




今天来介绍些asr相关的主要模型论文的总结,希望对asr有兴趣的朋友们做个入门版的概览
模型架构和主流
wav语音波形(连续) -> 分帧/加窗/傅里叶变换 -> 语音特征(梅尔谱)(离散) -> tokenize(codebook) -> asr模型 -> 文本

模型架构对比
AR自回归 vs NAR非自回归
非自回归框架弱于自回归框架模型:
1.非自回归更快,但缺少输出token的上下文依赖 2.NAR需要进行输出token的predict
with llm architecture vs traditional
主流模型
NAR非自回归
paraformer
AR自回归
sensevoice-large
whisper
大模型
qwen-audio 1/2
MooER
seedASR
数据集
AISHELL-1, AISHELL-2 benchmark
benchmark
MooER benchmark表
| Language | Testset | Paraformer-large | SenseVoice-small | Qwen-audio | Whisper-large-v3 | SeamlessM4T-v2 | MooER-5K | MooER-80K | MooER-80K-v2 |
|---|---|---|---|---|---|---|---|---|---|
| Chinese | aishell1 | 1.93 | 3.03 | 1.43 | 7.86 | 4.09 | 1.93 | 1.25 | 1.00 |
| aishell2_ios | 2.85 | 3.79 | 3.57 | 5.38 | 4.81 | 3.17 | 2.67 | 2.62 | |
| test_magicdata | 3.66 | 3.81 | 5.31 | 8.36 | 9.69 | 3.48 | 2.52 | 2.17 | |
| test_thchs | 3.99 | 5.17 | 4.86 | 9.06 | 7.14 | 4.11 | 3.14 | 3.00 | |
| fleurs cmn_dev | 5.56 | 6.39 | 10.54 | 4.54 | 7.12 | 5.81 | 5.23 | 5.15 | |
| fleurs cmn_test | 6.92 | 7.36 | 11.07 | 5.24 | 7.66 | 6.77 | 6.18 | 6.14 | |
