




PostgreSQL 流程—更新
概述
更新操作是DML操作中最复杂的一个,在PostgreSQL对更新的实现方式是“先插入,再删除”,所以在PostgreSQL中更新操作实际上包含了是数据库的所有常用操作:查询、插入、删除。简单来讲,PostgreSQL的更新操作有如下3个步骤:
- 根据查询条件获取满足条件的元组。
- 根据原始元组和更新字段创建新元组,并执行插入。
- 删除原始元组。
PostgreSQL对步骤1中查询的处理和普通查询完全一致,都是基于MVCC的查询。那么现在我们考虑三个场景。
场景1
假设有一账户,用balance表示其金额,当前balance值为100元。下面有两个事务分别向账户中存入100元,具体情况如下表。
| 时间 | 事务A | 事务B |
|---|---|---|
| T1 | 开启事务 | |
| T2 | 开启事务 | |
| T3 | 发起存款:update account set balance = balance+ 100; | |
| T4 | 发起存款:update account set balance = balance+ 100; | 完成存款:insert一条balance值为200的记录 |
| T5 | 事务快照:<事务B> | |
| T6 | 查询需要更新的元组 | 提交事务 |
| T7 | 完成存款 | |
| T8 | 提交事务 |
在上述场景中,我们要注意以下几个时间点:
-
T4
在T4时刻,事务B完成了update account set balance = balance+ 100;由于PostgreSQL的update操作是由insert + delete完成的,并且delete只会设置xmax,然后由MVCC来判断可见性。所以此时数据库中存在两条元组,balance分别为100和200。
-
T5
在T5事务A开始了update的第一个步骤,做一次事务快照,此时由于事务B还未提交,所以事务B存在于快照中。
-
T6
在T6事务A开始了update的查询操作,和普通查询一样,事务A会根据事务快照判断元组的可见性。由于事务B存在于事务快照中,所以更新后的元组对于事务A不可见,该查询会返回更新前的元组,即balance为100的元组。
-
T7
这一步非常关键,因为在这一步我们会真正执行修改操作,将balance的值加上100元,我们注意两点:
-
事务A和事务B由于修改了同一行元组,所以原则上是需要行锁的,在T6时事务B已经提交,所以T7时事务A并没有对元组加行锁(PostgreSQL只有发现元组可能已经被其他事务修改时才会加行锁,这一点会在后面说明)。
-
T6时,事务A依据MVCC查询到了修改前的元组,元组的balance为100。那么在做更新时我们应该如何更新?具体而言,我们应该更新事务A查询到了这条old tuple还是当前的new tuple,还有我们是应该使用old tuple的balance(值为100),还是应该使用new tuple的balance(值为200)?
其实这个两个问题就是所谓的更新丢失问题,也是接下来会重点阐述的问题,现在先给出结论:
由于old tuple实际已经被事务B删除了,并且该删除已经提交,所以如果事务A再去更新old tuple那么必然这个更新会丢失!所以显然不能更新old tuple,而应该更新new tuple。既然是更新new tuple,那么自然是在new tuple的balance上加上100,将balance的值更新的300,从另外一个角度上来看,如果采用old tuple的balance值,那么最终将会把balance的值更新为200,这也是更新丢失。
所以,所有的更新都应该在最新版本的tuple上执行,虽然在查询阶段可能会返回老版本的元组。
-
场景2
假设test表有一个字段id,id的初始值为1,考虑如下场景:
| 时间 | 事务A | 事务B |
|---|---|---|
| T1 | 开启事务 | |
| T2 | 开启事务 | |
| T3 | 发起更新:update test set id = id+1 where id = 1; | |
| T4 | 事务快照:<事务B> | 发起更新:update test set id = id+1 where id = 1; |
| T5 | 查询需要更新的元组 | 事务快照:<事务A> |
| T6 | 查询需要更新的元组 | |
| T7 | 执行更新 | |
| T8 | 事务提交 | |
| T9 | 执行更新 | |
| T10 | 事务提交 |
同样,我们对几个时间点进行说明:
-
T5,T6
由于事务B在T7时才执行更新,所以T5,T6时数据库只有一个版本的元组,元组id为1。那么事务A和事务B分别于T5和T6时刻查询到了这条id为1的元组,均满足where条件。
-
T7,T8
事务B对元组执行了更新并提交,此时数据库中多了一条id为2的new tuple。这种情况在多线程\多进程下很可能发生,由于进程调度,虽然事务A比事务B先发起,但事务B先执行了更新。
-
T9
此时,事务A对元组进行更新。此时考虑一个问题:事务A还可以更新这条元组么?从场景1中,我们得到一个结论更新操作必须更新new tuple。而此时new tuple的id为2,已经不满足id = 1的条件,所以事务A不会对执行更新操作。

场景3
假设test表有一个字段id,id的初始值为1,我们对场景2进行一下修改:
| 时间 | 事务A | 事务B |
|---|---|---|
| T1 | 开启事务 | |
| T2 | 开启事务 | |
| T3 | 发起更新:update test set id = id+1 where id = 2; | |
