




引言
在正式进入神经网络之前,我们有必要先看清它在大图中的位置。
人工智能是终极目标,机器学习是实现路径 —— 让计算机从数据中自己学出规律;而神经网络是机器学习中的一类算法,深度学习则是它加深后的现代形态。
本章给出当前人工智能框架下的概念地图,帮助读者建立完整的坐标感:神经网络从哪来、属于谁、和别的算法有什么区别。理解了这张地图,后面每一章的推进才有方向感。
总览
-
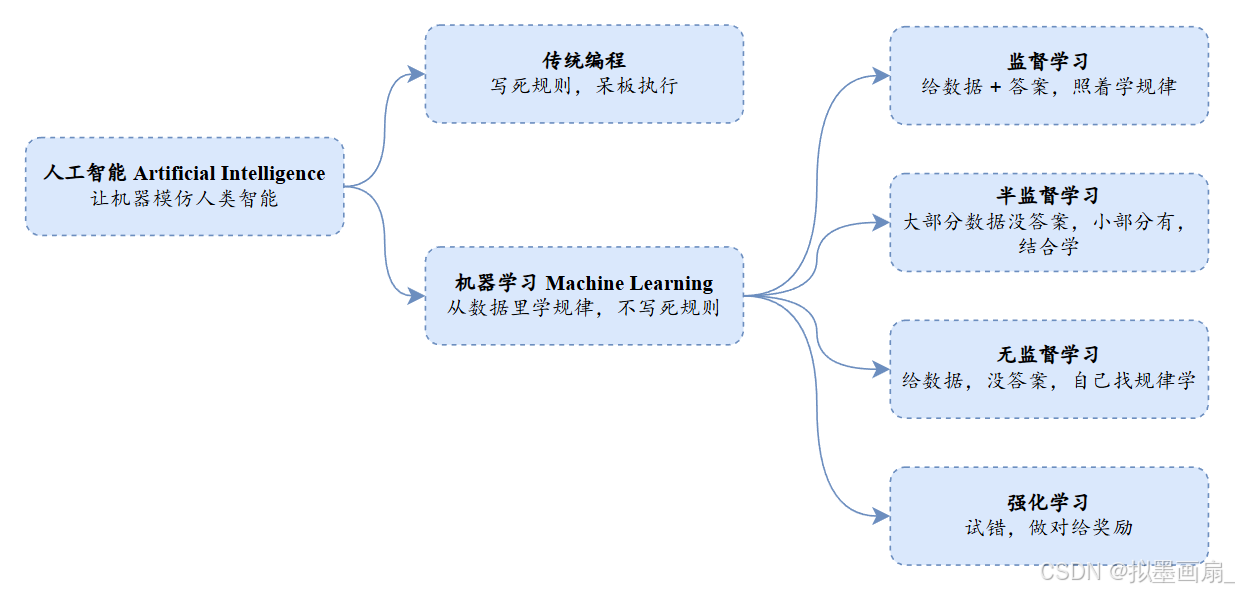
人工智能
AI(Artificial Intelligence)—— 让计算机模拟人类的思维,解决一些不能用代码描述的问题一些问题不能用传统的编程方法解决,因为没有一个确定的算法流程,但是人类很容易解决,因为人类大脑不是根据固定的算法来推导的,而是根据以往的认知或者经验来推理
将这个思想放到计算机上,即让计算机自己形成一套模型,然后利用这套模型解决问题。这里的模型,可以看做计算机的“经验”或者“认知”
-
机器学习
ML(Machine Learning)—— 从数据中积累经验,逐渐形成自己的认知,这个让计算机不断学习的过程,称为机器学习。按照学习方式分类,可以分为4类:名称 描述 类比 例子 监督学习 数据全部有标签
对照着学习规律有答案的练习题 给一堆标注“猫”和“狗”的图 无监督学习 数据全部没有标签
自己找规律没答案的试卷 把相似新闻自动归类 半监督学习 大部分数据没有标签,少数有标签
结合着学习先做几道例题
再做海量没答案的卷子100张CT片有诊断结果,用来
辅助学习剩下10000张无标签的CT片强化学习 做对奖励,做错惩罚
自己摸索出最优策略训狗,做对给肉,做错没吃 AlphaGo下棋
监督学习
-
概念 —— 监督学习属于机器学习下的一个范畴,其思想是:给机器一组带标签的数据,让它学会从输入到输出的映射关系