| average | 4.15 | 4.93 | 6.13 | 6.74 | 6.75 | 4.21 | 3.50 | 3.35 | |
| English | librispeech test_clean | 14.15 | 4.07 | 2.15 | 3.42 | 2.77 | 7.78 | 4.11 | 3.57 |
| librispeech test_other | 22.99 | 8.26 | 4.68 | 5.62 | 5.25 | 15.25 | 9.99 | 9.09 | |
| fleurs eng_dev | 24.93 | 12.92 | 22.53 | 11.63 | 11.36 | 18.89 | 13.32 | 13.12 | |
| fleurs eng_test | 26.81 | 13.41 | 22.51 | 12.57 | 11.82 | 20.41 | 14.97 | 14.74 | |
| gigaspeech dev | 24.23 | 19.44 | 12.96 | 19.18 | 28.01 | 23.46 | 16.92 | 17.34 | |
| gigaspeech test | 23.07 | 16.65 | 13.26 | 22.34 | 28.65 | 22.09 | 16.64 | 16.97 | |
| average | 22.70 | 12.46 | 13.02 | 12.46 | 14.64 | 17.98 | 12.66 | 12.47 |
主要挑战:
- 生词
- 噪音
- 口音
- 说话人重叠
- 上下文信息
- 切分过程的信息丢失
seedASR
1.前情提要
大部分end2end model取得了不错的成绩,但都是数据匹配场景的(细分场景),已经遇到了瓶颈。大模型有能处理多域、多语言、口音/方言的能力,中英公开数据集10%-40%(wer或cer)的提升
2.5个亮点
高识别精度:通过对超过 2000 万小时的语音数据和近 90 万小时的配对 ASR 数据进行训练,我们的中文多方言模型 Seed-ASR(CN)和多语言模型 Seed-ASR(ML)在公共数据集和我们内部的综合评估集上都取得了令人印象深刻的结果(如图 所示);
大模型容量:Seed-ASR 采用了拥有近 20 亿参数的音频编码器和包含数十亿参数的专家混合(MoE)LLM 进行建模。
多语言支持:在保持高精度的同时,Seed-ASR(CN)支持使用单一模型转录普通话和 13 种中国方言。此外,Seed-ASR(ML)能够识别英语及其他 7 种语言的语音,并且正在扩展以支持超过 40 种语言;
