



3.2.9 高斯混合
import numpy as np
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture
from matplotlib.colors import LogNorm
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# ----------------------------
# 1. 生成模拟数据(三个高斯分布混合)
# ----------------------------
np.random.seed(42) # 设置随机种子,保证结果可复现
# 三个高斯分布的参数:均值(mean)、协方差(cov)、样本数量
params = [
{'mean': [0, 0], 'cov': [[1, 0.5], [0.5, 2]], 'size': 300}, # 第一个高斯分布
{'mean': [5, 5], 'cov': [[2, -0.3], [-0.3, 1]], 'size': 400}, # 第二个高斯分布
{'mean': [8, 2], 'cov': [[1.5, 0], [0, 1.5]], 'size': 300} # 第三个高斯分布(圆形)
]
# 生成每个高斯分布的样本并合并
X = []
for p in params:
x = np.random.multivariate_normal(mean=p['mean'], cov=p['cov'], size=p['size'])
X.append(x)
X = np.vstack(X) # 合并为 (1000, 2) 的数组(1000个样本,2个特征)
# ----------------------------
# 2. 用GMM模型拟合数据
# ----------------------------
n_components = 3 # 已知混合成分数量为3
gmm = GaussianMixture(n_components=n_components, random_state=42)
gmm.fit(X) # 训练模型
# 查看模型学习到的参数(与真实参数对比)
print("学习到的均值(means):")
print(gmm.means_)
print("\n学习到的协方差(covariances):")
print(gmm.covariances_)
print("\n学习到的混合权重(weights):")
print(gmm.weights_)
# ----------------------------
# 3. 可视化结果
# ----------------------------
plt.figure(figsize=(12, 5))
# 子图1:原始数据散点图
plt.subplot(121)
plt.scatter(X[:, 0], X[:, 1], s=10, alpha=0.6, c='gray')
plt.title('原始混合数据(3个高斯分布)')
plt.xlabel('特征1')
plt.ylabel('特征2')
# 子图2:GMM拟合结果(决策边界+概率密度)
plt.subplot(122)
# 生成网格数据用于绘制密度图
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
Z = -gmm.score_samples(np.c_[xx.ravel(), yy.ravel()]) # 计算负对数概率(用于等高线)
Z = Z.reshape(xx.shape)
# 绘制等高线(概率密度)
plt.contourf(xx, yy, Z, norm=LogNorm(vmin=1.0, vmax=1000.0),
levels=np.logspace(0, 3, 10), cmap='viridis', alpha=0.5)
plt.contour(xx, yy, Z, norm=LogNorm(vmin=1.0, vmax=1000.0),
levels=np.logspace(0, 3, 10), colors='black', linewidths=1)
# 用不同颜色标记模型预测的聚类结果
labels = gmm.predict(X) # 预测每个样本属于哪个高斯成分
plt.scatter(X[:, 0], X[:, 1], s=10, c=labels, cmap='tab10', alpha=0.6)
# 标记每个高斯成分的均值中心
plt.scatter(gmm.means_[:, 0], gmm.means_[:, 1], s=100, marker='X',