例如,输入是房屋的面积和地段,输出是房价;输入是一张图片,输出是“猫”还是“狗”
-
形式化表达 —— 给定训练数据集
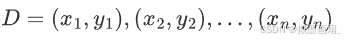
其中, x i x_i xi 是输入特征, y i y_i yi 是标签,监督学习目的是找到函数 f ( x ) f(x) f(x) ,使 f ( x i ) f(x_i) f(xi) 尽可能逼近真实值 y i y_i yi
-
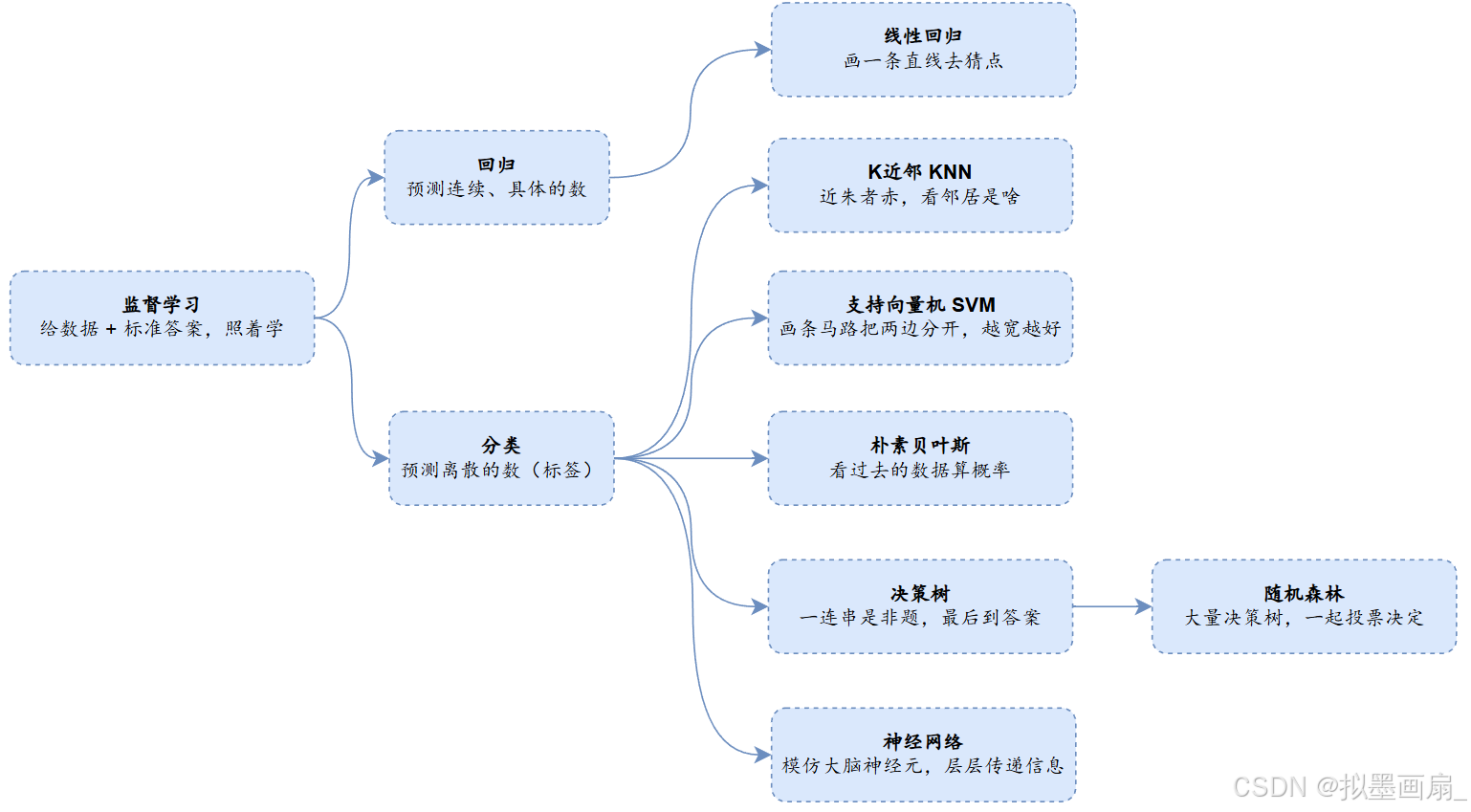
任务 —— 监督学习有两个主要任务:回归和分类
- 回归 —— 预测连续的、具体的数值
- 分类 —— 对各种事物进行分类,用于离散预测
-
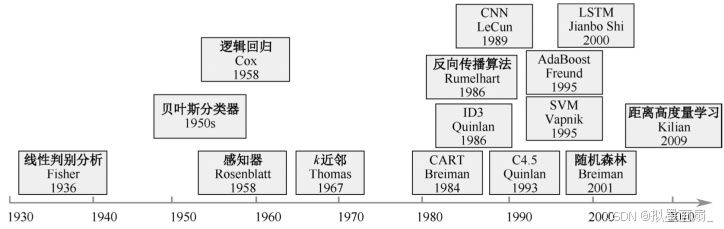
监督学习算法 —— 监督学习算法发展如下:
-
回归算法
算法 描述 特点 线性回归 画一条直线去拟合数据 最简单、可解释性强,假设数据是线性关系 多项式回归 画一条曲线去拟合数据 在线性回归的基础上加入了变量的高次项来拟合 岭回归 / Lasso回归 / 弹性网络给直线加紧箍咒 通过增加正则化项来防止模型过于复杂,减少过拟合 -
分类算法
算法 描述 特点 K近邻
(KNN)近朱者赤,近墨者黑
寻找周围最近的K个邻居的标签,依此投票决定自己- 不需要训练,惰性学习
- 对距离度量敏感,计算量大支持向量机
(SVM)找一个超平面,使得两类样本到此平面的最小距离最大 - 擅长高维数据、小样本
- 核技巧可处理非线性分类朴素贝叶斯 根据过去的数据算出各种概率
再由贝叶斯公式算后验概率,哪个大就判哪个- 假设特征之间相互独立(朴素的由来)
- 对小样本和缺失数据鲁棒,常用于文本分类决策树 一连串“是/否”的是非题,像猜谜游戏一样层层往下走