上下文感知能力:Seed-ASR 在统一模型中利用了包括历史对话、视频编辑历史和会议参与细节在内的多种上下文信息,以捕捉与语音内容相关的关键指标。这种整合大幅提升了各种场景下 ASR 评估集中的关键词召回率;
分阶段训练方案:Seed-ASR 的开发经历了一个简单而有效的训练方案:音频编码器的自监督学习(SSL)→ 监督微调(SFT)→ 上下文 SFT → 强化学习(RL)。每个阶段都有其独特的作用,确保了 Seed-ASR 的逐步性能提升。
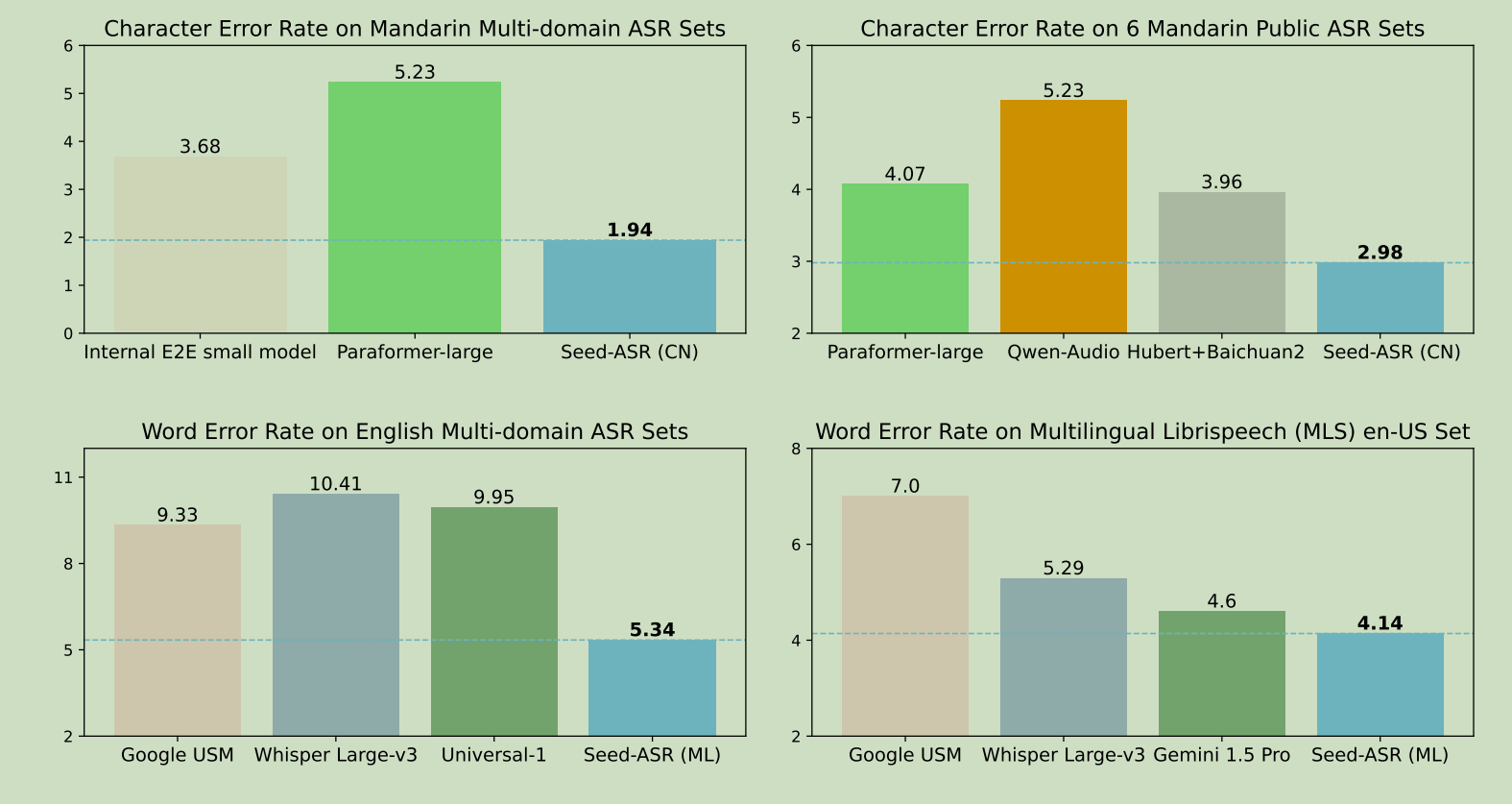
(注意这里的qwen-audio是版本1的,版本2的asr效果和paraformer差不多)
3.模型架构和训练
3.1架构图
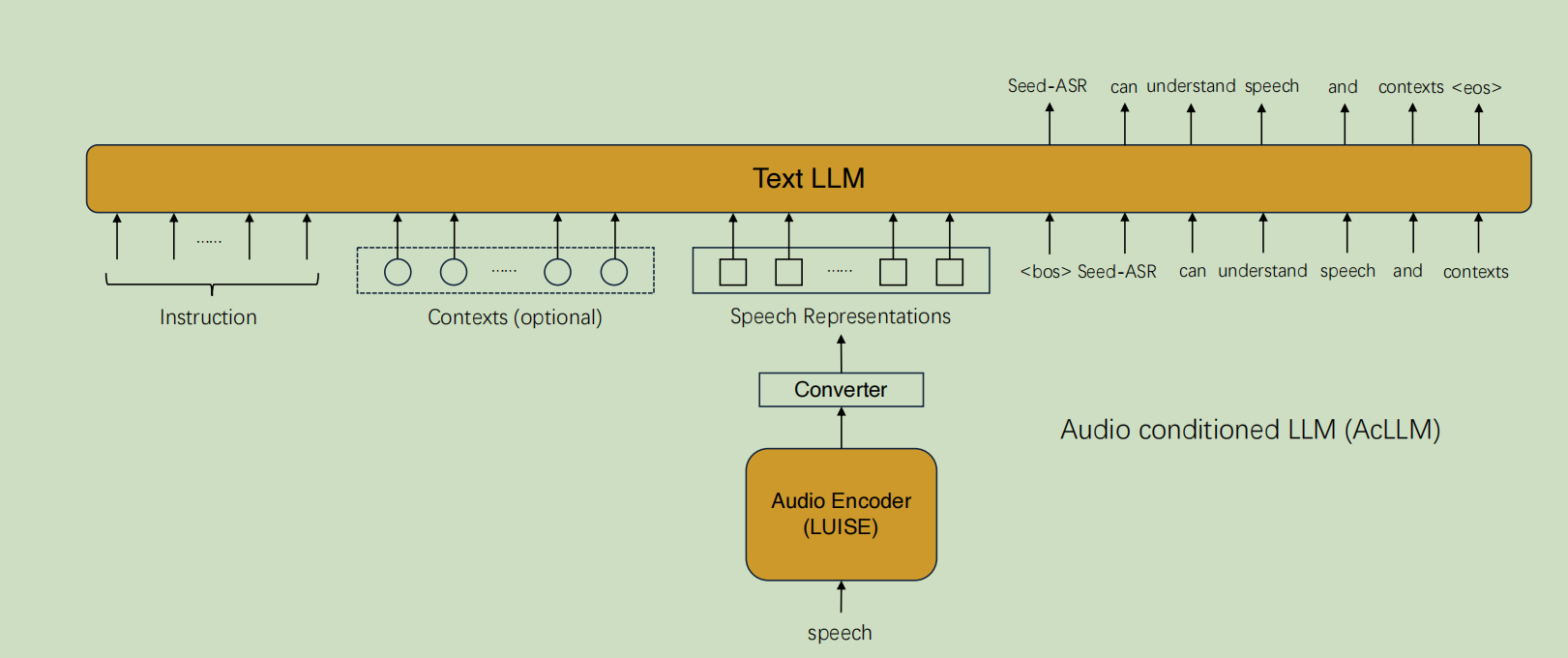
我们构建了一个拥有近 20 亿参数的音频编码器,并在数千万小时的数据上进行自监督学习(SSL)。经过预训练的音频编码器获得了强大的语音表示能力,从而在监督微调(SFT)阶段实现了快速收敛。在大规模 SSL 阶段之后,我们在 AcLLM 框架内实施了一个简单而有效的分阶段训练方案(如图 3 所示)。在 SFT 阶段,我们通过在大量语音-文本对上进行训练,建立语音和文本之间的映射关系。在上下文 SFT 阶段,我们使用相对较少的上下文-语音-文本三元组数据来引导 LLM 从上下文中捕捉与语音相关线索的能力。这些三元组数据可以根据特定场景进行定制。在强化学习阶段,我们应用了 MWER [37] 的训练标准并进行了一些改进,以进一步增强我们模型的能力。在接下来的小节中,我们将更详细地介绍这些方法。
3.2 音频编码器的自监督学习(SSL)
大规模的 SSL 使音频编码器能够从语音中捕捉丰富的信息。受到基于 BERT 的语音 SSL 框架 [27, 2, 8, 10] 的启发,我们开发了一个基于 Conformer [22] 的音频编码器模型,该模型能够捕捉音频信号中存储的全局和局部结构。在这项工作中,我们主要关注语音信号。由于它是在大规模无监督数据上进行训练的,我们将训练后的音频编码器称为 LUISE,代表大规模无监督迭代语音编码器(Large-scale Unsupervised Iterative Speech Encoder)。
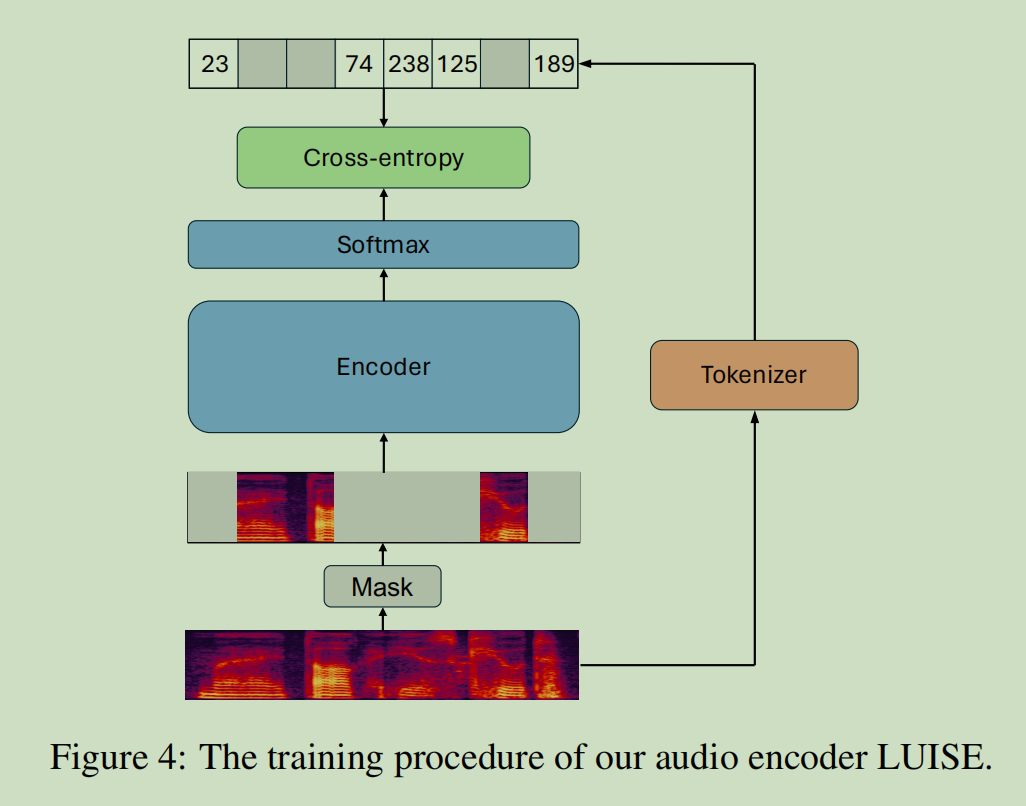