| T4 | 事务快照:<事务B> | 发起更新:update test set id = id+1 where id = 1; |
| T5 | 事务快照:<事务A> | |
| T6 | 查询需要更新的元组 | |
| T7 | 执行更新 | |
| T8 | 事务提交 | |
| T9 | 查询需要更新的元组 | |
| T10 | 执行更新 | |
| T11 | 事务提交 |
我们修改了事务A的查询条件,改为了where id = 2。事务A在T4时刻做的事务快照,此时事务B为活跃事务,所以事务A在T9进行查询时,虽然事务B的修改操作已经提交,但是new tuple对事务A不可见,事务A获取的是old tuple,显然old tuple不满足id = 2,所以不会对元组进行更新。
下面我们将从源代码的角度详细阐述PostgreSQL的更新流程,看看他是如何应对上述三个场景的。
更新主流程
更新操作相关函数的调用顺序为:ExecutePlan > ExecProcNode > ExecModifyTable。其中ExecModifyTable为更新操作的主要函数,该函数可以分为两个步骤:
- 调用ExecProcNode获取一条可见且合法的元组。
- 调用ExecUpdate函数执行更新操作。
源代码如下:
TupleTableSlot *
ExecModifyTable(ModifyTableState *node)
{
EState *estate = node->ps.state;
CmdType operation = node->operation;
ResultRelInfo *saved_resultRelInfo;
ResultRelInfo *resultRelInfo;
PlanState *subplanstate;
JunkFilter *junkfilter;
TupleTableSlot *slot;
TupleTableSlot *planSlot;
ItemPointer tupleid;
ItemPointerData tuple_ctid;
HeapTupleData oldtupdata;
HeapTuple oldtuple;
/*
* This should NOT get called during EvalPlanQual; we should have passed a
* subplan tree to EvalPlanQual, instead. Use a runtime test not just
* Assert because this condition is easy to miss in testing. (Note:
* although ModifyTable should not get executed within an EvalPlanQual
* operation, we do have to allow it to be initialized and shut down in
* case it is within a CTE subplan. Hence this test must be here, not in
* ExecInitModifyTable.)
*/
if (estate->es_epqTuple != NULL)
elog(ERROR, "ModifyTable should not be called during EvalPlanQual");
/*
* If we've already completed processing, don't try to do more. We need
* this test because ExecPostprocessPlan might call us an extra time, and
* our subplan's nodes aren't necessarily robust against being called
* extra times.
*/
if (node->mt_done)
return NULL;
/*
* On first call, fire BEFORE STATEMENT triggers before proceeding.
*/
if (node->fireBSTriggers)
{
fireBSTriggers(node);
node->fireBSTriggers = false;
}
/* Preload local variables */
resultRelInfo = node->resultRelInfo + node->mt_whichplan;
subplanstate = node->mt_plans[node->mt_whichplan];
junkfilter = resultRelInfo->ri_junkFilter;
/*
* es_result_relation_info must point to the currently active result
* relation while we are within this ModifyTable node. Even though
* ModifyTable nodes can't be nested statically, they can be nested
* dynamically (since our subplan could include a reference to a modifying
* CTE). So we have to save and restore the caller's value.
