







看喷有感
这几天看到有公众号文章疯狂攻击MySQL,点进去看了一下,里面所谓的ACID、RR正确性问题,给大家介绍下背后的原理,以及为什么MySQL要选择这样的实现方式。
MySQL新版恶性Bug,表太多就崩给你看!----最近的这一篇,以及这里面引用的下面两篇
MySQL的正确性为何如此拉垮?
为什么说PostgreSQL前途无量?
由于本人行业背景关系,对pg了解一点,对MySQL也了解一点,故有一点不同看法。
关于ACID
文章中原图如下,得出结论说MySQL不符合ACID,这 -_- !!! -_- !!! -_- !!! -_- !!!
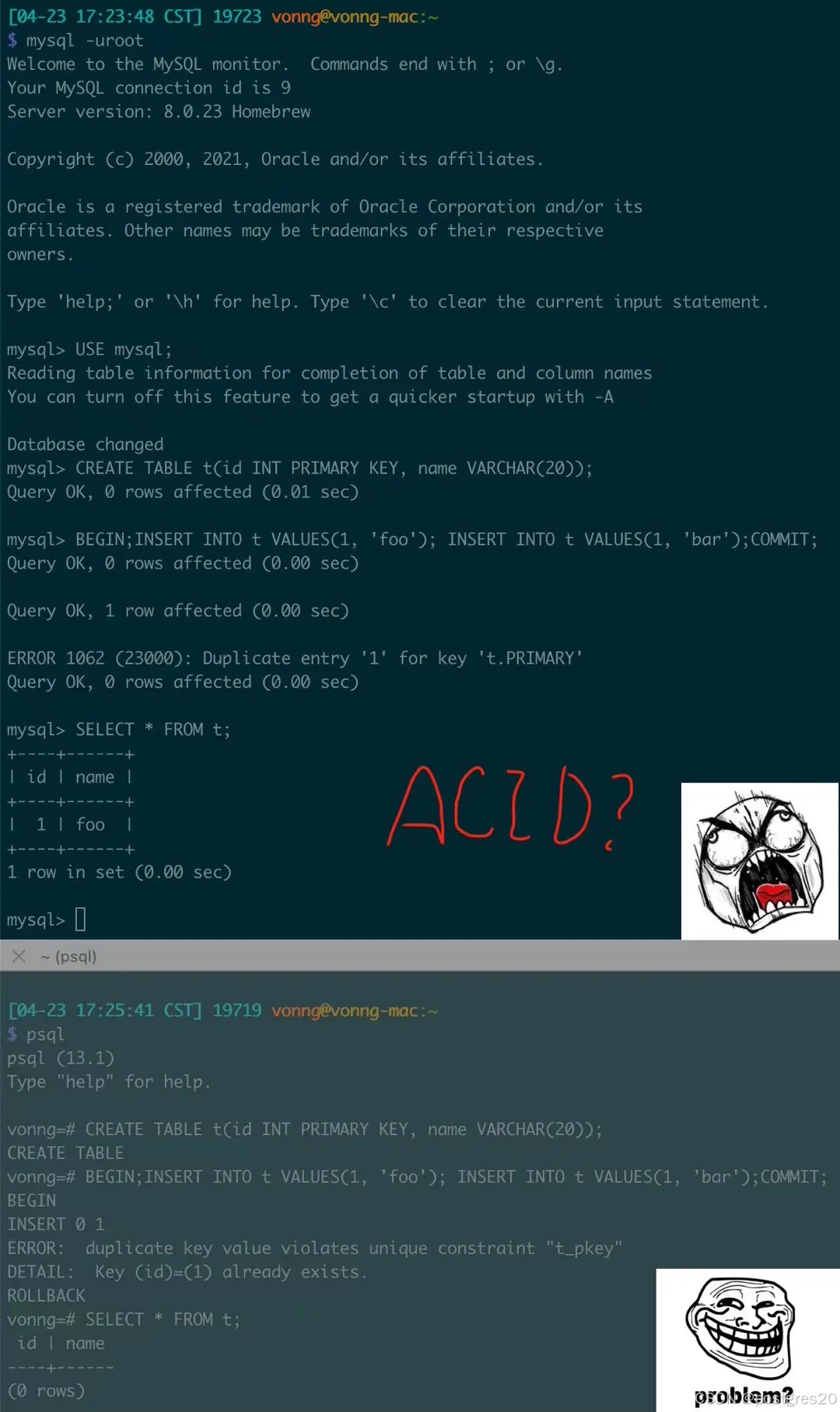
在 MySQL 的事务处理中,出现错误并不会自动回滚整个事务,而 PostgreSQL 则会在发生错误时自动回滚整个事务。这是否意味着 MySQL 不符合 ACID 原则呢?