遵循 BERT [14] 的概念,LUISE 采用了掩码语言预测的学习范式。训练过程如图 4 所示。具体来说,从波形中提取的梅尔滤波器组特征序列首先被输入到分词器模块,以获得每一帧的离散标签。然后,LUISE 的训练使用交叉熵标准进行,损失函数仅针对被掩码的帧计算。训练完成后,移除 softmax 层,LUISE 的编码器部分将用于后续的监督微调。
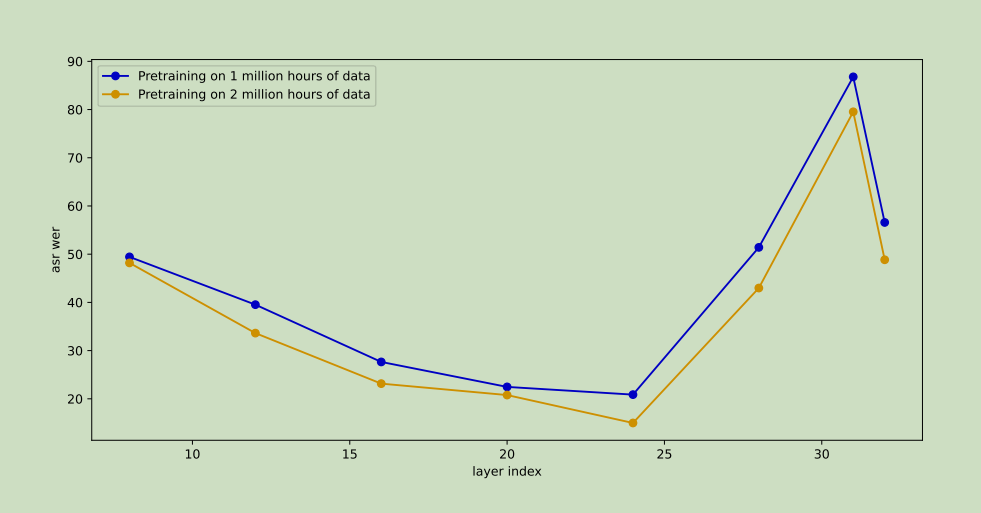
我们采用了一种迭代固定分词器方法来为每一帧获取相应的离散标签。在第一轮迭代中,我们使用随机投影层 [10] 将语音特征投射到一个随机初始化的码本中,并通过寻找码本中最接近的向量将它们映射为离散标签。在第二轮迭代中,我们对先前训练的编码器的中间层表示进行 K-means 聚类,以获得一个新的码本。然后,通过在新的码本中寻找最接近同一中间层表示的向量,获得离散标签。在选择中间层时,我们冻结在第一轮迭代中训练的编码器参数,并在每个中间层上添加一个映射层和连接时序分类(CTC)[21] 损失,以进行监督微调。图 5 显示了在每个中间层表示上进行监督微调后获得的字错误率(WER)。对于拥有 20 亿参数的 LUISE,32 层中的第 25 层的输出表现出了最佳的语义表示,并被用于后续迭代中离散标签的生成。
3.3 SFT
在对大规模语音数据进行训练后,LUISE 已经发展出强大的语音表示能力。它输出的连续表示包含丰富的语音和语义信息,帧率为 40 毫秒。为了使 AcLLM 更好地理解语音中的相应文本内容,我们需要将编码表示中的语义信息映射到 LLM 的语义空间中。为此,我们使用了以下两种方法:
- 在模型结构中,我们引入了一个转换器模块,将我们的音频编码器(LUISE)与 LLM 连接起来(如图 2 所示)。转换器包括一个下采样模块和一个线性投影层。我们发现不同的下采样方法效果相同,因此我们采用了最简洁的方法:帧拼接。具体来说,我们将连续的 4 帧语音表示在特征维度上进行拼接后输入到线性层中。因此,图 2 中输入到 LLM 的语音表示帧率为 160 毫秒;
- 在训练方法方面,我们采用了“可学习音频编码器 + 可学习转换器 + 固定 LLM”的策略,通过保持 LLM 的参数不变,最大化保留 LLM 的丰富语义知识和推理能力。可学习的音频编码器和转换器参数确保语音表示中的语义信息与 LLM 的语义空间对齐。在训练过程中,使用交叉熵损失函数,只有生成转录文本的标记位置参与交叉熵计算。
3.4 Context SFT