*/
saved_resultRelInfo = estate->es_result_relation_info;
estate->es_result_relation_info = resultRelInfo;
/*
* Fetch rows from subplan(s), and execute the required table modification
* for each row.
*/
for (;;)
{
/*
* Reset the per-output-tuple exprcontext. This is needed because
* triggers expect to use that context as workspace. It's a bit ugly
* to do this below the top level of the plan, however. We might need
* to rethink this later.
*/
ResetPerTupleExprContext(estate);
/* 步骤1:获取一条可见且合法的元组 */
planSlot = ExecProcNode(subplanstate);
if (TupIsNull(planSlot))
{
/* advance to next subplan if any */
node->mt_whichplan++;
if (node->mt_whichplan < node->mt_nplans)
{
resultRelInfo++;
subplanstate = node->mt_plans[node->mt_whichplan];
junkfilter = resultRelInfo->ri_junkFilter;
estate->es_result_relation_info = resultRelInfo;
EvalPlanQualSetPlan(&node->mt_epqstate, subplanstate->plan,
node->mt_arowmarks[node->mt_whichplan]);
continue;
}
else
break;
}
/*
* If resultRelInfo->ri_usesFdwDirectModify is true, all we need to do
* here is compute the RETURNING expressions.
*/
if (resultRelInfo->ri_usesFdwDirectModify)
{
Assert(resultRelInfo->ri_projectReturning);
/*
* A scan slot containing the data that was actually inserted,
* updated or deleted has already been made available to
* ExecProcessReturning by IterateDirectModify, so no need to
* provide it here.
*/
slot = ExecProcessReturning(resultRelInfo, NULL, planSlot);
estate->es_result_relation_info = saved_resultRelInfo;
return slot;
}
EvalPlanQualSetSlot(&node->mt_epqstate, planSlot);
slot = planSlot;
tupleid = NULL;
oldtuple = NULL;
if (junkfilter != NULL)
{
/*
* extract the 'ctid' or 'wholerow' junk attribute.
*/
if (operation == CMD_UPDATE || operation == CMD_DELETE)
{
char relkind;
Datum datum;
bool isNull;
relkind = resultRelInfo->ri_RelationDesc->rd_rel->relkind;
if (relkind == RELKIND_RELATION || relkind == RELKIND_MATVIEW)
{
datum = ExecGetJunkAttribute(slot,
junkfilter->jf_junkAttNo,
&isNull);
/* shouldn't ever get a null result... */
if (isNull)
elog(ERROR, "ctid is NULL");
tupleid = (ItemPointer) DatumGetPointer(datum);
tuple_ctid = *tupleid; /* be sure we don't free
* ctid!! */
tupleid = &tuple_ctid;
}
/*
* Use the wholerow attribute, when available, to reconstruct
* the old relation tuple.
*
* Foreign table updates have a wholerow attribute when the
* relation has an AFTER ROW trigger. Note that the wholerow
* attribute does not carry system columns. Foreign table
* triggers miss seeing those, except that we know enough here
* to set t_tableOid. Quite separately from this, the FDW may
* fetch its own junk attrs to identify the row.
*
* Other relevant relkinds, currently limited to views, always
* have a wholerow attribute.
*/
else if (AttributeNumberIsValid(junkfilter->jf_junkAttNo))
{
datum = ExecGetJunkAttribute(slot,
junkfilter->jf_junkAttNo,
&isNull);
/* shouldn't ever get a null result... */
if (isNull)
elog(ERROR, "wholerow is NULL");
oldtupdata.t_data = DatumGetHeapTupleHeader(datum);
oldtupdata.t_len =
HeapTupleHeaderGetDatumLength(oldtupdata.t_data);
ItemPointerSetInvalid(&(oldtupdata.t_self));
/* Historically, view triggers see invalid t_tableOid. */
oldtupdata.t_tableOid =
(relkind == RELKIND_VIEW) ? InvalidOid :
RelationGetRelid(resultRelInfo->ri_RelationDesc);
oldtuple = &oldtupdata;
}
else
Assert(relkind == RELKIND_FOREIGN_TABLE);
}
/*
* apply the junkfilter if needed.
