




 本文介绍了如何使用Python的sklearn和graphviz库来创建和可视化决策树。首先,从sklearn导入数据集和决策树分类器,然后下载并配置graphviz环境变量。通过pip安装graphviz后,可以利用export_graphviz函数生成决策树的图形表示,并将其保存为PDF。示例以Iris数据集和英雄联盟比赛胜负数据展示了决策树的构建和应用。
本文介绍了如何使用Python的sklearn和graphviz库来创建和可视化决策树。首先,从sklearn导入数据集和决策树分类器,然后下载并配置graphviz环境变量。通过pip安装graphviz后,可以利用export_graphviz函数生成决策树的图形表示,并将其保存为PDF。示例以Iris数据集和英雄联盟比赛胜负数据展示了决策树的构建和应用。
我们以iris为例:
from sklearn import tree
from sklearn.datasets import load_iris
iris = load_iris()
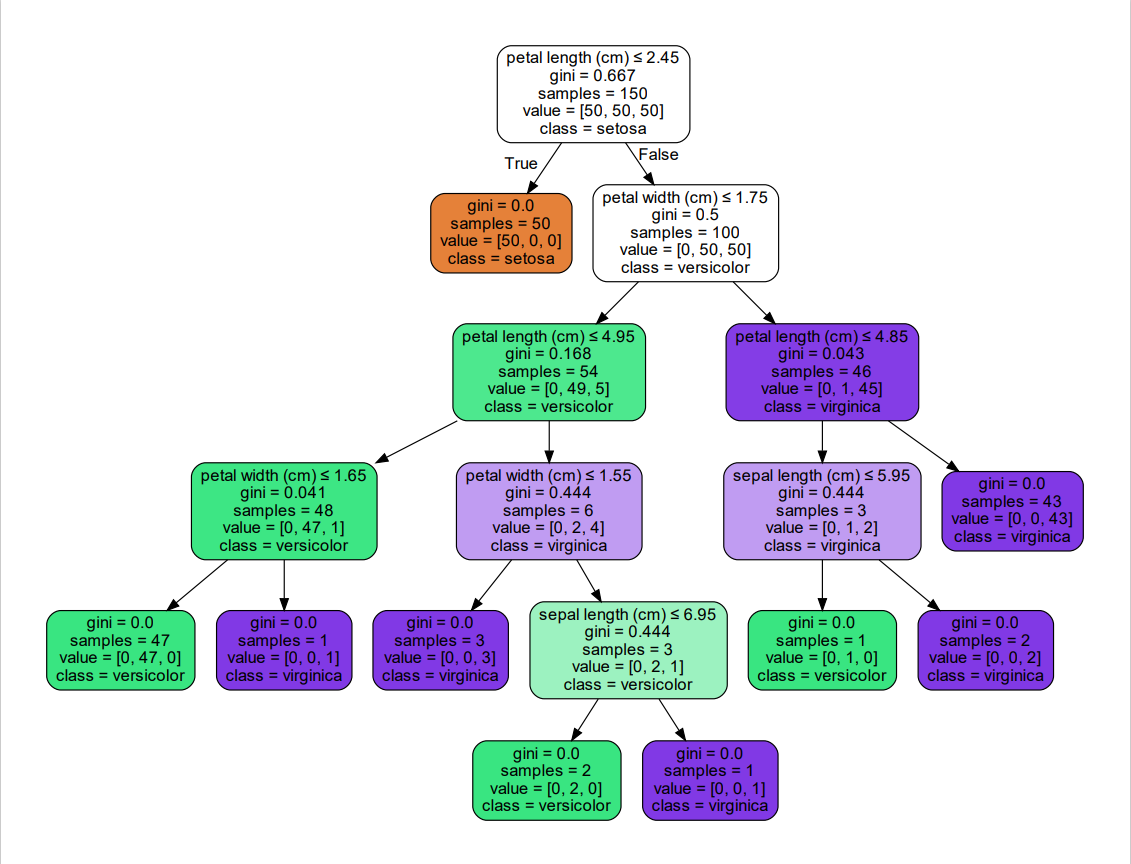
clf = tree.DecisionTreeClassifier()生成如下决策树:
第一步:去官网下载graphviz
建议安装到 自己的anaconda下的 \Lib\site-packages\ 里面去
第二步:改名字
比如我刚刚安装到了自己的anaconda下的 \Lib\site-packages\ 里面,文件名默认是大写的Graphviz,为了方便,我们改为graphviz。
第三步:配置环境变量
在系统、用户环境变量中添加路径:C:\Anaconda01\Lib\site-packages\graphviz\bin
当然如果你在安装时把那个添加环境变量打勾了就不用管了。