在对大规模语音-文本对数据进行训练后,我们的 SFT 模型在覆盖多个领域的测试集上表现出色。然而,SFT 模型的训练方式决定了它在给定上下文信息(context)时缺乏识别模糊语音内容的能力。这些问题在涉及口音(语音模糊)、同音词或稀有词(语义模糊)的场景中尤为突出。因此,我们引入了上下文感知训练
和联合束搜索方法来增强模型有效利用上下文的能力(示例见图 6)。
-
上下文感知训练:首先,我们使用内部 LLM 生成与语音转录相关的上下文。与使用长文本语音的历史转录作为上下文相比,实验表明这种方法效果更好。生成的自然语言上下文能够提供比采样词汇更完整的语义,从而使得模型不仅能复制相关的转录内容,还能学习推理。接着,我们建立了一个 <context, speech, text> 三元组的数据集,并与一定比例的通用 ASR 数据(语音-文本对数据)混合用于上下文感知训练。如图 2 所示,在上下文感知训练过程中,我们将上下文和语音表示输入到 LLM 中。此训练的目标是增强模型从上下文中捕捉与语音内容相关线索的能力。
-
联合束搜索:我们发现直接使用原生束搜索存在严重的幻觉问题。为了解决这个问题,我们提出了一种联合束搜索的解码策略,以缓解这一问题。具体而言,我们使用联合束搜索来寻找最佳得分 P j o i n t ( y ∣ x , c ) P_{joint}(y|x, c) Pjoint(y∣x,c),其中 y y y 表示预测的假设, x x x 是语音信息, c c c 是给定的上下文信息。超参数 α \alpha α 用于平衡解码过程中语音信息和上下文信息的重要性:
P j o i n t ( y ∣ x , c ) = α 1 + α ⋅ P ( y ∣ x , c ) + 1 1 + α ⋅ P ( y ∣ x ) P_{joint}(y|x, c) = \frac{\alpha}{1 + \alpha} \cdot P(y|x, c) + \frac{1}{1 + \alpha} \cdot P(y|x) Pjoint(y∣x,c)=1+αα⋅P(y∣x,c)+1+α1⋅P(y∣x)
同时,我们引入了一种修剪策略,首先使用上下文无关的得分 P ( y ∣ x ) P(y|x) P(y∣x) 来过滤掉声学上不合理的候选标记,然后对剩余的候选标记应用联合束搜索。修剪策略在减轻幻觉问题中发挥了重要作用。
3.5 RL
由于 SFT 和 Context SFT 阶段的训练是基于交叉熵目标函数,这与推理过程中使用的评估指标(如 WER)存在不匹配。随着强化学习(RL)的成功发展,它能够在序列建模任务中学习相对优化的决策策略。因此,我们通过构建基于 ASR 指标的奖励函数引入了 RL 阶段。
