



当下 AI 终端编码工具一片红海,Claude Code、Codex、Gemini CLI 都卷到飞起了。
在这种背景下,最近 GitHub 上还是有一款编程工具悄然问世,它叫 omp(oh-my-pi)。
基于 Pi 项目二次开发,Pi 是一个开源 AI 智能体工具包,主打编码 Agent CLI 和多模型统一接口。
扩展后的 omp,定位做一个「能与 IDE 编辑器联动的终端编程工具」。
支持 40+ 模型供应商、内置超 32 个工具,项目核心代码约 27000 行。

比起这些数字,更值得关注的是,它解决了当前 AI 工具的几大痛点。
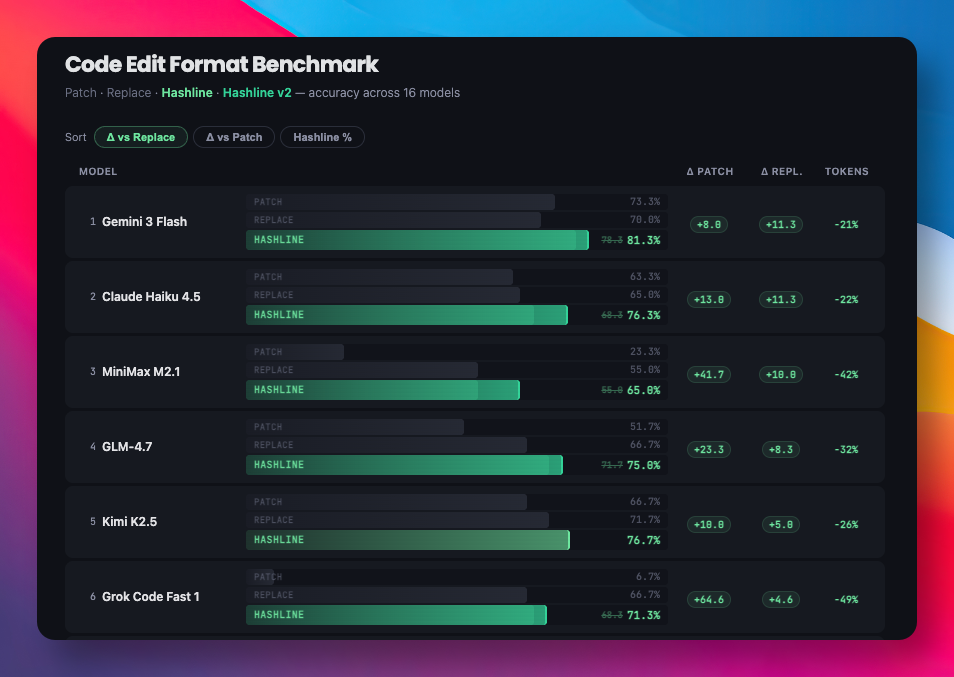
首先是 omp 内部的代码编辑系统,背后用到一个叫 Hashline 的技术。
传统 AI 工具修改代码,会先匹配原代码,再给出修改后的版本,靠的是文本匹配来定位。
这种方式不但 Token 烧得多,模型只要记错一个空格或引号就会匹配失败,反复重试。
而 Hashline 用的是代码的内容哈希作为锚点来定位修改位置。
不仅能解决空白符不匹配,导致 AI 编辑失败的问题,还能减少 61% 的 Token 消耗。
并且将 Grok Code Fast 1 的编辑成功率从 6.7% 直接拉到 68.3%,提升了将近十倍。
对我们普通开发者来说,用 omp 可以节省 API 费用,另外也能减少返工次数。
接着是 IDE 级的深度集成,这是大部分终端 AI 工具都缺失的能力。