实际上,上图中的最后一个 commit 已经给出了答案:MySQL只是将【提交】或【回滚】的选择权交给了用户而已!一个事务可能包含成千上万的增删改查SQL语句,在MySQL中,当某个语句执行出错后,用户可以根据错误信息进行处理,选择继续提交还是回滚。许多情况下,用户希望错误不影响之前的语句,那么就可以像上图一样直接提交;如果认为有影响,则可以选择回滚。选择权在用户手中。
而在PostgreSQL中,发生错误时会强制回滚,用户没有选择权,即使用户执行的是 commit,也会被回滚,如上图所示。如果较真起来,PostgreSQL在这种情况下会丢失所有事务数据,而业务实际执行的是 commit,回滚并不是业务的预期结果。试想一个场景:某用户辛辛苦苦执行了几百条语句,某个语句手误出错,直接强制回滚整个事务,用户会是什么心态?硬要告诉用户ACID标准就是这样,所以要全部失败?为什么不能妥协一下,把选择权交给用户,让用户决定提交或回滚呢?用户来决策是否提交或回滚就不符合ACID了吗? -_- !!! -_- !!!
此外这个公众号作者,列举的所有其它的用例sql都一条sql占一行,而这个用例偏偏把多条sql写在一行?为什么呢?这一行等价关系如下:
begin;insert into t values(1,'foo');insert into t values(1,'bar');commit;
--- 等价于下
begin;
insert into t values(1,'foo');
insert into t values(1,'bar');
commit;
这好像也没啥,那复制过去执行一下如下: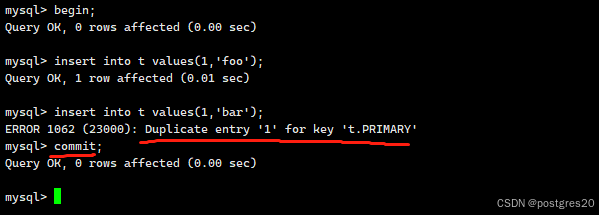
如果分成多行输入,就会明显的看到,数据库已经报错了,用户仍然选择了提交。
从技术上来说,MySQL 要支持在某个语句出错时强制回滚整个事务的能力,是非常容易实现的,执行出错时,my_error 捕获到错误打印错误信息的同时,增加一个ha_rollback就可以搞定,不存任何在技术难度,是现有功能。反而 PostgreSQL 使用 sigsetjmp 和 siglongjmp 这种“大跳”进行内部错误处理,如果要改造成类似 MySQL 这样的,出错时让用户来决定提交or回滚,还是略有些麻烦的,当然也不是什么大问题。那么,MySQL为什么非要支持这种麻烦的用法呢?真想统计下,有多少pg从业者,接到过客户这种类似需求,最后帮客户改写plsql部分实现?
标准规定是死的,技术、业务、解决方案等是不断进化的,如果有对用户和业务更加灵活好用的方案,为什么不能改变呢? ORACLE数据库他就遵守什么sql92、sql99标准了吗?标准不是用来自嗨的,服务好用户才是最终的标准!