c='red', label='拟合的均值中心')
plt.title('GMM拟合结果(3个成分)')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.legend()
plt.tight_layout()
plt.show()
绘图如下:
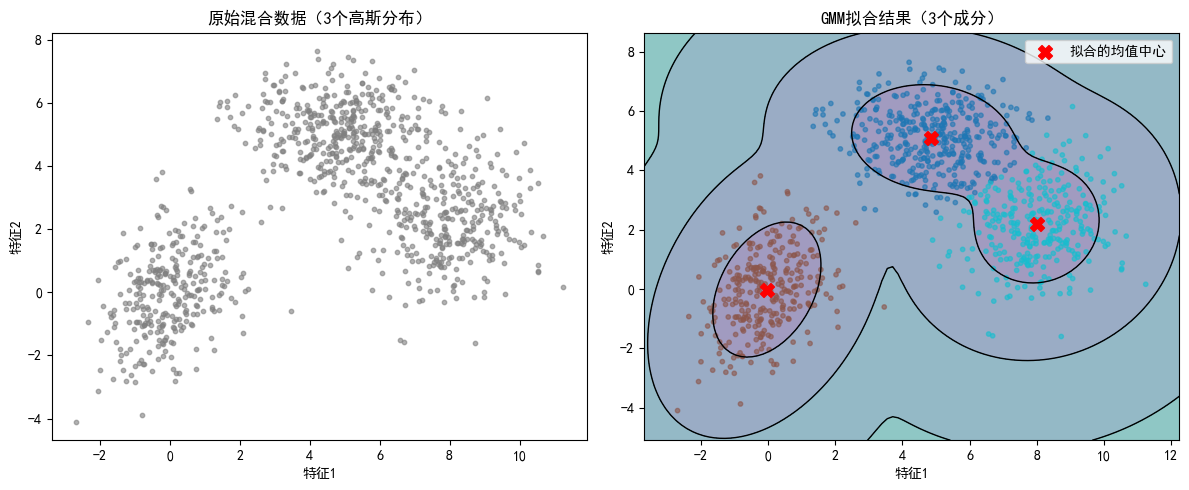
3.3 周期变量
米塞斯分布(von Mises distribution)是一种专门用于描述圆形数据(角度数据) 的概率分布,类似于线性数据中的正态分布。由于角度具有周期性(如 0° 与 360° 是同一个方向,-π 与 π 等价),传统的正态分布无法处理这种周期性,而米塞斯分布通过引入周期性假设,成为分析方向数据(如风向、动物运动方向、时钟时间、罗盘角度等)的核心工具。
1. 适用场景
当数据是角度或方向(取值范围为 0 到 2π,或 -π 到 π),且具有周期性时,米塞斯分布是最佳选择。例如:
- 气象学中记录的风向(0° 到 360°);
- 生物学中动物的运动方向;
- 工业中机械零件的旋转角度误差。
2. 概率密度函数(PDF)
米塞斯分布的概率密度函数为:
f(θ;μ,κ)=2πI0(κ)1exp(κcos(θ−μ))
其中:
- θ 是角度(自变量,范围通常为 [0,2π) 或 [−π,π));
- μ 是均值方向(location parameter):分布的 “中心方向”,类似正态分布的均值;
- κ 是浓度参数(concentration parameter):控制分布的集中程度(κ>0);
- I0(κ) 是修正的第一类零阶贝塞尔函数(用于归一化,确保分布在 [0,2π) 上的积分等于 1)。
3. 核心参数的意义
- 均值方向 μ:决定分布的峰值位置(最可能出现的角度)。例如,若 μ=π/2(90°),则数据主要集中在 “正上方” 方向。
- 浓度参数 κ:
- κ 越大,分布越集中在 μ 附近(类似正态分布的小标准差);
- κ→0 时,分布趋近于均匀分布(所有角度出现的概率相近)。
4. 与正态分布的对比
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import vonmises # 米塞斯分布工具
from scipy.special import i0 # 修正的零阶贝塞尔函数
import matplotlib.gridspec as gridspec
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
# 1. 定义真实参数并生成模拟数据
np.random.seed(42) # 固定随机种子,确保结果可复现
mu_true = np.pi / 4 # 真实均值方向:45°(东北方向)
kappa_true = 3 # 真实浓度参数:中等集中
n_samples = 500 # 样本量
# 生成米塞斯分布样本(scipy中vonmises的loc参数为mu,kappa为浓度)
samples = vonmises.rvs(kappa=kappa_true, loc=mu_true, size=n_samples)
# 将角度转换到[0, 2π)范围(方便可视化)
samples = (samples + 2 * np.pi) % (2 * np.pi)
# 2. 用米塞斯分布拟合样本数据,估计参数
# vonmises.fit返回(浓度参数, 均值方向, 0),最后一个参数为尺度(米塞斯分布固定为1)
kappa_fit, mu_fit, _ = vonmises.fit(samples)
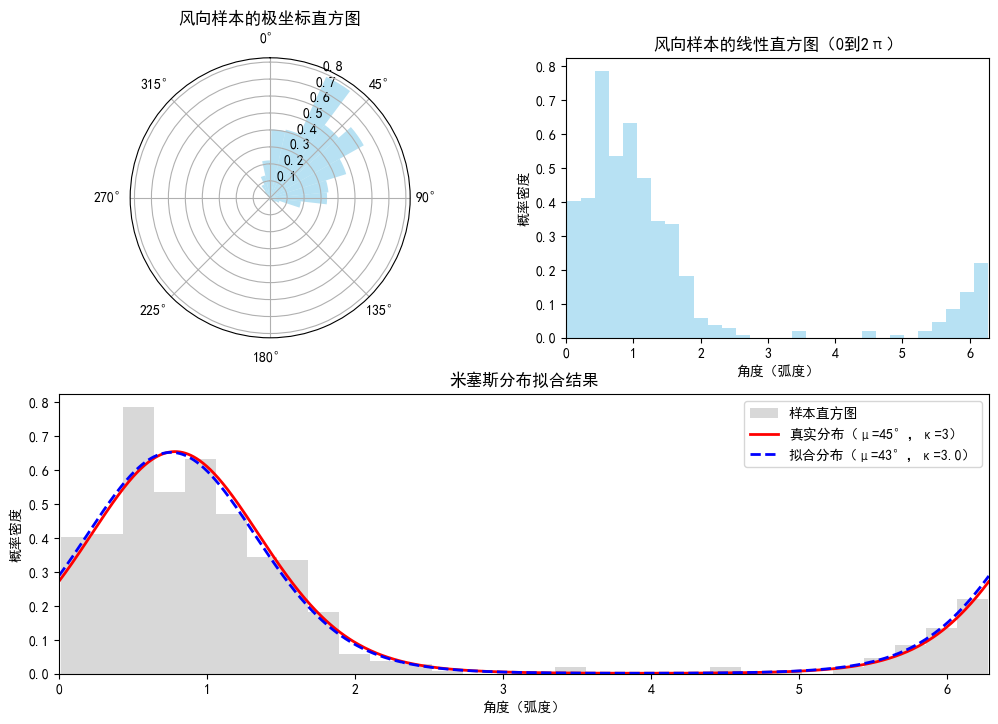
print(f"真实均值方向:{mu_true:.2f} 弧度({np.rad2deg(mu_true):.1f}°)")
print(f"拟合均值方向:{mu_fit:.2f} 弧度({np.rad2deg(mu_fit):.1f}°)")
print(f"真实浓度参数:{kappa_true}")
print(f"拟合浓度参数:{kappa_fit:.2f}")
# 3. 可视化结果
fig = plt.figure(figsize=(12, 8))
gs = gridspec.GridSpec(2, 2) # 2行2列布局
# 子图1:原始样本的直方图(极坐标,展示风向分布)
ax1 = fig.add_subplot(gs[0, 0], polar=True) # 极坐标图
ax1.hist(samples, bins=30, density=True, alpha=0.6, color='skyblue')
