




目录
1. 引言与背景
在机器学习领域,统计推断是建立和评估模型的核心方法之一。其中,最大似然估计(Maximum Likelihood Estimation, MLE)作为一项基础且广泛应用的参数估计技术,凭借其直观的原理、坚实的理论基础以及良好的实践效果,成为众多统计模型构建过程中的首选策略。本文旨在系统地阐述最大似然估计的理论基础、算法原理、实现细节、优缺点分析、实际应用案例,并将其与相关算法进行对比,最后展望其在机器学习未来发展的潜在影响。
2. 最大似然定理
最大似然定理是最大似然估计的理论基石。该定理指出,对于一个给定的观测数据集和一个参数化的概率模型,若模型参数的真值未知,那么在所有可能的参数值中,使观测数据出现的概率(即似然函数)最大的那个参数值,可以作为参数的估计值。简而言之,最大似然估计旨在找到能使已知数据最“自然”、最“合理”的模型参数。
数学上,假设数据集 是独立同分布的样本,其共同的概率分布由参数向量 θ 决定。则似然函数
可以表示为所有样本联合发生的概率:
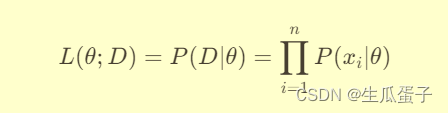
最大似然估计的目标就是找到使似然函数最大化的参数值,即:
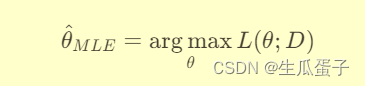
或者等价地最大化对数似然函数(为了计算方便,避免数值下溢):
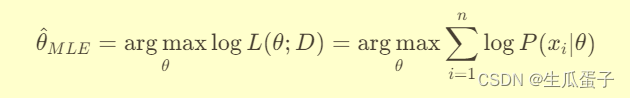



















原理及其应用&spm=1001.2101.3001.5002&articleId=137912409&d=1&t=3&u=1c5be56520c243d9a94d7c2cc99e746f)
 7093
7093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










