



 OpenAI的Whisper模型能高效识别口音和噪声中的语音,转化为文本,随后StableDiffusion依据文本生成图像,实现语音输入到图像输出的转换。用户只需录制音频,经过模型处理,即可得到相应的图像。这是一个将AI技术应用于多模态生成的实例。
OpenAI的Whisper模型能高效识别口音和噪声中的语音,转化为文本,随后StableDiffusion依据文本生成图像,实现语音输入到图像输出的转换。用户只需录制音频,经过模型处理,即可得到相应的图像。这是一个将AI技术应用于多模态生成的实例。
现在热门的不仅是多模态的文本图像生成,前阵子,OpenAI 发布了一个自动语音识别系统 Whispe 。在处理口音、背景噪声以及技术术语方面,Whisper 几乎达到了人类的水准。
那么将 Whisper 与 Stable Diffusion 结合,可以直接完成语音生成图像的任务。用户可以语音输入一个短句,Whisper 会自动将语音转化为文本,接着,Stable Diffusion 会根据文本生成图像。
步骤
第一步:录制音频或上传音频文件
图片来源:huggingface
第二步:检查语言输出,必要时进行更正
图片来源:huggingface
第三步:等待1~10秒,直到有稳定的扩散结果
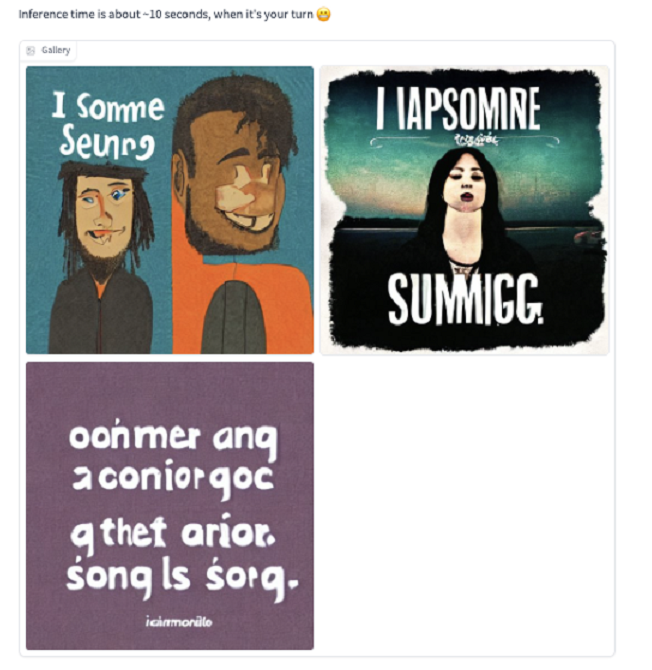
图片来源:huggingface
简单概况一下,Whisper 是一个通用的语音识别模型,它是在各种音频的大型数据集上进行训练的,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。
Stable Diffusion 是一个通过文本生成图像的模型。
将它们们结合起来,你就可以通过语音来直接生成图像。
不如现在就试试看:
https://huggingface.co/spaces/fffiloni/whisper-to-stable-diffusion

社群,请添加客服


















 8710
8710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