ax1.set_title('风向样本的极坐标直方图')
ax1.set_theta_zero_location('N') # 0°在北方(符合风向习惯)
ax1.set_theta_direction(-1) # 顺时针方向为正(符合风向习惯)
# 子图2:原始样本的线性直方图(0到2π)
ax2 = fig.add_subplot(gs[0, 1])
ax2.hist(samples, bins=30, density=True, alpha=0.6, color='skyblue')
ax2.set_xlabel('角度(弧度)')
ax2.set_ylabel('概率密度')
ax2.set_title('风向样本的线性直方图(0到2π)')
ax2.set_xlim(0, 2*np.pi)
# 子图3:拟合的米塞斯分布曲线(与样本对比)
ax3 = fig.add_subplot(gs[1, :]) # 跨两列
theta = np.linspace(0, 2*np.pi, 1000) # 角度网格
# 计算真实分布的PDF
pdf_true = vonmises.pdf(theta, kappa=kappa_true, loc=mu_true)
# 计算拟合分布的PDF
pdf_fit = vonmises.pdf(theta, kappa=kappa_fit, loc=mu_fit)
# 绘制直方图(样本分布)
ax3.hist(samples, bins=30, density=True, alpha=0.3, color='gray', label='样本直方图')
# 绘制真实分布
ax3.plot(theta, pdf_true, 'r-', linewidth=2, label=f'真实分布(μ={np.rad2deg(mu_true):.0f}°,κ={kappa_true})')
# 绘制拟合分布
ax3.plot(theta, pdf_fit, 'b--', linewidth=2, label=f'拟合分布(μ={np.rad2deg(mu_fit):.0f}°,κ={kappa_fit:.1f})')
ax3.set_xlabel('角度(弧度)')
ax3.set_ylabel('概率密度')
ax3.set_title('米塞斯分布拟合结果')
ax3.set_xlim(0, 2*np.pi)
ax3.legend()
# 4. 额外:展示不同浓度参数κ对分布的影响
fig2 = plt.figure(figsize=(10, 6))
theta = np.linspace(0, 2*np.pi, 1000)
mus = [np.pi/4] * 3 # 固定均值方向为45°
kappas = [0.5, 3, 10] # 不同浓度参数(从小到大)
colors = ['green', 'blue', 'red']
labels = [f'κ={k}(分散)' if k==0.5 else f'κ={k}(集中)' if k==10 else f'κ={k}(中等)' for k in kappas]
for mu, kappa, color, label in zip(mus, kappas, colors, labels):
pdf = vonmises.pdf(theta, kappa=kappa, loc=mu)
plt.plot(theta, pdf, color=color, linewidth=2, label=label)
plt.xlabel('角度(弧度)')
plt.ylabel('概率密度')
plt.title('不同浓度参数κ下的米塞斯分布')
plt.xlim(0, 2*np.pi)
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
| 特性 | 正态分布(线性数据) | 米塞斯分布(圆形数据) |
|---|---|---|
| 数据范围 | (−∞,+∞) | [0,2π)(周期性) |
| 核心参数 | 均值 μ、标准差 σ | 均值方向 μ、浓度 κ |
| 集中程度 | σ 越小越集中 | κ 越大越集中 |
| 归一化方式 | 高斯函数积分 | 贝塞尔函数 I0(κ) 归一化 |
3.4 指数分布
1. 定义:统一的数学形式
指数族分布的概率密度函数(或概率质量函数)可以写成以下标准形式:
p(x;η)=h(x)exp(ηT⋅T(x)−A(η))
其中各部分的含义:
| 符号 | 名称 | 含义 |
|---|---|---|
| x | 随机变量 | 可以是标量或向量(如样本数据) |
