




这次测试的目标很直接:看看 Qwen3.6-35B-A3B-AWQ-4bit 在双 RTX 4090 上,用 vLLM 跑起来以后,吞吐、延迟、长输入长输出和 speculative decoding 的表现大概落在哪个区间。
部署命令如下。这里没有额外改动模型,也不额外补充测试结果之外的推测,后面的判断都只基于这组实测数据。
vllm serve /model/cyankiwi/Qwen3.6-35B-A3B-AWQ-4bit \
--host 0.0.0.0 \
--port 8000 \
--served-model-name Qwen3.6-35B-A3B \
--tensor-parallel-size 2 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice --tool-call-parser qwen3_coder \
--speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
从结果看,这套配置的可用性是明确的。所有测试都是 0 failed requests,双卡显存监控显示两张卡都在约 23086 MiB,占单卡 24GB 的 93.9% 左右,没有出现一张卡明显闲着、另一张卡顶满的失衡状态。真正需要取舍的是吞吐和延迟:并发拉上去以后,output tokens/s 很快变漂亮,但首字延迟和端到端延迟也会同步变重。
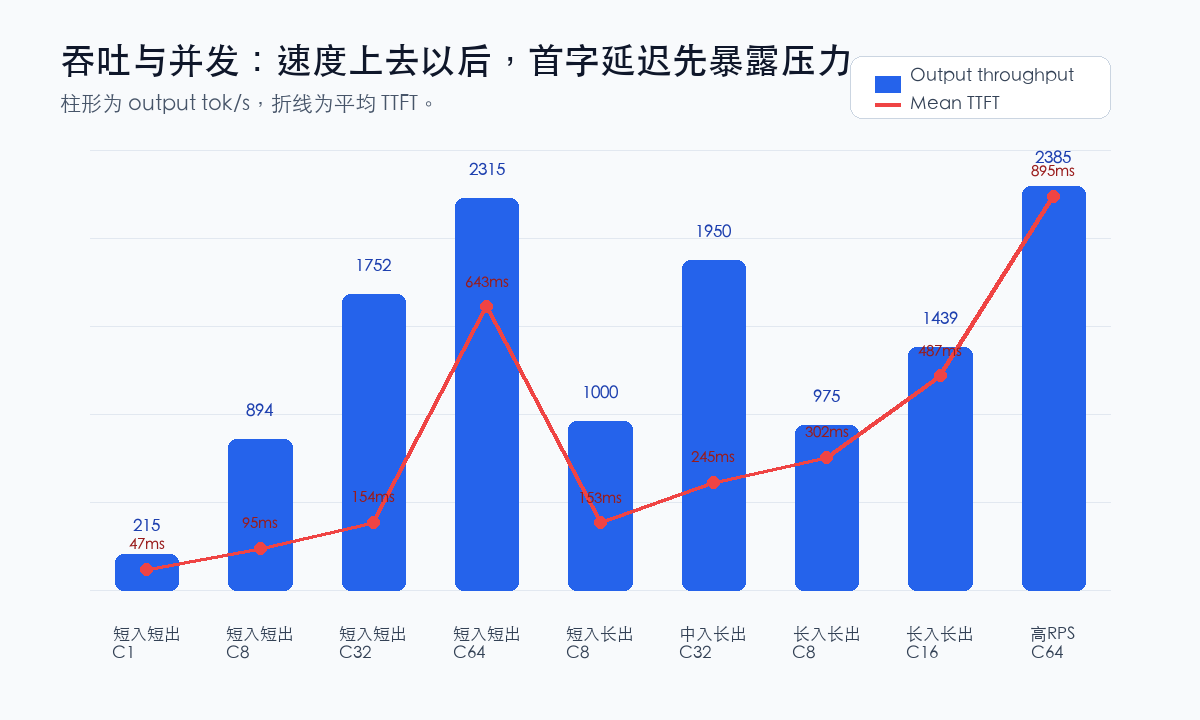
短输入、短输出的压力下,低并发时体验非常轻。C1 场景平均 TTFT 只有 47.39 ms,平均 TPOT 4.32 ms,平均端到端 595.82 ms。这类请求对用户来说基本就是“点完就开始吐字”。
并发上来后,吞吐提升很明显。短输入短输出从 C8 到 C32,输出吞吐从 894.31 tok/s 提到 1751.77 tok/s;继续到 C64,输出吞吐到 2315.20 tok/s,总 token 吞吐达到 4818.78 tok/s。这说明双卡 4090 + AWQ 4bit 在批量服务场景下确实能把 vLLM 的连续批处理吃起来。
