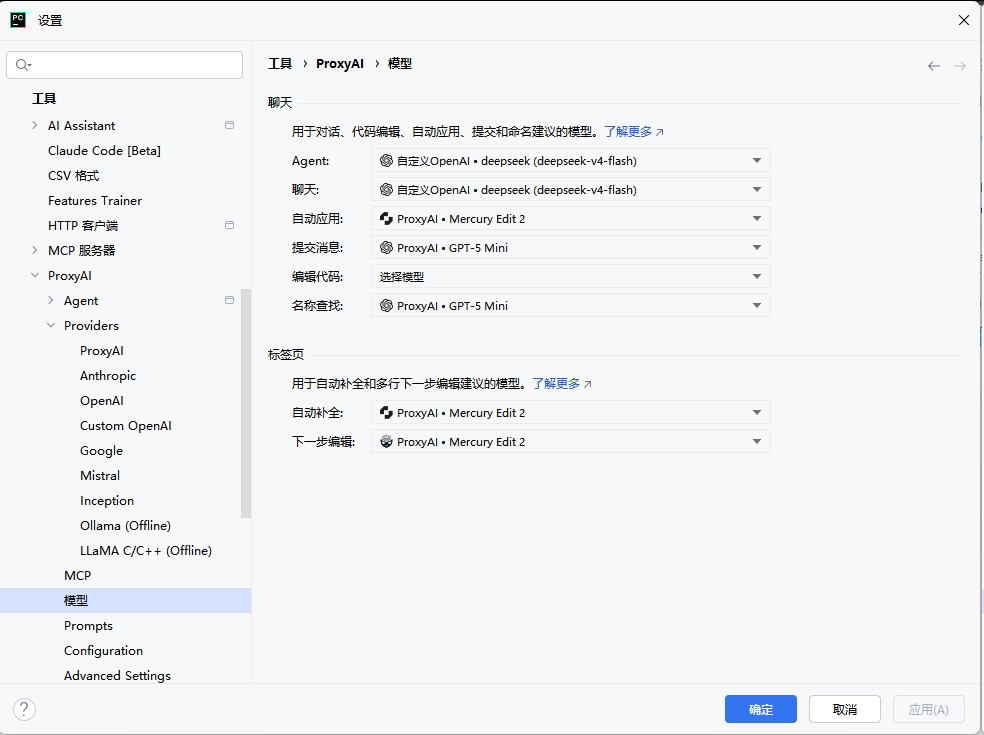
打开PyCharm,依次点击 File → Settings → Plugins,在插件市场中搜索 ProxyAI(部分版本显示为Proxy AI)并安装。安装完成后重启IDE。
第二步:配置Custom OpenAI Provider
- 进入
File→Settings→Tools→ProxyAI→Providers - 选择 Custom OpenAI 作为Provider类型
- 按照以下参数配置:
| 配置参数 | 填写内容 | 技术说明 |
|---|---|---|
| Preset template | OpenAI | 使用OpenAI Chat Completions协议格式 |
| Custom provider name | AIGC Bar(自定义) | 便于在IDE中识别 |
| API key | AIGC Bar创建的API Key | 统一认证凭证 |
| Chat Completion URL | https://api.aigc.bar/v1/chat/completions | OpenAI兼容端点 |
| Model参数 | deepseek-v4-flash 或 glm-5.2 | 指定调用的模型 |
第三步:验证连接
点击 Test 按钮验证配置是否正确。成功连接后,即可在PyCharm右侧边栏的ProxyAI面板中切换模型并开始使用。
6.3 Python代码直接调用方案
对于需要更精细控制或构建自定义智能体的场景,可以通过Python代码直接调用AIGC Bar API。
环境配置:
pip install openai
调用DeepSeek-V4-Flash示例:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_AIGC_BAR_API_KEY",
base_url="https://api.aigc.bar/v1"
)
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "你是一个专业的Python编程专家"},
{"role": "user", "content": "请解释Python装饰器的工作原理并给出示例"}
],
temperature=0.7,
max_tokens=2048,
stream=False
)
print(response.choices[0].message.content)
调用GLM-5.2示例(OpenSource-MultiModal分组) :
from openai import OpenAI
client = OpenAI(
api_key="YOUR_AIGC_BAR_API_KEY",
base_url="https://api.aigc.bar/v1"
)
response = client.chat.completions.create(
model="glm-5.2",
messages=[
{"role": "system", "content": "你是一个全栈开发专家,擅长代码审查与优化"},
{"role": "user", "content": "请对以下Python代码进行深度审查并给出优化方案"}
],
temperature=0.3,
max_tokens=4096
)
print(response.choices[0].message.content)
6.4 流式响应的工程实现
对于需要实时反馈的场景,流式响应是优化用户体验的关键技术。其实现原理基于Server-Sent Events(SSE)协议:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_AIGC_BAR_API_KEY",
base_url="https://api.aigc.bar/v1"
)
stream = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "写一个快速排序算法"}],
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
流式响应的核心数学原理在于,模型在自回归生成过程中,每一步解码产生一个概率分布:
P ( w t ∣ w 1 , w 2 , . . . , w t − 1 ) = Softmax ( W ⋅ h t + b ) P(w_t | w_1, w_2, ..., w_{t-1}) = \text{Softmax}(W \cdot h_t + b) P(wt∣w1,w2,...,wt−1)=Softmax(W⋅ht+b)
其中 h t h_t ht是Transformer解码器在时间步 t t t的隐藏状态, W W W和 b b b是输出层的权重矩阵和偏置。流式响应将每一步生成的 w t w_t wt逐块返回,而非等待完整序列 { w 1 , w 2 , . . . , w n } \{w_1, w_2, ..., w_n\} {w1,w2,...,wn}全部生成完毕后再一次性返回。