| η | 自然参数(natural parameter) | 分布的核心参数(可能是向量),不同分布的η形式不同 |
| T(x) | 充分统计量(sufficient statistic) | 对数据的 “概括”,包含了估计η所需的全部信息(如样本均值、总和等) |
| A(η) | 对数配分函数(log partition function) | 归一化常数,确保分布的积分(或求和)为 1,A(η)=log(∫h(x)exp(ηTT(x))dx) |
| h(x) | 基底测度(base measure) | 与参数无关的函数,决定了分布的 “基底” 形态(如连续 / 离散) |
2. 核心性质
指数族的统一形式带来了许多优良性质,使其在统计和机器学习中广泛应用:
- 充分统计量:T(x)包含了估计参数所需的全部信息,无需保留原始数据(简化计算);
- 最大熵:在给定充分统计量的期望约束下,指数族分布是 “最不确定”(熵最大)的分布,符合 “无偏假设”;
- 共轭先验:指数族分布的共轭先验仍属于指数族,简化贝叶斯推断中的后验计算;
- 广义线性模型(GLM):GLM 的核心是将目标变量的分布假设为指数族,通过线性预测器连接自然参数与特征。
3. 常见的指数族分布
几乎所有常用分布都属于指数族,以下是几个典型例子:
| 分布 | 随机变量x | 自然参数η | 充分统计量T(x) | 对数配分函数A(η) | 基底测度h(x) |
|---|---|---|---|---|---|
| 伯努利分布 | x∈{0,1} | η=log(1−pp)(logit 变换) | T(x)=x | A(η)=log(1+eη) | h(x)=1(离散) |
| 正态分布(σ2已知) | x∈R | η=σ2μ | T(x)=x | A(η)=2σ2η2 | h(x)=2πσ21 |
| 泊松分布 | x∈{0,1,2,...} | η=log(λ) | T(x)=x | A(η)=eη |
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
# 1. 验证伯努利分布属于指数族
def bernoulli_pdf(x, p):
"""伯努利分布的概率质量函数(原始形式):P(x; p) = p^x (1-p)^(1-x)"""
return p**x * (1 - p)**(1 - x)
def bernoulli_exponential_form(x, eta):
"""伯努利分布的指数族形式:h(x) * exp(eta*T(x) - A(eta))"""
h = 1 # 基底测度
T = x # 充分统计量
A = np.log(1 + np.exp(eta)) # 对数配分函数
return h * np.exp(eta * T - A)
# 验证两种形式等价(p与eta的转换:eta = log(p/(1-p)) → p = 1/(1 + exp(-eta)))
p_true = 0.3 # 真实成功概率
eta_true = np.log(p_true / (1 - p_true)) # 对应的自然参数
x_test = [0, 1] # 伯努利变量的可能取值
print("验证两种形式等价:")
for x in x_test:
p1 = bernoulli_pdf(x, p_true)
p2 = bernoulli_exponential_form(x, eta_true)
print(f"x={x}:原始形式={p1:.4f},指数族形式={p2:.4f}(误差={abs(p1-p2):.8f})")
# 2. 生成伯努利分布数据并估计参数
np.random.seed(42)
n_samples = 1000 # 样本量
data = np.random.binomial(n=1, p=p_true, size=n_samples) # 生成伯努利样本(0或1)
# 方法1:通过充分统计量直接估计(解析解)
# 伯努利分布的充分统计量T(x)=x,其期望E[T(x)] = p = 样本均值
p_hat = np.mean(data) # 样本均值即p的极大似然估计
eta_hat = np.log(p_hat / (1 - p_hat)) # 转换为自然参数
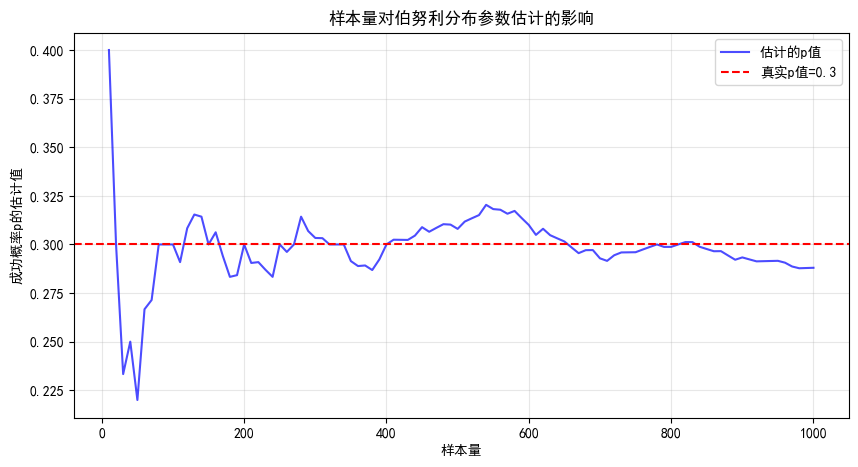
print(f"\n样本量={n_samples}时的估计结果:")
print(f"真实p={p_true},估计p={p_hat:.4f}")
print(f"真实eta={eta_true:.4f},估计eta={eta_hat:.4f}")
