



摘要
本文介绍了一种创新的虚假新闻检测模型,该模型集成了长短期记忆网络(LSTM)与自注意力机制。鉴于信息传播速度不断加快,虚假新闻的广泛传播已对社会造成了诸多负面影响,尤其在疫情期间。因此开发高效的虚假新闻检测技术显得尤为关键。传统文本分类方法在处理新闻内容时存在一定的局限性,而本研究提出的模型通过结合LSTM的序列建模能力和自注意力机制的特征聚焦优势,旨在提升对新闻文本语义信息的理解及特征提取效能。本文的数据集来源多样,涵盖了疫情期间从多个平台收集的新闻数据、澎湃新闻网的真实新闻数据、从中国互联网平台爬取的辟谣新闻数据以及微信公众号发布的谣言数据。数据整合后,构建基于自注意力机制的LSTM模型(DoubleCheck),用于虚假新闻的分类与预测。为保证模型具备一定的通用性和鲁棒性,实验开始前,通过计算新闻样本之间的余弦相似度来去除冗余数据。实验结果显示,该模型在多个评估指标上表现出色,特别是在准确性、召回率及F1分数方面均有显著提高。这一结果不仅验证了自注意力机制结合LSTM架构在识别虚假信息方面的有效性,同时也为未来相关研究开辟了新路径,有助于更好地应对日益复杂的虚假新闻传播挑战,从而维护信息安全与社会稳定。关键词:数据爬取,虚假新闻检测,DoubleCheck,自注意力机制,LSTM,信息安全。
研究意义
谣言会对人们的行为和态度产生重大影响,尤其是在社交媒体时代,虚假新闻可以迅速传播并误导公众舆论。疫情期间,COVID-19 大流行只会加剧这一问题,如下表所示,“吸烟可以预防非典,因为烟油可以阻挡病毒进入肺细胞”、“喝高度白酒、蒸桑拿,可以抵抗新型冠状病毒”等谣言新闻标题,很容易造成群众的认知误导,因此,识别并应对社交媒体平台上的谣言已成为一个亟待解决的重要问题。在本文中,我们重点关注跨多个社交媒体平台的数据分析,以确保所构建模型的鲁棒性和有效性。| 新闻来源 | 新闻标题 |
|---|---|
| COVID-19-rumors | 吸烟可以预防非典,因为烟油可以阻挡病毒进入肺细胞 |
| COVID-19-rumors | 喝高度白酒、蒸桑拿,可以抵抗新型冠状病毒 |
| 微信公众号 | 安踏,你代表不了中国体育精神风貌 |
数据获取
爬虫
在数据集准备期间,首先考虑到的数据获取方法是爬取网页的新闻数据,在本文中,爬取了中国互联网联合辟谣平台的联动要闻数据和部分微信公众号谣言发文。中国互联网联合辟谣平台
通过遍历联动要闻下新闻标题对应的url进入对应新闻的正文信息页面,在遍历过程中需要进行动态翻页,保证数据爬取的完整性,进入正文信息页后,逐段爬取新闻的正文内容,最后整合为中国互联网新闻文件(见附件)。由于平台本身的辟谣属性,标记列全部设置为“真”。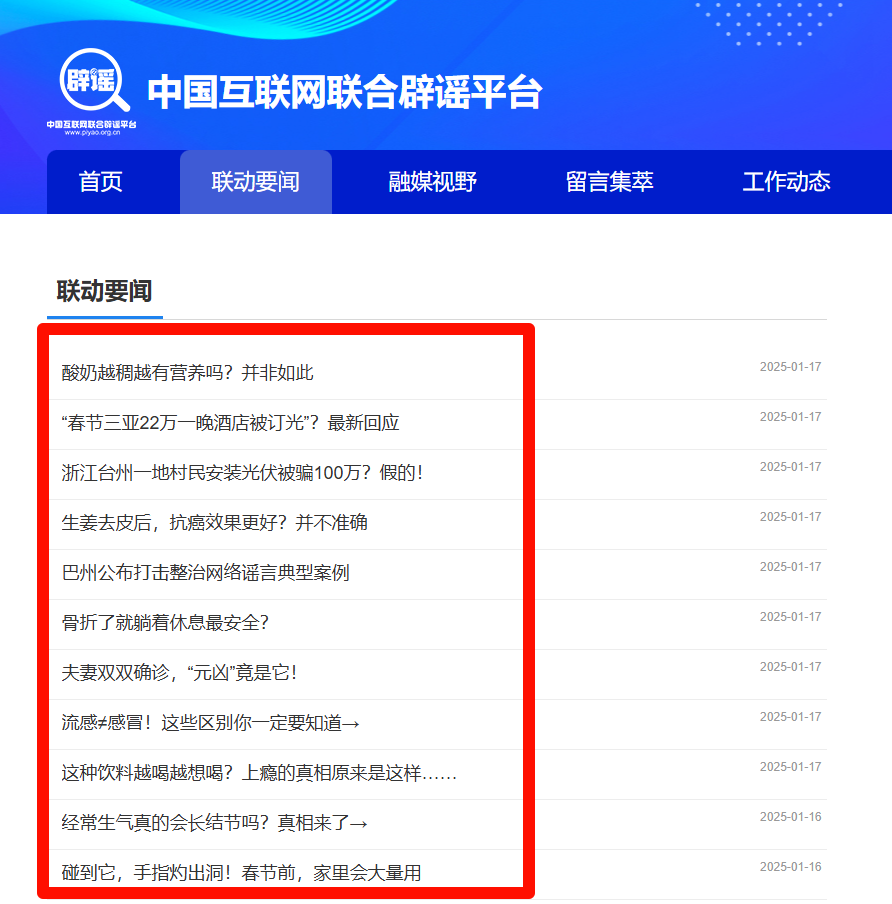
微信公众号谣言发文
对微信公众号中涉及谣言的文章URL进行了全面遍历,并对这些文章的正文内容进行了爬取,以收集相关谣言文章的具体信息。值得注意的是,由于部分文章因被平台识别为谣言而遭到处理,或是由原作者自行删除,导致部分URL已失效,无法成功获取其正文内容。经过筛选与验证后,最终成功收集到超过2000篇可访问的公众号文章正文(见附件)。