最后到达一个叶子节点,即答案- 可解释性强,可视化好
- 容易过拟合,需要剪枝。随机森林 种一大堆决策树,每棵树用不同的数据子集和特征子集训练
最后大家一起投票决定结果。- 比单棵决策树更稳定、更准
- 不容易过拟合逻辑回归 虽然名字里有“回归”,但实际是做分类的
输出0~1之间的概率,通常以0.5为阈值来划分类别- 线性分类器中的标杆
- 输出概率,可解释性好
- 只能处理线性可分问题神经网络 模仿大脑神经元,一层层传递信息
每个神经元把输入加权求和再激活,传给下一层- 可以拟合任意复杂函数
- 需要大量数据和算力
-
神经网络
-
概念
-
更进一步的,在监督学习下,我们看到了神经网络这一概念
-
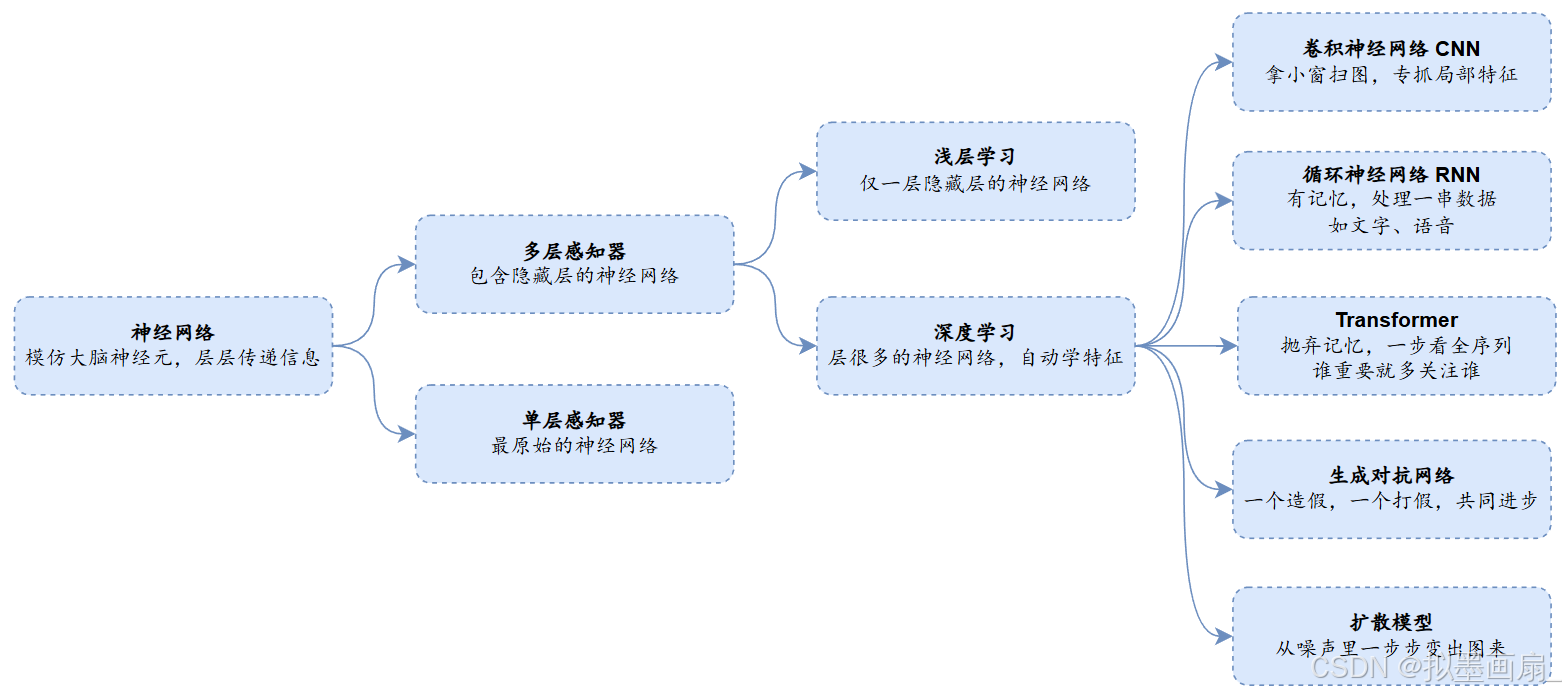
神经网络的思想是:通过模拟生物神经元连接方式,由输入层、隐藏层、输出层组成的可学习的计算系统
-
-
分类
- 单层神经网络 —— 只有输入层和输出层、没有隐藏层,只能解决线性可分问题
- 多层神经网络 —— 包含一个或多个隐藏层,通过层层非线性变换能解决复杂问题
- 浅层学习 —— 使用只有少量隐藏层(通常为1~2层)的神经网络进行学习,表达能力有限,但计算简单
- 深度学习 —— 使用包含大量隐藏层(通常数十甚至数百层)的神经网络进行学习,能自动从原始数据中逐层提取抽象特征
浅层学习与深度学习的历史
-
反向传播算法(BP)的提出,让神经网络能从大量数据中学习统计规律,掀起了基于统计模型的机器学习热潮,但当时的神经网络多为仅含一层隐层的浅层模型。
-
90年代,
SVM、Boosting等浅层模型在理论与应用大获成功,而深度神经因训练困难、理论分析复杂而相对沉寂。 -
2006年,
Hinton提出深度网络可通过逐层初始化有效训练,开启了深度学习的浪潮。 -
