






 本文通过实验对比了Java中遍历Map的不同方式,包括keySet、entrySet和values的遍历,分析了它们在不同数据量和场景下的效率。总结指出,对于大数据量,entrySet遍历key+value效率较高,而仅需value时,values遍历更优。同时强调了面试中应掌握的Java基础知识、面向对象、数据库、Web开发、框架和分布式系统等相关技术。
本文通过实验对比了Java中遍历Map的不同方式,包括keySet、entrySet和values的遍历,分析了它们在不同数据量和场景下的效率。总结指出,对于大数据量,entrySet遍历key+value效率较高,而仅需value时,values遍历更优。同时强调了面试中应掌握的Java基础知识、面向对象、数据库、Web开发、框架和分布式系统等相关技术。
1、由来
我们应该在什么时刻选择什么样的遍历方式呢,必须通过实践的比较才能看到效率,也看了很多文章,大家建议使用entrySet,认为entrySet对于大数据量的查找来说,速度更快,今天我们就通过下面采用不同方法遍历key+value,key,value不同情景下的差异。
2、准备测试数据:
HashMap1:大小为1000000,key和value的值均为String,key的值为1、2、3.........1000000;
Map<String,String> map =new HashMap<String,String>();
String key,value;
for(int i=1;i<=num;i++){
key = ""+i;
value="value"+i;
map.put(key,value);
}
HashMap2:大小为1000000,key和value的值为String,key的值为50、100、150........50000000;
Map<String,String> map = new HashMap<String,String>();
String key,value;
for(int i=1;i<=num;i++){
key=""+(i*50);
value="value"+key;
map.put(key,value);
}
3、场景测试
3.1遍历key+value
1)keySet利用Iterator遍历
long startTime1 =System.currentTimeMillis();
Iterator<String> iter = map.keySet().iterator();
while (iter.hasNext()){
key=iter.next();
value=map.get(key);
}
long endTime1 =System.currentTimeMillis();
System.out.println("第一个程序运行时间:"+(endTime1-startTime1)+"ms");
2)keySet利用for遍历
long startTime2 =System.currentTimeMillis();
for(String key2:map.keySet()){
value=map.get(key2);
}
long endTime2 =System.currentTimeMillis();
System.out.println("第二个程序运行时间:"+(endTime2-startTime2)+"ms");
3)entrySet利用Iterator遍历
long startTime3=System.currentTimeMillis();
Iterator<Map.Entry<String,String>> iter3 =map.entrySet().iterator();
Map.Entry<String,String> entry3;
while (iter3.hasNext()){
entry3 = iter3.next();
key = entry3.getKey();
value=entry3.getValue();
}
long endTime3 =System.currentTimeMillis();
System.out.println("第三个程序运行时间:" +(endTime3-startTime3)+"ms");
4)entrySet利用for遍历
long startTime4=System.currentTimeMillis();
for(Map.Entry<String,String> entry4:map.entrySet()){
key=entry4.getKey();
value=entry4.getValue();
}
long endTime4 =System.currentTimeMillis();
System.out.println("第四个程序运行时间:"+(endTime4-startTime4) +"ms");
3.2遍历key
1)keySet利用Iterator遍历
long startTime1 =System.currentTimeMillis();
Iterator<String> iter = map.keySet().iterator();
while (iter.hasNext()){
key=iter.next();
}
long endTime1 =System.currentTimeMillis();
System.out.println("第一个程序运行时间:"+(endTime1-startTime1)+"ms");
2)keySet利用for遍历
long startTime2 =System.currentTimeMillis();
for(String key2:map.keySet()){
}
long endTime2 =System.currentTimeMillis();