*/
if (operation != CMD_DELETE)
slot = ExecFilterJunk(junkfilter, slot);
}
switch (operation)
{
case CMD_INSERT:
slot = ExecInsert(node, slot, planSlot,
node->mt_arbiterindexes, node->mt_onconflict,
estate, node->canSetTag);
break;
case CMD_UPDATE:
/* 步骤2:执行更新操作 */
slot = ExecUpdate(tupleid, oldtuple, slot, planSlot,
&node->mt_epqstate, estate, node->canSetTag);
break;
case CMD_DELETE:
slot = ExecDelete(tupleid, oldtuple, planSlot,
&node->mt_epqstate, estate, node->canSetTag);
break;
default:
elog(ERROR, "unknown operation");
break;
}
/*
* If we got a RETURNING result, return it to caller. We'll continue
* the work on next call.
*/
if (slot)
{
estate->es_result_relation_info = saved_resultRelInfo;
return slot;
}
}
/* Restore es_result_relation_info before exiting */
estate->es_result_relation_info = saved_resultRelInfo;
/*
* We're done, but fire AFTER STATEMENT triggers before exiting.
*/
fireASTriggers(node);
node->mt_done = true;
return NULL;
}
ExecProcNode
ExecProcNode函数我们在全表遍历时已经介绍过,该函数用于获取一条可见且合法的元组,但是在这里我们需要做一点扩展,因为ExecProcNode除了会返回元组,还会返回查询字段的值。例如:当前test表中id字段的值为1,我们做如下查询:
select id,id+1,id+10,id+100 from test;
ExecProcNode会返回TupleTableSlot类型的solt对象,solt中的tts_values成员就存放了上述select语句,针对当前元组计算出的查询结果:
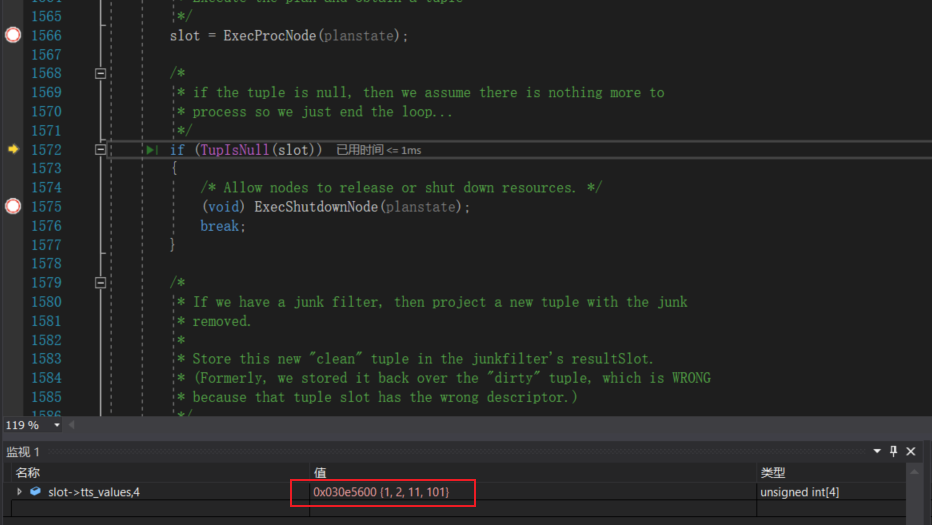
补充
其实更准确的说法是,在普通查询时ExecProcNode不返回合法元组,而只会返回查询结果,对上述select语句solt的tts_tuple成员为NULL。而对于聚合函数,ExecProcNode不返回查询结果,只返回合法元组。
而对于update操作而言,ExecProcNode返回的则是SET表达式的结果,例如:当前test表中id字段的值为1,我们做如下修改:
update test set id = id + 198;
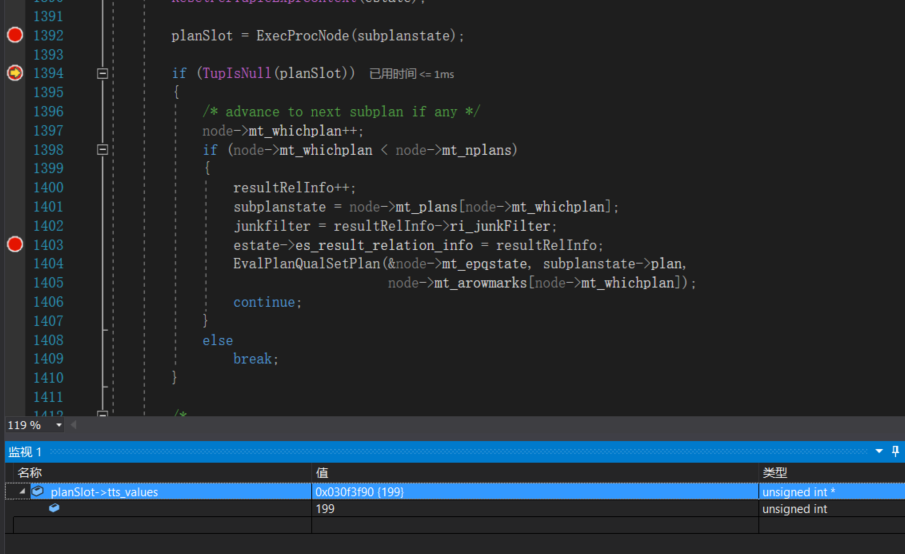
接下来我们来看看tts_values的值是如何计算出来的。我们首先来回顾下在全表遍历中讲到的ExecScan函数,该函数有如下3个步骤:
