




 本文通过Python与R语言实现决策树,并对比两种语言的优劣。利用Tushare金融数据接口及标准化信用卡违约数据集,实现回归树与分类树,探讨路径依赖问题及线性拆分局限。
本文通过Python与R语言实现决策树,并对比两种语言的优劣。利用Tushare金融数据接口及标准化信用卡违约数据集,实现回归树与分类树,探讨路径依赖问题及线性拆分局限。
摘要及声明
1:本文主要介绍决策树的实现方法及可视化方法;
2:本文主要为理念的讲解,模型也是笔者自建,文中假设与观点是基于笔者对模型及数据的一孔之见,若有不同见解欢迎随时留言交流;
3:笔者希望搭建出一套交易体系,原则是只做干货的分享。后续将更新更多内容,但工作学习之余的闲暇时间有限,更新速度慢还请谅解;
4:本文Python部分的数据通过Tushare金融大数据平台接口获取,R语言部分的数据是用笔者之前上学的作业;
5:本文模型实现基于python3.8及R 4.1.2;
由于笔者后面打算写的几篇主线文章会用到决策树,如果突然出一期主线内容又讲金融原理,又讲技术原理难免显得太过杂乱,于是决定先发一篇把技术实现解决,方便后续可以专注于金融原理上。本文同时通过Python和R语言实现决策树,最后进行了两种语言实现方式的比较,有特定语言需求的读者可以从目录直接跳转,本文主要内容如下:
目录
1. 决策的本质是对数据集进行切分
·根据拟合因变量的类型,决策树可以分为两种:回归树(连续因变量)和分类树(离散因变量)。举个借钱给朋友的栗子,如果我们将收入作为借与不借的唯一标准,那么我们可以生成一颗分类树:
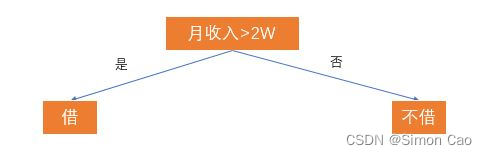
图一:树的要素:根,叶,决策判断条件
我们把月收入称作“根节点”,借与不借(树最下面一行的节点)两个子节点称为“叶”,“借”与“不借”则代表了从根到叶的决策路径。但现实生活中肯定不会那么简单,我们再加入一个失信次数的条件:
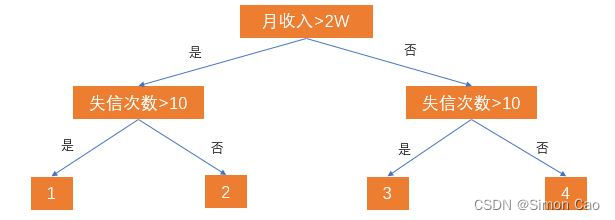
图二:简单的决策树
于是现在的树就分裂出四个叶节点。那么这四个节点分别代表:
1:月收入>2W,失信次数>10次,老赖;
2:月收入>2W,失信次数<=10次,还款能力高,信用高;
3:月收入<=2W,失信次数>10次,要钱没有要命一条;
4:月收入>=2W,失信次数<=10次,还款能力低,但比较诚信;
其实我们已经不知不觉将数据集拆分成了4份:

图三:决策树对数据集的划分
这棵树最大的问题是所有节点的决策阈值都是笔者主观判断给出的。换句话说,我们怎么知道月收入2W是最佳的决策标准?失信次数大于10次是最好的判断依据?可能10次失信里某一次欠了一个亿那岂不是要老命了。
因此,我们需要借助更强大和更理性的算法找到最理想的的决策依据。
2. 回归、分类树是路径依赖问题,线性拆分问题
其实网上已经有很多文章写决策树,写得也很不错。笔者不打算在数学推导上浪费时间,只提一个很容易被忽略的性质:其实决策树也好,回归树也好,都是路径依赖问题,即下一步的决策取决于上一步已经获得的信息。这也是传统技术派的观点,即过去可以代表未来。
为什么路径依赖这条性质十分重要呢?因为很多金融问题并不是路径依赖的,如果依靠路径依赖的模型解决非路径依赖的问题那就是牛头不对马嘴。有没有非路径依赖的模型呢?有,蒙特卡洛模拟,随机游走实验这类方式就不是路径依赖问题,即下一步怎么走是完全独立的,和上一步无关。
其次是线性拆分问题,树的分裂是基于递归二分法,即给定某个阈值,每次采取二叉树的形式分裂。眼尖的人可能发现了,给定的某个阈值导致数据拆分时永远是方形的(例如图三)。而如果数据是非线性分割的,树算法就很容易出现偏差,例如图四中点A本来属于2类,但却被分类算法错误的分进4类中。
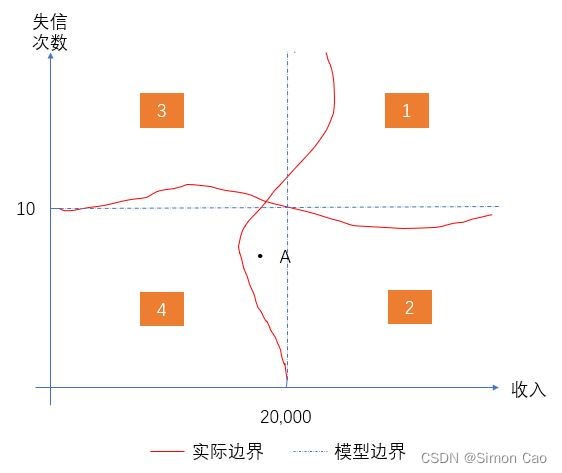
图四:线性切分导致偏差
3. Python实现
Python的sklearn就可以实现算法,也比较简单,但可视化上好一顿折腾:
先导入需要模块:
import tushare as ts
import pandas as pd
from sklearn import tree
import graphviz
如果电脑上完全没有graphviz这个模块,除了pip,还要安装graphviz的一个插件并且将其配置到环境变量里,不然不能输出最后的可视化PDF文件。安装和配置过程可以参考这篇知乎文章:Graphviz安装及使用-决策树可视化 - 知乎,笔者亲测有效。(graphviz出了很多版本,可以随便挑个旧版本的EXE文件下载安装)
数据方面笔者通过Tushare金融数据接口拿了今年11月4号的交易数据,下面获取一下数据:





















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