System.out.println("第二个程序运行时间:"+(endTime2-startTime2)+"ms");
3)entrySet利用Iterator遍历
long startTime3=System.currentTimeMillis();
Iterator<Map.Entry<String,String>> iter3 =map.entrySet().iterator();
Map.Entry<String,String> entry3;
while (iter3.hasNext()){
key = iter3.next().getKey();
}
long endTime3 =System.currentTimeMillis();
System.out.println("第三个程序运行时间:" +(endTime3-startTime3)+"ms");
4)entrySet利用for遍历
long startTime4=System.currentTimeMillis();
for(Map.Entry<String,String> entry4:map.entrySet()){
key=entry4.getKey();
}
long endTime4 =System.currentTimeMillis();
System.out.println("第四个程序运行时间:"+(endTime4-startTime4) +"ms");
3.3遍历value
1)keySet利用Iterator遍历
long startTime1 =System.currentTimeMillis();
Iterator<String> iter = map.keySet().iterator();
while (iter.hasNext()){
value=map.get(iter.next());
}
long endTime1 =System.currentTimeMillis();
System.out.println("第一个程序运行时间:"+(endTime1-startTime1)+"ms");
2)keySet利用for遍历
long startTime2 =System.currentTimeMillis();
for(String key2:map.keySet()){
value=map.get(key2);
}
long endTime2 =System.currentTimeMillis();
System.out.println("第二个程序运行时间:"+(endTime2-startTime2)+"ms");
3)entrySet利用Iterator遍历
long startTime3=System.currentTimeMillis();
Iterator<Map.Entry<String,String>> iter3 =map.entrySet().iterator();
Map.Entry<String,String> entry3;
while (iter3.hasNext()){
value=iter3.next().getValue();
}
long endTime3 =System.currentTimeMillis();
System.out.println("第三个程序运行时间:" +(endTime3-startTime3)+"ms");
4)entrySet利用for遍历
long startTime4=System.currentTimeMillis();
for(Map.Entry<String,String> entry4:map.entrySet()){
value=entry4.getValue();
}
long endTime4 =System.currentTimeMillis();
System.out.println("第四个程序运行时间:"+(endTime4-startTime4) +"ms");
5)values利用iterator遍历
long startTime5=System.currentTimeMillis();
Iterator<String> iter5=map.values().iterator();
while (iter5.hasNext()){
value=iter5.next();
}
long endTime5 =System.currentTimeMillis();
System.out.println("第五个程序运行时间:"+(endTime5-startTime5) +"ms");
6)values利用for遍历
long startTime6=System.currentTimeMillis();
for(String value6:map.values()){
}
long endTime6 =System.currentTimeMillis();
System.out.println("第六个程序运行时间:"+(endTime6-startTime6) +"ms");
4、时间对比
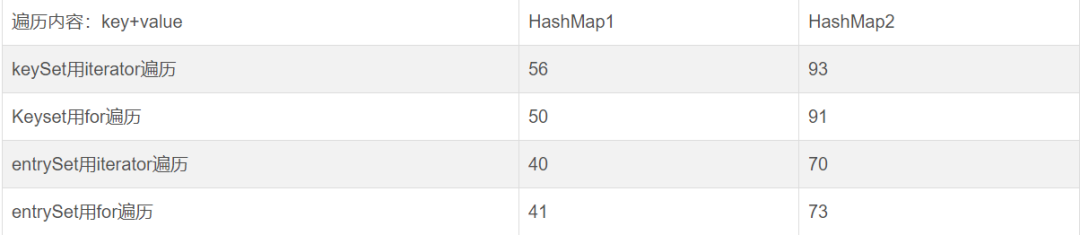
4.1遍历key+value
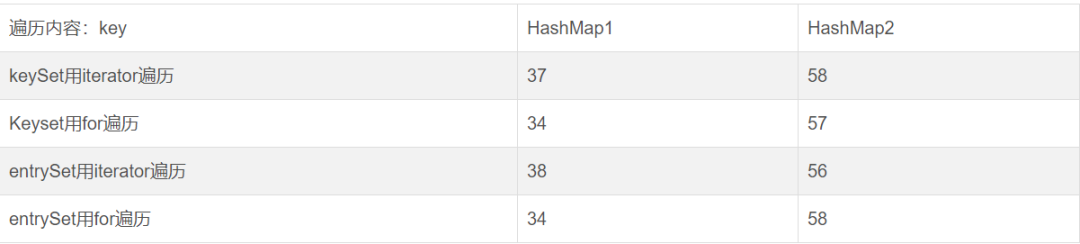
4.2遍历key
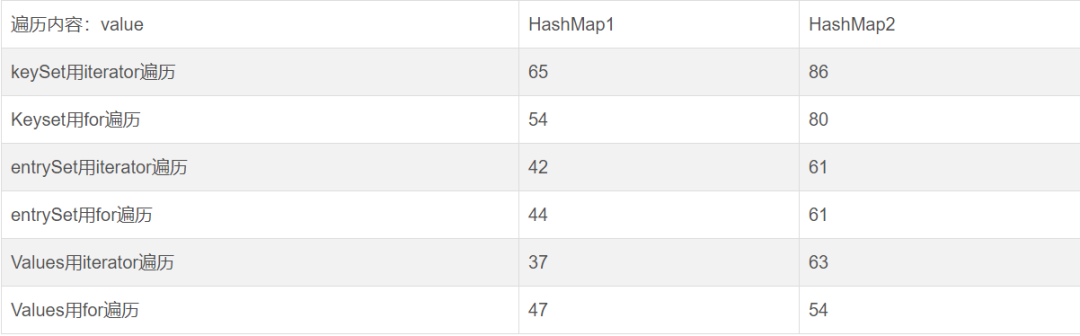
4.3遍历value
5、总结
从上面的时间比较来看:
1)map的key采用简单形式和复杂形式时,查找的效率是不同的,简单的key值效率更高
2)当数据量大的时候,采用entrySet遍历key+value的效率要高于keySet
3)当我们只需要取得value值时,采用values来遍历效率更高
面试需要掌握那些技能?
