



基于wasserstein生成对抗网络梯度惩罚(WGAN-GP)的图像生成模型 matlab代码,要求2019b及以上版本
最近在折腾图像生成模型,发现WGAN-GP这个玩法比传统GAN稳定不少。它用Wasserstein距离替代JS散度,解决了梯度消失的老大难问题。最妙的是那个梯度惩罚项,不用像原始WGAN那样搞权重裁剪了。咱们今天就用Matlab来撸一个能跑的版本(需要2019b以上,低版本可能缺某些深度学习函数)。
先看生成器结构,这次用全连接层搭个简易版。别小看这个架构,MNIST手写数字生成效果够用了:
function generator = makeGenerator()
layers = [
featureInputLayer(100) % 输入100维噪声
fullyConnectedLayer(7*7*128)
reluLayer
reshapeLayer([7 7 128])
transposedConv2dLayer([4 4],64,'Stride',2,'Cropping',1)
reluLayer
transposedConv2dLayer([4 4],1,'Stride',2,'Cropping',1)
tanhLayer]; % 输出-1到1之间的图像
generator = dlnetwork(layers);
end这里用转置卷积做上采样,注意最后一层用tanh把像素值约束在[-1,1],记得把训练图片也归一化到这个范围。中间那个reshapeLayer是关键,把全连接层输出的向量转成7x7x128的特征图,为后续卷积做准备。
判别器这边更有意思,WGAN-GP要求去掉最后一层的sigmoid,直接输出分数:
function critic = makeCritic()
layers = [
imageInputLayer([28 28 1],'Normalization','none')
convolution2dLayer(5,64,'Stride',2,'Padding',2)
leakyReluLayer(0.2)
convolution2dLayer(5,128,'Stride',2,'Padding',2)
leakyReluLayer(0.2)
fullyConnectedLayer(1) % 直接输出实数,不接sigmoid!
];
critic = dlnetwork(layers);
end注意两点:输入层别加归一化,leaky ReLU的斜率设小点防止梯度爆炸。这个结构比生成器深,因为判别器需要更强的特征提取能力。
重头戏在梯度惩罚的实现。咱们得在真假样本之间随机插值,然后计算梯度:
function penalty = gradientPenalty(critic, realData, fakeData, lambda)
[~,~,N] = size(realData);
epsilon = rand(1,1,1,N); % 随机插值系数
x_hat = epsilon.*realData + (1-epsilon).*fakeData;
% 计算判别器对插值样本的梯度
gradients = dlfeval(@criticGradients, critic, x_hat);
gradients = stripdims(gradients);
norm_gradients = vecnorm(gradients,2,1); % 计算L2范数
penalty = lambda * mean((norm_gradients - 1).^2); # 与1的平方差
end
function grad = criticGradients(critic, x)
scores = forward(critic, x);
grad = dlgradient(scores, x);
end这段代码有几个细节:用stripdims去掉自动添加的维度,vecnorm算梯度范数时注意维度。lambda一般设在10左右,这个超参数别乱改,论文里验证过的最优值。
基于wasserstein生成对抗网络梯度惩罚(WGAN-GP)的图像生成模型 matlab代码,要求2019b及以上版本
训练循环部分和普通GAN差别挺大,看这个核心代码:
for epoch = 1:numEpochs
for i = 1:numBatches
% 从数据存储区读取真实图像
realData = next(imdsTrain);
realData = dlarray(realData, 'SSCB'); % 维度顺序重要!