开放数据集
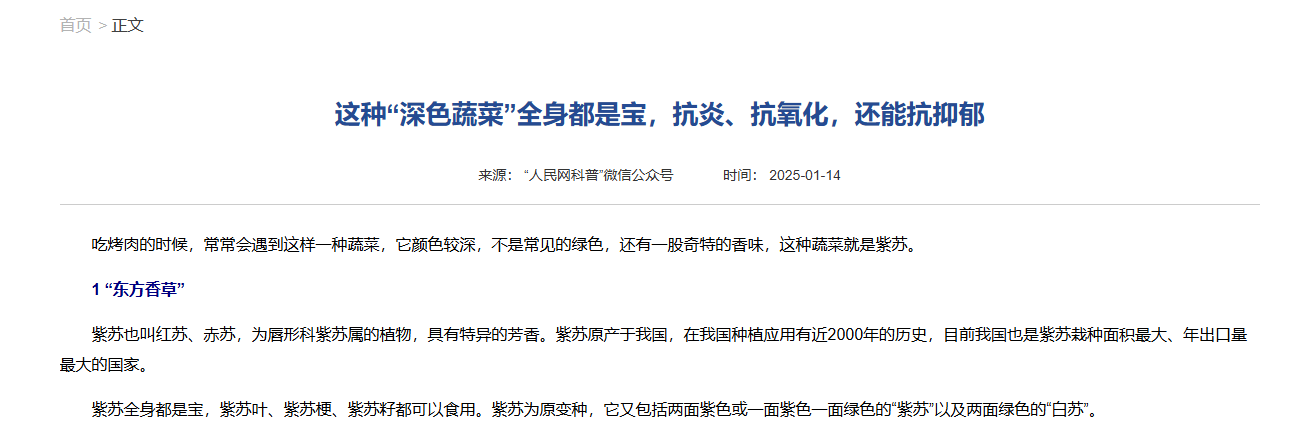
除了通过网络爬虫获取新闻数据之外,另一种可行的数据获取方法是从开放数据平台上直接下载由用户或机构发布的数据集。常见的开放数据平台包括CSDN、Kaggle 和 GitHub 等。本文从 GitHub 平台上收集了与 COVID-19 相关的谣言新闻数据,并从澎湃新闻网站获取了真实新闻数据(见附件)。这些数据来源的多样化有助于增加数据样本的数量和多样性,从而提升模型预测结果的普适性和准确性。将收集到的数据整合至单一文件中,并设定一套标准化的规则,确保文件仅包含以下关键信息:新闻来源、标题、内容、发布时间及验证标识。具体而言,若某条新闻被标记为0,则表示该新闻被判定为虚假信息;反之,若其标识为1,则意味着该新闻被认为是真实可信的。
For example:
| source | title | content | label | time |
|---|---|---|---|---|
| COVID-19-rumors | 吸烟可以预防非典,因为烟油可以阻挡病毒进入肺细胞 | 网上流传的“烟油保护层”的理论称:烟油可以覆盖在肺细胞表面,相当于一个紧密的防护层;病毒进了… | 0 | 2020-01-21 |
最终整理得到数据共11480条,其中假新闻占比为22.5%,长度大于100的新闻占比为96.8%。
# 加载数据
data = pd.read_excel(r'D:\\大数据应用实践\\news\\news_data_all.xlsx')
# 数据验证
print(f'数据集大小: {data.shape}')
print(f'数据集列名: {data.columns}')
print(f'假新闻占比: {data[data["label"] == 0].shape[0] / data.shape[0]}')
print(f'长度大于100的新闻占比: {data[data["content"].str.len() > 100].shape[0] / data.shape[0]}')
运行结果:
数据集大小: (11480, 5)
数据集列名: Index(['source', 'title', 'content', 'label', 'time'], dtype='object')
假新闻占比: 0.22534843205574914
长度大于100的新闻占比: 0.9680313588850175
数据预处理
短文本剔除
针对已整理的新闻数据,对篇幅较短的新闻进行筛除。此举旨在防止在后续处理中,当输入固定长度的索引序列时,出现某些序列包含大量零值填充的情况,从而可能对模型的学习性能产生不利影响。# 数据预处理-1 删除长度小于100的新闻
data = data[data['content'].str.len() > 100]