词错误率(WER)通常被视为评估 ASR 模型性能的核心指标,但句子中的某些内容(如关键词)在理解整个句子时起着更关键的作用。因此,我们还引入了加权词错误率(WWER)作为额外的奖励函数,强调关键词错误的重要性。具体来说,我们在 RL 阶段将最小词错误率(MWER)作为另一个训练目标,与交叉熵目标 L C E L_{CE} LCE 进行插值:
L N − b e s t m w e r ( x , y ∗ ) = 1 N ∑ y i ∈ N − b e s t ( x , N ) P ^ ( y i ∣ x ) ( W ( y i , y ∗ ) − W ˉ ) + λ L C E L_{N-best_{mwer}}(x, y^*) = \frac{1}{N} \sum_{y_i \in N-best(x, N)} \hat{P}(y_i|x) \left(W(y_i, y^*) - \bar{W}\right) + \lambda L_{CE} LN−bestmwer(x,y∗)=N1∑yi∈N−best(x,N)P^(yi∣x)(W(yi,y∗)−Wˉ)+λLCE
其中, W ( y ∗ , y i ) W(y^*, y_i) W(y∗,yi) 代表 ground-truth( y ∗ y^* y∗)和 N-best 中每个假设 y i y_i yi 之间的 WER 或 WWER 值(关键词错误的权重增加)。 W ˉ \bar{W} Wˉ 代表 N-best 假设的平均 WER 或 WWER。 λ \lambda λ 是插值系数。 P ^ ( y i ∣ x ) \hat{P}(y_i|x) P^(yi∣x) 代表假设的归一化似然概率,其计算方式如下:
P ^ ( y i ∣ x ) = P ( y i ∣ x ) ∑ y i ∈ N − b e s t ( x , N ) P ( y i ∣ x ) \hat{P}(y_i|x) = \frac{P(y_i|x)}{\sum_{y_i \in N-best(x, N)} P(y_i|x)} P^(yi∣x)=∑yi∈N−best(x,N)P(yi∣x)P(yi∣x)