但同一组里也能看到代价。C64 的平均 TTFT 已经到 643.34 ms,P90 TTFT 1075.88 ms,P99 TTFT 2467.74 ms。如果业务是离线批处理或后台生成,这个换法很划算;如果是强交互聊天,C64 不一定是舒服的档位。更稳妥的服务区间大概在 C8 到 C32 之间,吞吐已经明显上来,首字延迟还没有完全失控。
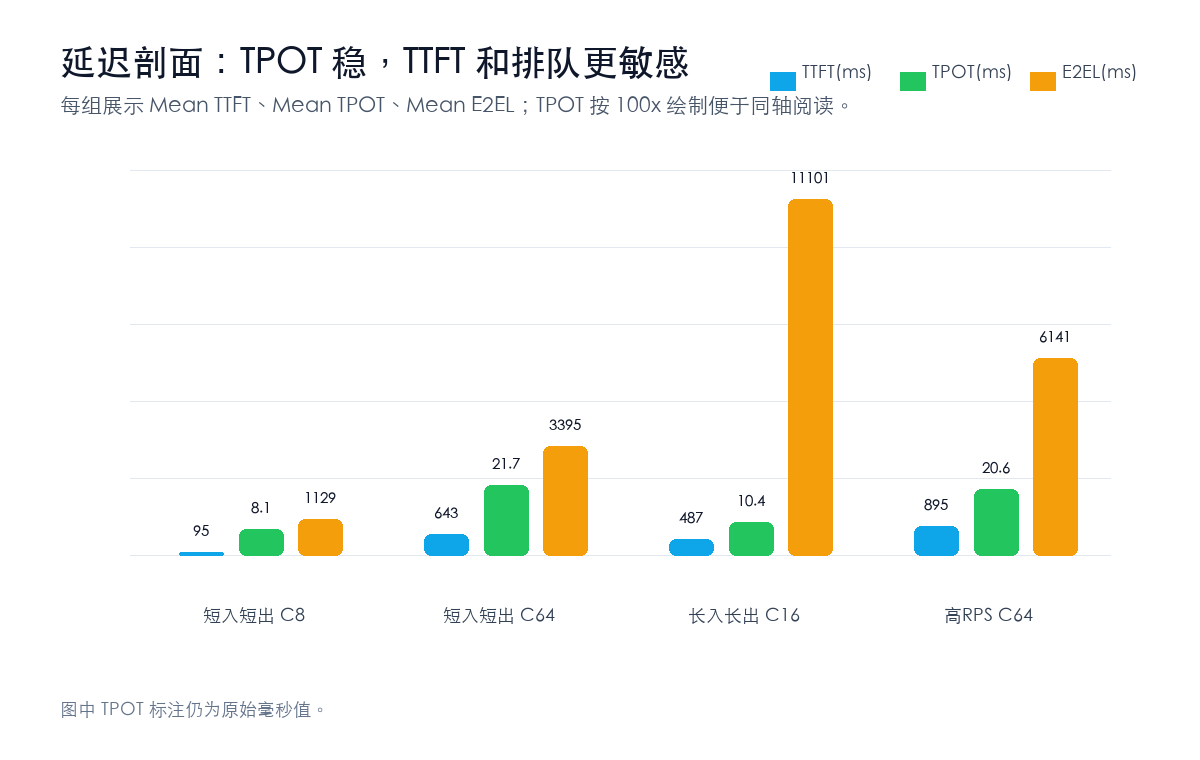
这组数据里,TPOT 比 TTFT 更像“模型持续输出时的底盘”。短输入短输出 C8 的平均 TPOT 是 8.14 ms,短输入长输出 C8 是 7.62 ms,长输入长输出 C8 是 7.74 ms。也就是说,在相同并发量级下,进入稳定解码后,每个输出 token 的间隔并没有因为输出变长而明显恶化。
真正变敏感的是首字和排队。长输入长输出 C8 的平均 TTFT 是 301.66 ms,到了 C16 变成 487.45 ms,P90 TTFT 直接到 1224.10 ms。这和直觉一致:长上下文会把 prefill 压力放大,并发再叠上去,用户最先感受到的不是“字变慢”,而是“第一句话出来得更晚”。
端到端延迟也在提醒我们,不同负载不能只拿 output tok/s 比。短输入长输出 C8 的平均 E2EL 是 4045.50 ms,中等输入长输出 C32 是 8194.45 ms,长输入长输出 C16 到 11100.69 ms。如果一个接口常常要处理 2K 左右输入并生成 1K 左右输出,就不能拿短输入短输出的吞吐峰值来估算用户等待时间。
| 场景 | 请求数 | 最大并发 | 输出吞吐 | 平均 TTFT | 平均 TPOT | 平均 E2EL | 接受率 |
|---|---|---|---|---|---|---|---|