- 调用ExecScanFetch获取一条可见的元组,存放在slot->tts_tuple中。
- 调用ExecQual判断元组是否满足where条件。
- 调用ExecProject计算查询结果。
下面我们重点来看看ExecProject的实现。
ExecProject
ExecProject用于计算当前元组对应的查询结果,主要可以分为两个步骤:
-
调用slot_getsomeattrs函数从元组中获取字段的值。
slot_getsomeattrs函数中,真正实现字段值获取的函数为:slot_deform_tuple。
-
调用ExecTargetList,根据字段值计算表达式值。
代码如下:
TupleTableSlot *
ExecProject(ProjectionInfo *projInfo, ExprDoneCond *isDone)
{
TupleTableSlot *slot;
ExprContext *econtext;
int numSimpleVars;
/*
* sanity checks
*/
Assert(projInfo != NULL);
/*
* get the projection info we want
*/
slot = projInfo->pi_slot;
econtext = projInfo->pi_exprContext;
/* Assume single result row until proven otherwise */
if (isDone)
*isDone = ExprSingleResult;
/*
* Clear any former contents of the result slot. This makes it safe for
* us to use the slot's Datum/isnull arrays as workspace. (Also, we can
* return the slot as-is if we decide no rows can be projected.)
*/
ExecClearTuple(slot);
/*
* Force extraction of all input values that we'll need. The
* Var-extraction loops below depend on this, and we are also prefetching
* all attributes that will be referenced in the generic expressions.
* 步骤1:调用slot_getsomeattrs函数从元组中获取字段的值
*/
if (projInfo->pi_lastInnerVar > 0)
slot_getsomeattrs(econtext->ecxt_innertuple,
projInfo->pi_lastInnerVar);
if (projInfo->pi_lastOuterVar > 0)
slot_getsomeattrs(econtext->ecxt_outertuple,
projInfo->pi_lastOuterVar);
if (projInfo->pi_lastScanVar > 0)
slot_getsomeattrs(econtext->ecxt_scantuple,
projInfo->pi_lastScanVar);
/*
* Assign simple Vars to result by direct extraction of fields from source
* slots ... a mite ugly, but fast ...