为了提高 RL 的训练效率,我们部署了一个远程服务来生成假设,并同时计算 MWER 损失,同时在当前服务器上更新模型参数。在 RL 训练过程中:1) 我们使用之前阶段训练得到的上下文 SFT 模型初始化模型参数;2) 我们利用高质量的数据进行强化学习训练,数据规模达到数千小时;3) 为了保留初始化模型的上下文感知能力,我们的训练数据还包括一定比例的 <context, speech, text> 三元组。在完成 RL 训练后,我们得到我们的 Seed-ASR 模型。
表 1:RL 阶段的消融研究。加权 WER 作为奖励函数在所有三个评估集上表现优于 WER(这些集合的详细信息在第 4.1 节中介绍)。RL 阶段中的 <contexts, speech, text> 三元组训练数据确保了上下文感知能力没有下降。Seed-ASR 使用了最后一行的策略。WER 或加权 WER 指标计算中文、日文和韩文的字符错误率,英文及其他语言的词错误率。
| 模型 | 多领域 WER ↓ | Hardcase (F1%) ↑ | 上下文严格 (Recall%) ↑ |
|---|---|---|---|
| Context SFT 后模型 | 2.02 | 93.39 | 80.63 |
| + RL w/ WER 奖励 | 1.98 | 93.39 | 75.34 |
| + RL w/ 加权 WER 奖励 | 1.94 | 93.78 | 78.01 |
| + 训练 w/ 上下文 | 1.94 | 93.72 | 80.63 |
3.6 观察
在提高 Seed-ASR 性能的过程中,我们也获得了一些观察结果:
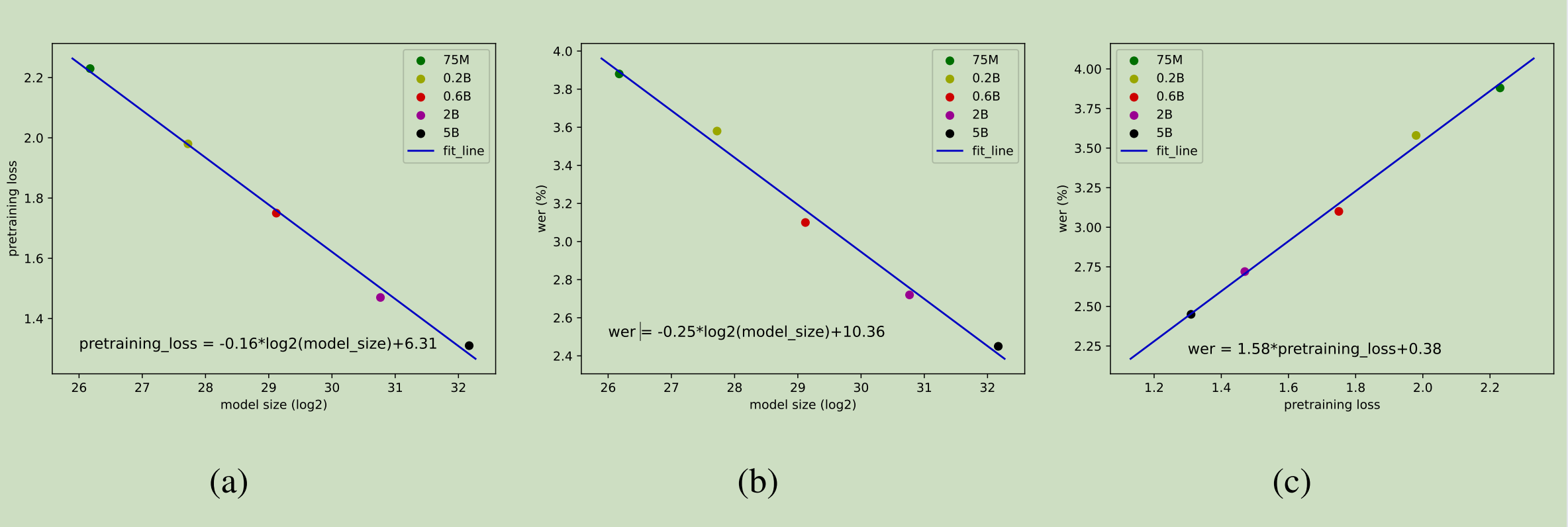
3.6.1 Scaling Law
在 LLM 领域,观察到更大的模型可以通过在更多数据上训练来持续降低损失值 [29, 26]。据我们所知,尚无关于基于 LLM 框架下音频编码器的扩展法则的相关研究。在 SSL 阶段,我们进行实验以探索不同模型规模下 LUISE 的性能。具体而言,我们选择了五组模型规模:75M、0.2B、0.6B、2B 和 5B。训练数据包括 770 万小时的无监督语音数据,覆盖多个领域,确保模型容量的充分利用。不同规模的模型在大多数训练配置中保持一致,除了随着模型规模的增加,我们按比例扩展模型的宽度和深度,适当增加批次大小和权重衰减,并降低学习率。
我们首先关注交叉熵预训练损失值与模型规模之间的相关性。如图 (a) 所示,我们观察到两者之间几乎是线性相关的。此外,我们比较了在小规模 SFT 数据上训练后的性能,使用贪婪搜索进行推理。如图 (b) 所示,多领域评估集上的 WER 指标也与 LUISE 的模型规模几乎呈线性相关关系。此外,这揭示了 SFT 后测试集上的 WER 指标与 SSL 阶段的损失函数值之间的正相关关系,如图 © 所示。这些关于扩展法则的发现为我们选择编码器(考虑到性能和效率的平衡)以及后续优化提供了指导。