谣言标志样本剔除
针对已经整理的新闻数据,发现某些新闻在其标题或正文中包含显著的谣言特征,则应将此类新闻明确标记为谣言,并予以排除。这是因为,在经过分词处理及注意力机制计算后,这些谣言特征往往会被赋予过高的重要性权重。为了避免这些异常值对模型训练产生不利影响,确保分词结果中词汇的重要性分布更加接近理想的高斯分布,在预处理阶段即移除上述含有明显谣言标志的新闻数据。谣言标志
近期有谣言称、据不实消息称、网传、有消息称、流传、谣言
余弦相似度去重
余弦相似度
cos(A,B)=A⋅B∥A∥⋅∥B∥\cos(A,B) = \frac{A \cdot B}{\|A\| \cdot \|B\|}cos(A,B)=∥A∥⋅∥B∥A⋅B
余弦相似度是一种常用的衡量两个向量在空间中方向相似度的指标,通常用于文本分析、信息检索和推荐系统中,特别是在处理文本数据时。其核心思想是计算两个向量之间夹角的余弦值,夹角越小,余弦值越接近 1,表示它们的方向越相似;夹角越大,余弦值越接近 -1 ,表示它们的方向越不相似。 对于两个余弦相似度过高的新闻样本,考虑去除重复的新闻样本以保证新闻数据样本的质量。
文本分词与向量化
在对每个新闻样本进行两两余弦相似度计算之前,需首先对其标题与内容进行文本分词处理,以生成适用于后续词向量化模型的输入数据。本文采用jieba库执行中文分词任务,该库在中文自然语言处理领域内广受认可,其功能在于将连续的汉字序列精准地切分为独立词汇,从而促进后续分析流程的有效开展。在文本分词后,使用TF-IDF将新闻向量化,两两计算新闻之间的余弦相似度,并对余弦相似度过高的重复新闻进行标记,被标记为重复新闻的新闻将被剔除。本文选定的相似度剔除标准为余弦相似度超过0.8即认为该新闻与过去的新闻重复。
词云图
完成数据预处理后检查分词后的新闻内容词云,词云图是一种通过视觉化的方式展示文本数据中词语频率的图形。每个词语的大小与其在文本中出现的频率成正比,频率较高的词语显示得较大,而频率较低的词语则较小。词云图通过这种方式使得文本数据的关键信息更加直观。
深度学习模型
LSTM
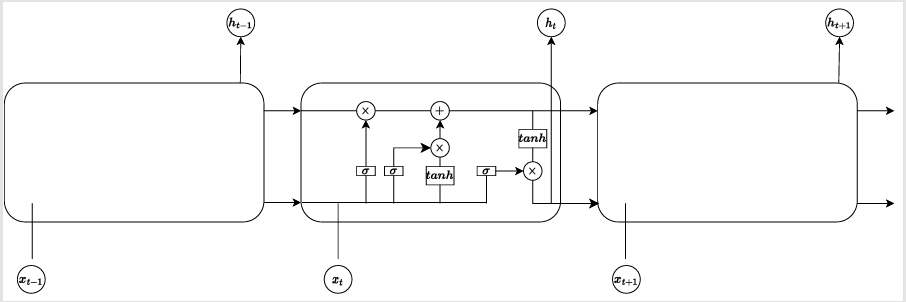
LSTM是一种特殊的循环神经网络,用于处理和预测序列数据中的长期依赖关系。与传统的RNN相比,LSTM能够有效地解决传统RNN在训练中遇到的梯度消失和梯度爆炸问题,因此在处理长序列数据时表现更好。LSTM通过门控机制来控制信息的流动,这使得它能够“记住”序列中的长远信息,同时避免丢失或过早忘记不重要的信息。LSTM有三个主要的门:输入门、遗忘门、和输出门。
自注意力机制
自注意力机制,也称为内部注意力机制,是一种将单个序列的不同位置关联起来以计算同一序列的表示的注意力机制。它允许模型在处理序列数据时,通过计算序列中不同位置元素之间的相关性得分,动态地调整对每个元素的关注程度,从而捕捉序列内部的复杂依赖关系。自注意力机制的核心在于,它不依赖于外部信息,而是在序列内部元素之间进行信息的交互和整合。具体来说,对于序列中的每个元素,自注意力机制会计算该元素与序列中所有其他元素的相关性,生成一个加权的表示,其中权重反映了元素间的相互关系。