# 方法2:通过最大化对数似然函数估计(数值解,验证解析解)
def neg_log_likelihood(eta, data):
"""负对数似然函数(需要最小化)"""
A = np.log(1 + np.exp(eta)) # 对数配分函数
log_likelihood = np.sum(eta * data - A) # 对数似然总和(指数族形式)
return -log_likelihood # 返回负值,用于minimize
# 初始猜测值
eta_init = 0.0
# 最小化负对数似然
result = minimize(neg_log_likelihood, eta_init, args=(data,))
eta_hat_num = result.x[0]
p_hat_num = 1 / (1 + np.exp(-eta_hat_num)) # 转换回p
print(f"数值优化估计eta={eta_hat_num:.4f},p={p_hat_num:.4f}(与解析解一致)")
# 3. 可视化:样本量对参数估计的影响
sample_sizes = np.arange(10, 1001, 10) # 不同样本量(10到1000)
p_estimates = []
for n in sample_sizes:
data_subset = data[:n] # 取前n个样本
p_est = np.mean(data_subset)
p_estimates.append(p_est)
plt.figure(figsize=(10, 5))
plt.plot(sample_sizes, p_estimates, 'b-', alpha=0.7, label='估计的p值')
plt.axhline(y=p_true, color='r', linestyle='--', label=f'真实p值={p_true}')
plt.xlabel('样本量')
plt.ylabel('成功概率p的估计值')
plt.title('样本量对伯努利分布参数估计的影响')
plt.legend()
plt.grid(alpha=0.3)
plt.show()
# 4. 可视化:对数配分函数A(eta)与均值的关系
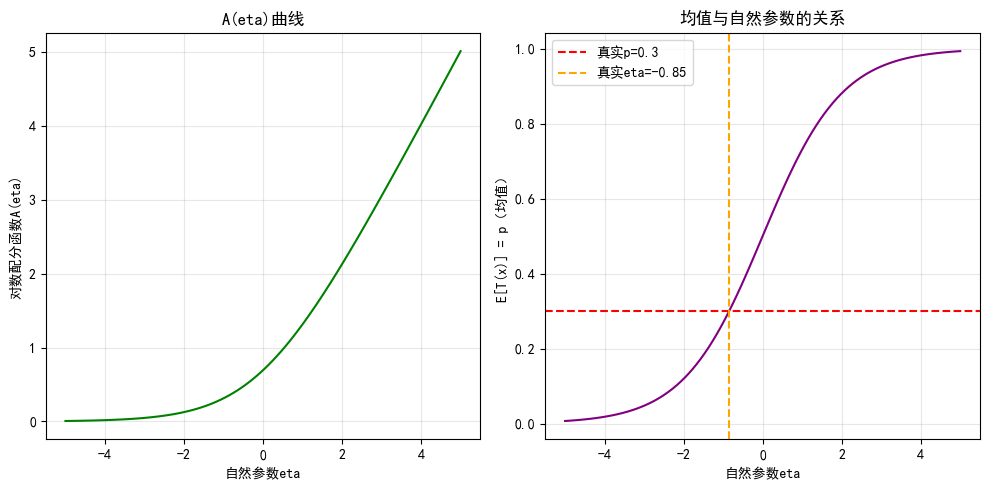
# 指数族中,A(eta)的导数 = E[T(x)](充分统计量的期望)
etas = np.linspace(-5, 5, 100) # 自然参数范围
A_values = np.log(1 + np.exp(etas)) # 对数配分函数
mean_values = np.exp(etas) / (1 + np.exp(etas)) # E[T(x)] = dA/deta = p(伯努利的均值)
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.plot(etas, A_values, 'g-')
plt.xlabel('自然参数eta')
plt.ylabel('对数配分函数A(eta)')
plt.title('A(eta)曲线')
plt.grid(alpha=0.3)
plt.subplot(122)
plt.plot(etas, mean_values, 'purple')
plt.axhline(y=p_true, color='r', linestyle='--', label=f'真实p={p_true}')
plt.axvline(x=eta_true, color='orange', linestyle='--', label=f'真实eta={eta_true:.2f}')
plt.xlabel('自然参数eta')
plt.ylabel('E[T(x)] = p(均值)')
plt.title('均值与自然参数的关系')
plt.legend()
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
验证两种形式等价: x=0:原始形式=0.7000,指数族形式=0.7000(误差=0.00000000) x=1:原始形式=0.3000,指数族形式=0.3000(误差=0.00000000) 样本量=1000时的估计结果: 真实p=0.3,估计p=0.2880 真实eta=-0.8473,估计eta=-0.9051 数值优化估计eta=-0.9051,p=0.2880(与解析解一致)
3.5 非参数方法
3.5.2 核密度
1. 核心思想
核密度估计的本质是:用一系列 “核函数” 对每个样本点进行 “扩散”,再将所有扩散结果叠加,得到平滑的密度曲线。
- 想象每个样本点是一个 “热源”,核函数是 “热量扩散的方式”,带宽(bandwidth)是 “扩散范围”;