深度学习与浅层学习的主要区别在于:
-
深度学习强调模型深度,并明确突出逐层特征学习的重要性
-
浅层模型通常只有一层或无隐层,依赖人工构造特征
-
-
深度学习算法
算法 描述 特点 卷积神经网络
(CNN)拿个小窗口在图上滑来滑去
每次只看一小块,最后把所有小块看到的拼起来理解整张图- 适合图像、视频 - 局部连接 + 权值共享(参数量少)
- 能自动提取边缘→形状→物体特征循环神经网络
(RNN)有记忆的神经元,读完一句话会记住前面说了啥
用来理解“我今天吃了____”这种依赖上下文的任务- 适合文本、语音、时间序列
- 循环结构,有“记忆”
- 容易梯度消失/爆炸,记不住太长的话Transformer抛弃记忆结构,一步看全整个序列
用“注意力”给每个词打分,谁跟谁关系大就多关注谁- 适合长文本、翻译、大模型
- 并行计算(比RNN快得多)
- 自注意力机制是核心
- ChatGPT、BERT都是它生的生成对抗网络 ( GAN)一个伪造假画,一个当鉴定师抓假画
俩人互相对抗、共同进步,最后伪造能以假乱真- 能生成逼真图像、人脸、艺术品
- 训练难度高(两方要平衡)
- 生成器 + 判别器互相对抗扩散模型 先从一张图慢慢加噪声直到变成雪花点
然后反过来,从雪花点一步步去噪,还原成清晰图像- 目前最火的AI绘画核心
- 生成质量比GAN更稳
- 生成慢(要走很多步),但质量高
无监督学习
-
概念
-
在机器学习范畴下,除了监督学习,还有无监督学习、半监督学习以及强化学习。
-
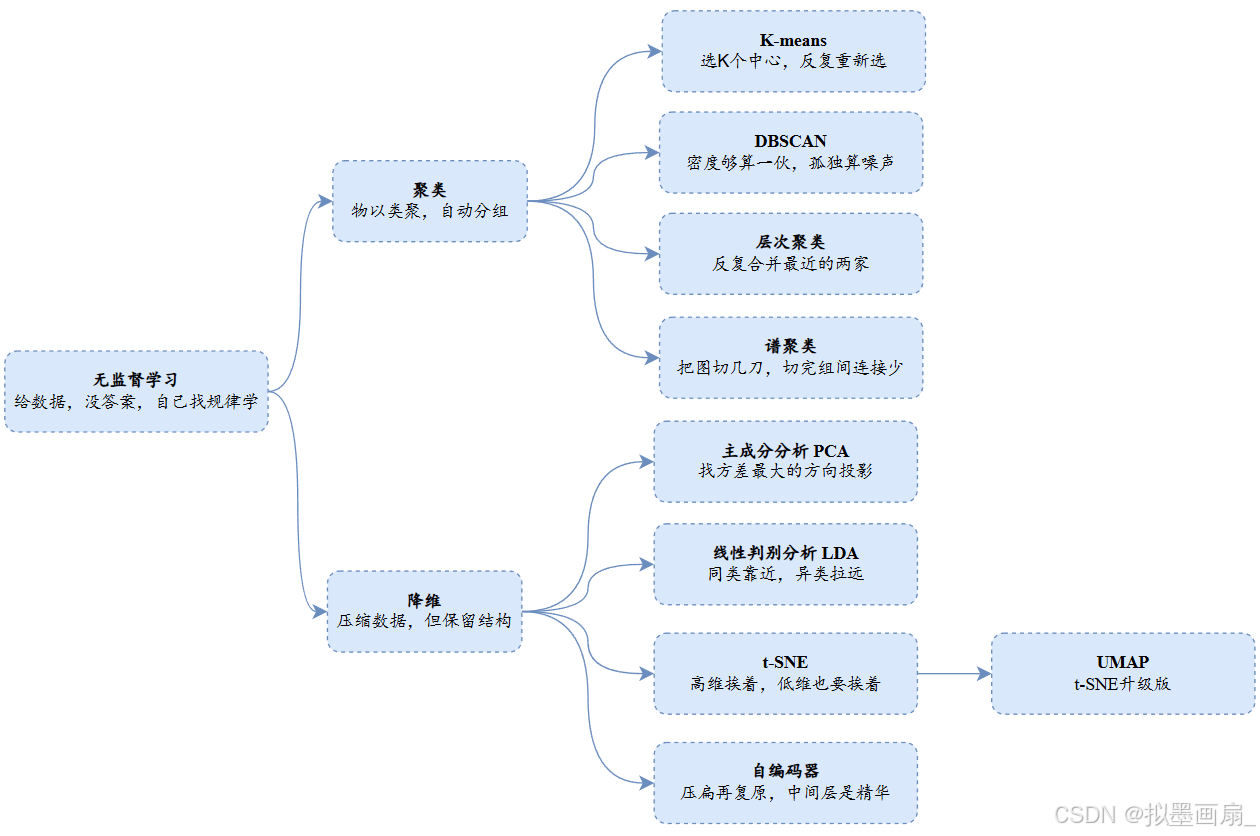
无监督学习的思想是:给机器一组无标签的数据,机器自己不断探索和归纳总结,尝试发现数据的内在规律和特征,对训练数据打标签
-
-
形式化表达 —— 给定训练数据集