*/
numSimpleVars = projInfo->pi_numSimpleVars;
if (numSimpleVars > 0)
{
Datum *values = slot->tts_values;
bool *isnull = slot->tts_isnull;
int *varSlotOffsets = projInfo->pi_varSlotOffsets;
int *varNumbers = projInfo->pi_varNumbers;
int i;
if (projInfo->pi_directMap)
{
/* especially simple case where vars go to output in order */
for (i = 0; i < numSimpleVars; i++)
{
char *slotptr = ((char *) econtext) + varSlotOffsets[i];
TupleTableSlot *varSlot = *((TupleTableSlot **) slotptr);
int varNumber = varNumbers[i] - 1;
values[i] = varSlot->tts_values[varNumber];
isnull[i] = varSlot->tts_isnull[varNumber];
}
}
else
{
/* we have to pay attention to varOutputCols[] */
int *varOutputCols = projInfo->pi_varOutputCols;
for (i = 0; i < numSimpleVars; i++)
{
char *slotptr = ((char *) econtext) + varSlotOffsets[i];
TupleTableSlot *varSlot = *((TupleTableSlot **) slotptr);
int varNumber = varNumbers[i] - 1;
int varOutputCol = varOutputCols[i] - 1;
values[varOutputCol] = varSlot->tts_values[varNumber];
isnull[varOutputCol] = varSlot->tts_isnull[varNumber];
}
}
}
/*
* If there are any generic expressions, evaluate them. It's possible
* that there are set-returning functions in such expressions; if so and
* we have reached the end of the set, we return the result slot, which we
* already marked empty.
*/
if (projInfo->pi_targetlist)
{
/* 步骤2:调用ExecTargetList,根据字段值计算表达式值 */
if (!ExecTargetList(projInfo->pi_targetlist,
slot->tts_tupleDescriptor,
econtext,
slot->tts_values,
slot->tts_isnull,
projInfo->pi_itemIsDone,
isDone))
return slot; /* no more result rows, return empty slot */
}
/*
* Successfully formed a result row. Mark the result slot as containing a
* valid virtual tuple.
*/
return ExecStoreVirtualTuple(slot);
}
ExecUpdate
当获取了需要修改的元组,以及修改的字段值后,就可以调用ExecUpdate执行修改操作了。ExecUpdate的实现比较复杂本文开篇在概述部分介绍的三种场景的处理也在ExecUpdate中完成。为了简化描述,我们先不考虑前面的几种特殊场景,只考虑最简单的更新。如此,ExecUpdate可以概括为两个步骤:
-
调用ExecMaterializeSlot组装new tuple。
该函数与插入时构建插入元组使用的是同一个函数。
-
调用heap_update执行更新操作。
源代码如下:
static TupleTableSlot *
ExecUpdate(ItemPointer tupleid,
HeapTuple oldtuple,
TupleTableSlot *slot,
TupleTableSlot *planSlot,
EPQState *epqstate,
EState *estate,
bool canSetTag)
{
HeapTuple tuple;
ResultRelInfo *resultRelInfo;
Relation resultRelationDesc;
HTSU_Result result;
HeapUpdateFailureData hufd;
List *recheckIndexes = NIL;
/*
* abort the operation if not running transactions
*/
if (IsBootstrapProcessingMode())
elog(ERROR, "cannot UPDATE during bootstrap");
/*
* get the heap tuple out of the tuple table slot, making sure we have a
* writable copy
* 步骤1:调用ExecMaterializeSlot组装new tuple
*/
tuple = ExecMaterializeSlot(slot);
/*
* get information on the (current) result relation
*/
resultRelInfo = estate->es_result_relation_info;
resultRelationDesc = resultRelInfo->ri_RelationDesc;
/* BEFORE ROW UPDATE Triggers */
if (resultRelInfo->ri_TrigDesc &&
resultRelInfo->ri_TrigDesc->trig_update_before_row)
{
slot = ExecBRUpdateTriggers(estate, epqstate, resultRelInfo,
tupleid, oldtuple, slot);
if (slot == NULL) /* "do nothing" */



















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










