




 该研究提出了一种模型无关的可认证防御策略,针对基于同义词替换的文本对抗攻击。通过定义平滑分类器和使用随机词替换扰动,该方法能够在不检查所有对抗样本的情况下,验证模型预测的一致性。关键在于计算置信度边界,确保对任意扰动,模型预测保持不变。通过蒙特卡罗估计和紧密性分析,该方法提供了一种统计上严格的方法来验证模型的鲁棒性。
该研究提出了一种模型无关的可认证防御策略,针对基于同义词替换的文本对抗攻击。通过定义平滑分类器和使用随机词替换扰动,该方法能够在不检查所有对抗样本的情况下,验证模型预测的一致性。关键在于计算置信度边界,确保对任意扰动,模型预测保持不变。通过蒙特卡罗估计和紧密性分析,该方法提供了一种统计上严格的方法来验证模型的鲁棒性。
1 研究目的
针对基于同义词替换的文本对抗攻击,提出一种模型无关的可认证防御方案。
2 问题定义
2.1 基于同义词替换的文本对抗攻击
在文本分类任务中,模型f(X)f(\mathbf{X})f(X)将输入X∈X\mathbf{X} \in \mathcal{X}X∈X映射为标签ccc,其中X=x1,..,xL\mathbf{X}=x_1,..,x_LX=x1,..,xL是由LLL个单词组成的句子。本文关注的攻击方式指,攻击者根据同义词表,任意地用同义词替换句子中的单词,以误导模型。
具体来说,对于任意单词xxx,考虑一个预先定义的同义词集合SxS_xSx,其中包含xxx的同义词和xxx本身。本文假设同义词关系是对称的,即xxx存在于xxx的所有同义词的同义词集合内。同义词集合SxS_xSx可以基于GLOVE构建。
给定输入句子X=x1,..,xL\mathbf{X}=x_1,..,x_LX=x1,..,xL,攻击者可以将X\mathbf{X}X中最多R≤LR\leq LR≤L个单词xix_ixi扰动为它们的同义词x′i∈Sxix{'}_{i} \in S_{x_i}x′i∈Sxi,构建出对抗样本X′=x1′,..,xL′\mathbf{X'}=x'_1,..,x'_LX′=x1′,..,xL′。:
SX:={X′:∣∣X′−X∣∣0≤R,xi′∈Sxi,∀i}, S_{\mathbf{X}}:=\{\mathbf{X}':||\mathbf{X}'-\mathbf{X}||_0 \leq R,x'_i\in S_{x_i}, \forall i \}, SX:={X′:∣∣X′−X∣∣0≤R,xi′∈Sxi,∀i},
其中SXS_{\mathbf{X}}SX代表对抗样本候选集合。∣∣X′−X∣∣0||\mathbf{X}'-\mathbf{X}||_0∣∣X′−X∣∣0为汉明距离。攻击者的目标是找到X′∈SX\mathbf{X}'\in S_{\mathbf{X}}X′∈SX满足f(X′)≠f(X)f(\mathbf{X}') \neq f(\mathbf{X})f(X′)=f(X)。
2.2 可认证鲁棒(Certified Robustness)
形式化地,如果模型fff能够对所有可能的单词替换扰动一致地给出正确的预测,即,
y=f(X)=f(X′),∀X′∈SX,(1)
y=f(\mathbf{X})=f(\mathbf{X}'), \forall \mathbf{X}' \in S_{\mathbf{X}}, \tag1
y=f(X)=f(X′),∀X′∈SX,(1)
其中yyy代表样本X\mathbf{X}X的真实标签。除非有额外的结构信息可用,否则这需要检查SXS_{\mathbf{X}}SX中的所有候选句子,其数量随RRR呈指数增长。本文主要考虑最具挑战性的R=LR=LR=L的情况。
2.3 验证平滑分类器(Certifying Smoothed Classifiers)
本文的思想是用一个更加平滑的模型来替代fff。平滑分类器fRSf^{RS}fRS通过在输入空间引入随机扰动构建,
fRS=arg maxc∈YPZ∼ΠX(f(Z)=c)
f^{RS}=\argmax_{c \in \mathcal{Y}} \mathbb{P}_{\mathbf{Z} \sim Π_{\mathbf{X}}} (f(\mathbf{Z})=c)
fRS=c∈YargmaxPZ∼ΠX(f(Z)=c)
其中,ΠXΠ_{\mathbf{X}}ΠX是输入空间上的概率分布,它规定了X\mathbf{X}X周围的随机扰动。我们将fRSf^{RS}fRS对标签ccc的置信度定义为:
gRS(X,c):=PZ∼ΠX(f(Z)=c)。
g^{RS}(\mathbf{X},c):=\mathbb{P}_{\mathbf{Z} \sim Π_{\mathbf{X}}} (f(\mathbf{Z})=c)。
gRS(X,c):=PZ∼ΠX(f(Z)=c)。
需要合适地选择扰动分布,以便fRS(X)f^{RS}(\mathbf{X})fRS(X)近似f(X)f(\mathbf{X})f(X),同时也要足够随机,使得fRSf^{RS}fRS足够光滑,以便进行鲁棒性验证。