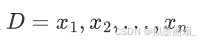
其中, x i x_i xi 是输入特征,无监督学习目的挖掘出数据的潜在模式,例如哪些样本相似
-
任务 —— 无监督学习有两个主要任务:聚类和降维
- 聚类 —— 将输入数据划分成几个组别,组别是根据数据的相似度划分
- 降维 —— 将高维数据转换为低维数据,同时尽量保留数据的重要信息
-
无监督学习算法
-
聚类算法
算法 类型 描述 特点 K-means基于划分的聚类 先随便选 K个点当“老大”
然后让每个小弟跟最近的“老大”
再重新选“老大”,重复直到稳定- 简单快速
- 需要预先指定K值
- 只能发现球形簇DBSCAN基于密度的聚类 扎堆的算一伙,孤立的算噪声
不管形状是圆是弯都能找出来- 不用指定簇个数
- 能发现任意形状簇
- 能自动识别噪声点层次聚类 基于层次的聚类 画一棵“家族树”,从每个点自成一族开始
反复把最近的两族合并- 生成可解释的树状图
- 不需要预先指定K
- 计算量大谱聚类 基于图论的聚类 把数据点看成网络节点,相似的点连边
然后切图,让不同组的连接尽量少- 擅长处理非凸形状簇
- 基于图拉普拉斯矩阵
- 对相似度图敏感高斯混合模型
(GMM)基于概率模型的聚类 假设数据是由多个高斯分布混合生成的
猜每个点属于哪个分布的概率- 输出“软聚类”(概率归属)
- 能描述椭圆形状簇 - 需要指定组件数 -
降维算法
算法 类型 描述 特点 主成分分析
(PCA)线性降维 找到数据“方差最大”的方向投影,
丢掉不重要的方向,压缩数据- 最经典、最快
- 线性变换,可解释性强
- 假设主成分正交线性判别分析
(LDA)线性降维 投影后让
同类尽量挤一起,不同类尽量远- 实际是有监督(需要标签)
- 常用于分类前的降维t-SNE非线性降维 高维中相似的点,在低维里也要靠得近
不相似的尽量远- 可视化效果极佳