第三步:在对应的python环境下下载graphviz
pip install graphviz此时,C:\Anaconda01\Lib\site-packages\graphviz 这个文件发生变化了,里面多了些python文件。
第四步:简单演示
以一组英雄联盟胜负数据为例:连接这里有
from sklearn import tree
from graphviz import sources
DT = tree.DecisionTreeClassifier(criterion='entropy',max_depth=4,min_samples_split=500)
DT = DT.fit(x_train,y_train)
# export_graphviz 还支持各种美化,包括通过他们的类着色节点(或回归值),
# 如果需要,还能使用显式变量和类名。Jupyter notebook也可以自动内联式渲染这些绘制节点:
dot_data = tree.export_graphviz(DT, out_file=None, feature_names=feature_names, class_names=['lose','win'], filled=True, rounded=True, special_characters=True)
graph = sources.Source(dot_data)
graph.render("DT") # 保存成pdf
graph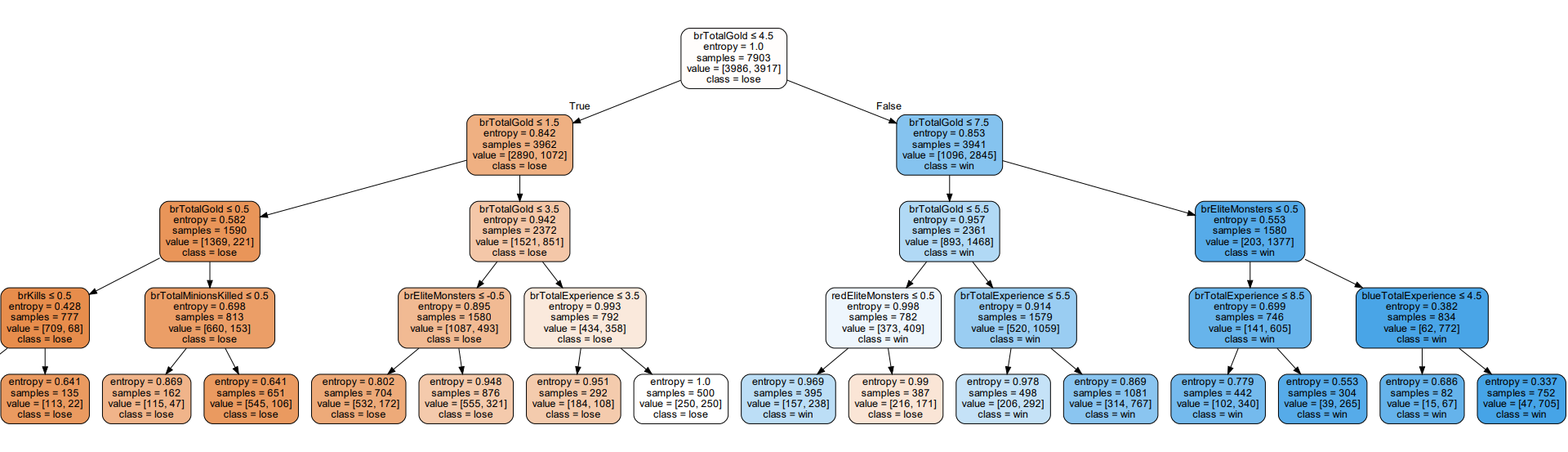
可以看到,左边蓝色方都输了,右边都赢了,中间有输有赢。
此外 graphviz 还有多种用法,可以自己设置节点等,感兴趣的可以自己进行查阅。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












