




一、信息来源
本文章是对韩国科学技术研究院于2025年5月8号发布的大模型推理服务框架综述文章《ASurvey on Inference Engines for Large Language Models:Perspectives on Optimization and Efficiency》做一个记录,方便后续查阅。
论文Github: https://github.com/sihyeong/Awesome-LLM-Inference-Engine
二、LLM推理流程
- 大模型结构和主流的Attention机制:当前大模型的架构基本是Decoder架构,也基本采用MQA(可通过config.json文件的num_key_value_heads查看分组信息,比如值为2,则是2个Query共享一对Key/Value值)。
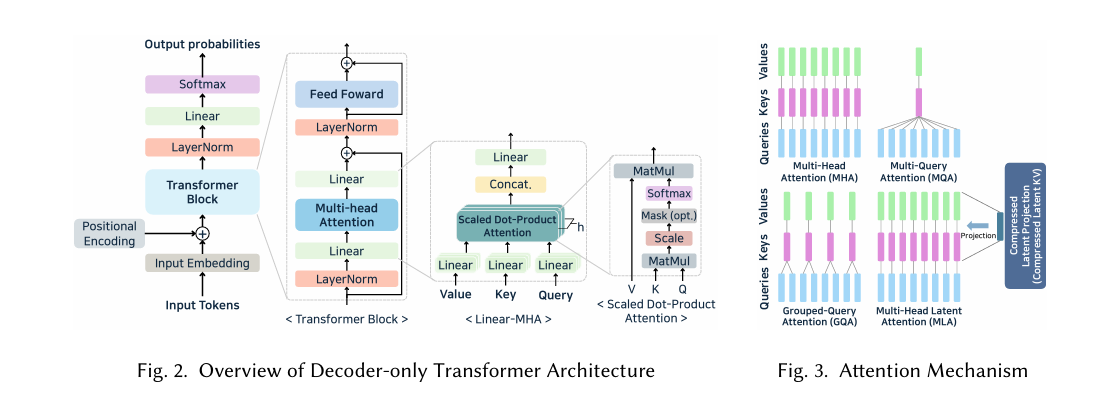
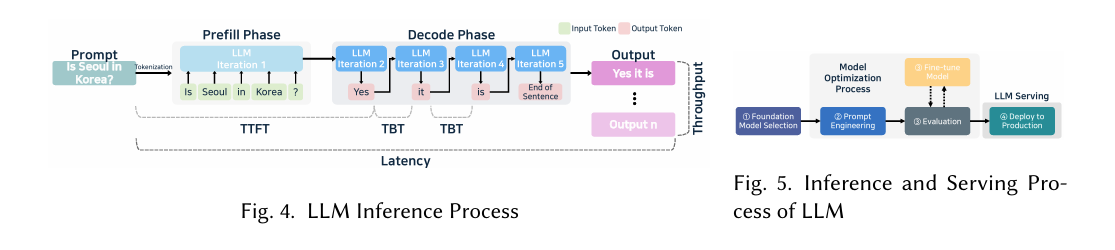
- 大模型推理流程:自回归解码(TTFT-首Token到达时间,TBT-Token与Token生成之间的时间间隔,Latency-输入至输出所耗费的时间)
三、论文重点关注点
大模型推理引擎选型时,根据以下四个方向,结合自己的使用场景,基本上都能够选定合适的推理引擎,根据个人经验,vLLM、Sglang适合大多数场景,但拥有一定的上手门槛,个人本地尝鲜Ollama足够了。补充个信息,Mac M芯片上部署大模型推荐使




















 1750
1750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