- 最终的密度曲线就是所有热源扩散后的总热量分布,样本越密集的区域,密度值越高。
2. 数学公式
对于一组样本 x1,x2,...,xn,核密度估计的概率密度函数为:
f^(x)=n⋅h1∑i=1nK(hx−xi)
其中:
- f^(x):估计的概率密度函数在 x 处的值;
- n:样本量;
- h:带宽(bandwidth,也称为平滑参数),控制核函数的扩散范围(关键参数);
- K(⋅):核函数(满足积分等于 1 的非负函数,用于描述单个样本的扩散方式)。
3. 核函数(Kernel)
核函数是 KDE 的 “扩散规则”,常见的核函数包括:
- 高斯核(Gaussian kernel):最常用,形状为正态分布曲线,K(u)=2π1exp(−2u2);
- 均匀核(Uniform kernel):在区间 [−1,1] 内为常数,K(u)=21⋅I(∣u∣≤1)(I 为指示函数);
- Epanechnikov 核:抛物线形状,K(u)=43(1−u2)⋅I(∣u∣≤1)。
实际应用中,高斯核因平滑性好、计算方便而最常用。
4. 带宽(Bandwidth)的影响
带宽 h 是 KDE 中最重要的参数,直接决定密度曲线的平滑程度:
- 带宽太小(h 过小):曲线过于 “尖锐”,会放大噪声(过拟合),呈现很多不必要的波动;
- 带宽太大(h 过大):曲线过于 “平滑”,会掩盖数据的真实分布特征(如多峰结构),导致欠拟合;
- 最优带宽:需平衡偏差和方差,通常通过交叉验证(如最小化均方误差)自动选择(多数工具库默认提供最优带宽估计)。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KernelDensity # scikit-learn的KDE工具
from scipy.stats import norm # 用于生成模拟数据
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False
# 1. 生成模拟数据(两个正态分布的混合,体现多峰特性)
np.random.seed(42) # 固定随机种子
n_samples = 500 # 样本量
# 生成两个正态分布的样本(均值分别为2和7,标准差分别为1和1.5)
sample1 = norm.rvs(loc=2, scale=1, size=int(n_samples*0.6)) # 60%的样本来自第一个分布
sample2 = norm.rvs(loc=7, scale=1.5, size=int(n_samples*0.4)) # 40%的样本来自第二个分布
data = np.concatenate([sample1, sample2]) # 合并为混合数据
# 2. 核密度估计(KDE)拟合
# 生成用于计算密度的网格(覆盖数据范围)
x_grid = np.linspace(data.min() - 1, data.max() + 1, 1000) # 1000个点的连续网格
# 定义不同带宽(对比效果)
bandwidths = [0.1, 1.0, 3.0] # 小带宽、适中带宽、大带宽
kde_results = []
for h in bandwidths:
# 初始化KDE模型:使用高斯核,指定带宽
kde = KernelDensity(kernel='gaussian', bandwidth=h)
# 拟合数据(注意:sklearn要求输入为二维数组,需reshape)
kde.fit(data.reshape(-1, 1))
# 计算网格上的密度值(返回的是对数密度,需指数转换为真实密度)
log_density = kde.score_samples(x_grid.reshape(-1, 1))
density = np.exp(log_density)
kde_results.append(density)
# 3. 可视化结果(对比直方图与不同带宽的KDE曲线)
plt.figure(figsize=(12, 6))
# 绘制直方图(作为参考, bins控制分箱数)
plt.hist(data, bins=30, density=True, alpha=0.3, color='gray', label='数据直方图')
# 绘制不同带宽的KDE曲线
colors = ['red', 'blue', 'green']
labels = [f'KDE (带宽h={h})' for h in bandwidths]
for density, h, color, label in zip(kde_results, bandwidths, colors, labels):