关于正确性
先说结论
MySQL这么设计实现,是为了高并发下保证数据一致性的同时提高并发性能的设计选择,所谓的“内部一致性错误” 、“中间状态”是为了尽可能的保障性能的前提下的一种妥协。
公众号提到的两个问题
公众号作者提到的 “隔离性问题” 和 “原子性问题" 这两个问题,引用的是什么 JEPSEN 的测试,这所谓的两个问题实际是一个问题,但设计那么复杂的测试用例,精确到 【9048个事务中的126个出现了内部一致性错误】,以及原子性问题 【它观察到了“中间状态”】,这就有点耐人寻味了,原图如下:
第一个问题原文

第二个问题原文
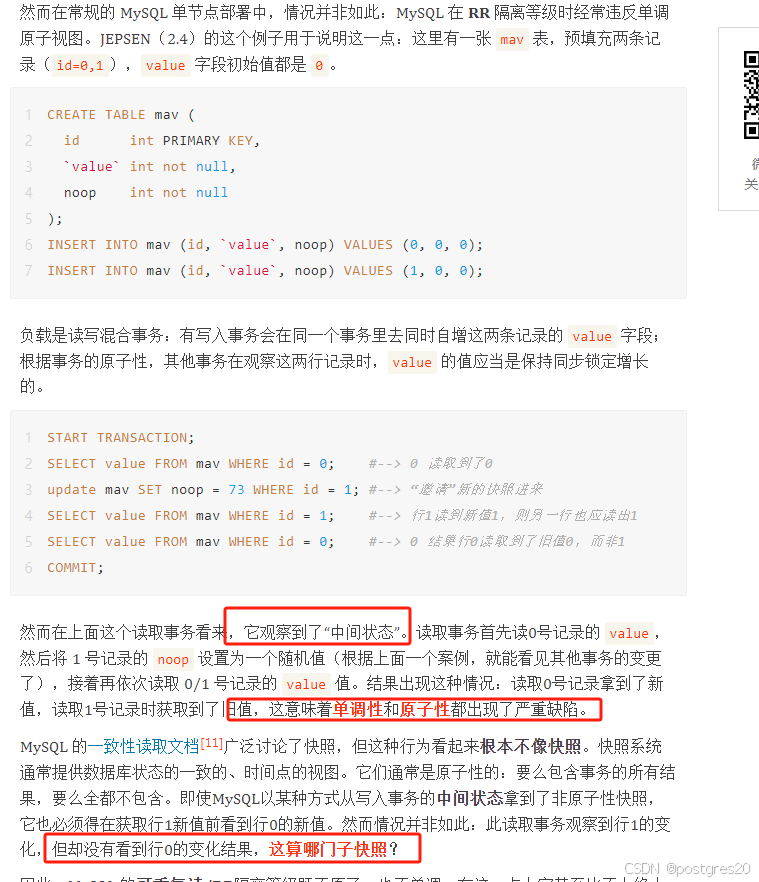
第一个用例解析与复现
原图已经奉上,为什么要说“耐人寻味”呢?这几个用例设计的有些水准,在看起有些“复杂”的并发场景中跑一阵之后,就有数据不一致或者不符合预期的情况出现,给人一种错觉,这是MySQL的重大缺陷。且这几个用例,直接复制过来跑是不能复现上面所说的情况的,具有一定迷惑性,也能显示出这个测试机构的“水准”。
这些用例的设计者应该是清楚或部分清楚MySQL这里的机制与逻辑的,但这个公众号作者是否了解就不好说了,下面我详细剖析一下这几个用例,以及为什么MySQL要这么实现,有什么优劣。
原用例1:
CREATE TABLE people (
id int PRIMARY KEY,
name text not null,
gender text not null
);
INSERT INTO people (id, name, gender)
VALUES (0, "moss", "enby");
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION; -- 开启事务
SELECT name FROM people WHERE id = 0; -- 第一次读取结果为 "pebble"
UPDATE people SET gender = "femme" WHERE id = 0; -- 随便更新点什么
SELECT name FROM people WHERE id = 0; -- 第二次读取结果为 "moss"
COMMIT;
原文说“9048个事务中的126个出现了内部一致性错误”,这个用例直接复制过来执行不会出现原文说的情况,把它稍改造一下,让它不用并发也能100%出现“内部一致性错误”,如下:
drop table people;
CREATE TABLE people (
id int PRIMARY KEY,
name text not null,
gender text not null
);
INSERT INTO people (id, name, gender)
VALUES (0, 'pebble', 'enby');
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION; -- 开启事务1
SELECT name FROM people WHERE id = 0; --第一次读取结果为 "pebble"
-------另开一个线程执行下面sql,并确保提交
BEGIN;