本文将ΠXΠ_{\mathbf{X}}ΠX定义为在随机词替换集合上的均匀分布(uniform distribution)。具体而言,设PxP_{x}Px是词汇表中单词xxx的扰动集,这与同义词集SxS_xSx不同。本文通过余弦相似度计算GLOVE上的top K最近邻居来构建PxP_{x}Px,其中KKK是一个超参数,控制扰动集合的大小。
对于句子X=x1,...,xL\mathbf{X}=x_1,...,x_LX=x1,...,xL,sentence-level的扰动分布ΠXΠ_{\mathbf{X}}ΠX被定义为每个单词等概率地被独立随机地扰动为PxiP_{x_i}Pxi中的词,即,
ΠX(Z)=Πi=1LI{zi∈Pxi}∣Pxi∣,
Π_{\mathbf{X}}(\mathbf{Z})= Π_{i=1}^{L}\frac{\mathbb{I}\{z_i \in P_{x_i}\}}{|P_{x_i}|},
ΠX(Z)=Πi=1L∣Pxi∣I{zi∈Pxi},
其中,Z=z1,...,zL\mathbf{Z}=z_1,...,z_LZ=z1,...,zL是扰动文本,∣Pxi∣|P_{x_i}|∣Pxi∣代表PxiP_{x_i}Pxi的大小。I{.}\mathbb{I}\{.\}I{.}是指示函数。
指示函数的含义是:当输入为True的时候,输出为1,输入为False的时候,输出为0。
请注意,随机扰动Z\mathbf{Z}Z和对抗候选样本X′∈SX\mathbf{X}' \in S_{\mathbf{X}}X′∈SX是不同的。
3 可认证鲁棒
fRSf^{RS}fRS鲁棒的可认证的条件是,对于任意的X′∈SX\mathbf{X}' \in S_{\mathbf{X}}X′∈SX,都有y=fRS(X′)y=f^{RS}(\mathbf{X}')y=fRS(X′),其中yyy是真实标签。满足它的充分条件是,
minX′∈SXgRS(X′,y)≥maxX′∈SXgRS(X′,c),∀c≠y, \min_{\mathbf{X}' \in S_{\mathbf{X}}} g^{RS}(\mathbf{X}',y) \geq \max_{\mathbf{X}' \in S_{\mathbf{X}}}g^{RS}(\mathbf{X}',c), \forall c \neq y, X′∈SXmingRS(X′,y)≥X′∈SXmaxgRS(X′,c),∀c=y,
其中,gRS(X′,y)g^{RS}(\mathbf{X}',y)gRS(X′,y)的下边界大于任意c≠yc \neq yc=y时gRS(X′,c)g^{RS}(\mathbf{X}',c)gRS(X′,c)的上边界。因此,关键步骤是计算任意c∈Yc \in \mathcal{Y}c∈Y和X′∈SX\mathbf{X}' \in S_{\mathbf{X}}X′∈SX,gRS(X′,c)g^{RS}(\mathbf{X}',c)gRS(X′,c)的上下边界。
3.1 Theorem 1(可认证的上/下边界)
假设对于每个单词xxx及其同义词x′∈Sxx' \in S_{x}x′∈Sx,扰动集PxP_xPx满足∣Px∣=∣Px′∣|P_{x}|=|P{x'}|∣Px∣=∣Px′∣。我们定义,
qx=minx′∈Sx∣Px∩Px′∣/∣Px∣, q_x=\min_{x' \in S_{x}} |P_x \cap P_{x'}|/|P_{x}|, qx=x′∈Sxmin∣Px∩Px′∣/∣Px∣,
其中,qxq_xqx表示两个不同扰动集之间的重叠。对于一个给定的句子X=x1,...,xL\mathbf{X}=x_1,...,x_LX=x1,...,xL,我们根据qxq_xqx排列所有的单词,使qxi1≤qxi2≤...≤qxiLq_{{x_i}_1} \leq q_{{x_i}_2} \leq ... \leq q_{{x_i}_L}qxi1≤qxi2≤...≤qxiL。可以得到,
minX′∈SXgRS(X′,c)≥max(gRS(X,c)−qX,0) \min_{\mathbf{X}' \in S_{\mathbf{X}}} g^{RS}(\mathbf{X}',c) \geq\max(g^{RS}(\mathbf{X},c)-q_{\mathbf{X}},0) X′∈SXmingRS(X′,c)≥max(gRS(X,c)−qX,0)
maxX′∈SXgRS(X′,c)≤min(gRS(X,c)+qX,1). \max_{\mathbf{X}' \in S_{\mathbf{X}}} g^{RS}(\mathbf{X}',c) \leq\min(g^{RS}(\mathbf{X},c)+q_{\mathbf{X}},1). X′∈SXmaxgRS(X′,c)≤min(gRS(X,c)+qX,1).