| 短入短出 C1 | 100 | 1 | 214.62 | 47.39 ms | 4.32 ms | 595.82 ms | 70.65% |
| 短入短出 C8 | 200 | 8 | 894.31 | 94.95 ms | 8.14 ms | 1129.22 ms | 69.83% |
| 短入短出 C32 | 400 | 32 | 1751.77 | 154.43 ms | 16.87 ms | 2296.32 ms | 64.66% |
| 短入短出 C64 | 400 | 64 | 2315.20 | 643.34 ms | 21.67 ms | 3395.27 ms | 69.19% |
| 短入长出 C8 | 200 | 8 | 1000.16 | 152.92 ms | 7.62 ms | 4045.50 ms | 72.33% |
| 中入长出 C32 | 320 | 32 | 1949.64 | 244.61 ms | 15.56 ms | 8194.45 ms | 72.04% |
| 长入长出 C8 | 80 | 8 | 975.13 | 301.66 ms | 7.74 ms | 8215.37 ms | 74.16% |
| 长入长出 C16 | 80 | 16 | 1438.52 | 487.45 ms | 10.37 ms | 11100.69 ms | 75.23% |
| 高 RPS C64 | 320 | 64 | 2385.38 | 895.23 ms | 20.57 ms | 6140.91 ms | 70.01% |
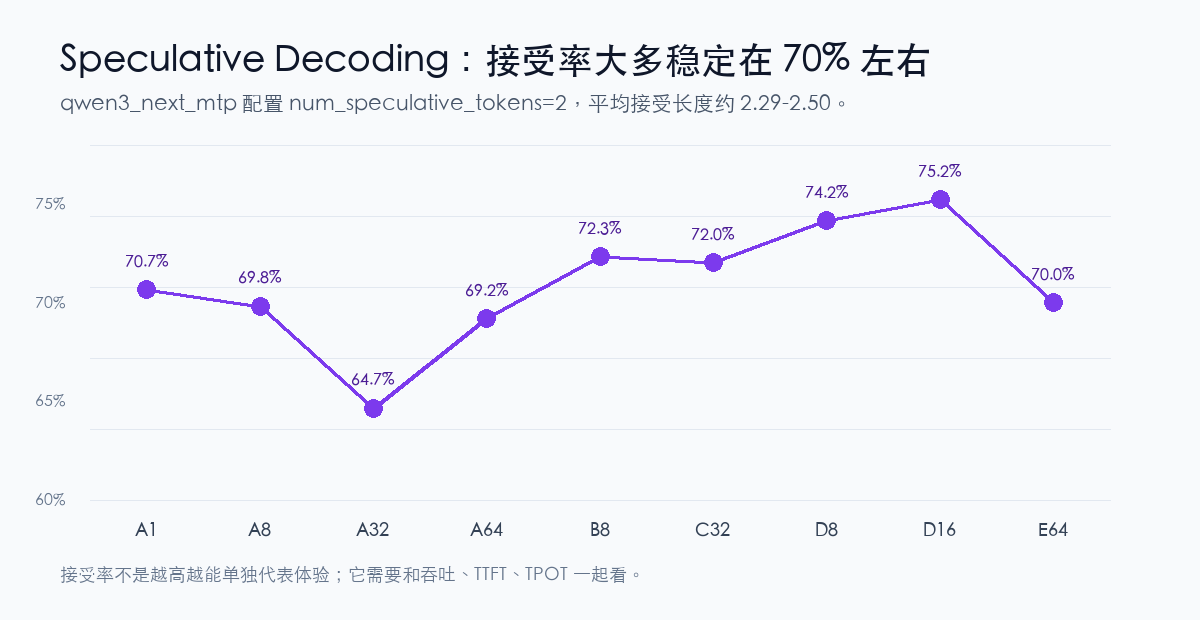
这次启用了 qwen3_next_mtp,num_speculative_tokens=2。speculative decoding 的接受率大多在 70% 左右,最低的短入短出 C32 是 64.66%,最高的长入长出 C16 是 75.23%。平均接受长度也很集中,基本在 2.29 到 2.50 之间。