3.6.2 长文本能力
我们的 Seed-ASR 模型在 AcLLM 框架下建模,自然利用了 LLM 的语义知识和长上下文建模能力。因此,我们还探索了将整个长文本语音直接输入 LLM 进行识别的选项。这种方法有效避免了将长文本语音分割为多个独立推理的问题:1) **分割过程可能导致边界处信息的丢失,**2)分割过程会破坏长文本语音中的强全局上下文信息,从而影响识别的准确性和一致性。
表 2:长文本视频测试集上的性能比较
| 模型 | 平均 WER | video_1 | video_2 | video_3 | video_4 | video_5 |
|---|---|---|---|---|---|---|
| Transducer-based E2E Model | 3.92 | 2.83 | 3.80 | 3.80 | 4.22 | 4.66 |
| Paraformer-large | 5.97 | 5.78 | 5.36 | 5.80 | 6.87 | 5.96 |
| Our Model after short-form SFT | 2.28 | 1.48 | 1.99 | 2.31 | 2.64 | 2.73 |
| + long-form SFT | 2.08 | 1.44 | 1.96 | 1.95 | 2.56 | 2.31 |
具体来说,我们构建了一系列长文本视频测试集,包括来自不同来源的 5 个数据集。在训练过程中,将整个长文本数据输入模型,而没有进行任何分割处理。测试集的时长分布与训练集相当。如表 2 所示,相比于短文本训练,长文本数据的训练和测试使得相对 WER 减少了近 8.8%。短文本训练使用了领域自适应 VAD 将长文本语音分割成几个部分进行训练和测试。长文本视频测试集的最大时长为 5 分钟,并具有显著的长度扩展调度器。
4 模型与评估
目前,我们重点关注在多样化场景中对中文和多语言(不含中文)语音识别性能的全面提升。因此,我们展示了两个具有相同模型结构和训练配方的 Seed-ASR 模型:中文多方言模型,称为 Seed-ASR (CN),以及多语言模型,称




















 7934
7934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