plt.plot(x_grid, density, color=color, linewidth=2, label=label)
# 标记两个真实分布的均值(辅助理解)
plt.axvline(x=2, color='black', linestyle='--', alpha=0.5, label='真实分布均值')
plt.axvline(x=7, color='black', linestyle='--', alpha=0.5)
# 图表设置
plt.xlabel('数据值')
plt.ylabel('概率密度')
plt.title('核密度估计(KDE)与不同带宽的效果对比')
plt.legend()
plt.grid(alpha=0.3)
plt.show()
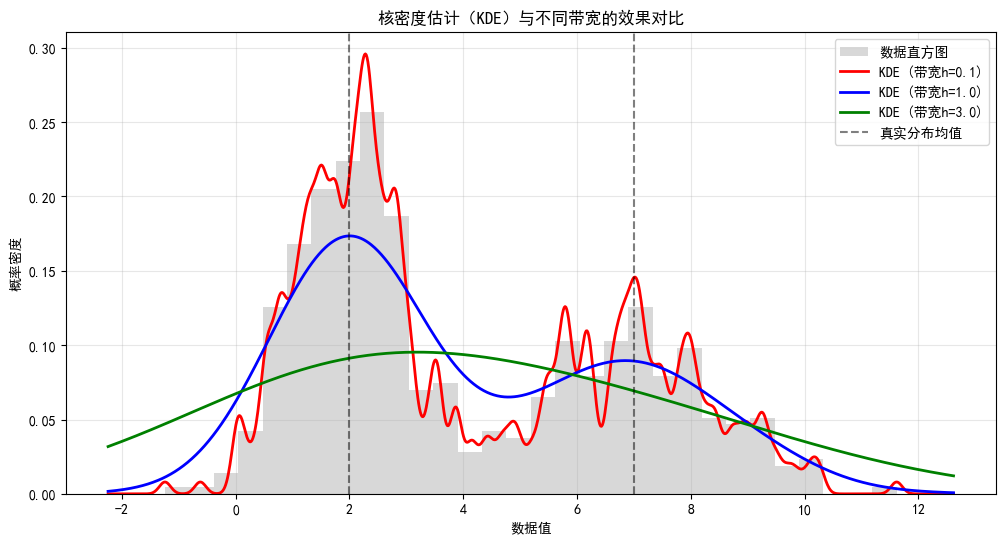
KDE概率密度函数的积分(应接近1):0.9258
3.5.3 最近临
最临近核密度估计通过固定每个样本点的邻域包含 k 个最近邻点,动态调整带宽来估计密度:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import NearestNeighbors
from scipy.stats import norm
# 设置中文字体
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
def knn_kernel_density_estimate(samples, x_grid, k=5, kernel='gaussian'):
"""
使用k-近邻方法进行核密度估计
参数:
samples: 训练样本数据,形状为(n_samples,)
x_grid: 用于估计密度的网格点,形状为(n_grid,)
k: 近邻数量
kernel: 核函数类型,支持'gaussian'(高斯核)和'uniform'(均匀核)
返回:
density: 估计的密度值,与x_grid形状相同
"""
n = len(samples)
density = np.zeros_like(x_grid, dtype=float)
# 构建近邻模型
nn = NearestNeighbors(n_neighbors=k)
nn.fit(samples.reshape(-1, 1)) # 转换为二维数组以适应sklearn接口
for i, x in enumerate(x_grid):
# 找到x的k个最近邻
distances, indices = nn.kneighbors([[x]])
h = distances[0][-1] # 第k个最近邻的距离作为带宽
if h == 0: # 避免除以零(当存在相同样本点时)
h = 1e-10
# 计算核函数加权和
neighbors = samples[indices[0]]
u = (neighbors - x) / h
if kernel == 'gaussian':
kernel_vals = norm.pdf(u)
elif kernel == 'uniform':
kernel_vals = np.where(np.abs(u) <= 1, 0.5, 0)
else:
raise ValueError("不支持的核函数类型,可选'gaussian'或'uniform'")
# 计算密度估计值
density[i] = np.sum(kernel_vals) / (n * h)
return density
# 示例用法
if __name__ == "__main__":
# 1. 生成测试数据(混合高斯分布)
np.random.seed(42)
n_samples = 200
mean1, mean2 = 2, 7
std1, std2 = 1, 1.5
samples = np.concatenate([
np.random.normal(mean1, std1, int(n_samples / 2)),
np.random.normal(mean2, std2, int(n_samples / 2))
])
# 2. 创建估计网格
x_min, x_max = min(samples) - 3, max(samples) + 3
x_grid = np.linspace(x_min, x_max, 500)
# 3. 进行核密度估计
k = 10 # 近邻数量
density_knn_gaussian = knn_kernel_density_estimate(samples, x_grid, k=k, kernel='gaussian')