其中qX:=1−Πj=1Rqxijq_{\mathbf{X}}:=1-Π_{j=1}^{R}q_{{x_{i}}_j}qX:=1−Πj=1Rqxij。这表示,对于任意c∈Yc \in \mathcal{Y}c∈Y,有∣gRS(X′,c)−gRS(X,c)∣≤qX|g^{RS}(\mathbf{X}',c)-g^{RS}(\mathbf{X},c)|\leq q_{\mathbf{X}}∣gRS(X′,c)−gRS(X,c)∣≤qX。主要思想是,通过随机平滑,对于任意X′∈SX\mathbf{X}' \in S_{\mathbf{X}}X′∈SX,gRS(X′,c)g^{RS}(\mathbf{X}',c)gRS(X′,c)和gRS(X,c)g^{RS}(\mathbf{X},c)gRS(X,c)的差距最多是qXq_{\mathbf{X}}qX。
因此,gRS(X′,c)g^{RS}(\mathbf{X}',c)gRS(X′,c)的上边界上\下边界为gRS(X,c)±qXg^{RS}(\mathbf{X},c) \pm q_{\mathbf{X}}gRS(X,c)±qX
这避免了困难的对抗性优化,而只需要在原始输入上评估gRS(X,c)g^{RS}(\mathbf{X},c)gRS(X,c)。
Theorem 1 证明
Lemma 1 将X{X}X映射为0或1的全部有界函数定义为H[0,1]\mathcal{H}_{[0,1]}H[0,1],对所有h∈H[0,1]h \in \mathcal{H_{[0,1]}}h∈H[0,1],定义ΠX[h]=EZ∼ΠX[h(Z)]Π_{{X}}[h]=\mathbb{E}_{Z \sim Π_{{X}}}[h(Z)]ΠX[h]=EZ∼ΠX[h(Z)]。
那么,对于任意X{X}X和任意x∈Yx \in \mathcal{Y}x∈Y,都有
minX′∈ΠXgRS(X′,c)≥minh∈H[0,1]minX′∈ΠX{ΠX′[h]s.t.ΠX[h]=gRS(X,c)}:=glowRS(X,c)
\min_{{X}' \in Π_{{X}}}g^{RS}({X}',c) \geq \min_{h \in \mathcal{H}_{[0,1]}}\min_{{X}' \in Π_{{X}}}\{Π_{{X}'}[h] \quad s.t. \quadΠ_{{X}}[h]=g^{RS}(X,c) \}:=g^{RS}_{low}(X,c)
X′∈ΠXmingRS(X′,c)≥h∈H[0,1]minX′∈ΠXmin{ΠX′[h]s.t.ΠX[h]=gRS(X,c)}:=glowRS(X,c)
maxX′∈ΠXgRS(X′,c)≤maxh∈H[0,1]maxX′∈ΠX{ΠX′[h]s.t.ΠX[h]=gRS(X,c)}:=gupRS(X,c)
\max_{{X}' \in Π_{{X}}}g^{RS}({X}',c) \leq \max_{h \in \mathcal{H}_{[0,1]}}\max_{{X}' \in Π_{{X}}}\{Π_{{X}'}[h] \quad s.t. \quadΠ_{{X}}[h]=g^{RS}(X,c) \}:=g^{RS}_{up}(X,c)
X′∈ΠXmaxgRS(X′,c)≤h∈H[0,1]maxX′∈ΠXmax{ΠX′[h]s.t.ΠX[h]=gRS(X,c)}:=gupRS(X,c)
Lemma 1 证明
证明很直接。定义h0[X]=I{f(X)=c}h_{0}[X]=\mathbb{I}\{f(X)=c\}h0[X]=I{f(X)=c},由于
gRS(X,c)=PZ∼ΠX(f(Z)=c)=ΠX[h0].