自注意力机制能够使模型更好地理解序列中的上下文信息,从而更准确地处理序列数据。例如在语言模型中,它可以考虑到序列中每个词与其他所有词的关系,从而理解词与词之间的语义关联度。
工作原理:
给定一个输入序列X=[x1,x2,...,xn]X = [x_1, x_2, ..., x_n]X=[x1,x2,...,xn],每个输入向量xix_ixi会生成三个向量:
- Query:表示当前元素的查询向量。
- Key:表示当前元素的键向量。
- Value:表示当前元素的值向量。
自注意力机制的目标是通过对输入序列的每个元素计算和其他元素的关系来更新每个元素的表示。计算步骤如下:
计算注意力权重: 计算 Query 和 Key 的点积来衡量不同位置之间的相似性:
Attention Scores=Q⋅KT \text{Attention Scores} = Q \cdot K^T Attention Scores=Q⋅KT
结果会通过一个 softmax 函数进行归一化,得到每个位置之间的注意力权重。
加权和: 使用得到的注意力权重来对 Value 进行加权求和:
Output=softmax(Q⋅KT)⋅V \text{Output} = \text{softmax}(Q \cdot K^T) \cdot V Output=softmax(Q⋅KT)⋅V
DoubleCheck
DoubleCheck模型旨在识别长文本中的虚假信息,尤其适用于中文文本的处理。该模型的关键创新点在于采用了双层长短期记忆网络(LSTM)结构以及一种基于自注意力机制的输入重加权,这些设计共同增强了模型对于虚假新闻内容的辨识能力。在构建DoubleCheck模型之前,需先将新闻文本经过分词处理后转换成索引序列形式,作为模型训练的基础输入。此外,还需对生成的索引序列长度执行描述性统计分析,以此为基础决定模型最终采用的一致化序列长度标准。索引序列的描述性统计:
| count | 10090 |
|---|---|
| mean | 994.24 |
| std | 1251.14 |
| min | 56 |
| 25% | 205.25 |
| 50% | 582.00 |
| 75% | 1290.00 |
| max | 12337 |
根据索引序列的描述性统计,可以发现不同的新闻篇幅差距明显,最短的新闻仅含56个分词,最长的新闻含有12337个分词,过长或过短的序列长度设置均会对于模型的训练造成影响,设定的序列长度过短,可能会导致信息丢失,无法完整捕捉较长文章的内容;反之,如果序列长度过长,则可能引入大量不必要的填充数据,增加计算负担,并且可能降低模型的训练效率和效果。为了平衡这些因素,本文经过综合考虑后决定将输入序列的长度设定为512。