density_knn_uniform = knn_kernel_density_estimate(samples, x_grid, k=k, kernel='uniform')
# 4. 绘制结果
plt.figure(figsize=(12, 6))
# 绘制样本点
plt.scatter(samples, np.zeros_like(samples), alpha=0.5, c='blue', label='样本点')
# 绘制密度估计曲线
plt.plot(x_grid, density_knn_gaussian, 'r-', label=f'k={k} 高斯核')
plt.plot(x_grid, density_knn_uniform, 'g--', label=f'k={k} 均匀核')
plt.xlabel('x')
plt.ylabel('密度')
plt.title('k-近邻核密度估计')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
#预测案例
# 1. 定义积分区间[a, b]
a, b = 0, 5
# 2. 在积分区间内生成极密集的网格(网格越密,积分精度越高)
# 建议点数:1000~5000,根据区间长度调整(此处用2000点)
x_dense = np.linspace(a, b, 2000)
# 3. 预计算密集网格上的密度值(一次计算,避免重复调用函数)
density_dense = knn_kernel_density_estimate(samples, x_dense, k=k, kernel='gaussian')
# 4. 梯形积分:np.trapz(函数值, 自变量)
total_prob_trapz = np.trapezoid(density_dense, x_dense)
# 5. 可选:绘制密集网格的密度曲线,验证平滑性
plt.figure(figsize=(10, 4))
plt.plot(x_dense, density_dense, 'r-', label='密集网格密度曲线')
plt.fill_between(x_dense, 0, density_dense, alpha=0.2, label=f'积分区间 [{a}, {b}]')
plt.legend()
plt.title('梯形积分区间与密度曲线')
plt.grid(True, alpha=0.3)
plt.show()
print(f"\n梯形积分结果:{total_prob_trapz:.4f}")
# 新样本点(待预测密度的点)
new_points = np.array([1.5, 4.0, 6.8, 9.2]) # 举例:4个新点
# 预测新点的密度(直接调用核密度估计函数,传入新点作为x_grid)
new_densities_gaussian = knn_kernel_density_estimate(
samples, new_points, k=k, kernel='gaussian'
)
new_densities_uniform = knn_kernel_density_estimate(
samples, new_points, k=k, kernel='uniform'
)
# 输出结果
print("新样本点的密度预测结果:")
for x, dens_gauss, dens_unif in zip(new_points, new_densities_gaussian, new_densities_uniform):
print(f"x={x:.1f} | 高斯核密度:{dens_gauss:.4f} | 均匀核密度:{dens_unif:.4f}")
梯形积分结果:0.3985
新样本点的密度预测结果:
x=1.5 | 高斯核密度:0.2749 | 均匀核密度:0.4014
x=4.0 | 高斯核密度:0.0241 | 均匀核密度:0.0388
x=6.8 | 高斯核密度:0.0826 | 均匀核密度:0.1269
x=9.2 | 高斯核密度:0.0220 | 均匀核密度:0.0331
- x=1.5:高斯核密度 0.2749,均匀核密度 0.4014表示在
x=1.5这个点的 “周围小区间内”(比如[1.4,1.6]),样本分布较密集 —— 密度值越高,说明这个点附近的样本越多。 - x=4.0:高斯核密度 0.0241,均匀核密度 0.0388表示在
x=4.0附近,样本分布非常稀疏 —— 密度值远低于 x=1.5,说明这个点周围几乎没有样本


















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