g^{RS}(X,c) = \mathbb{P}_{Z∼Π_X} (f(Z) = c) = Π_X[h_0].
gRS(X,c)=PZ∼ΠX(f(Z)=c)=ΠX[h0].
因此,h0h_0h0满足优化中的约束,显然
gRS(X′,c)=ΠX′[h0]≥min{ΠX′[h]s.t.ΠX[h]=gRS(X,c)}
g^{RS}(X', c) = Π_X' [h_0] ≥ \min \{Π_{X'} [h] \quad s.t. \quad Π_X[h] = g^{RS}(X, c)\}
gRS(X′,c)=ΠX′[h0]≥min{ΠX′[h]s.t.ΠX[h]=gRS(X,c)}
在两边取minX′∈SX\min_{X'} \in S_XminX′∈SX得出下界。上界遵循相同的推导。
因此,问题归结为优化问题的推导边界。
| 数学符号 | 含义 |
|---|---|
| XXX | 输入样本 |
| ΠXΠ_XΠX | 输入空间上的概率分布,规定了XXX周围的随机扰动 |
| gRS(X,c)g^{RS}(X, c)gRS(X,c) | 平滑分类器输出样本XXX关于标签ccc的置信度,等价于PZ∼ΠX(f(Z)=c)\mathbb{P}_{Z\sim Π_X} (f(Z) = c)PZ∼ΠX(f(Z)=c) |
| hhh | 任意将输入映射到0或1的函数 |
| EZ∼ΠX[h(Z)]\mathbb{E}_{Z∼Π_X}[h(Z)]EZ∼ΠX[h(Z)] | 函数hhh接收输入ZZZ产生的输出的期望,简写为ΠX[h]Π_{X}[h]ΠX[h] |
3.2 Proposition1
对于一个句子X\mathbf{X}X及其标签yyy,我们定义,
yB=arg maxc∈Y,c≠ygRS(X,c).
y_{B}=\argmax_{c \in \mathcal{Y}, c \neq y} g^{RS}(\mathbf{X}, c).
yB=c∈Y,c=yargmaxgRS(X,c).
然后,在定理1的条件下,我们可以验证,对于任意X′∈SX\mathbf{X}' \in S_{\mathbf{X}}X′∈SX,都有f(X′)=f(X)=yf(\mathbf{X}')=f(\mathbf{X})=yf(X′)=f(X)=y的条件是,
ΔX=gRS(X,y)−gRS(X,yB)−2qX>0.(2) \Delta_{\mathbf{X}}=g^{RS}(\mathbf{X},y)-g^{RS}(\mathbf{X},y_{B})-2q_{\mathbf{X}} >0. \tag2 ΔX=gRS(X,y)−gRS(X,yB)−2qX>0.(2)
因此,验证模型是否给出了一致正确的预测,只需检查ΔX\Delta_{\mathbf{X}}ΔX是否为正,这可以很容易地通过蒙特卡罗估计实现。如下图所示:
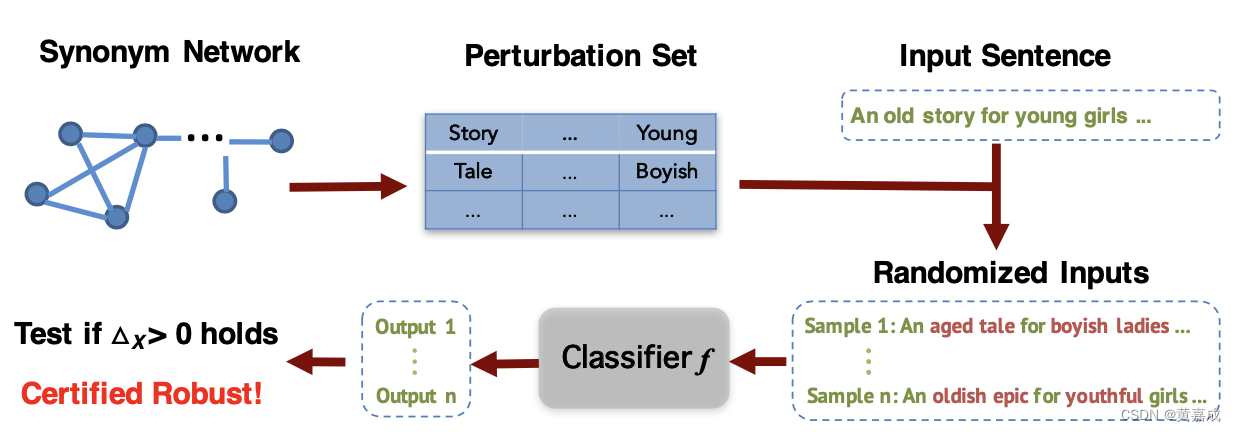
3.3 估计gRS(X,c)g^{RS}(\mathbf{X},c)gRS(X,c)和ΔX\Delta_{\mathbf{X}}ΔX