UPDATE people SET name = 'moss' WHERE id = 0;
COMMIT;
-------回到事务1连接继续执行下面语句
UPDATE people SET gender = 'femme' WHERE id = 0; -- 随便更新点什么
SELECT name FROM people WHERE id = 0; -- 第二次读取结果为 "moss",“不一致”
COMMIT;
串行执行上面用例,完全不用任何并发,就会100%出现name为moss的所谓的"内部一致性错误", 如下图: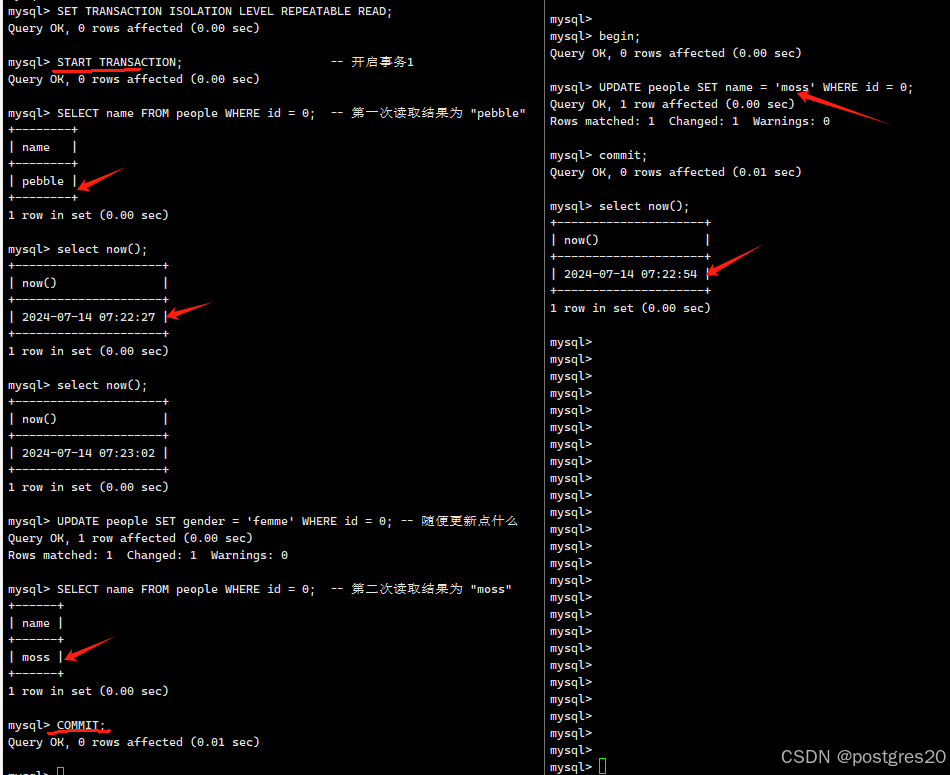
MySQL可见性判断逻辑为何如此设计?
MySQL采用的回滚段方式实现的MVCC,而PG用的是页面内多版本方式实现MVCC(见文章Postgresql MVCC机制源码初探)。
MySQL在更新时会产生版本链,最新的版本在页面上,老版本在回滚段中,物理页面元组上有指针指向老版本,形成版本链。判断是否可见依赖快照,快照是一个数组,里面存了所有活跃事务ID。MySQL根据行上的事务ID以及这个快照数组,可以判断出当前记录是否可见。所谓的RR和RC隔离级别,在判断可见性时没有区别,本质是完全相同。差别在于RR只在事务第一个语句执行时生成快照,而RC是在事务中的每个语句执行时都要生成一次快照。RR相对于RC的性能优势就在此,有非常多资料介绍MySQL的MVCC机制,这里不再展开。
继续,MySQL通过快照判断可见性逻辑中,还有一个类似“超级用户权限”的逻辑:当前事务操作的行,当前事务默认可见(当然PG也是这样的)。举个例子,当前事务插入了一行,这一行记录当前事务立即可见,即使当前事务没提交,这很合理吧。当前事务删除了一行,这一行当前事务立即不可见,即使当前事务没提交,这也很合理吧。当前事务更新了一行,这一行的更新内容当前事务立即可见,即使当前事务没提交,这也.....等等,测试用例中的问题是否出现了?
设计用例中的更新语句:
UPDATE people SET gender = "femme" WHERE id = 0;
看起来与 name 字段无关,它更新的是gender字段,而实际上,由于 name 已经在这个语句之前被更新成了 moss , 所以这个 update 与下面语句是等价的:
UPDATE people SET gender = "femme" ,name ="moss" WHERE id = 0; (不管是pg还是mysql,物理元组或行是可操作的最小单位,有变化的字段更新,没变化的字段原样拷过去)
所以,当前事务自己更新的内容,被当前事务看到,在可见性判断上是合理的,这里快照读到没有任何问题。
MySQL的争议点
那MySQL在其它方面就没有可疑点吗?当然有,这里真正的问题是这个更新操作为什么可以看到了RR不应该看到的数据。这就涉及MySQL的另外一个机制,更新数据时,使用的是当前读,非快照读!即更新永远都读到最新的数据,可以理解成更新时用的RC级别,只要提交就可见(未提交则等锁)。
简单来说就是两个原因导致了这个测试结果:
1. 更新使用的是当前读,永远读最新数据。
2. 当前事务对自己事务内的修改完全见。
那么MySQL更新为什么要使用当前读呢?