- 计算慢,不适合新数据投影
- 只保留局部结构UMAP非线性降维 t-SNE的升级版
又快又能保留全局结构- 比t-SNE快得多
- 能保留更多全局结构
- 支持新数据投影自编码器
(Autoencoder)深度学习降维 先把数据“压缩”成低维码
再“解压”回去
中间那层就是降维结果- 能学非线性变换
- 需要训练神经网络
- 可结合正则化做特征学习
-
半监督学习
-
概念
-
半监督学习的思想介于全监督学习与无监督学习
-
其思想是:给机器少量有标签数据和大量无标签数据,让机器结合二者学习
-
-
应用场景 —— 现实中,获取有标签的数据往往很昂贵,而无标签数据却很多
-
医学影像 — 标注一张 CT 片需要专业医生,成本高。
-
语音识别 — 少量人工标注语音 + 大量未标注语音数据
-
-
常见学习方法
方法 思路 自训练 - 先用少量标注数据训练模型,让模型给未标注数据打伪标签
- 把高置信度的加入训练集,重复迭代伪标签法 - 模型对未标注数据预测出伪标签,当成真的算损失(本质是最简单的自训练) 协同训练 - 训练两个不同视角的模型,互相给对方未标注数据打伪标签
- 选置信度高的喂给对方再训练生成式方法 - 假设每个类别数据服从某种分布,用EM算法同时估计分布参数和未标注数据的类别 图半监督学习 - 把所有数据(标+未标)建成一张图,节点是样本,边是相似度
- 让标签沿着边传染给邻居。半监督 SVM- 找一条分类边界,不仅要分开已标注数据,还要让它避开高密度未标注数据(即边界应该划在数据稀疏区) 一致性正则化 - 对同一个未标注样本做两次不同的数据增强,模型对两次输出的预测应该一致(不能变来变去) MixMatch- 对未标注数据做多次增强并平均预测结果作为伪标签
- 再把增强后的数据和伪标签混合起来训练FixMatch- 对弱增强的未标注数据生成伪标签