可以通过蒙特卡洛估计法来估计gRS(X,c)g^{RS}(\mathbf{X},c)gRS(X,c),即∑i=1nI{f(Z(i)=c)}/n\sum^{n}_{i=1} \mathbb{I}\{f(\mathbf{Z}^{(i)}=c)\}/n∑i=1nI{f(Z(i)=c)}/n,其中,Z(i)\mathbf{Z}^{(i)}Z(i)是ΠXΠ_{\mathbf{X}}ΠX中独立同分布的样本。此外,ΔX\Delta_{\mathbf{X}}ΔX可以相应地近似。
利用浓度不等式,我们可以量化非渐近逼近误差(non-asymptotic approximation error)。这允许我们构建严格的统计过程,以拒绝零假设(null hypothesis),即,以给定的显著性水平(例如,1%),fRSf^{RS}fRS在X\mathbf{X}X处未被证明鲁棒(即ΔX≤0\Delta_{\mathbf{X}} \leq 0ΔX≤0)。
3.4 紧密性
一个关键问题是边界是否足够紧密。下一个定理表明,定理1中的上下界是紧的,不能进一步改进,除非获得模型的进一步信息。
3.5 Theorem2 (紧密性)
假设定理1的条件成立。对于满足命题1中定义的fRS(X)=yf^{RS}(\mathbf{X})=yfRS(X)=y和yBy_ByB的模型fff,存在一个模型f∗f_{*}f∗及其相关的平滑模型g∗RSg^{RS}_{*}g∗RS,当c=yc=yc=y且c=yBc=y_Bc=yB时,满足g∗RS(X,c)=gRS(X,c)g^{RS}_{*}(\mathbf{X},c)=g^{RS}(\mathbf{X},c)g∗RS(X,c)=gRS(X,c),并且,
minX′∈SXg∗RS(X′,y)=max(g∗RS(X,y)−qX,0) \min_{\mathbf{X}' \in S_{\mathbf{X}}} g_{*}^{RS}(\mathbf{X}',y) =\max(g_{*}^{RS}(\mathbf{X},y)-q_{\mathbf{X}},0) X′∈SXming∗RS(X′,y)=max(g∗RS(X,y)−qX,0)
maxX′∈SXg∗RS(X′,yB)=min(g∗RS(X,yB)+qX,1). \max_{\mathbf{X}' \in S_{\mathbf{X}}} g_{*}^{RS}(\mathbf{X}',y_B) =\min(g_{*}^{RS}(\mathbf{X},y_B)+q_{\mathbf{X}},1). X′∈SXmaxg∗RS(X′,yB)=min(g∗RS(X,yB)+qX,1).
换句话说,如果我们只通过gRS(X,y)g^{RS}(\mathbf{X},y)gRS(X,y)和gRS(X,yB)g^{RS}(\mathbf{X},y_B)gRS(X,yB)的评估来访问gRSg^{RS}gRS,那么定理1中的边界的紧密性是我们尽最大可能达到的,因为通过可用的信息,我们无法区分定理2中的gRSg^{RS}_{}gRS和g∗RSg^{RS}_{*}g∗RS。




















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