7 基于AIGC Bar的多模型智能体构建
7.1 LLM Agent的核心原理
智能体(Agent)是指能够自主感知环境、做出决策并执行动作的AI系统。在大模型语境下,智能体以大语言模型为核心控制器,通过调用外部工具(代码执行器、搜索引擎、数据库等)来完成复杂任务。
一个标准的LLM Agent系统包含以下核心组件:
- 规划模块(Planning) :将复杂任务分解为可执行的子任务序列
- 记忆模块(Memory) :维护短期上下文与长期知识
- 工具调用模块(Tool Use) :通过函数调用(Function Calling)机制与外部环境交互
GLM-5.2在长程Agent任务上表现尤为突出——能够自主完成从开发、联调、测试到打包上线的完整软件交付流程。
7.2 多模型协作的Agent架构
AIGC Bar的核心价值在于 “一次接入、多模型协作” 。通过统一的API接口,开发者可以按需调用DeepSeek-V4-Flash、GLM-5.2、Kimi-K2.6、Qwen3.5等多种模型构建智能体。
7.3 多模型智能体代码框架
以下是一个基于AIGC Bar API构建多模型智能体的工程化框架:
from openai import OpenAI
from typing import List, Dict, Any
import json
class MultiModelAgent:
def __init__(self, api_key: str, base_url: str = "https://api.aigc.bar/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
# 模型路由表:按任务类型映射到最优模型
self.model_routing = {
"planning": "deepseek-v4-flash", # 任务规划
"coding": "glm-5.2", # 代码生成(GLM-5.2专长)
"review": "glm-5.2", # 代码审查
"chat": "deepseek-v4-flash", # 实时对话(低成本高响应)
"reasoning": "deepseek-v4-flash" # 复杂推理
}
def chat(self, task_type: str, messages: List[Dict[str, str]],
temperature: float = 0.7, max_tokens: int = 2048) -> str:
"""统一调用接口,根据任务类型自动路由到最优模型"""
model_name = self.model_routing.get(task_type, "deepseek-v4-flash")
response = self.client.chat.completions.create(
model=model_name,
messages=messages,
temperature=temperature,
max_tokens=max_tokens
)
return response.choices[0].message.content
def plan_project(self, requirement: str) -> Dict[str, Any]:
"""使用规划模型分解项目需求"""
messages = [
{"role": "system", "content": "你是一个软件架构师,请将需求分解为可执行的开发任务"},
{"role": "user", "content": requirement}
]
plan_text = self.chat("planning", messages, temperature=0.5, max_tokens=4096)
# 解析规划文本为结构化任务列表
return {"plan": plan_text}
def generate_code(self, task_description: str) -> str:
"""使用GLM-5.2生成代码"""
messages = [
{"role": "system", "content": "你是一个资深软件工程师,请根据需求生成高质量的Python代码"},
{"role": "user", "content": task_description}
]
return self.chat("coding", messages, temperature=0.2, max_tokens=8192)
def review_code(self, code: str) -> str:
"""使用GLM-5.2进行代码审查"""
messages = [
{"role": "system", "content": "你是一个代码审查专家,请分析代码问题并给出改进建议"},
{"role": "user", "content": f"请审查以下代码:\n{code}"}