这个结果比较干净:MTP 没有在某个负载下完全塌掉,也没有出现接受率大幅跳水。它能不能继续提高吞吐,还要看不开 speculative 的对照组;但只看这批数据,至少可以确认这一配置在双 4090 上跑得稳定,并且不同输入长度下接受率波动不大。
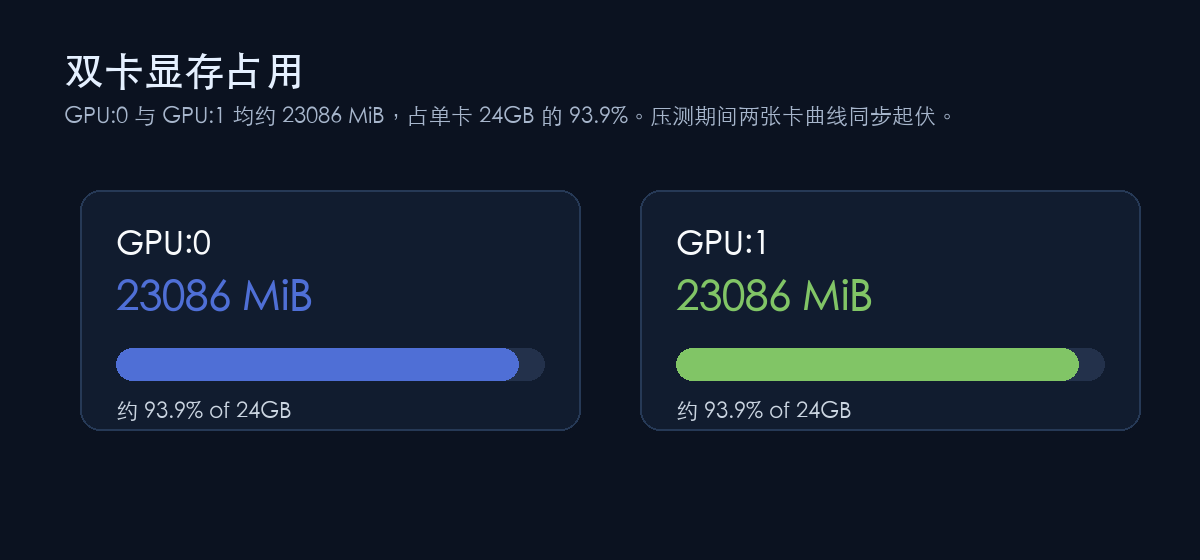
显存这张图也值得单独看。压测期间两张卡都在约 23086 MiB,占单卡 24GB 的 93.9% 左右,曲线同步起伏。对于 --tensor-parallel-size 2 来说,这种同步性是好信号:模型切分和推理负载都确实落到了两张卡上。
不过它也说明余量并不大。双 4090 部署 35B 级 AWQ 4bit 模型可行,但长上下文、并发、工具调用、服务端其他进程都会继续吃显存。--max-model-len 262144 给了很长的上下文上限,可是真正上线时不建议只看“能不能启动”,还要按实际业务的输入长度、输出长度和并发去压一遍。
如果把这组结果用于服务配置,我会把它看成一个很实用的参照:短请求高并发可以冲到 2300+ output tok/s,中等输入长输出在 C32 下也有 1949.64 output tok/s;面向交互体验时,C8 到 C32 更像默认工作区间;面向长上下文任务时,要重点盯 TTFT 和 E2EL,而不是只看持续输出时的 TPOT。
最后,这不是“4090 双卡无脑跑 262K 上下文”的结论。更准确地说,它证明了这套 vLLM 命令能把 Qwen3.6-35B-A3B-AWQ-4bit 稳定拉起来,并在不同请求形态下给出一组可参考的速度边界。后续如果要继续优化,最值得补的不是更漂亮的单点数字,而是同一批负载下关闭 speculative decoding 的对照、不同 max_num_batched_tokens / 并发限流策略的对照,以及真实业务 prompt 的长尾延迟。



















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