为了进一步提升模型训练的准确性,本文在训练过程中引入了验证集,以便对每次迭代后的训练结果进行评估。此外,为避免过拟合现象的发生,在每次训练迭代中,通过Dropout层随机地禁用部分神经元的激活值。这一策略能够有效阻止神经元间形成过于复杂的相互依赖关系,进而增强模型的泛化性能。
在损失函数和模型优化器的选择上,本文选择的损失函数为二元交叉熵损失函数BCEWithLogitsLoss ,这是一种结合了sigmoid激活函数和二元交叉熵损失的计算。这种设计使得它在数值上更加稳定,同时减少了计算量。
计算公式如下:
Loss=−1N∑i=1N[yilog(σ(xi))+(1−yi)log(1−σ(xi))] Loss=-\frac{1}{N}\sum_{i=1}^N[y_ilog(\sigma(x_i))+(1-y_i)log(1-\sigma(x_i))] Loss=−N1i=1∑N[yilog(σ(xi))+(1−yi)log(1−σ(xi))]
其中:
- xix_ixi是模型的输出。
- σ(xi)\sigma(x_i)σ(xi) 是sigmoid激活函数,σ(x)=11+e−x\sigma(x) = \frac{1}{1 + e^{-x}}σ(x)=1+e−x1。
- yiy_iyi是实际的标签,0 或 1。
- NNN是样本的数量。
模型优化器选择Adam优化器,这是一种基于梯度的优化算法,它结合了Momentum动量和RMSProp自适应学习率的有限,在处理稀疏梯度问题时效果显著,适用于大规模数据集和高维参数空间。
训练模型过程中,设置迭代次数10次,每次迭代后在验证集上对模型训练结果进行评估,计算其准确率、精确率、召回率和F1分数,同时在训练过程中记录损失函数值,绘制Loss曲线。
Loss曲线:
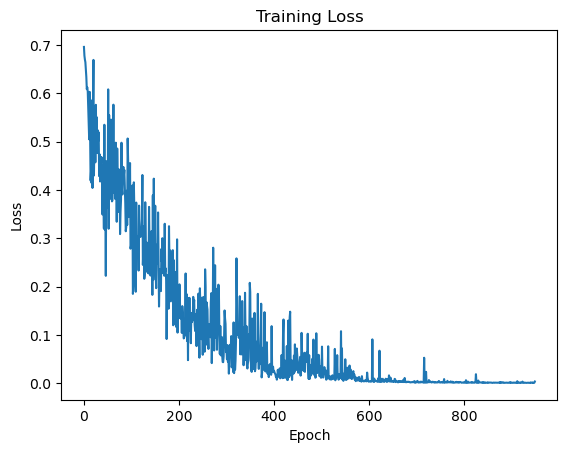
依据最终的预测结果,绘制混淆矩阵并生成分类报告,以评估模型在测试集上的性能。评估结果显示,该模型在正例上的表现尤为突出。此外,模型在检测虚假新闻方面也取得了一定成效,其召回率达到0.70,表明模型已具备初步的假新闻识别能力。然而,为了进一步提升其准确性和可靠性,仍需进行优化与改进。
混淆矩阵如下图所示:
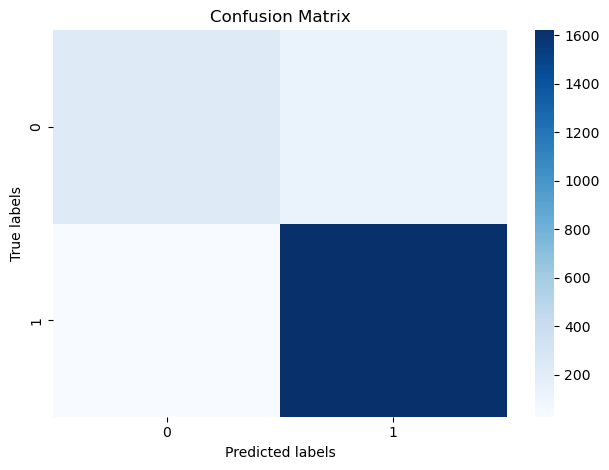
分类报告如下表所示:
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 0 | 0.87 | 0.70 | 0.77 | 370 |
| 1 | 0.93 | 0.98 | 0.96 | 1648 |
| accuracy | 0.93 | 2018 | ||
| macro avg | 0.90 | 0.84 | 0.86 | 2018 |
| weighted avg | 0.92 | 0.93 | 0.92 | 2018 |


















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