]
return self.chat("review", messages, temperature=0.3, max_tokens=4096)
# 使用示例
agent = MultiModelAgent(api_key="YOUR_AIGC_BAR_API_KEY")
plan = agent.plan_project("开发一个基于FastAPI的RESTful API后端,包含用户认证和CRUD操作")
print("项目规划:", plan)
code = agent.generate_code("实现一个带有JWT认证的FastAPI用户登录接口")
print("生成代码:", code)
7.4 对话服务与API调用的场景区分
需要特别强调的是,API调用主要面向开发者,用于在应用程序或IDE中集成大模型能力。对于普通用户而言,如果只是使用对话服务,直接访问各模型的官方网站即可获得更好的用户体验。
| 使用场景 | 推荐方式 | 技术说明 |
|---|---|---|
| PyCharm编程辅助 | AIGC Bar API + ProxyAI | 深度集成IDE,提升开发效率 |
| 智能体应用开发 | AIGC Bar API | 多模型统一调用,灵活路由 |
| 日常对话咨询 | 各模型官网 | 界面友好,功能完整 |
| 企业级应用集成 | AIGC Bar API | 统一管理,成本可控 |
8 总结与展望
本文从技术原理层面系统性地剖析了ProxyAI插件的工作机制、OpenAI兼容接口协议的设计哲学,以及AIGC Bar作为多模型统一API入口的架构价值。
ProxyAI通过JetBrains Plugin SDK的扩展点机制,实现了大模型推理能力与IDE编辑器环境的深度集成。其多Provider连接层设计使得开发者可以通过统一的配置接口接入OpenAI、Anthropic、Azure、Mistral等云服务商,以及Ollama等本地部署方案。
OpenAI兼容API协议作为事实上的行业标准接口,为AIGC Bar等聚合平台提供了技术基础。通过“中心辐射型”架构,AIGC Bar实现了同一套工程框架、同一套密钥管理下对DeepSeek-V4-Flash、GLM-5.2等多种模型的统一调用。
GLM-5.2作为智谱AI最新开源的旗舰模型,以744B总参数的MoE架构和1M无损上下文窗口,在Code Arena上取得全球可用模型第一的表现。其IndexShare架构将1M上下文下的单位token FLOPs降低至2.9倍,标志着国产大模型在编程与长程任务领域跻身世界前列。
展望未来,随着大模型能力的持续演进和IDE插件生态的不断丰富,AI原生开发将成为软件工程的新常态。开发者应当深入理解插件集成与API调用的技术原理,将大模型能力真正融入日常开发流程,实现生产力的质的飞跃。
参考文献
[1] ProxyAI Plugin for JetBrains IDEs. JetBrains Marketplace. https://plugins.jetbrains.com/plugin/21056-proxyai
[2] ProxyAI Official Documentation. https://docs.tryproxy.io/
[3] IDEA x DeepSeek:开发者效率革命的实践指南. 百度开发者中心. https://developer.baidu.com/article/detail.html?id=5592994
[4] AIGC Bar中的API站最新使用全指南. CSDN博客. https://blog.csdn.net/nmdbbzcl/article/details/155859825
[5] AIGC Bar API平台接入与工程化实践指南. ZeekLog. https://zeeklog.com/aigc-barzhong-de-apizhan-zui-xin-shi-yong-quan-zhi-nan-3
[6] GLM-5.2 Model Page. 智脑API. https://ai.360.com/open/zh/models/z-ai/glm-5.2
[7] 智谱上线并开源GLM-5.2模型. 北京市科学技术委员会. https://kw.beijing.gov.cn/xwdt/kcyx/xwdtyqqy/202606/t20260618_4705864.html
[8] GLM-5.2上线并开源:专注Coding与长程任务. 智谱AI官网. https://www.zhipuai.cn
[9] GLM-5.2 API | Together AI. https://www.together.ai
[10] OpenAI Compatible API 到底兼容什么?. 腾讯云. https://cloud.tencent.com


















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