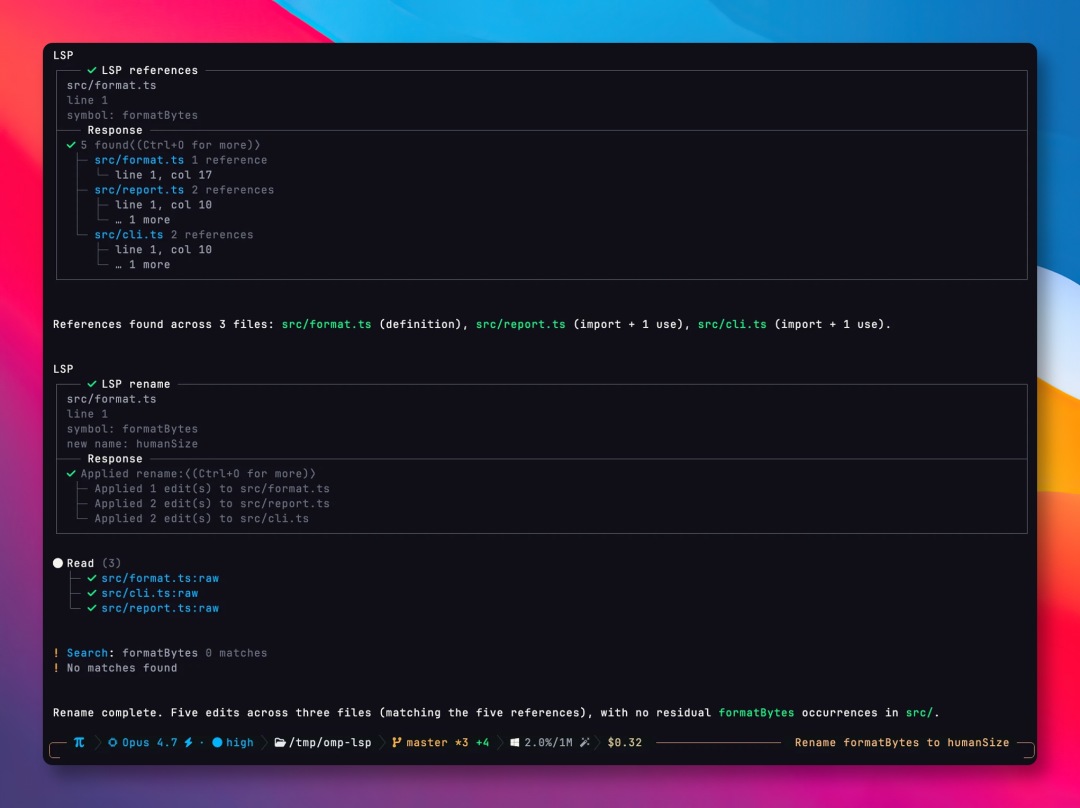
举个例子,让 AI 重命名一个函数,omp 调的不是简单的文本搜索,而是 IDE 底层的代码分析能力。
所有引用这个函数的地方,不论藏在多深的导入关系里,都会被自动同步修改。
代码里的报错信息,omp 也能直接读到,不需要我们手动复制粘贴。
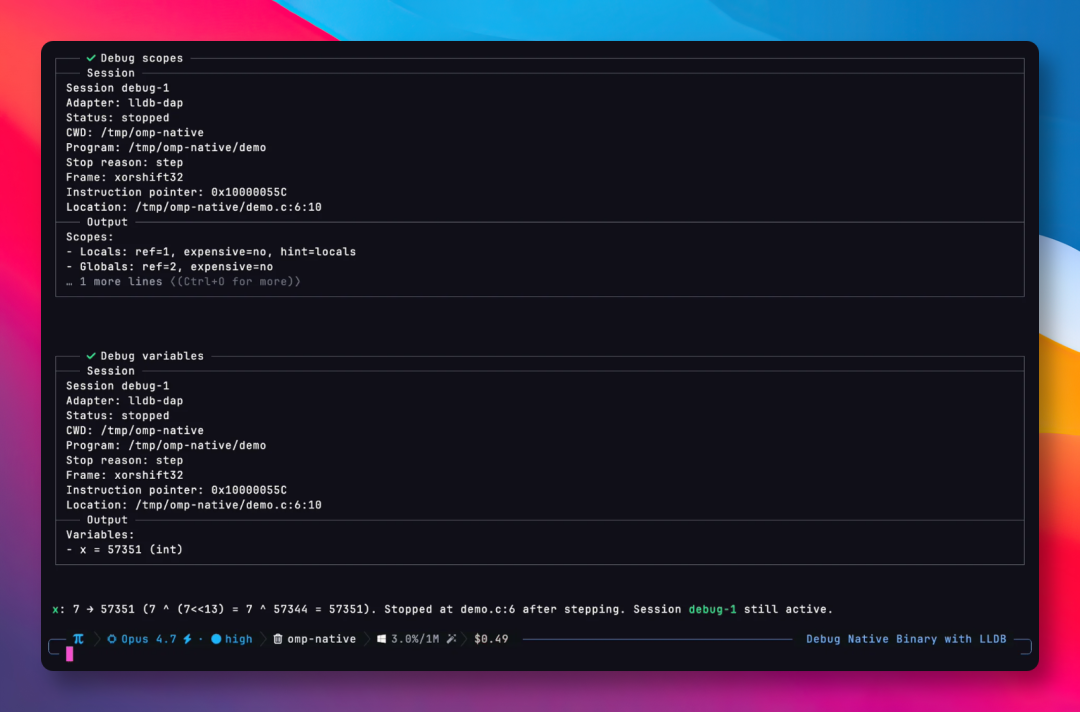
除此之外,omp 还能像 IDE 那样做断点调试。
代码运行报错,大部分 AI 工具只会在代码里增加打印日志一行行的排查。
而 omp 可以设个断点,程序停在出问题的那行,直接读取当前的变量值和调用栈,然后告诉我们问题出在哪。
整个过程不需要我们手动加日志、反复编译运行。
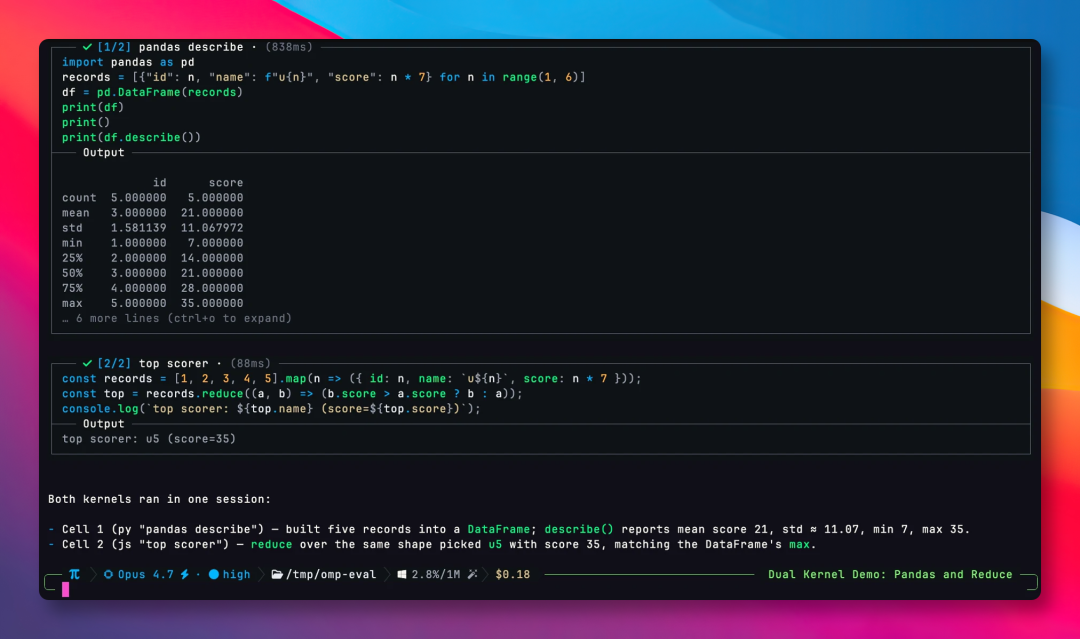
第三个亮点,是模型自由度。
omp 同时支持 Claude、GPT、Gemini、Grok 等四十多家供应商,本地的 Ollama、LM Studio 也都能跑。
并且把模型按任务类型分了路由,在实际使用当中,会自动地切换不同模型。
比如日常对话就用一些普通模型,遇到复杂开发任务时则调用能力更强的大模型。
也支持主动切换模型,只需要输入 /model 命令,或者按 Ctrl+P 直接循环切换。
除了上面三个核心亮点之外,omp 还塞进了不少称得上「全家桶」的能力。
内置网页搜索,背后有 14 个搜索供应商,arxiv 论文、GitHub 项目、Stack Overflow 帖子都能直接读成结构化的内容喂给模型。