% 生成假图像
noise = randn(100,1,1,batchSize);
fakeData = forward(generator, noise);
% 更新判别器(Critic)
[criticGrad, gp] = dlfeval(@modelGradients, critic, generator, realData, noise);
critic.LearnRate = 1e-4; % 学习率要比生成器小
critic = adamupdate(critic, criticGrad, critic.LearnRate);
% 每5次更新一次生成器
if mod(iter,5)==0
genGrad = dlfeval(@generatorGradients, generator, critic, noise);
generator.LearnRate = 5e-4;
generator = adamupdate(generator, genGrad, generator.LearnRate);
end
% 损失计算和监控
currentLoss = mean(scoresFake - scoresReal) + gp;
end
end注意判别器要比生成器多更新几次(这里5:1的比例),这是WGAN-GP的关键策略。用Adam优化器时记得调小β1参数(比如0.5),防止更新幅度过大。
实际跑起来后你会发现几个现象:初期生成的像噪点,约20个epoch后数字轮廓开始显现。损失值可能上下波动,但整体趋势应该是判别器损失缓慢上升,生成器损失缓慢下降。如果出现NaN,八成是梯度爆炸,试试调小学习率或梯度惩罚系数。
最后说个实用技巧:在训练过程中定期保存生成样本,用matlab的montage函数拼成图片墙,能直观看到生成质量的演变。想要更清晰的图像,可以把生成器的全连接层换成更深的卷积结构,不过训练时间会翻倍。
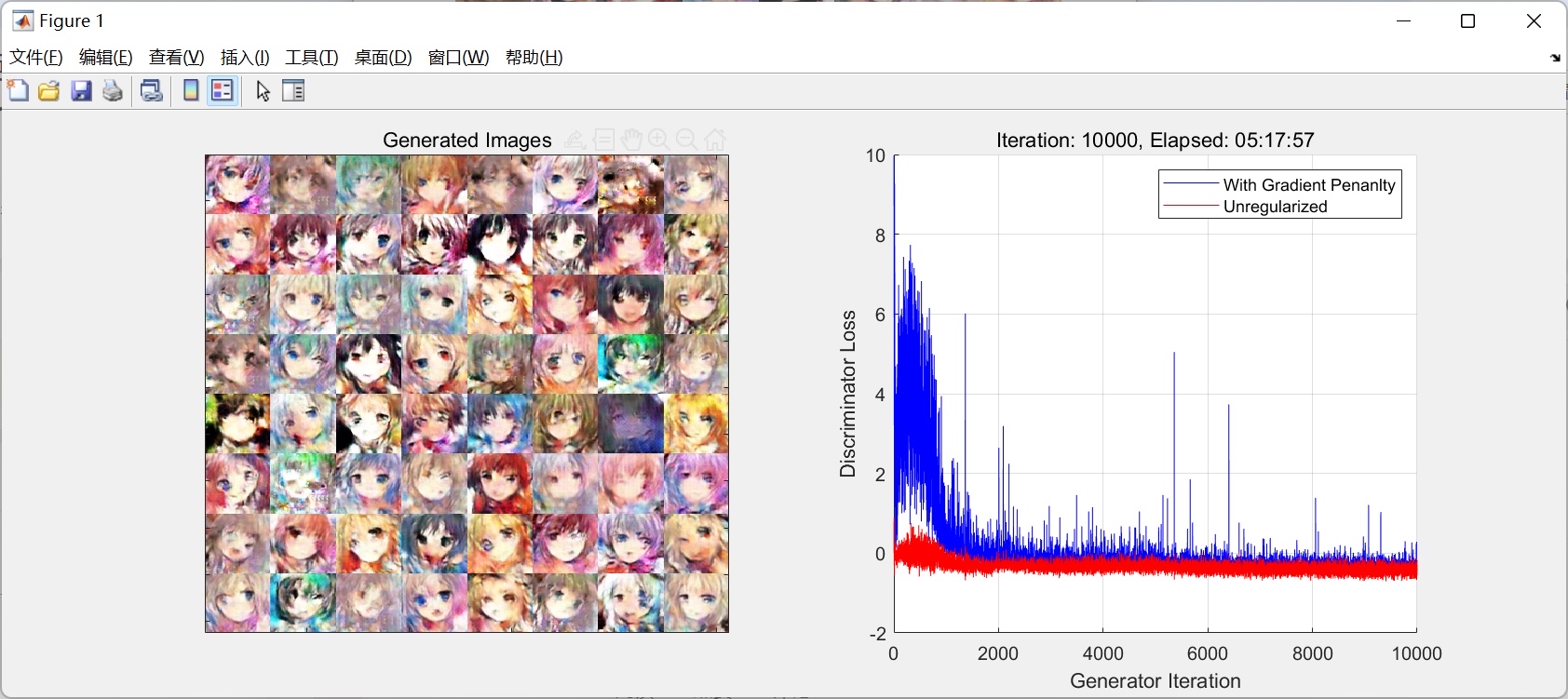
完整代码大概200行左右,跑起来显存占用不到2G(batch_size=64的情况下)。虽然比不过PyTorch的效率,但Matlab的自动微分和可视化工具链用着是真香。下次可以试试在CIFAR-10上搞彩色图像生成,不过得把卷积核数量翻倍才行。


















 1804
1804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










