




Abstract
图卷积网络 (GCN) 已成为协同过滤的最新技术。然而,它推荐有效性的原因并没有得到很好的理解。该工作还发现 GCN 中最常见的两种设计——特征变换和非线性激活——对协同过滤的性能贡献不大,并且还增加了训练的难度,降低了推荐性能。
在这项工作中,作者提出了一种新的模型LightGCN,只包含GCN中最基本的组件——邻域聚合。具体来说,LightGCN 通过在用户-项目交互图上线性传播来学习用户和项目嵌入,并使用所有层学习到的嵌入的加权和作为最终嵌入。这种简单、线性和整洁的模型更容易实现和训练,与同一个组之前提出的NGCF相比,有明显的改进(平均约 16.0% 的相对改进)。最后对LightGCN的合理性进行了分析。
本文的主要贡献:
- 通过实验说明GCN中的非线性激活以及特征变换对协同过滤没有积极影响
- 提出了LightGCN,结构更加简洁,并且性能更好
- 对LightGCN的合理性进行分析
NGCF
先简单介绍一下NGCF。
NGCF主张在协同过滤中加入对user-item对信息的编码,而不仅仅是只考虑user,item的emmbedding,从而能够获得更多信息,进而进行推荐。实际场景中user-item对的信息很多,所以它借鉴了GCN中的领域聚合的思想,仿照GCN的结构,每一层聚合周围邻居的信息,从而在多层之后实现对多跳邻居的信息的收集。
具体来说,每一层的信息传播公式为
mu←i(l)=1∣Nu∣∣Ni∣(W1(l)ei(l−1)+W2(l)(ei(l−1)⊙eu(l−1))) m_{u\leftarrow i}^{(l)}=\frac{1}{\sqrt{|N_u||N_i|}}(W_1^{(l)}e_i^{(l-1)}+W_2^{(l)}(e_i^{(l-1)}⊙e_u^{(l-1)})) mu←i(l)=∣Nu∣∣Ni∣1(W1(l)ei(l−1)+W2(l)(ei(l−1)⊙eu(l−1)))
mu←u(l)=W1(l)eu(l−1) m_{u\leftarrow u}^{(l)}=W_1^{(l)}e_u^{(l-1)} mu←u(l)=W1(l)eu(l−1)
这是对user而言的,item的传播公式同理
其中mu←im_{u\leftarrow i}mu←i表示itemiitem_iitemi与useruuser_uuseru之间的协作信息,1∣Nu∣∣Ni∣\frac{1}{\sqrt{|N_u||N_i|}}∣Nu∣∣Ni∣1借鉴了GCN的思路,不过作者在文中把它理解为信息的衰减系数,也就是当前信息应该随着层的传播而比重变小。考虑到自己到自己的信息不用衰减,所以第二个式子没有乘上对称归一化的系数。W1,W2W_1,W_2W1,W2是可训练系数,ei,eue_i,e_uei,eu就是item和user的当前特征embedding,最后加了一个ei⊙eue_i⊙e_uei⊙eu,也就是两者的哈达玛积,用来编码两者的信息交互(有点像attention?)
最后得到每一层的新的特征表示:
eu(l)=LeakyReLU(mu←u(l)+∑i∈Numu←i(l)) e_u^{(l)} = LeakyReLU(m_{u\leftarrow u}^{(l)}+\sum_{i\in N_u}m_{u\leftarrow i}^{(l)}) eu(l)=LeakyReLU(mu←u(l)+i∈Nu∑mu←i(l))
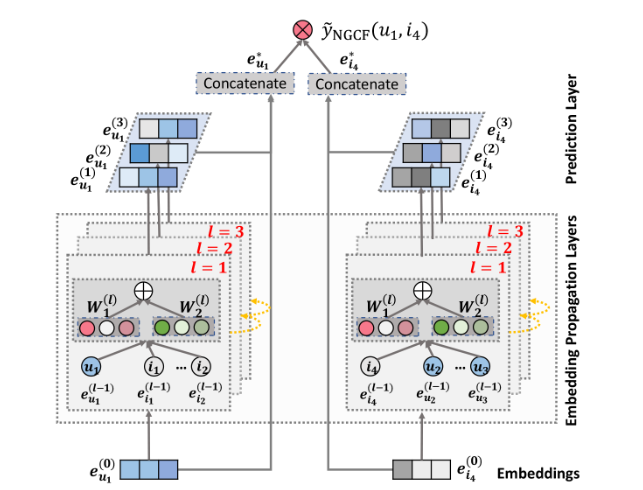
这是NGCF的基本结构。首先在embedding层获得每一个user,item的embedding,这里展示了eu1(0)e_{u_1}^{(0)}eu1(0)以及ei4(0)e_{i_4}^{(0)}ei4(0)的embedding。然后逐层传播并更新每一层的embedding,在最后一层将每一层的embedding进行拼接,然后拿去做预测。
这里拼接应该也是为了进行特征增强,不过后面LightGCN也还是改掉了。
LightGCN
可以看到NGCF其实大量借鉴了GCN的结构,但是其中也有一些操作是毫无理由就搬上来了。所以作者对其进行了大量的消融分析,包括对非线性激活和特征变化结构的质疑。
作者建立了四个模型进行比较,分别是
- NGCF,也就是原模型
- NGCF-n 去掉了特征变换,也就是上一节中的





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