- 再要求模型在强增强版本上也预测同一个标签对比学习方法 - 让同一样本的不同增强版本在特征空间里靠近,不同样本的版本互相推远
- 对比损失利用未标注数据。
强化学习
-
概念 —— 机器在互动环境中通过试错学习,做对了给奖励,做错了没奖励,目标是最大化累积奖励
-
应用场景 —— 需要序列决策、有长期后果的任务,难以直接给“正确答案”
- 游戏 —
AlphaGo击败围棋冠军,需要长远布局,不是只看眼前一步 - 机器人 — 学习行走、抓取物体,摔倒了才知道动作不对
- 自动驾驶 — 在复杂路况下决策,既要快又要安全
- 推荐系统 — 不断试探用户偏好,平衡“推熟悉的”和“尝试新内容”
- 游戏 —
-
核心要素 —— 马尔可夫决策过程
MDP要素 理解 类比 状态 智能体当前看到的局面 棋盘的棋子分布、机器人的关节角度 动作 智能体可以做的操作 下一颗棋、左腿向前迈一步 奖励 做动作后环境给的即时反馈 赢了+1分、撞墙-10分 策略 智能体的行动指南 在什么状态下该做什么动作 -
常见方法
方法 思路 值迭代 - 先算出每个状态/动作的“价值”(长期回报预期),再选价值最高的动作
- 基于动态规划,需要知道环境模型策略迭代 - 先定一个策略→评估它好不好→改进策略→循环,直到最优
- 同样基于动态规划Q-learning- 学一个 Q表: Q ( 状态 , 动作 ) = 这个动作的预期总奖励 Q(状态, 动作) = 这个动作的预期总奖励 Q(状态,动作)=这个动作的预期总奖励
- 不需要知道环境模型(离线学习),是经典的“无模型”方法深度 Q网络DQN- Q-learning的神经网络升级版:用神经网络代替Q表
- 能处理状态空间极大的问题(如下围棋、打雅达利游戏)策略梯度 - 不计算“价值”,直接优化策略函数:哪个动作的概率该提高?