1. Java基础知识:包括面向对象编程、集合框架、多线程编程、JVM、测试和调试技术等。
2. 熟悉Spring框架:包括Spring MVC、Spring Boot、Spring Cloud等。
3. 掌握常见的数据库操作技术:如SQL语句、关系型数据库和非关系型数据库等。
4. 熟练使用版本控制工具:如Git等。
5. 对Web开发有一定的了解,熟悉前端相关技术:如HTML、CSS、JavaScript等。
6. 能够写高效的算法,并对数据结构有一定的了解。
7. 有良好的代码习惯,能够编写易于维护和扩展的代码,并理解单元测试和集成测试等概念。
8. 在面试过程中,还需要表达清晰、思路清晰明了、能够准确地回答面试官提出的问题,此外,自信、积极和礼貌也是很重要的。
2023年大厂面试官常问的技术核心知识点
1. Java基础知识:Java语言的基本知识,包括数据类型、继承、多态、接口等。
2. 面向对象编程:对面向对象编程原则和设计模式的理解,如单例、工厂、观察者、策略等。
3. 数据库知识:对关系型数据库和非关系型数据库操作的熟悉程度,掌握SQL语言,了解事务管理机制,并清楚地描述ORM框架的使用场景及实际操作。
4. Web开发:Web开发相关技术,例如Servlet、JSP、Spring MVC、JSON、RESTful API等。熟悉HTTP/HTTPS协议以及网络通信机制。
5. 常用框架:Spring、Hibernate、MyBatis等框架,尤其是Spring框架,深入理解Spring IOC,AOP等核心原理,知道如何配置基础设施组件,如事务管理、缓存等基础组件。
6. 分布式系统架构:分布式系统相关技术,如Dubbo、Zookeeper等,对微服务架构模式有一定的了解,熟悉分布式锁、分布式缓存、分布式数据存储等高可用性方案。
7. 性能排查:了解性能优化的方法,包括代码和SQL调优等,并且熟悉性能监测和分析工具,例如掌握JVM内存结构及堆栈排查技术。
8. 算法和数据结构:有基本的算法和数据结构知识,例如排序、查找、哈希表等。
我最近整理了一些小伙伴们发给我的面试题以及我的一些最新的面试等学习资料,有需要的小伙伴可以找我领取下。或者点击 → 《2023最新Java后端全套VIP面试学习资源》直接获取以下Java后端架构VIP进阶学习面试资料。
资料里面包含了:Java基础、MySQL、jvm、分布式、性能优化、spring 、spring boot、spring cloud、 MyBatis、Netty源码分析、算法、乙级高并发、Redis、dubbo、Tomcat、集合框架、锁、MQ、百万简历模板等等学习视频资料。
资料如图展示:(知识其中一部分)

同时也欢迎大家关注公众号【Java烂猪皮】,回复【666】,获取最新Java后端架构VIP学习资料以及视频学习教程,然后一起学习,一文在手,面试我有。
公众号【Java烂猪皮】里面每天都会分享很多独家的干货内容,比如:Java后端学习路线,分享实战项目,源码分析,百万级系统设计,系统上线的一些坑,MQ专题,真实面试题,每天都会回答大家提出的问题。
每一个专栏都是大家非常关心,和非常有价值的话题,我相信在专栏中你会学到很多东西,一起共勉。


















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