为了提升并发性能与容错性,当前读读到的数据是已经提交的数据,逻辑上不会有什么问题,最大的后果就是等价于退化到RC级别,但这样处理后对并发处理数据就非常友好了。
为什么当前读会对并发处理数据很友好呢?
假如更新依旧要用快照读,那么更新就可能在旧版本上更新,其它事务可能已经提交了更新版本,在旧版本更新肯定是不对的,一定会造成数据不一致,怎么办?只能报错,遇到这种情况就报错,这就是PG的逻辑,它物理元组上有xmin和xmax是知道这行记录是被什么事务插入,被什么事务更新过的,当二次更新一个旧数据时,会直接报错:could not serialize access due to concurrent update,MySQL更新逻辑则是永远读最新版本来解决这个问题。
试想一下,RR隔离级别下,一个事务A产生快照开始执行,在它提交前,晚于事务A开始的其它更新事务已经提交,如果A事务要修改过晚于A事务提交的数据,一律报错,并且,PG的逻辑,会彻底的贯彻执行ACID,只要报错就回滚整个事务,那在热点冲突数据稍微多一点的场景中,有并发修改相同数据的情况下,会产生大量“could not serialize access” 问题导致业务应用很难流畅的跑下去。而MySQL的设计逻辑,这种场景完全没问题,当然会有一个“后果”,并发修改的数据,实际会退化到RC级别,如果业务应用在一致性要求上不能接受,那么就使用RC级别,在性能和一致性之间,由用户自己去做权衡决策。
另外,有个题外问题读者朋友可仔细以考虑下:为什么MySQL默认隔离级别用RR,而PG默认隔离级别用RC呢?
所以说MySQL这么设计实现,是为了高并发下保证数据一致性的同时提高并发性能的设计选择,是为了尽可能的保障性能的前提下的一种妥协。
第二个用例解析与复现
至于第二个问题,什么“原子性问题:非单调视图”,其实是重复凑数问题,原因还是一样:
1. 更新使用的是当前读,永远读最新数据。
2. 当前事务对自己事务内的修改完全见。
由于原因相同,不再展开啰嗦,附一下简化不需要并发即可复现用例如下,有兴趣的同学自己去玩一下:
drop table mav;
CREATE TABLE mav (
id int PRIMARY KEY,
`value` int not null,
noop int not null
);
INSERT INTO mav (id, `value`, noop) VALUES (0, 0, 0);
INSERT INTO mav (id, `value`, noop) VALUES (1, 0, 0);
begin; -- 事务1
SELECT value FROM mav WHERE id = 0;
begin; -- 事务2
update mav SET value = 1 WHERE id = 1;
update mav SET value = 1 WHERE id = 0;
commit;
-- 事务1继续
update mav SET noop = 73 WHERE id = 1;
SELECT value FROM mav WHERE id = 1; #--> 行1读到新值1,则另一行也应读出1
SELECT value FROM mav WHERE id = 0; #--> 0 结果行0读取到了旧值0,而非1
commit;
小结
数据库设计应该重视客户体验,充分考虑业务应用需求实际场景,而不是老想着教育用户,你们应该怎么用数据库,强制用户按设计者思维使用数据库。不可否认,pg是一款优秀且先进的数据库,有非常多值得MySQL学习的地方,同样MySQL也一款优秀的数据库,有非常多值pg学习的点。上文提到的ACID与一致性相关问题,并不是说谁就一定是对的,谁一定是更好的。对于用户来说,他们不会因谁标榜自己最先进就选谁,也不会因为谁说自己最流行就选谁,一定会是基于自己的业务场景,技术储备,后续运维的便利性,性价比等非常多的综合因素才决定选什么数据库的。不可能有一款数据库能适用任何场景,但任何场景一定有一款最适合的数据库,用户会做出最符合自己业务逻辑的选择。
建议pg加上MySQL的事务中报错不回滚模式供用户选择,同时建议MySQL加上pg这样的事务中报错就回滚的模式供用户选择,大家相互学习,共同进步嘛,多元多彩的世界多有意思,单极单调的世界多无趣!
另外,泼妇骂街除了显示自己的愚蠢,没有其它收益,就事论事即可!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