- 天生适合连续动作问题(如机器人控制)演员-评论家 Actor-Critic- 策略梯度(演员负责选动作)+ 价值函数(评论家负责打分)
- 两个网络互相配合,训练更稳定
总结
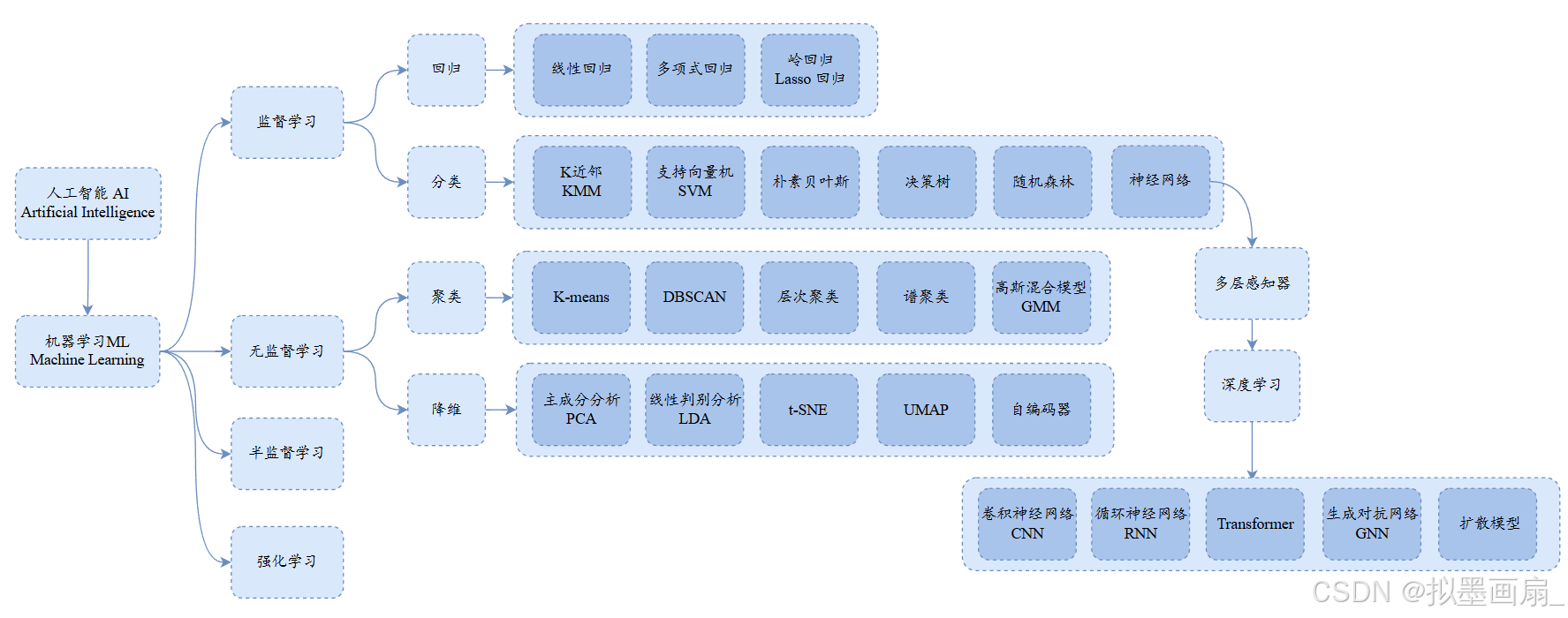
从这张图可以清晰地看到神经网络在整个计算机科学中的位置,它的层级脉络如下:
人工智能
A
I
→
机器学习
M
L
→
监督学习
→
神经网络
→
多层感知器
→
深度学习
→
全连接神经网络
F
C
N
N
、卷积神经网络
C
N
N
等
人工智能AI → 机器学习ML → 监督学习 → 神经网络 → 多层感知器 → 深度学习 → 全连接神经网络FCNN、卷积神经网络CNN等
人工智能AI→机器学习ML→监督学习→神经网络→多层感知器→深度学习→全连接神经网络FCNN、卷积神经网络CNN等
- 人工智能是让计算机模拟人类智能的宏大目标
- 机器学习是实现这一目标的核心路径 —— 让计算机从数据中自己学出规律,而非手工编写规则。
- 监督学习是机器学习中应用最广的分支,通过"带答案的数据"来训练模型。
- 神经网络是监督学习中的一类算法,模仿大脑神经元连接方式。
- 单层感知器是最原始的形态,但只能处理线性问题;
- 堆叠多层形成多层感知器,能够表达任意非线性函数。
- 当网络层数进一步加深、数据量和算力大幅增长时,便进入了深度学习阶段,衍生出全连接网络、卷积神经网络、 T r a n s f o r m e r Transformer Transformer 等各种强大架构。
参考内容:


















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