它也能驱动一个真实的浏览器,默认开启反爬检测规避模式,不会被网页识别为机器人。
针对复杂任务,omp 支持子智能体并行执行,把任务拆成几个子任务分配给不同的子智能体同时干,最后再合并回来。
另外还有一个比较有意思的能力,叫 Hindsight,可以让智能体在对话之间保留记忆。
这次学到的项目结构,下次开新会话时还在,不用从头解释一遍。
写在最后
这次 omp 的亮点一句话总结,把 IDE、调试器、浏览器的能力,统一到了一个终端 AI 编程工具里。
过去我们用 AI 编码工具,更像是请了一个隔着玻璃看代码的助手,只能根据我们贴出来的文本给建议或修改。
而 omp 试图打破这层玻璃,让 AI 跟我们站在同一个开发环境里,看到同样的报错、读取同样的变量、走完同样的调试流程。
模型编码能力的差距正在缩小,工具链的深度、对开发环境的理解,才是 AI 编程工具接下来真正拉开差距的地方。
omp 是不是最终答案不好说,但它至少补上了目前 AI 终端工具所存在的缺点,给了我们多一个选择。
感兴趣的同学,不妨试下。
GitHub 项目地址:https://github.com/can1357/oh-my-pi
今天的分享到此结束,感谢大家抽空阅读,我们下期再见,Respect!


















 1329
1329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










